利用IDEA开发Spark-SQL
示例
- 创建子模块Spark-SQL,并添加依赖
<dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>3.0.0</version></dependency></dependencies>2.创建Spark-SQL的测试代码:
import com.sun.rowset.internal.Row
import org.apache.spark.{SparkConf, sql}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}case class User(id:Int,name:String,age:Int)
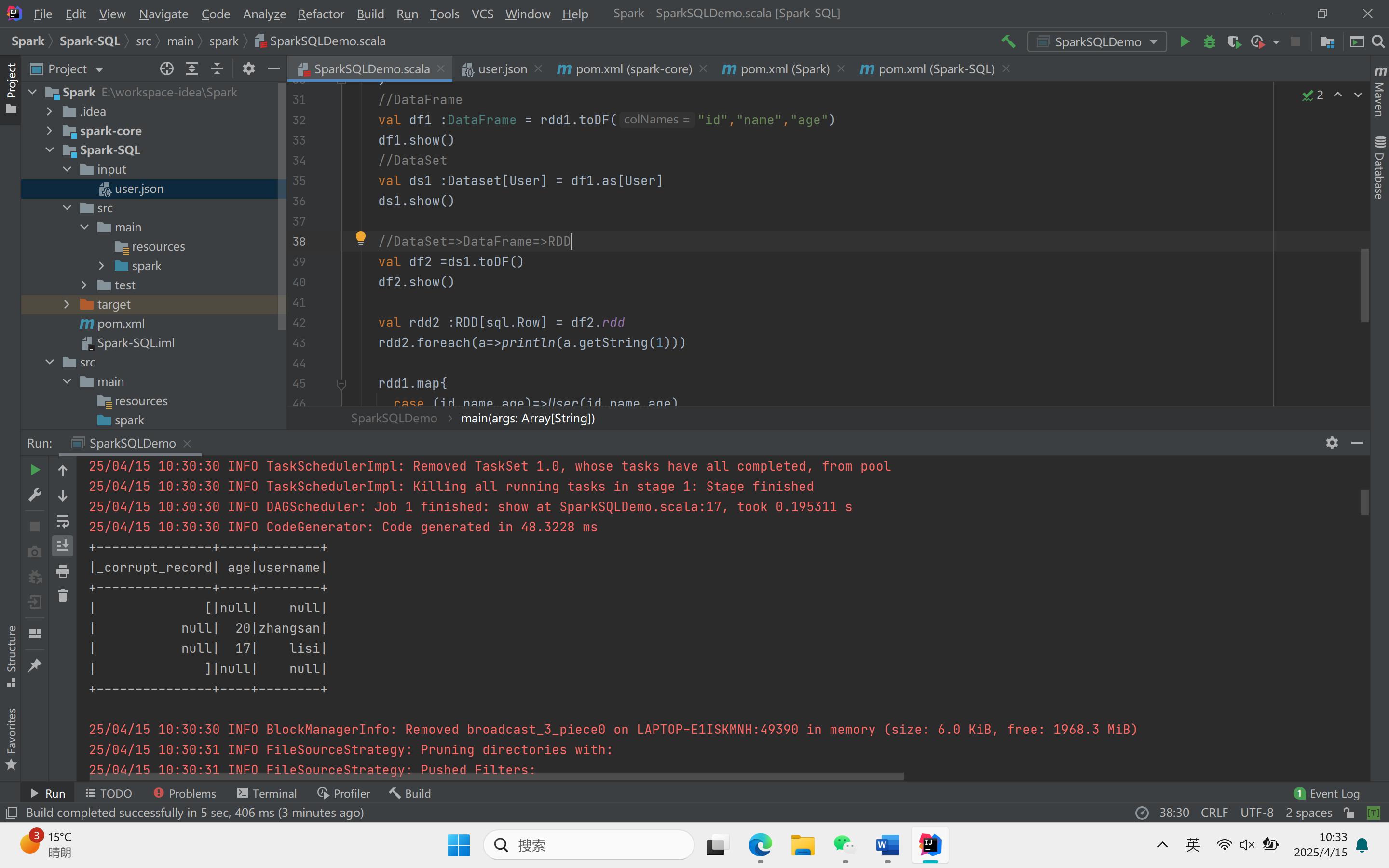
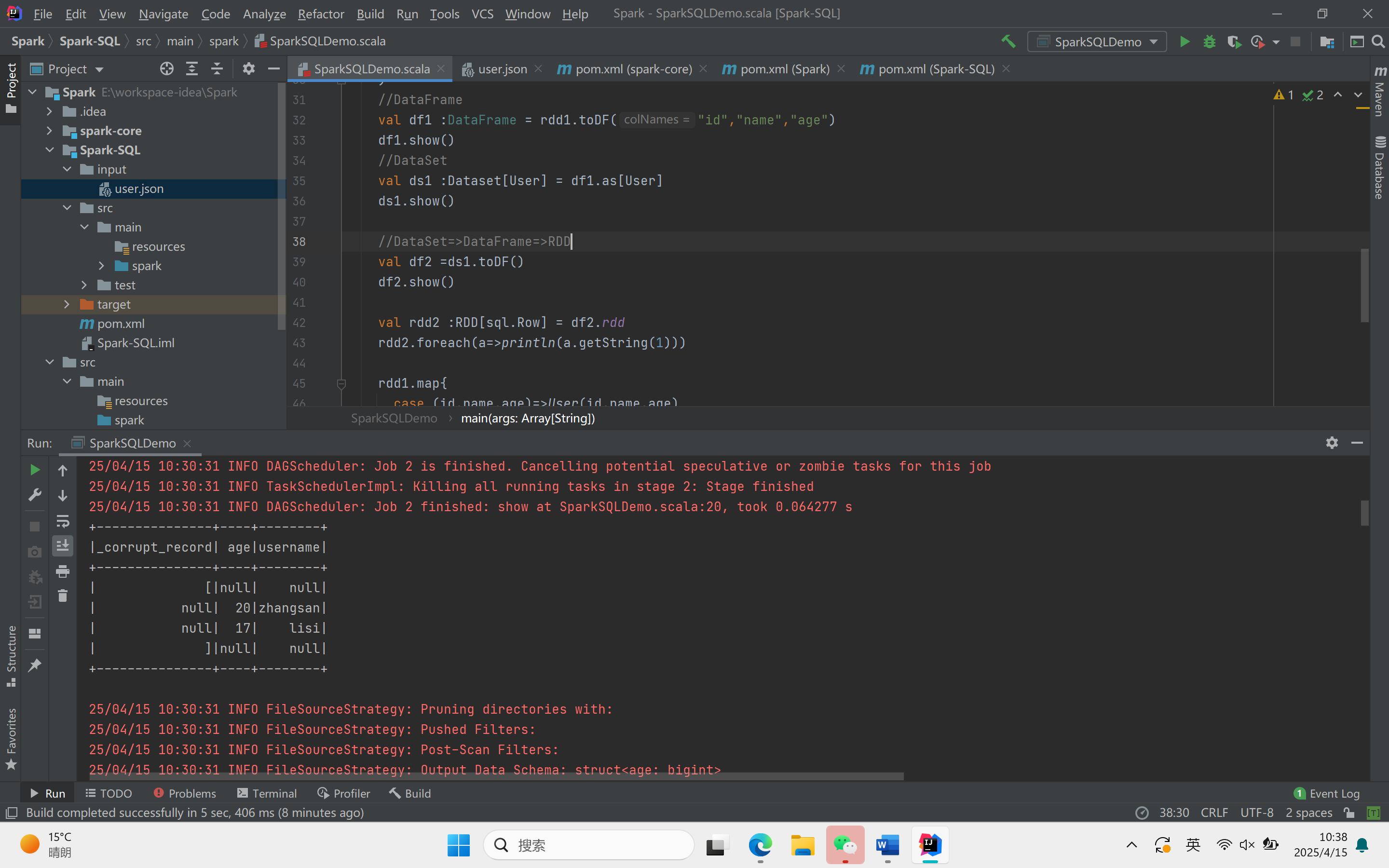
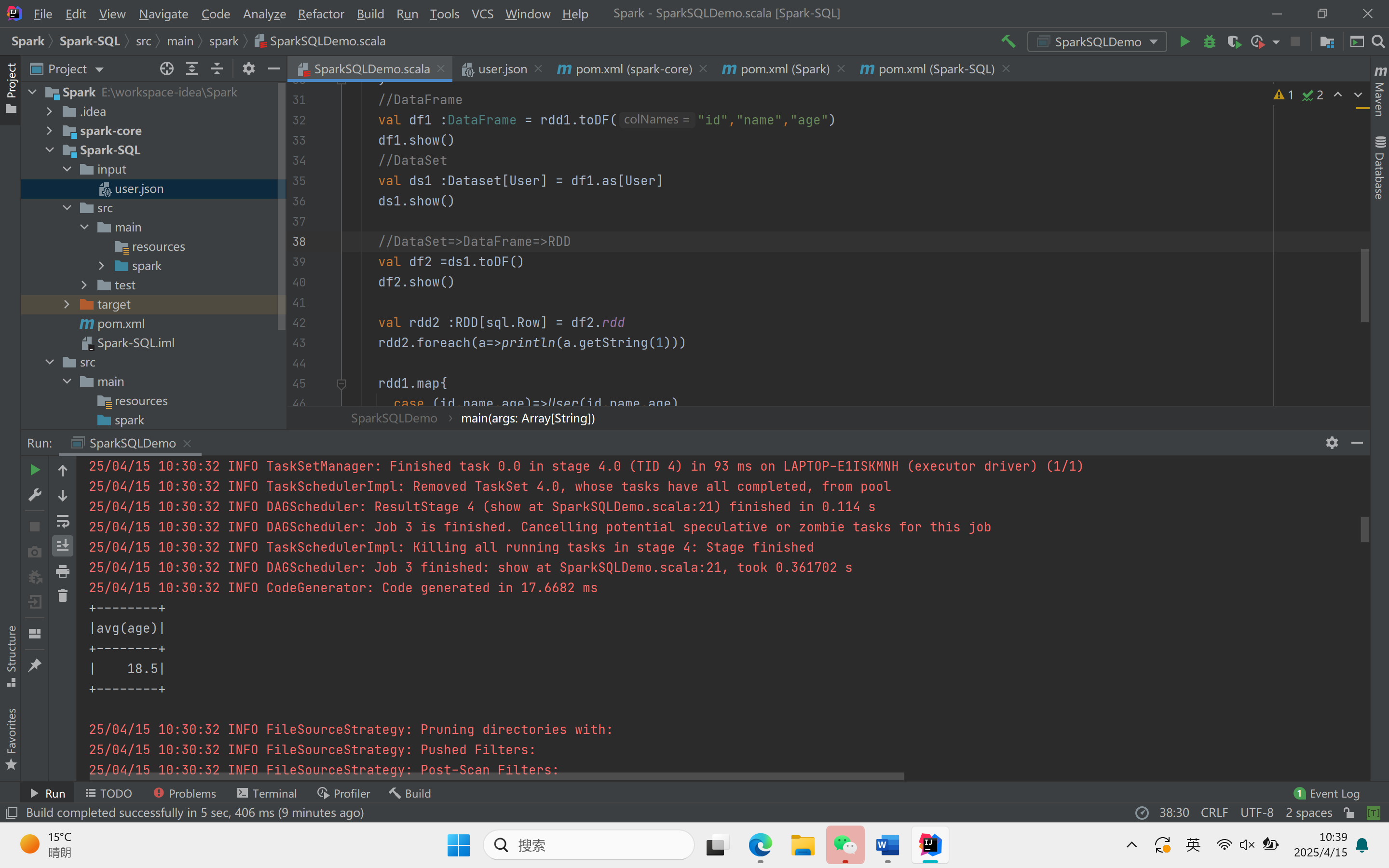
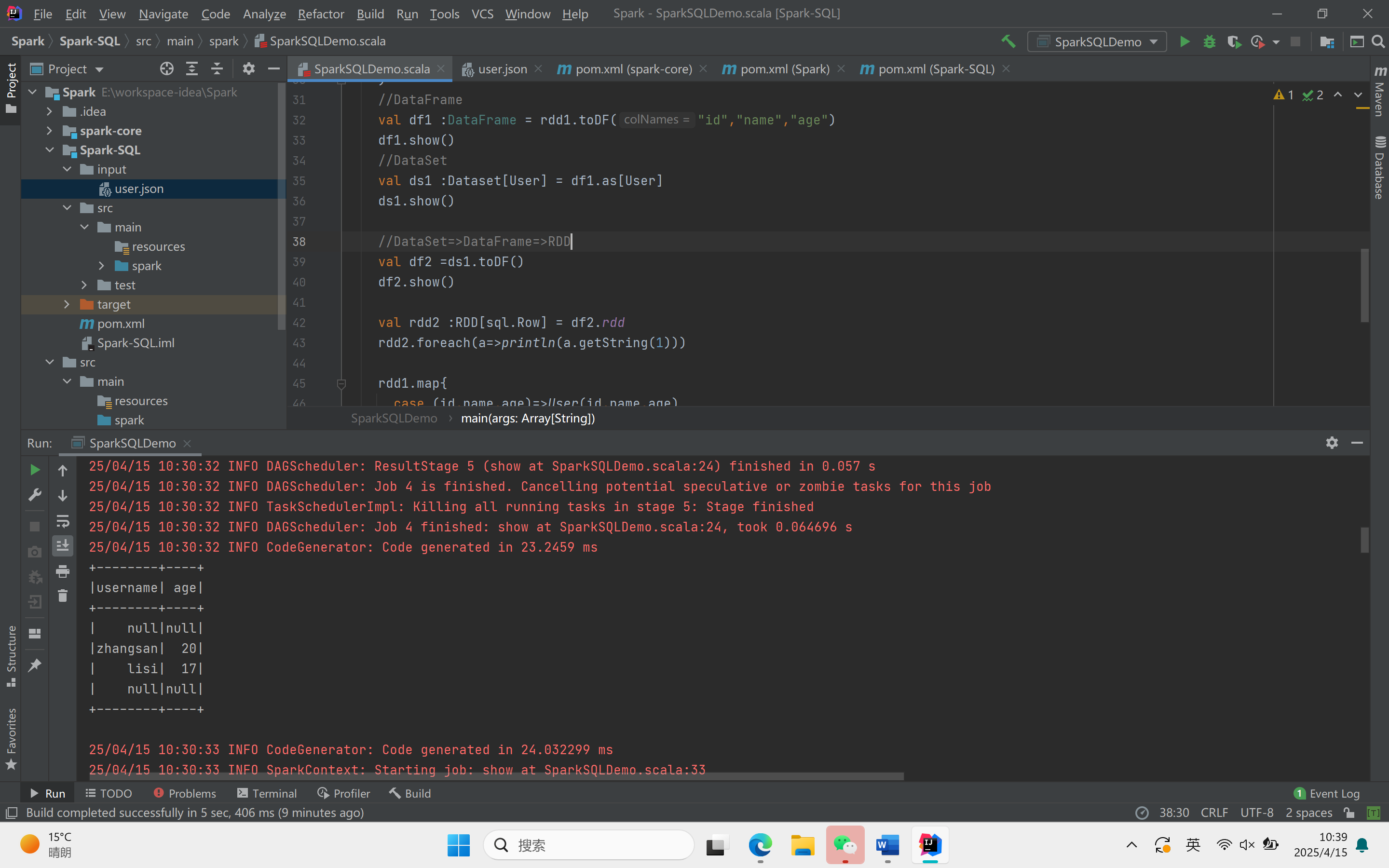
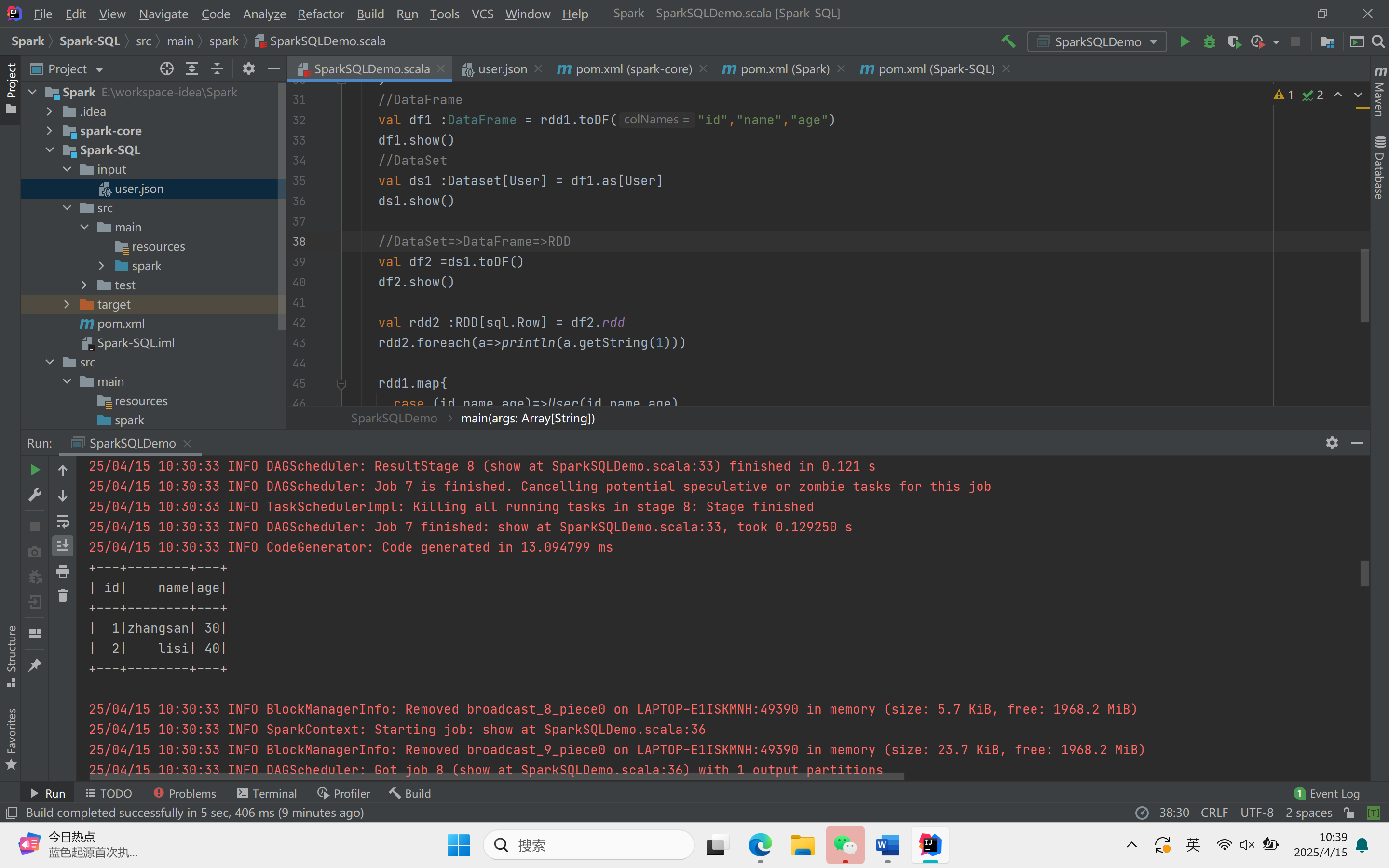
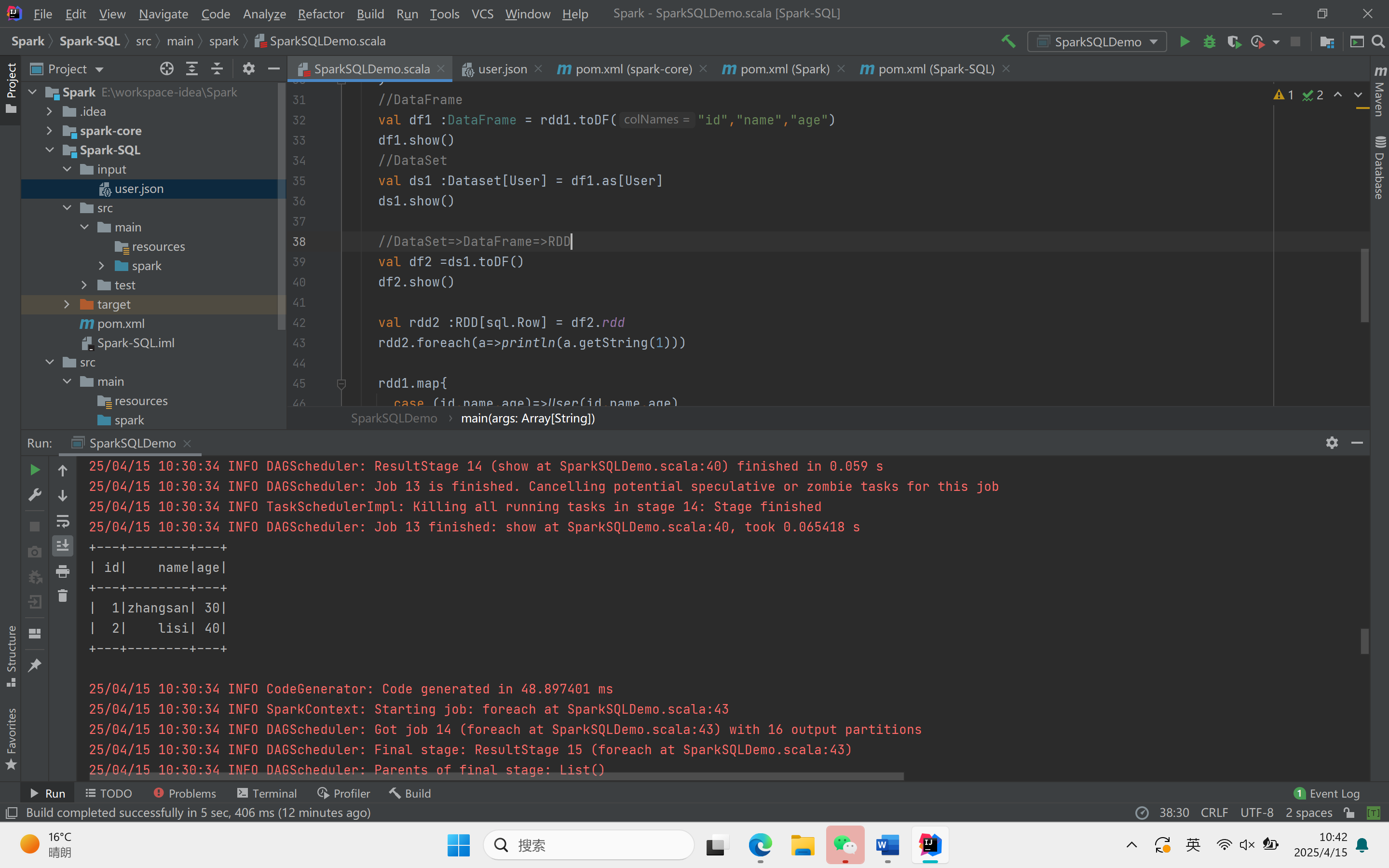
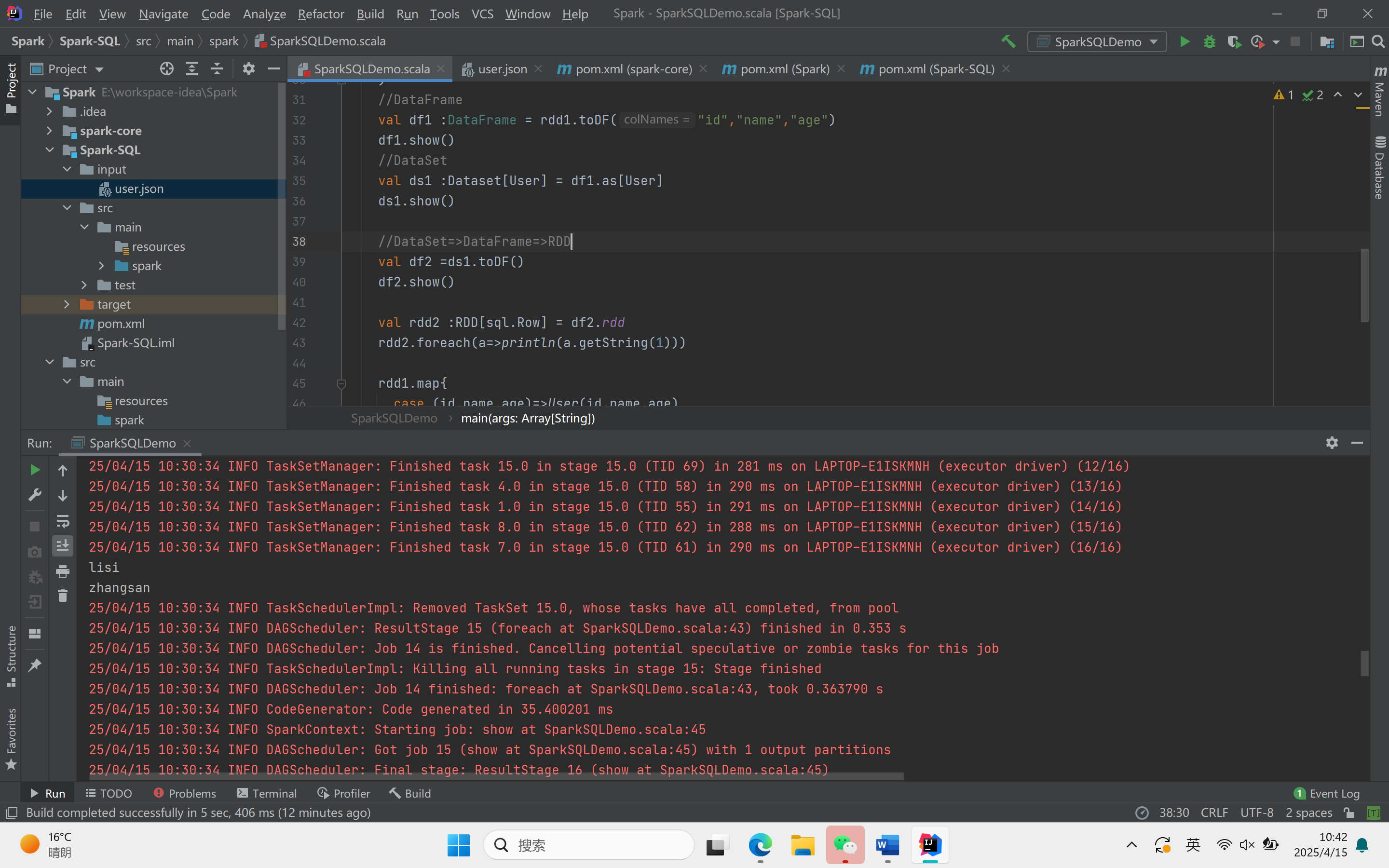
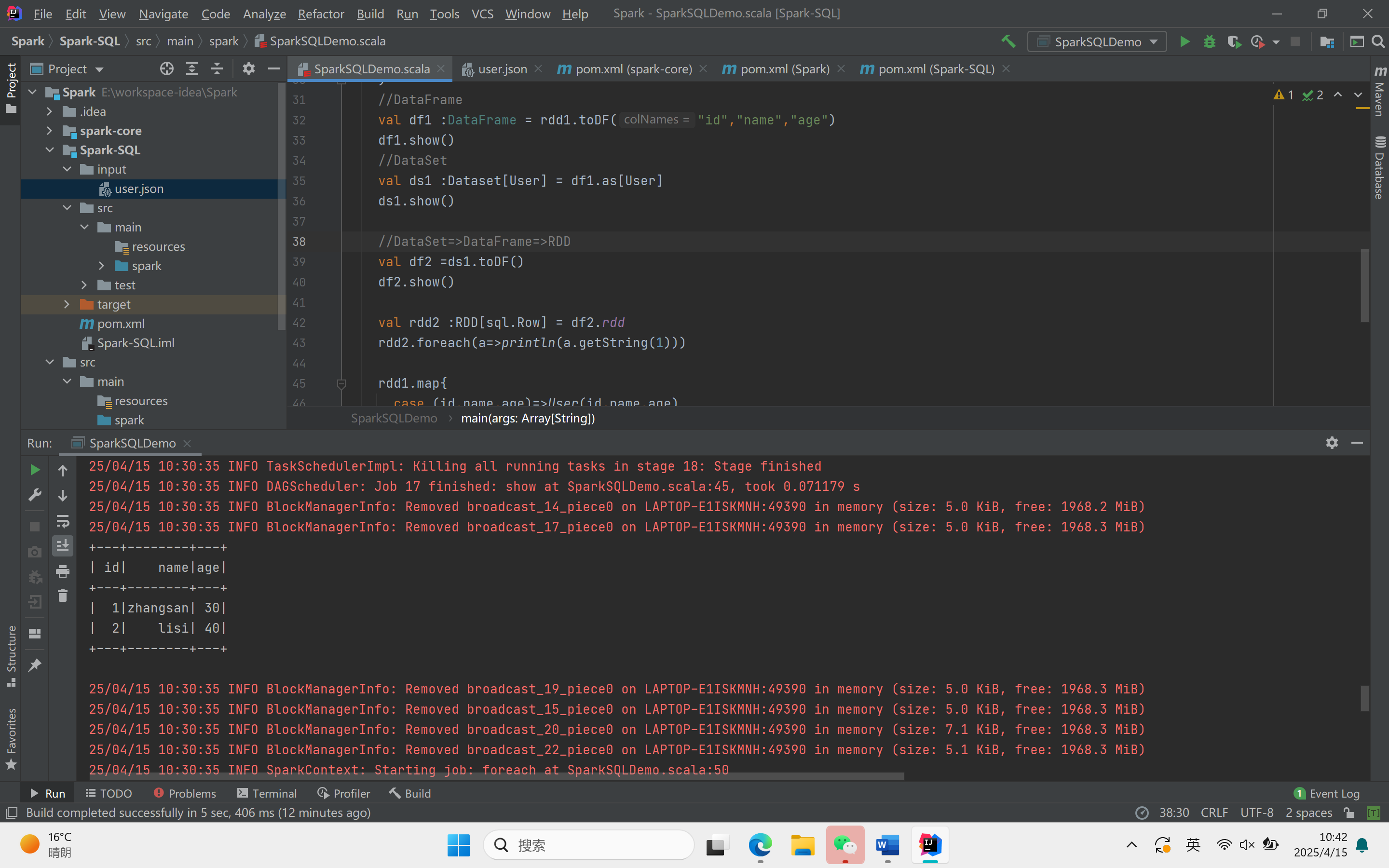
object SparkSQLDemo {def main(args: Array[String]): Unit = {//创建上下文环境配置对象val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SQLDemo")//创建SparkSession对象val spark :SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()import spark.implicits._//读取json文件val df : DataFrame = spark.read.json("Spark-SQL/input/user.json")df.show()//SQL风格语法df.createOrReplaceTempView("user")spark.sql("select * from user").showspark.sql("select avg(age) from user").show//DSL风格语法df.select("username","age").show()//RDD=>DataFrame=>DataSet//RDDval rdd1 :RDD[(Int,String,Int)] = spark.sparkContext.makeRDD(List((1,"zhangsan",30),(2,"lisi",40)))//DataFrameval df1 :DataFrame = rdd1.toDF("id","name","age")df1.show()//DataSetval ds1 :Dataset[User] = df1.as[User]ds1.show()//DataSet=>DataFrame=>RDDval df2 =ds1.toDF()df2.show()val rdd2 :RDD[sql.Row] = df2.rddrdd2.foreach(a=>println(a.getString(1)))rdd1.map{case (id,name,age)=>User(id,name,age)}.toDS().show()val rdd3 = ds1.rddrdd3.foreach(a=>println(a.age))rdd3.foreach(a=>println(a.id))rdd3.foreach(a=>println(a.name))spark.stop()}}
在子模块Spark-SQL创建input
再创建user的json文件
输入以下内容
[{"username":"zhangsan","age":20},{"username":"lisi","age":17}
]
运行结果:
自定义函数:
示例
UDF
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}object UDF {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SQLDemo")val spark :SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()import spark.implicits._//读取json文件val df : DataFrame = spark.read.json("Spark-SQL/input/user.json")spark.udf.register("addName",(x:String)=>"Name:"+x)df.createOrReplaceTempView("people")spark.sql("select addName(username),age from people").show()spark.stop()}}运行结果
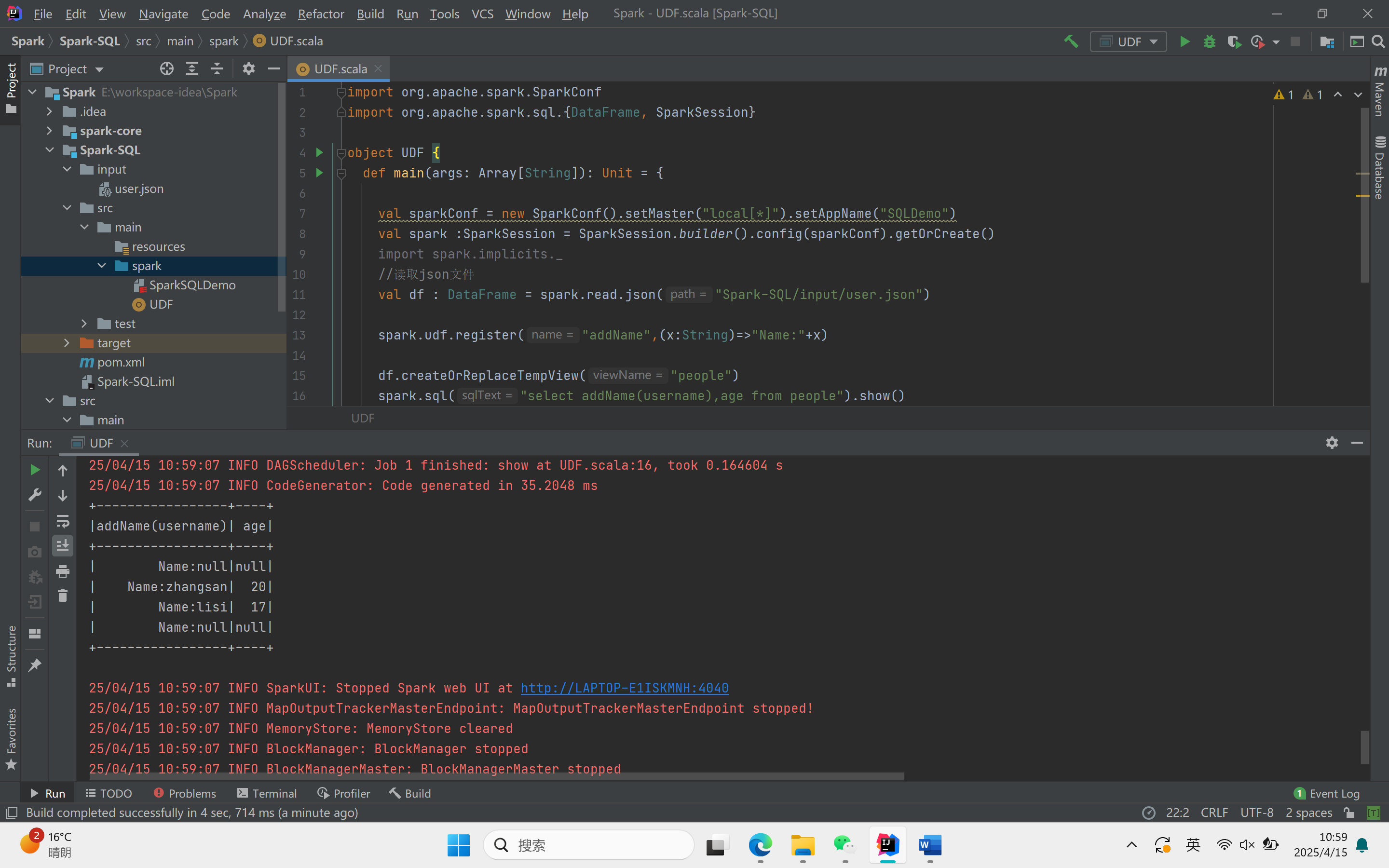
计算平均工资:
RDD实现方式
import org.apache.spark.{SparkConf, SparkContext}object RDD {def main(args: Array[String]): Unit = {val sparkConf: SparkConf = new SparkConf().setAppName("app").setMaster("local")val sc: SparkContext = new SparkContext(sparkConf)val resRDD: (Int, Int) = sc.makeRDD(List(("zhangsan", 20), ("lisi", 30), ("wangwu", 40))).map {case (name, salary) => {(salary, 1)}}.reduce {(t1, t2) => {(t1._1 + t2._1, t1._2 + t2._2)}}println(resRDD._1 / resRDD._2)// 关闭连接sc.stop()}
}运行结果
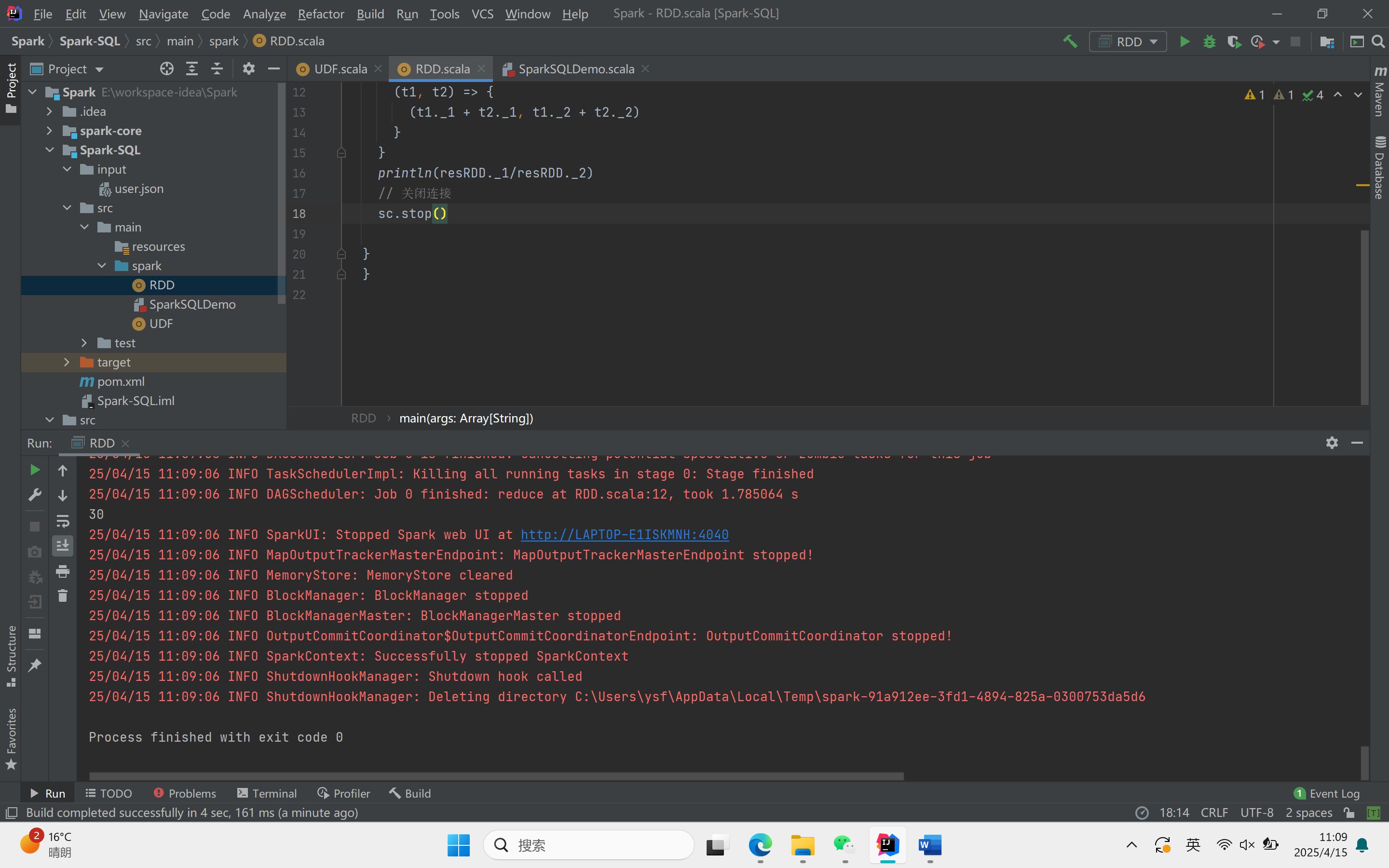
强类型UDAF实现方式:
代码示例
import org.apache.spark.sql.{DataFrame, Encoder, Encoders, SparkSession, functions}
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.functions.udaf
import org.apache.spark.sql.types._
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
// 定义中间状态样例对象
case class Buff(var sum: Long, var cnt: Long)// 自定义聚合函数类
class MyAverageUDAF extends Aggregator[Long, Buff, Double] {override def zero: Buff = Buff(0, 0)override def reduce(b: Buff, a: Long): Buff = {b.sum += ab.cnt += 1b}override def merge(b1: Buff, b2: Buff): Buff = {b1.sum += b2.sumb1.cnt += b2.cntb1}override def finish(reduction: Buff): Double = {reduction.sum.toDouble / reduction.cnt}override def bufferEncoder: Encoder[Buff] = Encoders.productoverride def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}
object Main {def main(args: Array[String]): Unit = {val sparkconf = new SparkConf().setAppName("app").setMaster("local[*]")val spark = SparkSession.builder().config(sparkconf).getOrCreate()import spark.implicits._val res :RDD[(String,Int)]= spark.sparkContext.makeRDD(List(("zhangsan", 20), ("lisi", 30), ("wangwu",40)))val df :DataFrame = res.toDF("name","salary")df.createOrReplaceTempView("user")var myAverage = new MyAverageUDAF//在 spark 中注册聚合函数spark.udf.register("avgSalary",functions.udaf(myAverage))spark.sql("select avgSalary(salary) from user").show()spark.stop()}
}运行结果:
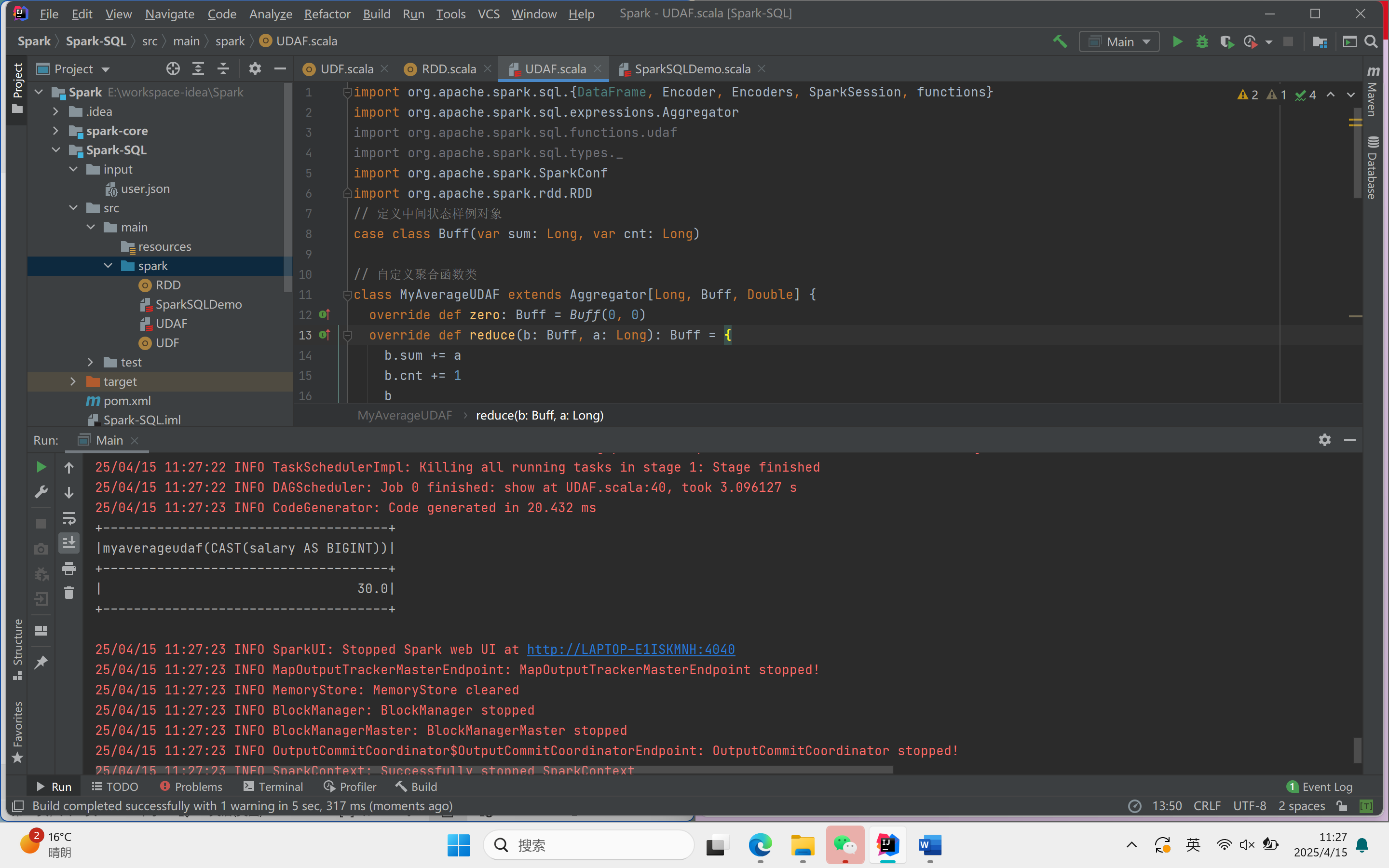






:部署应用、了解常用命令及编写资源清单)