代码:
# 创建数据框
data_a <- data.frame(
usubjid = c('1- 1', '1- 2', '1- 3', '1- 4', '1- 5',
'1- 6', '1- 7', '1- 8', '1- 9', '1-10',
'2- 1', '2- 2', '2- 3', '2- 4', '2- 5',
'2- 6', '2- 7', '2- 8', '2- 9', '2-10'),
cnsr = c(0,1,0,1,0,1,0,0,0,1,
1,0,1,0,1,0,0,1,0,1),
time = c(5,7,9,1,10,2,9,11,8,4,
11,11,9,11,10,12,9,9,9,13),
arm = c(rep('A', 10), rep('B', 10))
)
# 查看数据结构
str(data_a)
# 显示前6行
head(data_a)
# 检查观测数
nrow(data_a) # 应返回20
# 检查分组比例
table(data_a$arm) # 应显示 A:10, B:10
# 加载必要的包
library(survival)
library(survminer) # 用于可视化(可选)
# 创建生存对象:事件定义为cnsr=0(需反转cnsr)
Surv_obj <- Surv(time = data_a$time, event = 1 - data_a$cnsr)
# 分层分析(按arm分组)并进行Log-Rank检验
logrank_test <- survdiff(Surv_obj ~ arm, data = data_a)
# 提取原始p值并应用Bonferroni校正(仅一次比较,校正后p值不变)
p_value <- 1 - pchisq(logrank_test$chisq, df = 1)
adjusted_p_value <- p.adjust(p_value, method = "bonferroni")
# 输出Log-Rank检验结果
cat("Log-Rank Test Results:\n")
cat("----------------------\n")
cat("Chi-Square Statistic:", logrank_test$chisq, "\n")
cat("Degrees of Freedom:", logrank_test$df, "\n")
cat("Raw p-value:", p_value, "\n")
cat("Bonferroni-adjusted p-value:", adjusted_p_value, "\n\n")
# 拟合Kaplan-Meier曲线(对照组为B组)
km_fit <- survfit(Surv_obj ~ arm, data = data_a)
# 输出生存曲线摘要(含中位生存时间及置信区间)
cat("Kaplan-Meier Survival Summary:\n")
cat("------------------------------\n")
print(summary(km_fit))
# 加载包
library(survival)
library(survminer) # 确保已加载!
# 绘制生存曲线
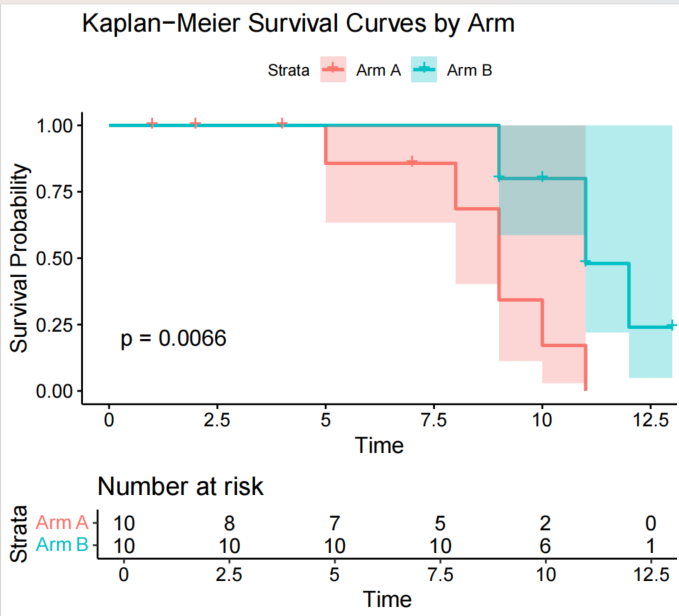
ggsurvplot(km_fit,
data = data_a,
pval = TRUE, # 显示p值
conf.int = TRUE, # 显示置信区间
和地址(Address))





