简介
Node Problem Detector(NPD)是 Kubernetes 集群中一个重要的监控插件,它的作用是监控节点的健康状况并检测可能出现的问题。NPD 通过在每个节点上运行的检测器来工作,能够发现基础设施、容器运行时、硬件和内核等问题,并将这些问题报告给集群中的上层控制面。
NPD 只是作为一个问题检测和报告程序运行,需要配合自愈程序才能完成节点问题的自动处理,默认的集群控制面组件并不会响应 NPD 报告的问题。NPD 可以检测的问题如下:
- 基础设施问题: NTP 服务关闭;
- 硬件问题:损坏的处理器 、内存或者磁盘;
- 内核问题:内核死锁或者文件系统损坏;
- 容器运行时问题:CRI 守护进程无响应;
- ...
NPD 以 DaemoSet 或独立进程的方式运行,支持多个 exporter 作为通知渠道,其中 Kubernetes exporter 向 APIServer 报告以下两类节点问题:
- Event ,对 Pod 影响有限但值得关注的问题;
- NodeCondition , 可以导致 Pod 无法在节点运行的持久性问题;
实际上,两类问题都会产生 K8s Event ,只不过 NodeCondition 会作为一个不可自动恢复的状态持久存在于 Node 的描述信息中,除非主动重置或者重启 NPD Pod。考虑到 NodeCondition 需要作为自愈系统的输入,这是一种合理的设计,让自愈行为能够实现串行操作,有利于在自愈过程中保持一致性。
架构方面,目前, NPD 作为守护进程以 goroutine 方式运行各类问题检测器,支持用户以各种语言扩展,例如编写 check_xxx.sh 脚本并配置为 NPD 插件, temporary 和 permanent 类型的规则分别为 APIServer 上报 Event 和 NodeCondition ,未来, NPD 和 问题检测器的架构可能发生变更,部分问题检测器以主机进程的方式运行,以避免检测行为受到被检测对象干扰,导致事件丢失。
NPD 支持的检测器类型有:
| 问题检测器类型 | NodeCondition | 描述 |
|---|---|---|
| SystemLogMonitor |
| 根据预定义规则监控系统日志,报告问题和指标,可禁用。 |
| SystemStatMonitor | 无 | 根据预定义规则监控系统健康相关的状态,报告问题和指标,可禁用。 |
| CustomPluginMonitor | NTPProblem ( NTP 问题) | 调用用户自定义的问题检测器,仅包含 NTP 检测器作为示例,可禁用。 |
| HealthChecker |
| 检查 Kubelet 和容器运行时( Docker 和 Containerd )健康状态,不支持禁用。 |
NPD 支持多种类型的导出器,可将节点事件导出为 Kubernetes 事件或者 Prometheus 指标等,通过采集以上渠道的数据可实现对节点事件的观测。相对来说,通过 Kubernetes Events 获取节点事件是一个更加优雅的方案,观测方能够通过事件流获得更丰富的上下文。
观测云采集器 Datakit 支持自动采集 Kubernetes 事件,配置日志检测监控器可向用户主动报告节点问题。使用云服务时,建议启用云厂商提供的 NPD 插件,将提供更强大的节点问题检测能力。
操作步骤
部署 DataKit
登录观测云控制台,点击「集成」 -「DataKit」 - 「Kubernetes」,下载 datakit.yaml,拷贝第 3 步中 ENV_DATAWAY 键的值:
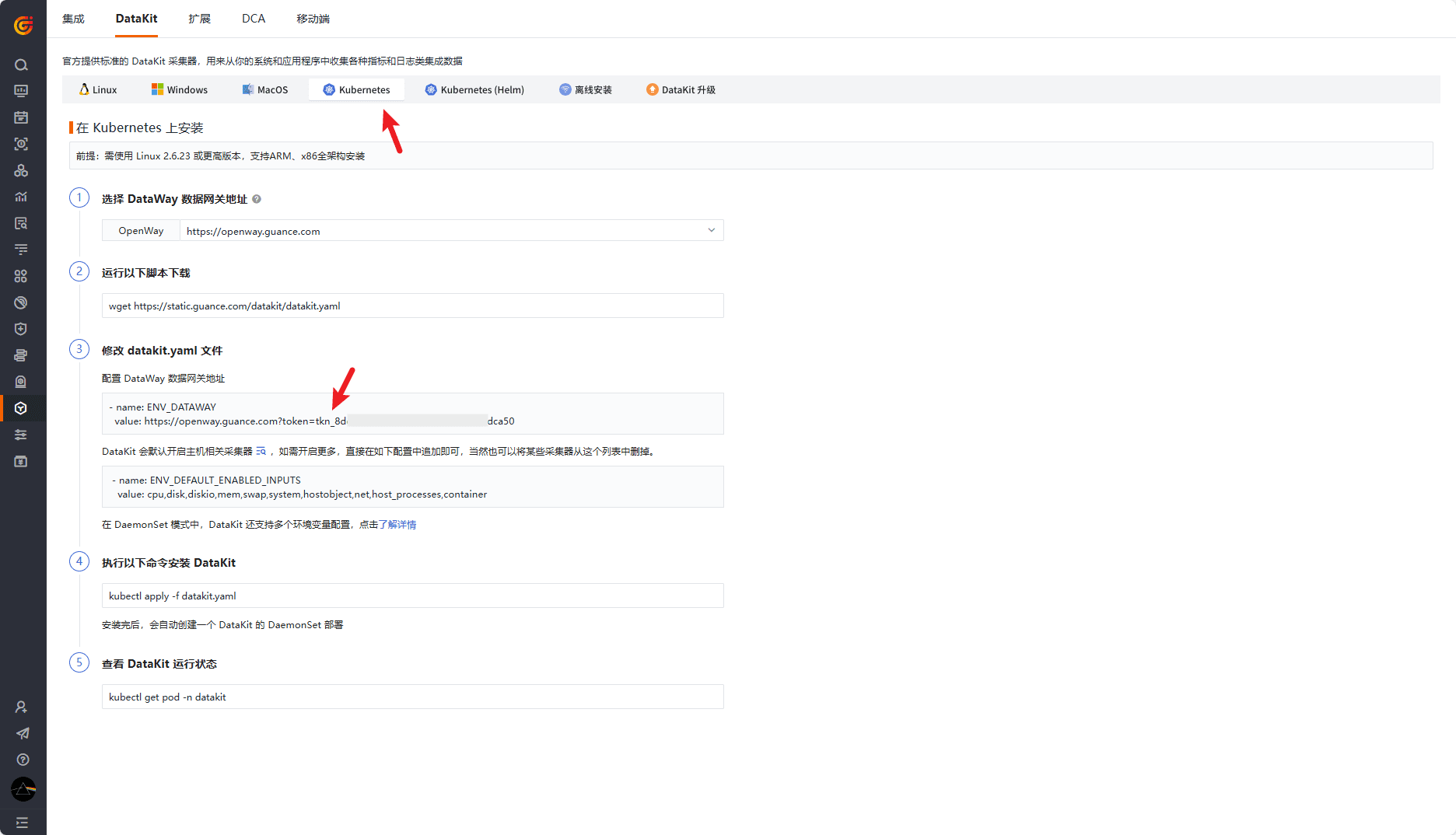
编辑 datakit.yaml,修改 DaemonSet 环境变量:
- 修改 ENV_DATAWAY 的值为上一步中拷贝的值;
- 修改 ENV_CLUSTER_NAME_K8S 的值为集群名称;
- 新增 ENV_NAMESPACE,值为集群名称;
执行以下命令部署 Datakit 并验证:
kubectl apply -f datakit.yaml
kubectl get pods -n datakit
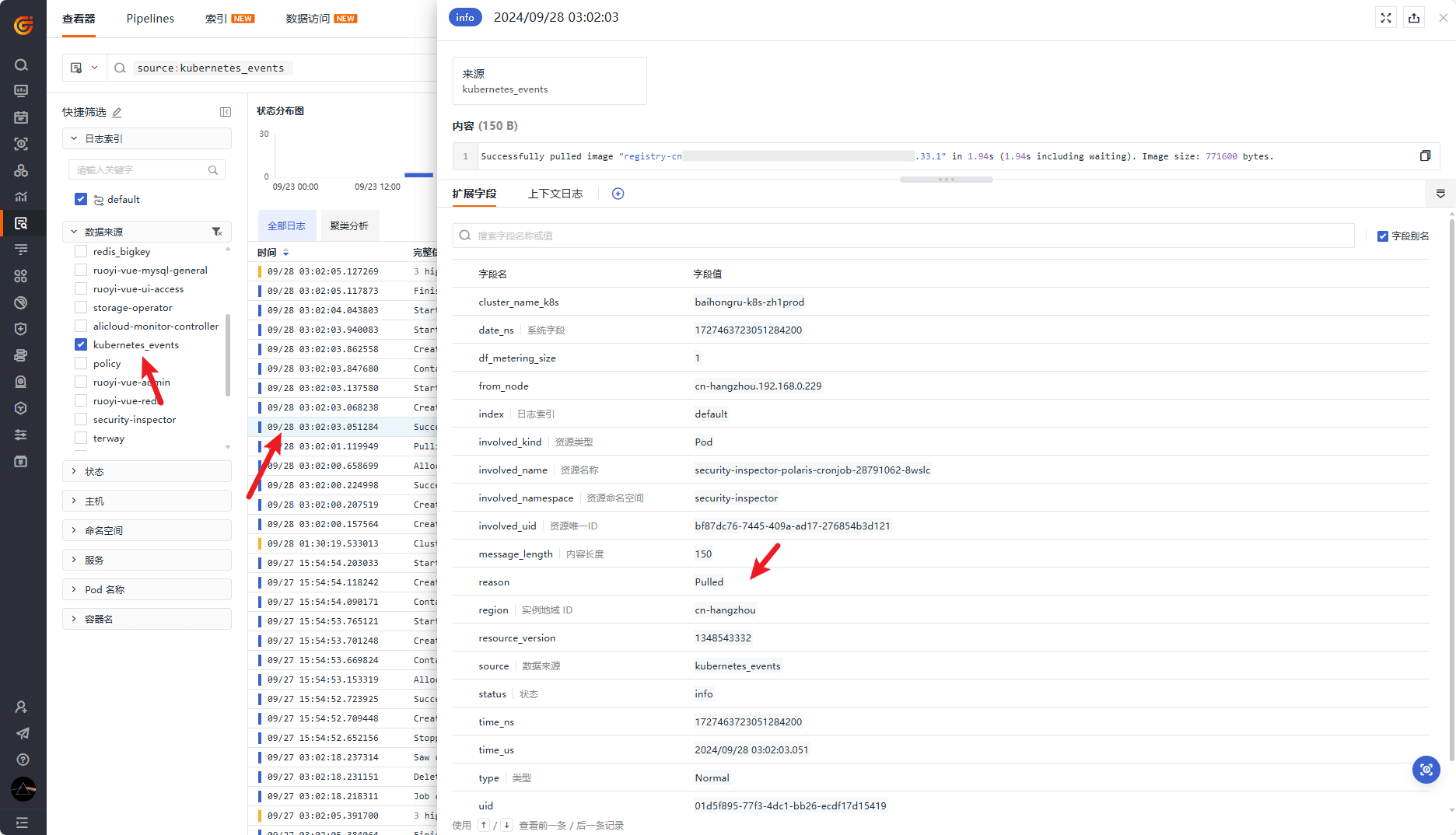
部署成功后 Datakit 将自动采集集群事件并上报至数据来源为 kubernetes_events 的日志,无需额外配置,点击日志条目可查看阔扩展信息:
开启 NPD 插件
对于云 Kubernetes 服务,推荐启用官方 NPD 插件,对于自建 Kubernetes 服务,可前往 NPD 官方仓库下载相关资源文件并部署:
- rbac.yaml
- node-problem-detector-config.yaml
- node-problem-detector.yaml
注意:
- 官方默认配置仅启用从操作系统、进程管理器日志检查节点问题的插件,启用其他插件可能需要为官方镜像集成命令行工具,例如 systemctl、crictl 等;
- 官方镜像无法拉取时,可为镜像增加前缀
k8s.m.daocloud.io/;
日志(事件)
观测云中,Kubernetes 事件描述如下:
{"time": 1723622964327,"time_us": 1723622964327008,"__docid": "L_1723622964327_cqu6cdhmc0rcje80ft90","__source": "kubernetes_events","message": "kernel: BUG: unable to handle kernel NULL pointer dereference at TESTING","__isCutMessage": false,"__namespace": "logging","source": "kubernetes_events","status": "warn","df_metering_size": 1,"message_length": 72,"cluster_name_k8s": "default","date_ns": 1723622964327008500,"from_node": "lc-ubuntu-k8s-70","index": "default","involved_kind": "Node","involved_name": "lc-ubuntu-k8s-70","involved_namespace": "","involved_uid": "lc-ubuntu-k8s-70","reason": "KernelOops","resource_version": "228175","time_ns": 1723622964327008500,"type": "Warning","uid": "32e220e4-e3f1-4e38-a079-4982c4824ca8","__search": 0,"__searches": [],"__unit": {"time": null,"time_us": null,"__docid": null,"__source": null,"__namespace": null,"source": null,"status": null,"df_metering_size": null,"message_length": null,"cluster_name_k8s": null,"date_ns": null,"from_node": null,"index": null,"involved_kind": null,"involved_name": null,"involved_namespace": null,"involved_uid": null,"reason": null,"resource_version": null,"time_ns": null,"type": null,"uid": null},"__uuid": "a41db1f0-5a14-11ef-bb6b-61e8f09c54b4","__hightlight": false,"__is_all_columns_data": true
}
NPD 生成的事件中并不包含标识持久性与临时性问题的字段,需要根据 reason 字段的值配置不同类型的监控器,例如持久性问题监控器和临时性问题监控器,分别匹配对应的 reason,另外,临时性事件频繁发生时可视为持久性事件。
可以通过云厂商官方文档或启用 NPD 后的 ConfigMap 了解能够检测的节点事件:
kubectl get configmap/ack-node-problem-detector-config -n kube-system -o yaml
监控视图
登录观测云控制台,点击「场景」 -「新建仪表板」,输入 “kubernetes”, 选择 “Node Problem Detector 监控视图”,点击 “确定” 即可添加视图:
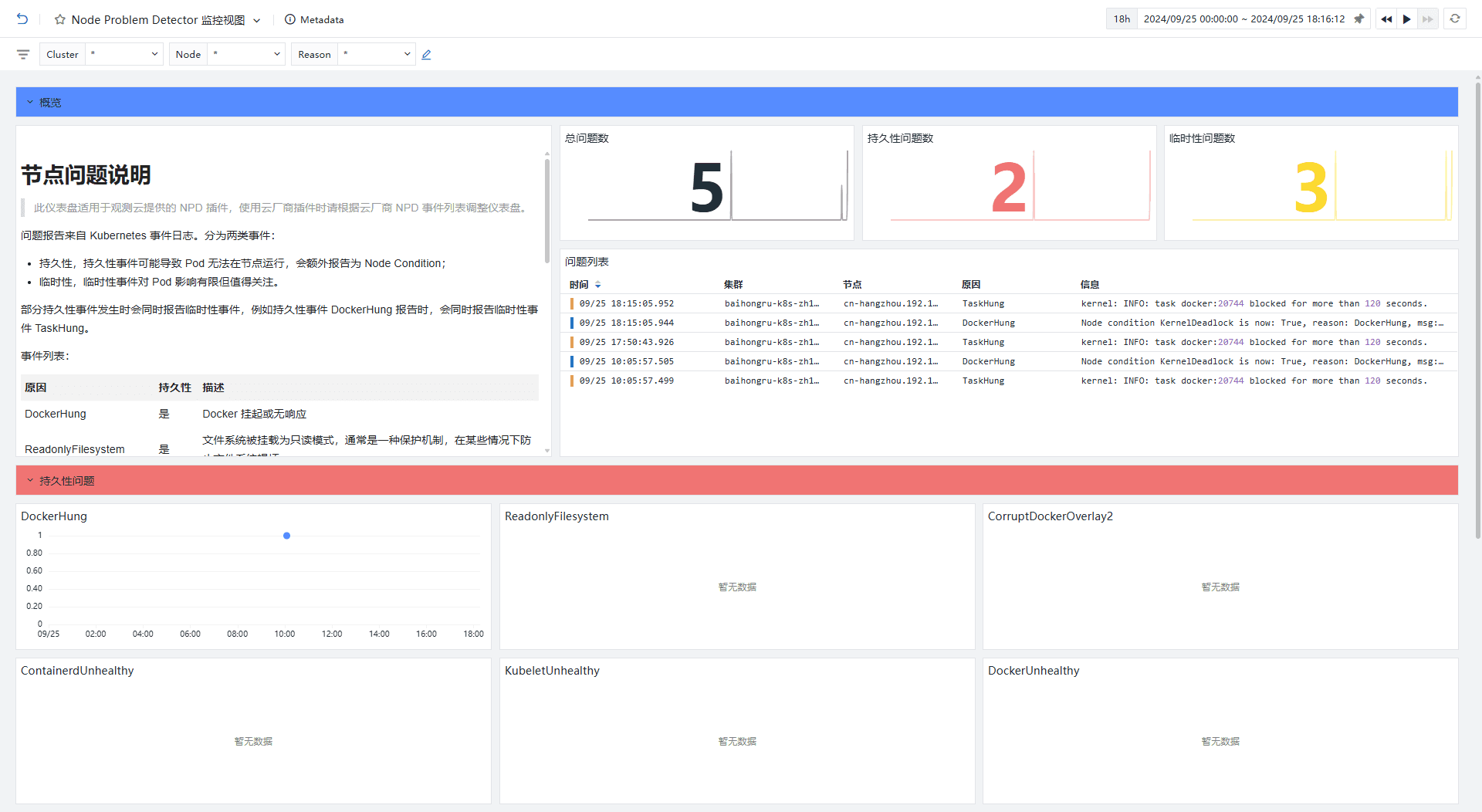
关键指标
任何持久性问题、频繁出现的非持久性问题均可作为关键指标,例如 Kubetlet 处于非健康状态、CNI 插件问题、Pod 频繁被 OOMKill 等,这些指标其实会作为日志的 tag 存在。
以下列表包含但不限于默认配置下 NPD 能够检测的事件:
| 原因 | 持久性 | 描述 |
|---|---|---|
| DockerHung | 是 | Docker 挂起或无响应 |
| ReadonlyFilesystem | 是 | 文件系统被挂载为只读模式,通常是一种保护机制,在某些情况下防止文件系统损坏 |
| CorruptDockerOverlay2 | 是 | Overlay2 存储驱动存在问题 |
| ContainerdUnhealthy | 是 | Containerd 处于非健康状态 |
| KubeletUnhealthy | 是 | Kubelet 处于非健康状态 |
| DockerUnhealthy | 是 | Docker 处于非健康状态 |
| OOMKilling | 否 | Kubernetes 因 OOM 结束 Pod |
| TaskHung | 否 | 任务挂起 |
| UnregisterNetDevice | 否 | 网络接口异常 |
| KernelOops | 否 | 内核检测到的异常行为,例如:空指针、设备错误 |
| Ext4Error | 否 | Ext4 文件系统问题 |
| Ext4Warning | 否 | Ext4 文件系统问题 |
| IOError | 否 | 缓冲区问题 |
| MemoryReadError | 否 | 可被修复的内存错误,频繁发生意味着内存硬件可能出现问题 |
| KubeletStart | 否 | Kubelet 启动,频繁出现意味 Kubelet 频繁重启 |
| DockerStart | 否 | Docker 启动,频繁出现意味 Kubelet 频繁重启 |
| ContainerdStart | 否 | Containerd 启动,频繁出现意味 Kubelet 频繁重启 |
| CorruptDockerImage | 否 | Docker registry 使用的目录不为空 |
| DockerContainerStartupFailure | 否 | Docker 无法启动 |
| ConntrackFull | 否 | 网络连接跟踪数满,将影响 NAT、防火墙等网络功能 |
| NTPIsDown | 否 | NTP时间同步异常 |
监控器(告警)
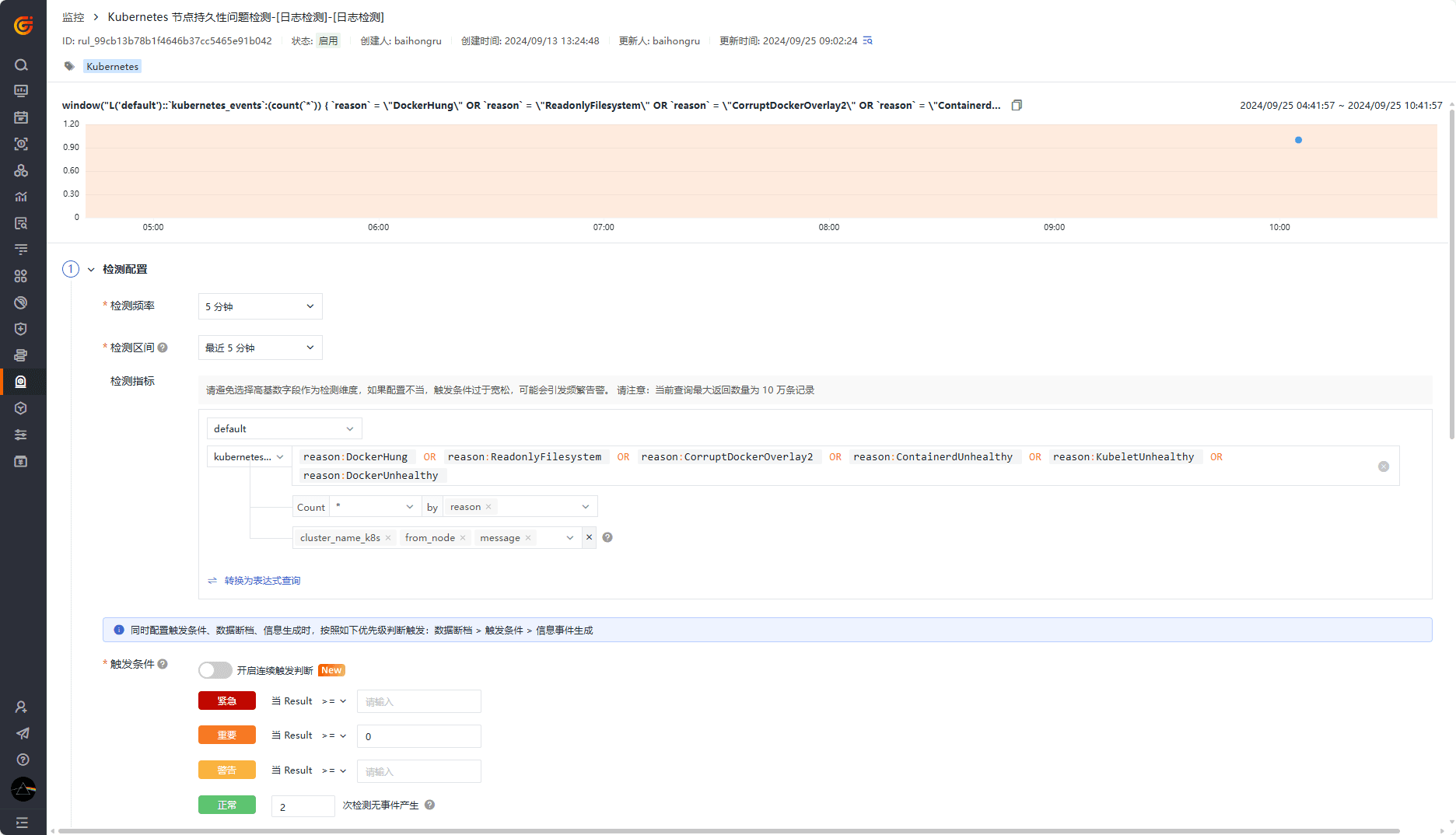
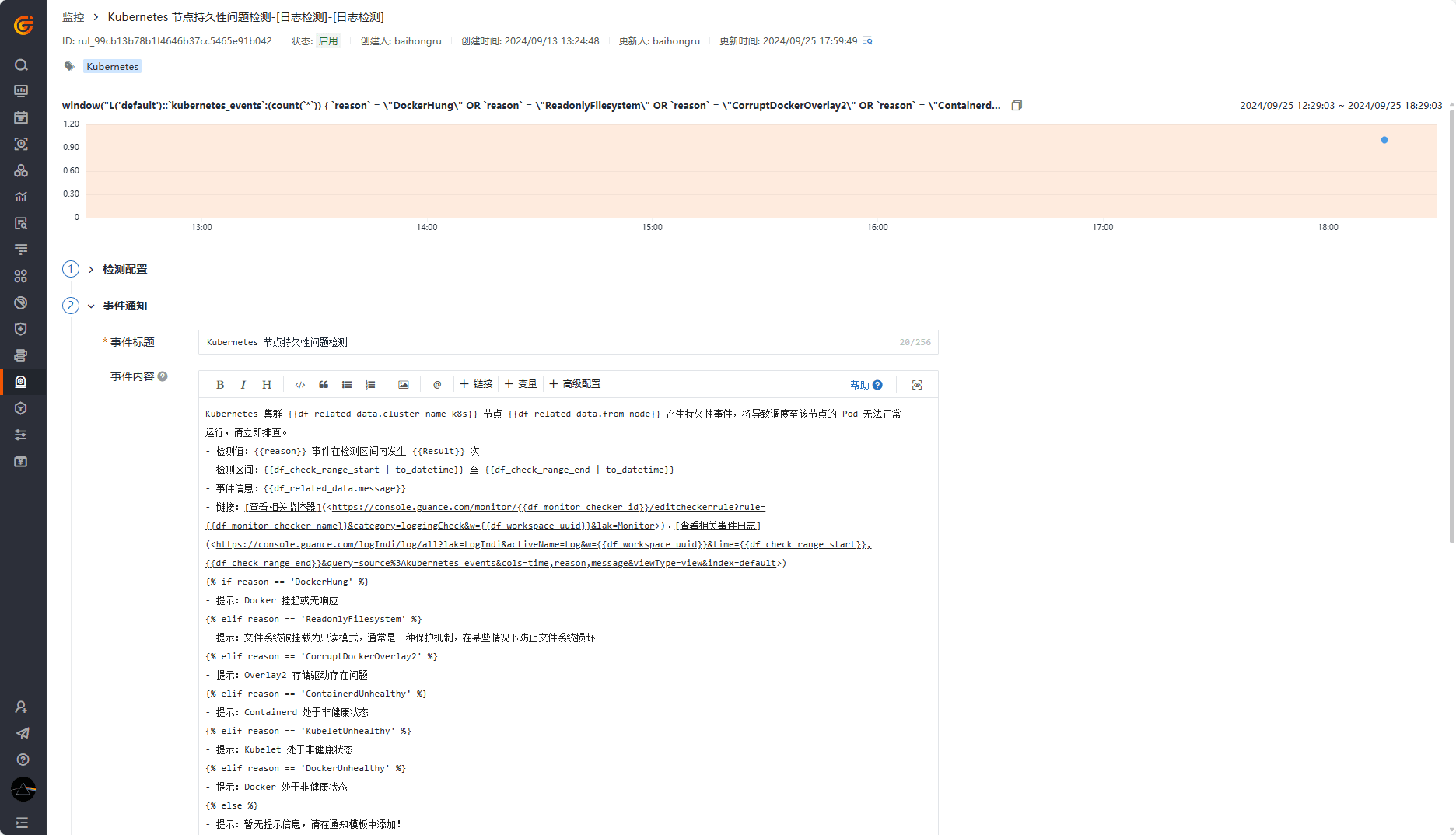
持久性问题监控器
配置持久性问题监控器,关注任意节点的指定事件:
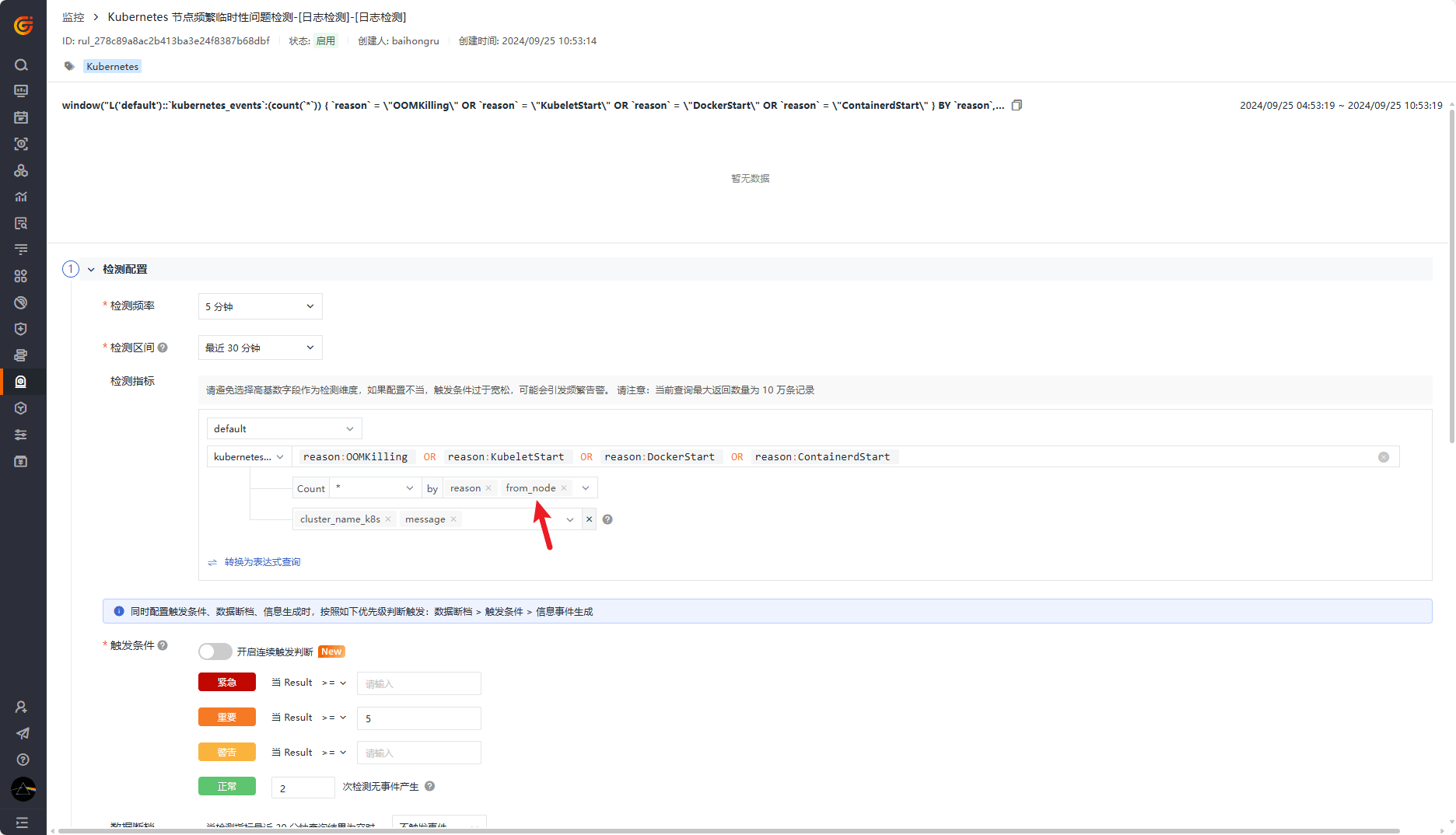
频繁出现的非持久性问题监控器
配置频繁出现的非持久性问题监控器,关注某一节点的指定事件出现的次数:
事件模拟
可通过以下命令模拟问题,该操作向 APIServer 同时写入了临时和持久性事件:
sudo sh -c "echo 'kernel: INFO: task docker:20744 blocked for more than 120 seconds.' >> /dev/kmsg"
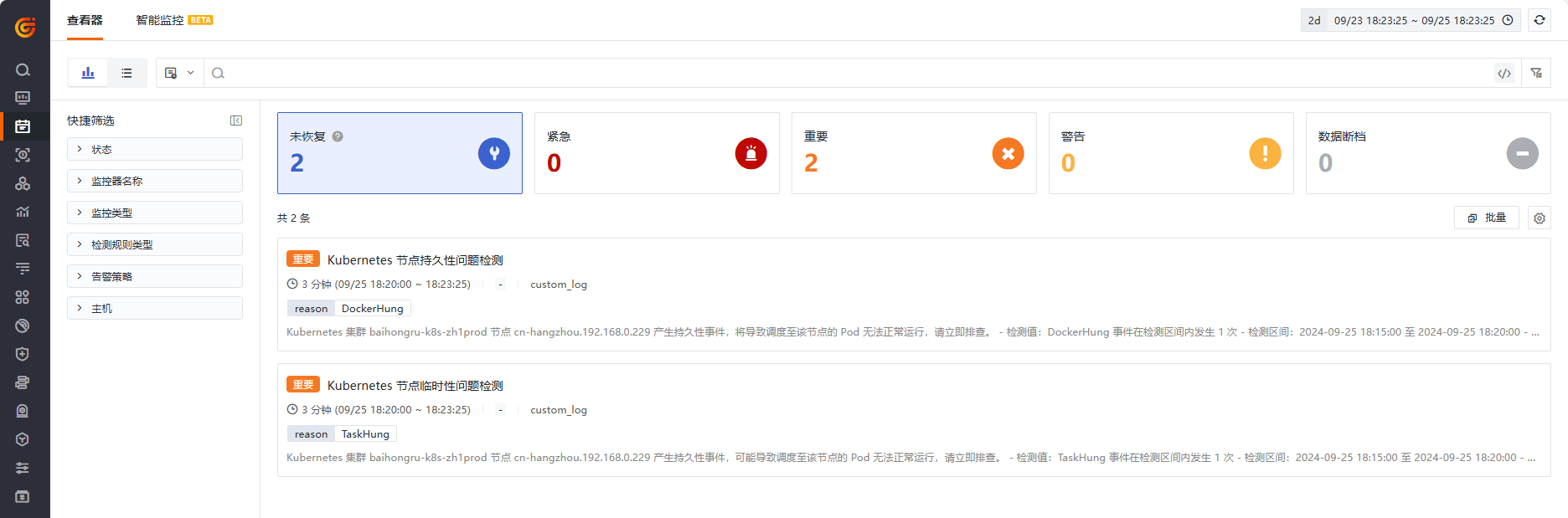
可看到告警产生:
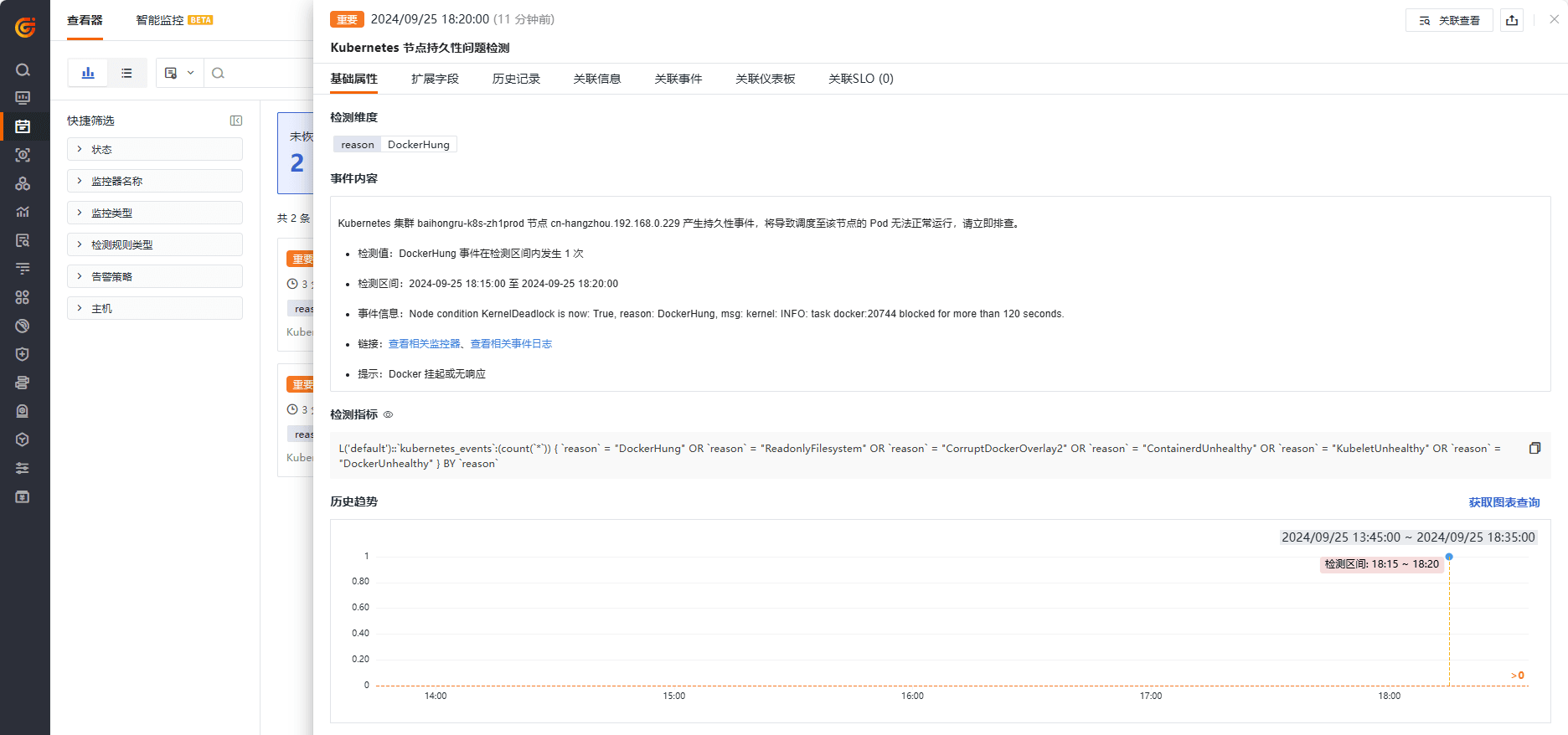
点击告警可快速查看事件趋势、自定义链接、事件历史、关联仪表盘等信息:
启用观测云监控器时,需要根据所选 NPD 插件报告的事件类型和 reason 调整仪表盘、监控器。
总结
总的来说,NPD 是 Kubernetes 集群可观测性的重要组成部分,它通过检测和报告节点问题,帮助提高集群的稳定性和可靠性,同时结合观测云的平台,可以为用户提供一个全面、自动化的 Kubernetes 节点监控解决方案,帮助用户更好地管理和维护他们的集群。



![[蓝桥杯 2018 省 B] 乘积最大-题解](http://pic.xiahunao.cn/nshx/[蓝桥杯 2018 省 B] 乘积最大-题解)


