贝叶斯方法是一种统计推断的 方法,它利用贝叶斯定理来更新我们对事件概率的信念。这种方法在机器学习和数据 分析中得到广泛应用,特别是在分类和概率估计问题上。
一、数据集介绍
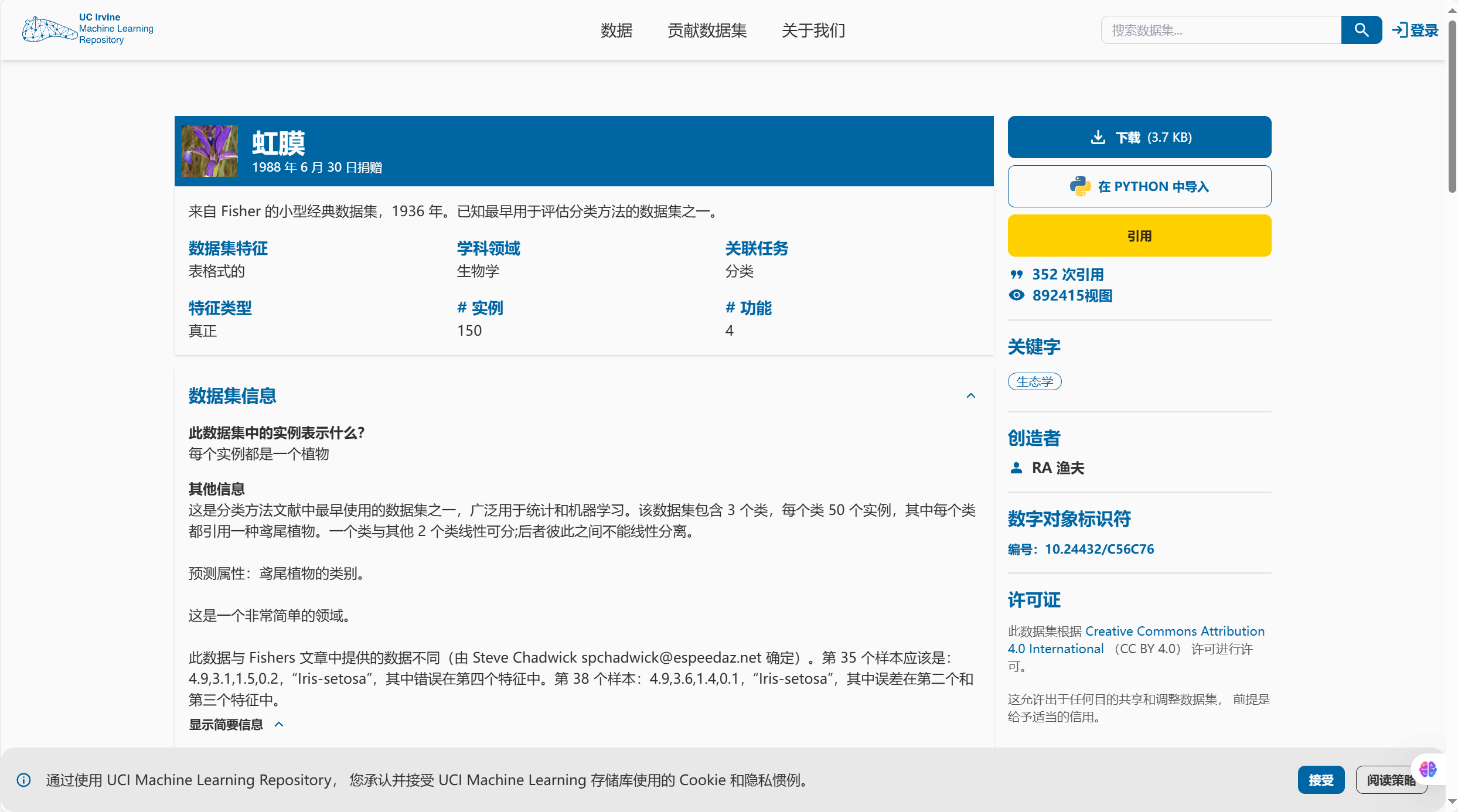
这是分类方法文献中最早使用的数据集之一,广泛用于统计和机器学习。该数据集包含 3 个类,每个类 50 个实例,其中每个类都引用一种鸢尾植物。一个类与其他 2 个类线性可分;后者彼此之间不能线性分离。 预测属性:鸢尾植物的类别。
数据集地址
Iris - UCI 机器学习存储库
| 变量名称 | 角色 | 类型 | 描述 | 单位 | 缺失值 |
|---|---|---|---|---|---|
| 萼片长度 | 特征 | 连续的 | 厘米 | 不 | |
| 萼片宽度 | 特征 | 连续的 | 厘米 | 不 | |
| 花瓣长度 | 特征 | 连续的 | 厘米 | 不 | |
| 花瓣宽度 | 特征 | 连续的 | 厘米 | 不 | |
| 类 | 目标 | 分类 | 鸢尾植物类:山鸢尾-- 变色鸢尾-- 弗吉尼亚鸢尾 | 不 |
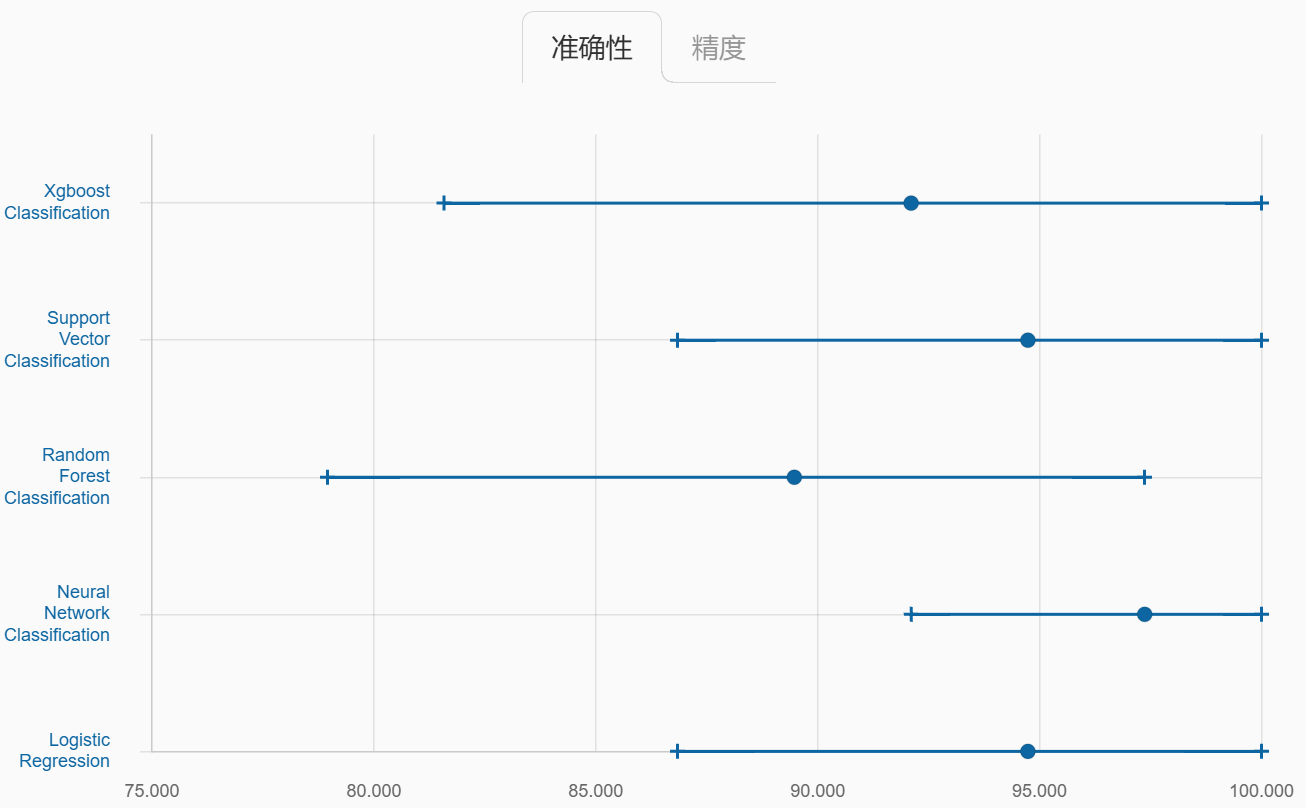
二、基准模型性能

三、设计思路
3.1、读取数据集
import pandas as pd
df=pd.read_csv('./dataset/iris.data',names=['萼片长度','萼片宽度','花瓣长度','花瓣宽度','类'])
df.head()
3.2、划分特征
X=df.drop(columns='类')
y=df['类']3.3、划分数据集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,train_size=0.75,random_state=42)3.4、标准化
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
X_train_scaler=scaler.fit_transform(X_train)
X_test_scaler=scaler.transform(X_test)3.5、模型的构建,训练,预测
from sklearn.naive_bayes import GaussianNB
gb=GaussianNB()
gb.fit(X_train,y_train)
y_pred=gb.predict(X_test)3.6、模型评估
模型训练完成后,我们对模型的性能进行评估。我们使用测试集进行预测,并计算准 确率、混淆矩阵和分类报告等指标来了解模型的表现。
准确度 (Accuracy):准确度是正确预测的样本数与总样本数之比。
混淆矩阵(Classification Report): 混淆矩阵显示了模型的分类情况。对角线上的元素表示正确分类的样本数,而非对角 线上的元素表示错误分类的样本数。例如,29个类别一被正确分类,而5个类别二被 错误分类成类别三。
分类报告 (Classification Report):
分类报告提供了更详细的性能指标,包括精度(precision)、召回率(recall)、F1分数 (f1-score)等。
对于“Iris-setosa”类别,精度为100%,召回率为100%,F1分数为100%。
对于“Iris-versicolor”类别,精度为100%,召回率为100%,F1分数为100%。
宏平均 (macro avg) 和加权平均 (weighted avg) 提供了整体性能的总结。在这个 情况下,宏平均的精确度分数为100%,加权平均的精确度分数为100%;宏平均的 召回率分数为100%,加权平均的召回率分数为100%;宏平均的F1分数为100%,加 权平均的F1分数为100%。这些指标是所有类别性能的平均值。
from sklearn.metrics import accuracy_score,confusion_matrix,classification_report
# 准确率:计算分类模型的准确率,也可以计算准确个数
accuracy = accuracy_score(y_test, y_pred)# 混淆矩阵:可以直观的展示分类模型在各个类别上的预测情况。
# 返回一个二维数组(也就是混淆矩阵),矩阵的行表示真实类别,矩阵的列表示预测类别
conf_matrix = confusion_matrix(y_test, y_pred)# 真反例:实际类别是反例,模型预测也是反例。
# 精准率:指该类别被正确预测的样本数(真正例)与所有被预测为该类别的样本数(假正例)。 真正例/(真正例+假正例)
# 召回率:指该类别被正确预测的样本数(真正例)与所有实际属于该类别的样本数(假反例)。 真正例(真正例+假反例)
# f1值:精准率与召回率的调和平均数 : 2 * pre * recall / (pre + recall)
# 支持度:指每个类别在真实标签中出现的样本数量
# 宏平均:对各个类别指标(pre、recall、f1)的简单平均
# 加权平均:根据每个类别的支持度对每个类别指标进行加权平均
class_report = classification_report(y_test, y_pred)print(f'Accuracy: {accuracy}')
print(f'Confusion Matrix: \n{conf_matrix}')
print(f'Classfication Report: \n{class_report}')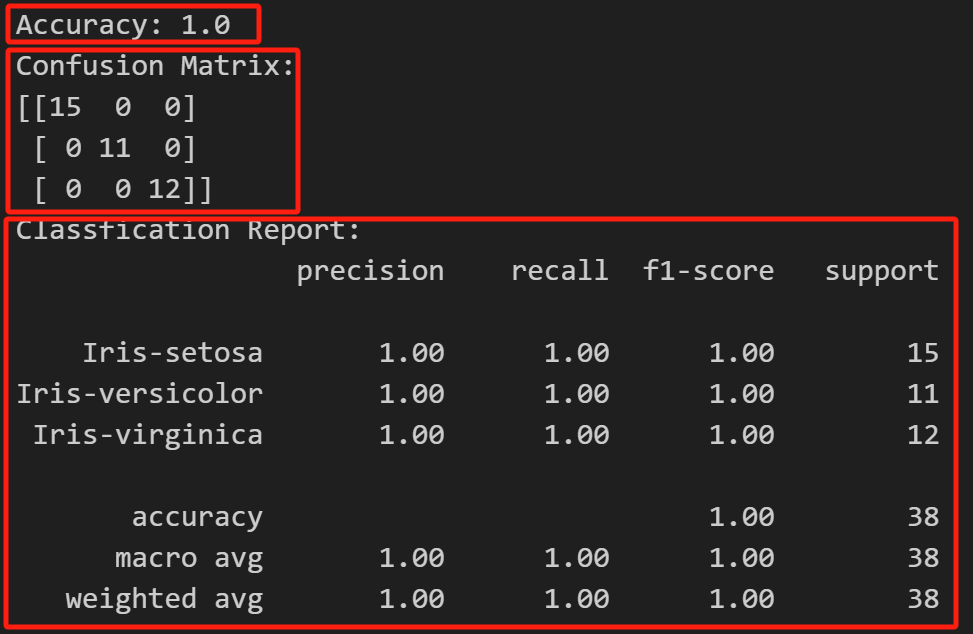
3.7、可视化
使用t-SNE对SVM模型的决策函数结果进行降维,创建散点图进行可视 化,以便更直观地理解模型在二维空间中的预测结果。
from matplotlib import pyplot as plt
from sklearn.manifold import TSNE
from sklearn.preprocessing import LabelEncoder
# 数据可视化,降维 使用t-sne算法进行降维操作,将特征讲到2维,方便可视化
tsne = TSNE(n_components=2)
x_tsne = tsne.fit_transform(X_test_scaler)# 将字符串标签转换为数值标签,方便画图
label_encoder = LabelEncoder()
y_test_numeric = label_encoder.fit_transform(y_pred)# 绘制图像
plt.figure(figsize=(8, 6))
scatter = plt.scatter(x_tsne[:, 0], x_tsne[:, 1], c=y_test_numeric, cmap='viridis')
plt.title('t-SNE Visualization of naive_bayes Predictions')
plt.legend(*scatter.legend_elements(), title='Classes')
plt.show()

四、完整代码
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.manifold import TSNE
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report # 加载鸢尾花数据集,并为列指定名称
df = pd.read_csv('./dataset/iris.data', names=['萼片长度', '萼片宽度', '花瓣长度', '花瓣宽度', '类'])
print(df.head()) # 显示数据集的前几行以便检查 # 划分特征(X)和标签(y)
X = df.drop(columns='类') # 特征:除了'类'以外的所有列
y = df['类'] # 标签:'类'列 # 将数据集分为训练集和测试集,训练集占75%
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.75, random_state=42) # 对特征进行标准化,去除均值并缩放到单位方差
scaler = StandardScaler()
X_train_scaler = scaler.fit_transform(X_train) # 拟合训练数据并转换
X_test_scaler = scaler.transform(X_test) # 转换测试数据 # 初始化并训练高斯朴素贝叶斯分类器
gb = GaussianNB()
gb.fit(X_train, y_train) # 用训练数据拟合模型
y_pred = gb.predict(X_test) # 对测试集进行预测 # 准确率:计算分类模型的准确率,也可以计算准确个数
accuracy = accuracy_score(y_test, y_pred) # 计算模型准确率 # 混淆矩阵:可以直观展示分类模型在各个类别的预测情况
# 返回二维数组(混淆矩阵),行表示真实类别,列表示预测类别
conf_matrix = confusion_matrix(y_test, y_pred) # 计算混淆矩阵 # 真反例:实际类别是反例,模型预测也是反例
# 精准率:该类别正确预测的样本数(真正例)与所有被预测为该类别的样本数(假正例)之比
# 召回率:该类别正确预测的样本数(真正例)与所有实际属于该类别的样本数(假反例)之比
# f1值:精准率与召回率的调和平均数:2 * (pre * recall) / (pre + recall)
# 支持度:每个类别在真实标签中出现的样本数量
# 宏平均:对各类别指标(pre、recall、f1)的简单平均
# 加权平均:根据每个类别的支持度对每个类别指标进行加权平均
class_report = classification_report(y_test, y_pred) # 生成分类报告 print(f'准确率: {accuracy}') # 打印模型的准确率
print(f'混淆矩阵: \n{conf_matrix}') # 打印混淆矩阵
print(f'分类报告: \n{class_report}') # 打印分类报告 # 数据可视化,降维,使用t-SNE算法进行降维处理,将特征转为二维,方便可视化
tsne = TSNE(n_components=2) # 初始化t-SNE,用于2D可视化
x_tsne = tsne.fit_transform(X_test_scaler) # 拟合并转换测试集 # 将字符串标签转换为数值标签,方便绘图
label_encoder = LabelEncoder()
y_test_numeric = label_encoder.fit_transform(y_pred) # 将预测标签转换为数值型以便绘图 # 绘制图像
plt.figure(figsize=(8, 6)) # 创建绘图的画布
scatter = plt.scatter(x_tsne[:, 0], x_tsne[:, 1], c=y_test_numeric, cmap='viridis') # 绘制t-SNE结果的散点图
plt.title('t-SNE可视化朴素贝叶斯预测结果') # 设置图表标题
plt.legend(*scatter.legend_elements(), title='类别') # 添加类别图例
plt.show() # 显示图表 )



——3.4指令类型)
