CONTENTS
- LeetCode 126. 单词接龙 II(困难)
- LeetCode 127. 单词接龙(困难)
- LeetCode 128. 最长连续序列(中等)
- LeetCode 129. 求根节点到叶节点数字之和(中等)
- LeetCode 130. 被围绕的区域(中等)
LeetCode 126. 单词接龙 II(困难)
【题目描述】
按字典 wordList 完成从单词 beginWord 到单词 endWord 转化,一个表示此过程的转换序列是形式上像 beginWord -> s1 -> s2 -> ... -> sk 这样的单词序列,并满足:
- 每对相邻的单词之间仅有单个字母不同。
- 转换过程中的每个单词
si( 1 ≤ i ≤ k 1 \le i \le k 1≤i≤k)必须是字典wordList中的单词。注意,beginWord不必是字典wordList中的单词。 sk == endWord。
给你两个单词 beginWord 和 endWord,以及一个字典 wordList。请你找出并返回所有从 beginWord 到 endWord 的最短转换序列,如果不存在这样的转换序列,返回一个空列表。每个序列都应该以单词列表 [beginWord, s1, s2, ..., sk] 的形式返回。
【示例 1】
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]
输出:[["hit","hot","dot","dog","cog"],["hit","hot","lot","log","cog"]]
解释:存在 2 种最短的转换序列:
"hit" -> "hot" -> "dot" -> "dog" -> "cog"
"hit" -> "hot" -> "lot" -> "log" -> "cog"
【示例 2】
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"]
输出:[]
解释:endWord "cog" 不在字典 wordList 中,所以不存在符合要求的转换序列。
【提示】
1 < = b e g i n W o r d . l e n g t h < = 5 1 <= beginWord.length <= 5 1<=beginWord.length<=5
e n d W o r d . l e n g t h = = b e g i n W o r d . l e n g t h endWord.length == beginWord.length endWord.length==beginWord.length
1 < = w o r d L i s t . l e n g t h < = 500 1 <= wordList.length <= 500 1<=wordList.length<=500
w o r d L i s t [ i ] . l e n g t h = = b e g i n W o r d . l e n g t h wordList[i].length == beginWord.length wordList[i].length==beginWord.length
beginWord、endWord 和 wordList[i] 由小写英文字母组成
beginWord != endWord
wordList 中的所有单词互不相同
【分析】
本题本质上是一个最短路的问题,如果不考虑具体方案,只求最短转换次数,可以看成边权为 1 的无向图,因此用 BFS 就能求出起点到每个点的最短距离。
本题的建图方式可以枚举每一对单词,然后判断这一对单词之间是否只有一个字符不同,这样建图的时间复杂度为 O ( n 2 L ) O(n^2L) O(n2L),其中 n n n 为字典的长度, L L L 为每个单词的长度。也可以只枚举一遍每个单词,对于每个单词枚举其每一个字符的所有可能的变化情况(26 种字符),然后判断变化一个字符后的单词是否在字典中(可以用哈希表),这样时间复杂度为 O ( 26 n L 2 ) O(26nL^2) O(26nL2),比前一种方式更好。
但是我们最后需要输出所有方案,方案数是指数级别的,如果直接爆搜也会 TLE。可以先预处理出 d i s [ i ] dis[i] dis[i] 数组表示从起点到 i i i 的最短距离,用来保证不会搜索没有意义的方案。
从终点 endWord 往回爆搜所有方案,假如 endWord 能变换到某个单词 a,那么只有满足 dis[a] + 1 == dis[endWord] 时搜索 a 才是有意义的,否则往 a 走一定不存在最短路。
【代码】
class Solution {
public:vector<vector<string>> res;vector<string> v;unordered_set<string> st; // wordList 中的单词集合unordered_map<string, int> dis; // dis[i] 表示 beginWord 到单词 i 的最短转换距离vector<vector<string>> findLadders(string beginWord, string endWord, vector<string>& wordList) {for (string word: wordList) st.insert(word);if (!st.count(endWord)) return res; // 字典中没有 endWord 就无解queue<string> Q;Q.push(beginWord);dis[beginWord] = 0;while (Q.size()) { // BFS 求起点到各点的最短距离string s = Q.front(); Q.pop();if (s == endWord) break; // 已经搜到 endWord// 枚举 s 只改变一个字符的所有情况for (int i = 0; i < s.size(); i++) { // 枚举每一位string t = s; // 拷贝一份方便还原for (char c = 'a'; c <= 'z'; c++) { // 枚举 'a' ~ 'z't[i] = c;if (st.count(t) && !dis.count(t)) // 如果在字典中且还未更新过最短距离则进行更新dis[t] = dis[s] + 1, Q.push(t);}}}v.push_back(endWord);dfs(beginWord, endWord); // 从终点开始爆搜所有方案return res;}void dfs(string& beginWord, string& s) {if (s == beginWord) {reverse(v.begin(), v.end()); // 从终点开始遍历,需要翻转序列res.push_back(v);reverse(v.begin(), v.end()); // 复原return;}for (int i = 0; i < s.size(); i++) {string t = s;for (int c = 'a'; c <= 'z'; c++) {t[i] = c;if (dis.count(t) && dis[t] + 1 == dis[s]) { // 不能用 st.count(t) 判断,因为起点不在 st 中v.push_back(t);dfs(beginWord, t);v.pop_back();}}}}
};
LeetCode 127. 单词接龙(困难)
【题目描述】
字典 wordList 中从单词 beginWord 到 endWord 的转换序列是一个按下述规格形成的序列 beginWord -> s1 -> s2 -> ... -> sk:
- 每一对相邻的单词只差一个字母。
- 对于 1 ≤ i ≤ k 1 \le i \le k 1≤i≤k 时,每个
si都在wordList中。注意,beginWord不需要在wordList中。 sk == endWord
给你两个单词 beginWord 和 endWord 和一个字典 wordList,返回从 beginWord 到 endWord 的最短转换序列中的单词数目。如果不存在这样的转换序列,返回 0。
【示例 1】
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"]
输出:5
解释:一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog", 返回它的长度 5。
【示例 2】
输入:beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log"]
输出:0
解释:endWord "cog" 不在字典中,所以无法进行转换。
【提示】
1 < = b e g i n W o r d . l e n g t h < = 10 1 <= beginWord.length <= 10 1<=beginWord.length<=10
e n d W o r d . l e n g t h = = b e g i n W o r d . l e n g t h endWord.length == beginWord.length endWord.length==beginWord.length
1 < = w o r d L i s t . l e n g t h < = 5000 1 <= wordList.length <= 5000 1<=wordList.length<=5000
w o r d L i s t [ i ] . l e n g t h = = b e g i n W o r d . l e n g t h wordList[i].length == beginWord.length wordList[i].length==beginWord.length
beginWord、endWord 和 wordList[i] 由小写英文字母组成
beginWord != endWord
wordList 中的所有单词互不相同
【分析】
和上一题一模一样,步骤还简化了,不用求出所有具体方案,只要 BFS 一遍求出最短路径长度即可,上一题理解了这一题就不用讲解了。
【代码】
class Solution {
public:unordered_set<string> st;unordered_map<string, int> dis;int ladderLength(string beginWord, string endWord, vector<string>& wordList) {for (string word: wordList) st.insert(word);if (!st.count(endWord)) return 0;queue<string> Q;Q.push(beginWord);dis[beginWord] = 1; // 上一题中距离不影响求解具体方案,没有将 beginWord 算进距离while (Q.size()) {string s = Q.front(); Q.pop();if (s == endWord) break;for (int i = 0; i < s.size(); i++) {string t = s;for (char c = 'a'; c <= 'z'; c++){t[i] = c;if (st.count(t) && !dis.count(t))dis[t] = dis[s] + 1, Q.push(t);}}}return dis[endWord];}
};
LeetCode 128. 最长连续序列(中等)
【题目描述】
给定一个未排序的整数数组 nums,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
请你设计并实现时间复杂度为 O ( n ) O(n) O(n) 的算法解决此问题。
【示例 1】
输入:nums = [100,4,200,1,3,2]
输出:4
解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
【示例 2】
输入:nums = [0,3,7,2,5,8,4,6,0,1]
输出:9
【示例 3】
输入:nums = [1,0,1,2]
输出:3
【提示】
0 < = n u m s . l e n g t h < = 1 0 5 0 <= nums.length <= 10^5 0<=nums.length<=105
− 1 0 9 < = n u m s [ i ] < = 1 0 9 -10^9 <= nums[i] <= 10^9 −109<=nums[i]<=109
【分析】
首先用哈希表记录下每个数是否存在,然后按照任意顺序枚举每个数,假如枚举到 x x x,然后我们就不断查看 x + 1 , x + 2 , … , y x + 1, x + 2, \dots, y x+1,x+2,…,y 是否存在,直到 y + 1 y + 1 y+1 不存在,那么连续序列的长度就为 y − x + 1 y - x + 1 y−x+1。
但如果每次都这样枚举时间复杂度为 O ( n 2 ) O(n^2) O(n2),需要优化,我们只枚举每段连续序列的起点,也就是最小值,如果 x − 1 x - 1 x−1 存在说明 x x x 肯定不是最长连续序列的起点,就不用枚举了。
此外还需要进行判重,对于遍历过的序列将其从哈希表中删去,保证每个数只被枚举一次,这样时间复杂度就为 O ( n ) O(n) O(n)。
【代码】
class Solution {
public:int longestConsecutive(vector<int>& nums) {unordered_set<int> st(nums.begin(), nums.end());for (int num: nums) st.insert(num);int res = 0;for (int num: nums)if (st.count(num) && !st.count(num - 1)) { // num 为连续序列的起点int x = num;while (st.count(x)) st.erase(x++); // 将 num 为起点的连续序列从哈希表中删去res = max(res, x - num);}return res;}
};
LeetCode 129. 求根节点到叶节点数字之和(中等)
【题目描述】
给你一个二叉树的根节点 root,树中每个节点都存放有一个 0 到 9 之间的数字。
每条从根节点到叶节点的路径都代表一个数字,例如,从根节点到叶节点的路径 1 -> 2 -> 3 表示数字 123。
计算从根节点到叶节点生成的所有数字之和。
叶节点是指没有子节点的节点。
【示例 1】
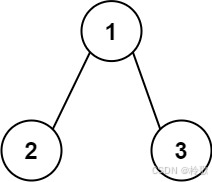
输入:root = [1,2,3]
输出:25
解释:
从根到叶子节点路径 1->2 代表数字 12
从根到叶子节点路径 1->3 代表数字 13
因此,数字总和 = 12 + 13 = 25
【示例 2】
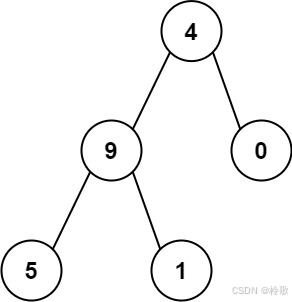
输入:root = [4,9,0,5,1]
输出:1026
解释:
从根到叶子节点路径 4->9->5 代表数字 495
从根到叶子节点路径 4->9->1 代表数字 491
从根到叶子节点路径 4->0 代表数字 40
因此,数字总和 = 495 + 491 + 40 = 1026
【提示】
树中节点的数目在范围 [ 1 , 1000 ] [1, 1000] [1,1000] 内
0 < = N o d e . v a l < = 9 0 <= Node.val <= 9 0<=Node.val<=9
树的深度不超过 10
【分析】
从根节点递归不断构建数字向下传递(维护从根到当前节点所构成的数是多少),直到叶节点就能找到根节点到叶节点所构成的数,然后在回溯的同时自下而上地计算每个子树的总和并返回:
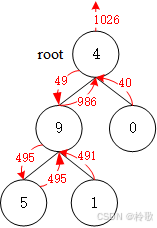
【代码】
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:int sumNumbers(TreeNode* root) {return dfs(root, root->val); // 返回从 root 到叶节点的所有数字之和}int dfs(TreeNode* u, int val) { // val 表示从 root 走到 u 所构成的数字是多少if (!u->left && !u->right) return val; // u 已经是叶子节点了则返回所构成的数字int left = 0, right = 0;if (u->left) left = dfs(u->left, val * 10 + u->left->val);if (u->right) right = dfs(u->right, val * 10 + u->right->val);return left + right;}
};
LeetCode 130. 被围绕的区域(中等)
【题目描述】
给你一个 m × n m \times n m×n 的矩阵 board,由若干字符 'X' 和 'O' 组成,捕获所有被围绕的区域:
- 连接:一个单元格与水平或垂直方向上相邻的单元格连接。
- 区域:连接所有
'O'的单元格来形成一个区域。 - 围绕:如果您可以用
'X'单元格连接这个区域,并且区域中没有任何单元格位于board边缘,则该区域被'X'单元格围绕。
通过原地将输入矩阵中的所有 'O' 替换为 'X' 来捕获被围绕的区域。你不需要返回任何值。
【示例 1】
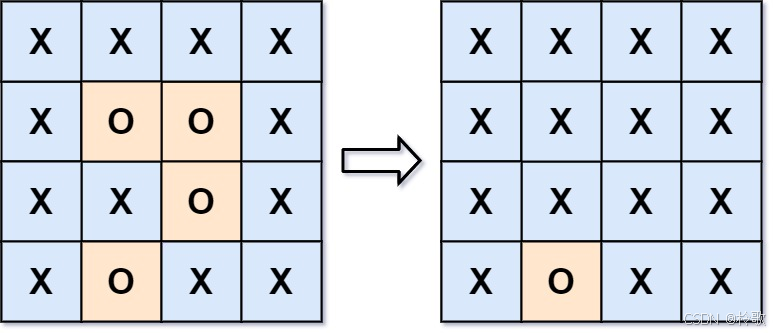
输入:board = [["X","X","X","X"],["X","O","O","X"],["X","X","O","X"],["X","O","X","X"]]
输出:[["X","X","X","X"],["X","X","X","X"],["X","X","X","X"],["X","O","X","X"]]
解释:在上图中,底部的区域没有被捕获,因为它在 board 的边缘并且不能被围绕。
【示例 2】
输入:board = [["X"]]
输出:[["X"]]
【提示】
m = = b o a r d . l e n g t h m == board.length m==board.length
n = = b o a r d [ i ] . l e n g t h n == board[i].length n==board[i].length
1 < = m , n < = 200 1 <= m, n <= 200 1<=m,n<=200
board[i][j] 为 'X' 或 'O'
【分析】
本题是考查经典的 Flood Fill 算法,也就是搜索连通块。我们需要考虑如何找出所有被 X 包围的 O,可以对于所有 O 的连通块都搜索一遍看看这个连通块有没有到边界,但是这样比较繁琐。
我们也可以逆向思维,先找出没有被包围的 O,也就是与边界相连的所有 O 的连通块都没有被包围,可以先从四个边界扫描一遍,用 Flood Fill 将 O 的连通块变为其他字符,例如 .,然后此时还剩下的 O 就都是被包围的,把剩余的 O 变成 X 就行。最后还需要继续扫描一下边缘用 Flood Fill 将 . 变回 O。
【代码】
class Solution {
public:int n, m;int dx[4] = {0, 1, 0, -1}, dy[4] = {-1, 0, 1, 0};void solve(vector<vector<char>>& board) {n = board.size(), m = board[0].size();for (int i = 0; i < n; i++) { // 将第一列和最后一列含 'O' 的连通块变为 '.'if (board[i][0] == 'O') dfs(board, i, 0, 'O', '.');if (board[i][m - 1] == 'O') dfs(board, i, m - 1, 'O', '.');}for (int i = 0; i < m; i++) { // 将第一行和最后一行含 'O' 的连通块变为 '.'if (board[0][i] == 'O') dfs(board, 0, i, 'O', '.');if (board[n - 1][i] == 'O') dfs(board, n - 1, i, 'O', '.');}for (int i = 1; i < n - 1; i++) // 将被围绕的 'O' 变为 'X'for (int j = 1; j < m - 1; j++)if (board[i][j] == 'O') board[i][j] = 'X';for (int i = 0; i < n; i++) { // 复原第一列和最后一列的 'O' 连通块if (board[i][0] == '.') dfs(board, i, 0, '.', 'O');if (board[i][m - 1] == '.') dfs(board, i, m - 1, '.', 'O');}for (int i = 0; i < m; i++) { // 复原第一行和最后一行的 'O' 连通块if (board[0][i] == '.') dfs(board, 0, i, '.', 'O');if (board[n - 1][i] == '.') dfs(board, n - 1, i, '.', 'O');}}// 将从 (x, y) 开始的为字符 u 的连通块全部变为 vvoid dfs(vector<vector<char>>& board, int x, int y, char u, char v) {board[x][y] = v;for (int i = 0; i < 4; i++) {int nx = x + dx[i], ny = y + dy[i];if (nx >= 0 && nx < n && ny >= 0 && ny < m && board[nx][ny] == u)dfs(board, nx, ny, u, v);}}
};

![[MySQL] 表的增删查改(查询是重点)](http://pic.xiahunao.cn/nshx/[MySQL] 表的增删查改(查询是重点))



