Efficient Burst Raw Denoising with Stabilization and Multi-Frequency Denoising Network
- Burst Raw Denoising必要性
- Burst Raw Image Denoising流程
- Main Contributions
- 具体方法介绍
- 集成noise prior
- CMOS sensor 噪声建模
- 噪声变换(Variance stabilization)
- 消除ISO对噪声方差的影响
- 消除真实信号值 x ∗ x^* x∗对噪声方差的影响
- 逆变换
- Multi-frame alignment
- Multi-frame denoising
- 整体架构
- 选定参考帧进行单帧降噪
- sequential多帧降噪
- Multi-frequency降噪网络
- 分频率降噪
- 频率聚合模块
- 实验细节
- Loss Function
- 数据集
- 降噪结果
- 消融实验
Burst Raw Denoising必要性
- 移动设备的普及促使移动摄像的需求剧增;
- 由于成本和空间限制,移动设备的sensor孔径和靶面小,导致成像噪声大,特别是在暗光场景;
- 由于噪声的随机性,单帧降噪效果容易丢失图像信号,burst raw denoising可利用时间维度缓解信息丢失的问题;
Burst Raw Image Denoising流程
-
噪声先验处理(noise prior)
camera拍摄参数(shutter,analog gain,digital gain等)根据环境光线变化,导致噪声水平不一致,导致难以处理。一般会基于一些先验知识对输入做变换,使其具备相同noise level。 -
帧对齐(frame alignment)
主要消除运动、抖动引起的前后帧像素位置错位,有助于更好地整合时序信息,提升降噪效果;
-
多帧降噪(multi-frame denoising)
主流方式有两种:
a) 多帧同时输入:运动估计和降噪效果更好,处理速度较快,但算力要求大;
b) 序列处理:按顺序逐帧处理,当前帧denoising的时候以上一帧的信息作为参考,算力消耗比较小;
Main Contributions
这篇论文的工作在noise prior、frame alignment、multi-frame denoising三个层面进行了创新(主要是noise prior和multi-frame denoising,frame alignment是用的某种coarse-to-fine的传统算法):
- noise prior
建模CMOS传感器的噪声,并提出一种方差稳定算法,使网络输入噪声图像的方差保持不变,降低denoising难度,可以在一定程度上降低网络大小和训练难度。 - multi-frame denoising
提出了一个多帧denoising框架,按照frame顺序融合多帧的时间信息,并设计了一个多频去噪网络来有效地处理不同频率的噪声。
具体方法介绍
集成noise prior
深度网络难以同时处理具有多种方差水平的噪声,除非网络设计的很大,但这难以在移动设备上部署。针对这个问题主要有两种解决方法:
- 显式地把噪声水平的先验信息集成到网络输入中;
- 对不同噪声水平的输入进行变换使其具备一样的方差,让网络对输入的噪声水平无感。
本篇论文选择了后者。
CMOS sensor 噪声建模
CMOS sensor的噪声来源主要有两种:
- shot noise
shot noise产生于光子-电子阶段,由于光电效应,sensor收集的光子数呈现随机性,这种随机性服从泊松分布,均值为真实信号值。shot noise与信号值本身相关,属于乘性噪声。 - read noise
read noise产生于电子-电压阶段,是电路的物理误差决定的,可建模为高斯分布,均值为0。与信号值无关,属于加性噪声。
所以,CMOS sensor的噪声可建模为:
x x x~ σ s ∗ P ( x ∗ σ s ) + N ( 0 , σ r 2 ) \sigma_s*P(\frac{x^*}{\sigma_s})+N(0, \sigma_r^2) σs∗P(σsx∗)+N(0,σr2)
x x x是观测值, x ∗ x^* x∗是没有被噪声污染的真实信号值, σ s \sigma_s σs和 σ r \sigma_r σr是噪声参数,和sensor gain(ISO)相关。
所以噪声的方差为:
V a r ( x ) = σ s ∗ x ∗ + σ r 2 Var(x)=\sigma_s*x^*+\sigma_r^2 Var(x)=σs∗x∗+σr2
推导依据:泊松分布的方差等于期望。
因为 σ s \sigma_s σs和 σ r \sigma_r σr只和sensor gain(ISO)相关。所以,当sensor型号固定时,噪声的方差只和ISO与真实信号值 x ∗ x^* x∗有关。噪声方差会随着ISO增加或亮度增加而增大。
噪声变换(Variance stabilization)
通过上面对CMOS sensor的噪声建模,我们知道噪声的方差是由ISO和真实信号值 x ∗ x^* x∗引起的。这一步的目的是对输入的带噪图像进行pixel-wise的处理,变换到一个新的空间,使其始终具备一样的方差,不受ISO和真实信号值 x ∗ x^* x∗影响。
消除ISO对噪声方差的影响
首先消除ISO变化引起的方差变化。令 x ˋ = x σ s \grave{x} = \frac{x}{\sigma_s} xˋ=σsx, x ∗ ˋ = x ∗ σ s \grave{x^*} = \frac{x^*}{\sigma_s} x∗ˋ=σsx∗, σ 2 ˋ = σ r 2 σ s 2 \grave{\sigma^2} = \frac{\sigma_r^2}{\sigma_s^2} σ2ˋ=σs2σr2推导出:
x ˋ \grave{x} xˋ ~ P ( x ∗ ˋ ) + N ( 0 , σ 2 ˋ ) P(\grave{x^*})+N(0, \grave{\sigma^2}) P(x∗ˋ)+N(0,σ2ˋ)
那么, V a r ( x ˋ ) Var(\grave{x}) Var(xˋ)= x ∗ ˋ + σ 2 ˋ \grave{x^*}+\grave{\sigma^2} x∗ˋ+σ2ˋ
消除真实信号值 x ∗ x^* x∗对噪声方差的影响
接下来要消除真实信号值 x ∗ x^* x∗引起的方差变化。
这里应用了Freeman-Tukey变换:
y = x ˋ + σ 2 ˋ + x ˋ + 1 + σ 2 ˋ y=\sqrt{\grave{x}+\grave{\sigma^2}}+\sqrt{\grave{x}+1+\grave{\sigma^2}} y=xˋ+σ2ˋ+xˋ+1+σ2ˋ
经过Freeman-Tukey变换,把原先的Possion-Gaussian分布变换成了高斯分布,且方差为1。
逆变换
噪声输入到denoising网络前经过 x ˋ = x σ s \grave{x} = \frac{x}{\sigma_s} xˋ=σsx和 y = x ˋ + σ 2 ˋ + x ˋ + 1 + σ 2 ˋ y=\sqrt{\grave{x}+\grave{\sigma^2}}+\sqrt{\grave{x}+1+\grave{\sigma^2}} y=xˋ+σ2ˋ+xˋ+1+σ2ˋ两步变换,变成和信号值 x ∗ x^* x∗无关且只有高斯噪声的信号,消除了ISO和 x ∗ x^* x∗引起的方差变化。denoising网络输出后需要进行逆变换,得到最终的denoise结果。
结合前面的变化公式,可推导出逆变换为:
I n v ( y ) = ( y 4 − 2 y 2 + 1 4 y 2 ) ∗ σ s Inv(y)=(\frac{y^{4}-2y^{2} +1}{4y^{2}})*\sigma_s Inv(y)=(4y2y4−2y2+1)∗σs
Multi-frame alignment
这部分不是重点,就简要介绍下。
考虑到计算性能因素,作者没有选择基于深度学习的多帧对齐方法,而是使用了传统的对齐方法:block matched和homography flow。
整体采用金字塔的形式,前两层使用block match进行全局的对齐,后两层使用homography flow进行局部的精细对齐。
Multi-frame denoising
整体架构
多帧去噪阶段需要从burst中聚合时间信息以产生一个帧干净的图像。然而,因为多帧之间的关系可能对建模具有挑战性,同时处理多帧不得不采用大网络。为了避免使用大网络,作者通过一系列高效的子网络按照顺序处理逐帧处理。所有子网络的结构相同,但参数不同的,整体架构如图所示。
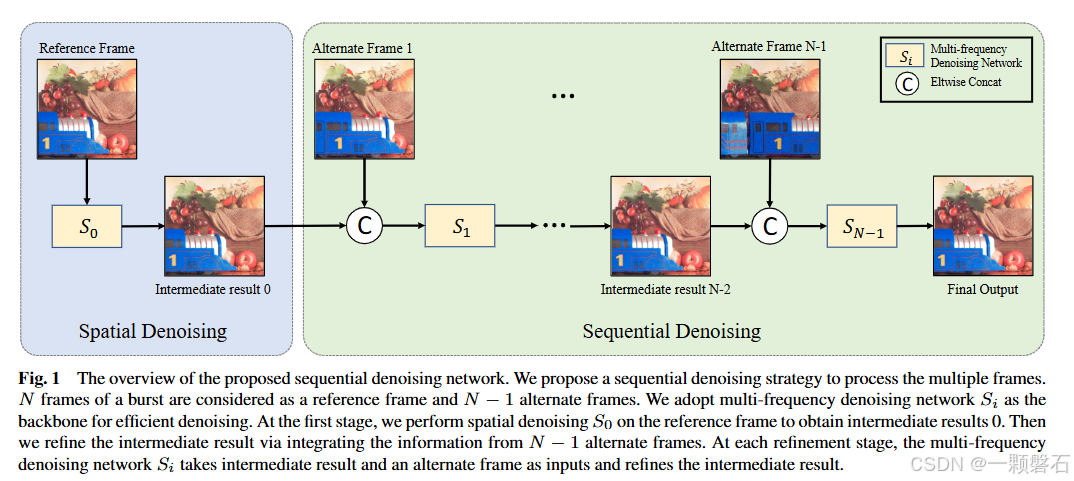
整个降噪过程分为两阶段:
选定参考帧进行单帧降噪
第一步对参考帧执行单帧预去噪,主要有两点好处:
1)单独处理参考帧会强调参考帧相对于其他替代帧的优先级并生成中间结果。在论文实验中也可以观察到,对参考帧做预降噪得到中间结果 I 0 I_0 I0,比直接使用带噪的参考帧表现更好。
2)第一阶段只在参考帧上执行单帧去噪,不需要考虑帧之间的时间关系。因此,为了提高效率,可以采用轻量级网络,降低计算消耗。
sequential多帧降噪
为了降低计算成本,在该阶段按顺序处理剩余的N-1帧。参考帧的单帧去噪产生的中间结果 I 0 I_0 I0经由N−1个独立子网络 S 1 S_1 S1、 S 2 S_2 S2,…, S N − 1 S_{N-1} SN−1依次细化。
具体的数据流向,子网络 S i S_i Si将前一个子网络的中间结果 I i − 1 I_{i-1} Ii−1和第 i i i帧作为输入,生成细化的中间结果 I i I_i Ii。最后,子网络 S N − 1 S_{N−1} SN−1的中间结果 I N − 1 I_{N−1} IN−1作为最终的去噪输出。
这种方式在降低计算成本的同时,也考虑到了相邻帧之间的时间信息,而且逐帧细化的方式也会输出更好的降噪结果。
Multi-frequency降噪网络
去噪神经网络通常擅长去除高频噪声,但在处理低频噪声方面表现的不是特别好。因此,子网络将整个图像的去噪拆分为多个频率域的去噪,每个子网络由多频去噪和多频聚合模块组成,结构如图所示:
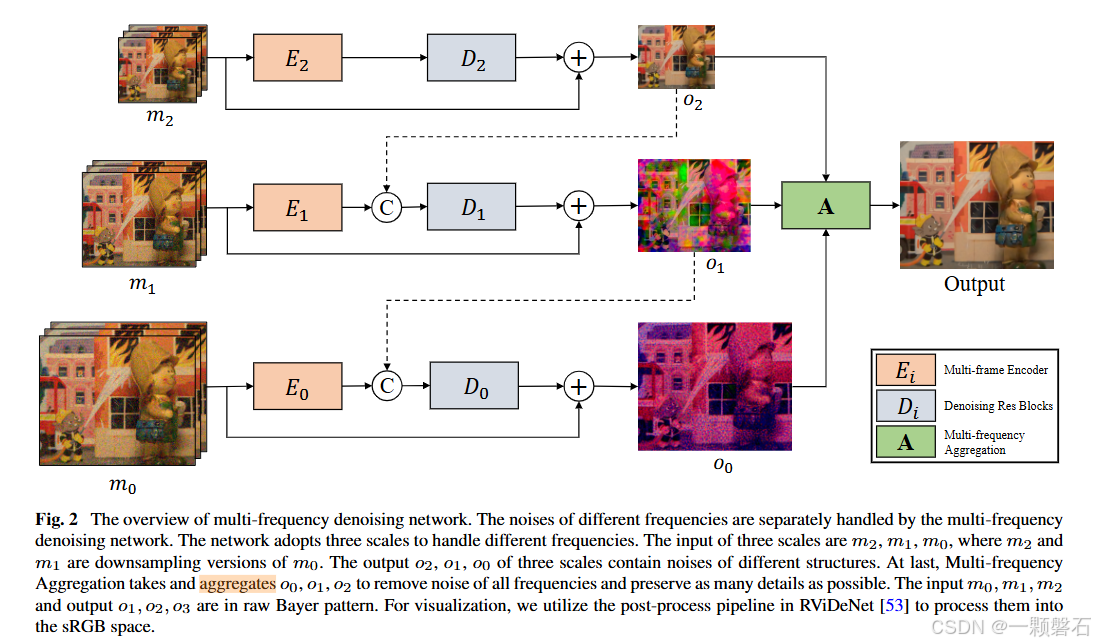
分频率降噪
首先,对输入做两次down-sample,每次分辨率缩小为原来的 1 4 \frac{1}{4} 41,得到三种分辨率的input map:{ m 0 , m 1 , m 2 m^0, m^1, m^2 m0,m1,m2}。
同一种pattern的噪声,在不同分辨率的input map中所表现的频率也不一样。当前分辨率的低频噪声在下一级input map中就表现为高频了(因为每down-sample一次,就会remove一些高频分量)。
在input map的 s c a l e = i scale=i scale=i,即输入为 m i m^i mi时,负责该scale的降噪子网络记为 F i F^i Fi, F i F^i Fi由 E i E^i Ei和 D i D^i Di组成,该scale的输出为 O i O^i Oi, F i F^i Fi学习的是残差。
O i = D i ( E i ( m i ) ) + m i O^i=D^i(E^i(m^i))+m^i Oi=Di(Ei(mi))+mi
从上图可以看出,除最上层之外, D i D^i Di的输入不仅有 E i ( m i ) E^i(m^i) Ei(mi),还有上一层的输出 O i + 1 O^{i+1} Oi+1,具体地有:
O 2 = D 2 ( E 2 ( m 2 ) ) + m 2 O^2=D^2(E^2(m^2))+m^2 O2=D2(E2(m2))+m2
O 1 = D 1 ( c o n c a t ( E 1 ( m 1 ) , O 2 ) ) + m 1 O^1=D^1(concat(E^1(m^1),O^2))+m^1 O1=D1(concat(E1(m1),O2))+m1
O 0 = D 0 ( c o n c a t ( E 0 ( m 0 ) , O 1 ) ) + m 0 O^0=D^0(concat(E^0(m^0),O^1))+m^0 O0=D0(concat(E0(m0),O1))+m0
相当于先在 m 2 m^2 m2层级,去除图像中的低频噪声,得到 O 2 O^2 O2;
然后在 m 1 m^1 m1层级,基于去除低频噪声的 O 2 O^2 O2,继续去除中频噪声,得到 O 1 O^1 O1;
最后,在 m 0 m^0 m0层级,基于去除中频噪声的 O 1 O^1 O1,继续去除高频噪声,得到 O 0 O^0 O0。
频率聚合模块
经过多频降噪网络,得到去除掉高、中、低频噪声的干净频率分量{ O 0 , O 1 , O 2 O^0,O^1,O^2 O0,O1,O2},需要把各分量组合起来得到完整的降噪结果。
n 1 = ↓ ( O 0 ) − O 1 n^1=\downarrow ({O^0})-O^1 n1=↓(O0)−O1
n 2 = ↓ ( O 1 ) − O 2 n^2=\downarrow ({O^1})-O^2 n2=↓(O1)−O2
I = O 0 − ↑ ( n 1 ) − ↑ ( ↑ ( n 2 ) ) I=O^0-\uparrow(n^1)-\uparrow(\uparrow(n^2)) I=O0−↑(n1)−↑(↑(n2))
n 1 n^1 n1相当于 O 0 O^0 O0里残留的中频噪声, n 2 n^2 n2相当于 O 1 O^1 O1里残留的低频噪声,在 O 0 O^0 O0里把 n 1 n^1 n1和 n 2 n^2 n2减掉,就得到了干净的图像。
实验细节
Loss Function
训练使用的损失函数主要是L1,包括RAW域的L1 loss和RGB域的L1 loss,除此之外,还有一项梯度约束项。
L r = L 1 ( y ∗ , y ^ ) + w 1 ∗ L 1 ( ▽ y ∗ , ▽ y ^ ) + w 2 ∗ L 1 ( I S P ( I n v ( y ∗ ) , I S P ( I n v ( y ^ ) ) ) ) L_r=L_1(y^*,\hat{y})+w1*L_1(\bigtriangledown y^*,\bigtriangledown {\hat{y}})+w2*L_1(ISP(Inv(y^*),ISP(Inv(\hat{y})))) Lr=L1(y∗,y^)+w1∗L1(▽y∗,▽y^)+w2∗L1(ISP(Inv(y∗),ISP(Inv(y^))))
数据集
CRVD和KPN synthetic dataset。这两个数据集包含了复杂多样的RAW数据,涉及到不同sensor,不同ISO,不同场景等,可以反映模型的降噪效果以及泛化性。
降噪结果


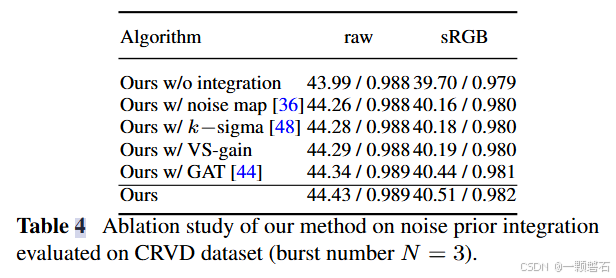
消融实验
)



)

