MySQL 日志是保障数据库可靠性、可恢复性以及数据一致性的关键组件。不同类型的日志在数据库的运行过程中扮演着各自独特的角色,从记录事务操作到实现故障恢复,从支持主从复制到确保数据原子性与持久性,它们共同协作,维持着数据库系统的稳定运转。
核心日志组件及其作用
| 日志类型 | 所属层级 | 核心功能 | 关键特性 |
|---|---|---|---|
| Undo Log | 存储引擎层 | 事务回滚/MVCC支持 | 逻辑日志,链式结构 |
| Redo Log | 存储引擎层 | 崩溃恢复/数据持久化 | 物理日志,循环写入 |
| Binlog | Server层 | 主从复制/时间点恢复 | 逻辑日志,追加写入 |
| Error Log | Server层 | 错误信息记录 | 文本格式,问题诊断 |
| Slow Query Log | Server层 | 慢查询记录 | 性能优化依据 |
| General Log | Server层 | 全量查询记录 | 审计与调试 |
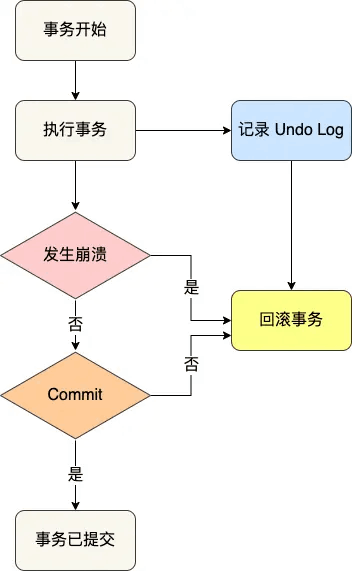
undo log 回滚日志
原理
undo log 回滚日志用于记录事务更新前的数据,其核心数据结构支持事务回滚与多版本并发控制(MVCC)。
-
roll_pointer是关键,它存在于每个数据行的隐藏列中,指向数据的上一版本,形成版本链。通过这个版本链,数据库能追踪数据历史版本,满足事务回滚和 MVCC 查询的需求。 -
undo log 记录包含
trx_id(事务 ID)和undo_no(日志序号)。trx_id唯一标识修改数据的事务,undo_no为每条日志赋予唯一编号,用于排序管理。 -
事务修改数据时,生成的 undo log 记录含修改前数据、
trx_id和undo_no,并通过roll_pointer连接版本链。事务回滚时,数据库依据版本链和undo_no回溯到初始状态,实现原子性。 -
在 MVCC 中,不同事务结合
trx_id和自身 Read View 判断数据可见性。Read View 含活跃事务信息,事务比较trx_id决定是否访问数据版本,不满足则沿版本链查找。
功能
undo log 在多版本并发控制(MVCC)中也起着关键作用。它为每个事务生成数据的历史版本,不同事务根据自身的 Read View 判断数据的可见性,从而实现并发事务之间的隔离。
生命周期与管理
undo log 在事务开始时产生,随着事务对数据的修改,不断记录相应的回滚信息。当事务提交后,undo log 并不会立即删除,而是进入 purge 阶段。在此阶段,数据库会根据 undo log 的使用情况,判断是否可以回收其占用的空间。这是因为在事务提交后,可能仍有其他事务依赖该 undo log 来实现 MVCC 相关功能。
为了有效管理 undo log,MySQL 会设置一些参数,如 innodb_undo_logs 用于控制 undo log 文件的数量,innodb_undo_tablespaces 用于指定 undo log 表空间等。
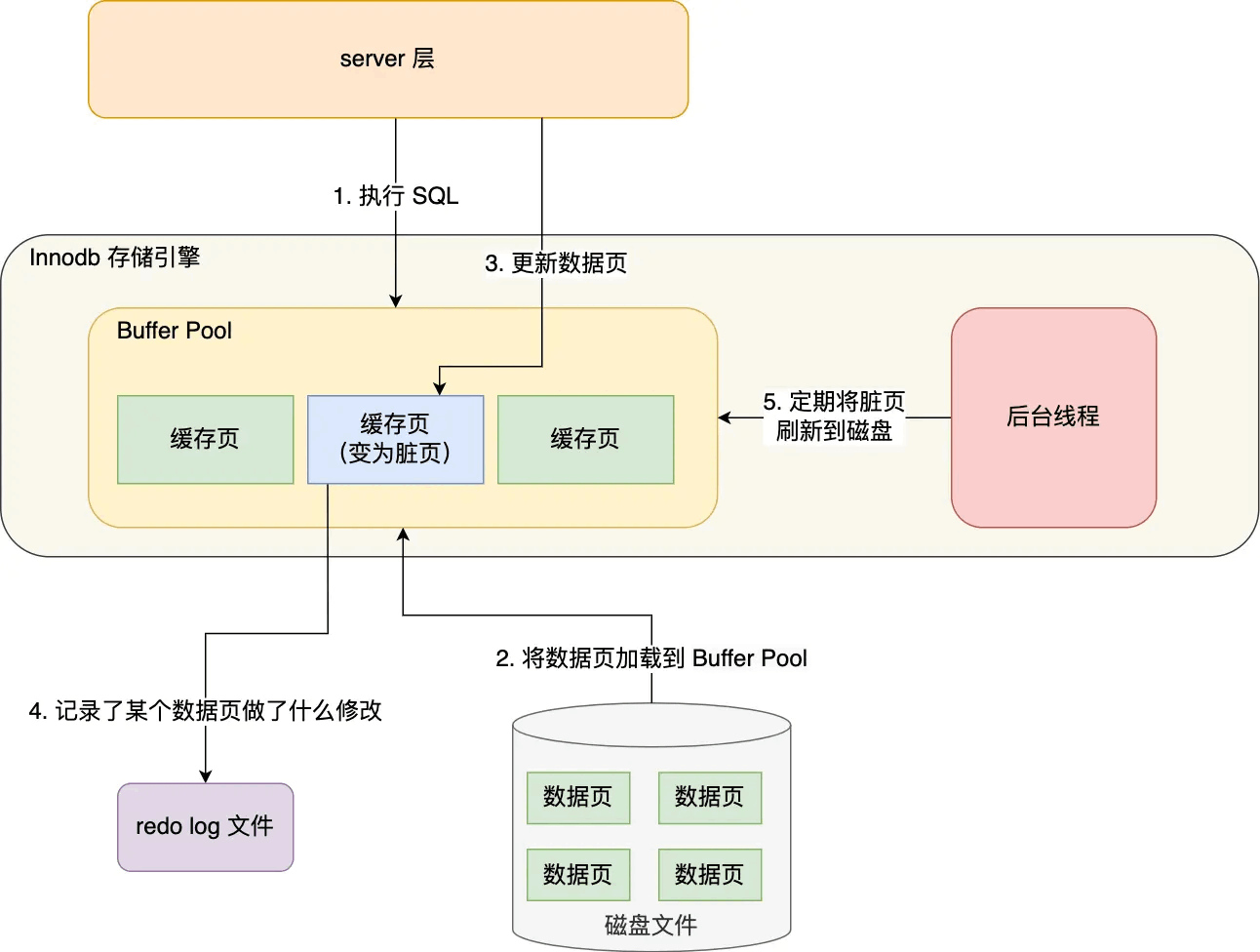
redo log 重做日志
原理
redo log 记录事务更新后的数据,主要用于故障恢复,实现事务的持久性。当事务提交时,相关的修改会先写入 redo log,然后再将数据写入磁盘。这种先写日志再写数据的方式称为 Write - Ahead Logging(WAL)。
WAL 技术(Write-Ahead Logging)
- 所有数据修改先写日志
- 日志必须持久化后才返回成功
- 数据页可以延迟写入(脏页刷盘)
WAL 的优点显著。一方面,它保证了数据的一致性,即使在系统崩溃或出现故障的情况下,也能通过 redo log 中的记录将数据恢复到正确状态。另一方面,它将随机写转化为顺序写,大大提升了性能。因为磁盘的顺序写速度远快于随机写,通过将对数据页的修改先记录到 redo log 中,再批量写入磁盘,减少了磁盘 I/O 的开销。
log buffer
log buffer 是内存中用于存储 redo log 数据的区域。在事务执行过程中,redo log 记录首先被写入 log buffer,然后再批量写入磁盘。这种方式进一步减少了磁盘 I/O 操作,提升了数据库性能。
MySQL 提供了一些参数来控制 log buffer 的行为,如 innodb_log_buffer_size 用于设置 log buffer 的大小。
binlog 归档日志
作用
binlog 由 server 层产生,通过追加写的方式记录已提交的事务。它主要用于备份恢复以及主从复制场景。在主从复制架构中,主库将事务写入 binlog,然后提交事务并更新本地存储数据。
主从同步
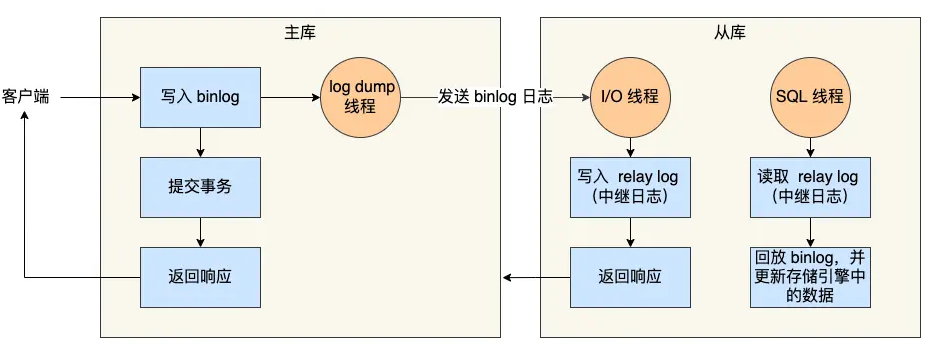
- 主库写入 binlog。
- 从库 I/O 线程读取 binlog 并写入本地 relay log。
- 从库 SQL 线程重放 relay log,完成数据同步。
主从复制模型
- 同步复制:主库在执行事务并写入 binlog 后,会同步等待所有从库确认收到数据。只有当所有从库都确认接收后,主库才会提交事务。最大程度保证主从数据的一致性,但会增加主库的等待时间,降低系统的并发性能。
- 异步复制:主库不需要等待从库的响应,在写入 binlog 并提交事务后,就继续处理后续事务。并发性能高,但存在一定风险,若主库在从库接收 binlog 之前出现故障,可能导致主从数据不一致。
- 半同步复制:主库等待至少一个从库确认收到数据后,就提交事务。兼顾了数据一致性和并发性能,是一种较为常用的主从复制模式。
日志的两阶段提交
原因
两阶段提交主要是为了避免 redo log 或 binlog 只有一者写入磁盘成功,导致主从不一致问题。在分布式系统或涉及主从复制的场景中,若不采用两阶段提交,可能会出现 redo log 提交成功但 binlog 写入失败,或者反之的情况,这将导致主从数据库之间的数据不一致。
执行流程
- prepare 阶段:将 redo log 对应事务设置为 prepare 状态,并将 redo log 刷新到磁盘。此时,事务虽然还未正式提交,但已经做好了提交的准备,确保了 redo log 的持久性。
- commit 阶段:将 binlog 刷新到磁盘,然后再将 redo log 设置为 commit 状态。这样就保证了 redo log 和 binlog 都成功写入磁盘,实现了主从数据的一致性。
:将 binlog 刷新到磁盘,然后再将 redo log 设置为 commit 状态。这样就保证了 redo log 和 binlog 都成功写入磁盘,实现了主从数据的一致性。
参考资料:小林coding
(五))

)


