综合示例:文本分类Transformer
要将词序考虑在内,你只需将Embedding层替换为位置感知的PositionEmbedding层,如代码清单11-25所示。
代码清单11-25 将Transformer编码器与位置嵌入相结合
vocab_size = 20000
sequence_length = 600
embed_dim = 256
num_heads = 2
dense_dim = 32inputs = keras.Input(shape=(None,), dtype="int64")
x = PositionalEmbedding(sequence_length, vocab_size, embed_dim)(inputs) ←----注意这行代码!
x = TransformerEncoder(embed_dim, dense_dim, num_heads)(x)
x = layers.GlobalMaxPooling1D()(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop",loss="binary_crossentropy",metrics=["accuracy"])
model.summary()callbacks = [keras.callbacks.ModelCheckpoint("full_transformer_encoder.keras",save_best_only=True)
]
model.fit(int_train_ds, validation_data=int_val_ds, epochs=20,callbacks=callbacks)
model = keras.models.load_model("full_transformer_encoder.keras",custom_objects={"TransformerEncoder": TransformerEncoder,"PositionalEmbedding": PositionalEmbedding})
print(f"Test acc: {model.evaluate(int_test_ds)[1]:.3f}")
模型的测试精度为88.3%。这是一个相当不错的改进,它清楚地表明了词序信息对文本分类的价值。这是迄今为止最好的序列模型,但仍然比词袋方法差一点。
何时使用序列模型而不是词袋模型
有时你会听到这样的说法:词袋方法已经过时了,无论是哪种任务和数据集,基于Transformer的序列模型才是正确的选择。事实绝非如此:在很多情况下,在二元语法袋之上堆叠几个Dense层,仍然是一种完全有效且有价值的方法。事实上,在IMDB数据集上尝试的各种方法中,到目前为止性能最好的就是二元语法袋。应该如何在序列模型和词袋模型之中做出选择呢?
事实证明,在处理新的文本分类任务时,你应该密切关注训练数据中的样本数与每个样本的平均词数之间的比例,如图11-11所示。如果这个比例很小(小于1500),那么二元语法模型的性能会更好(它还有一个优点,那就是训练速度和迭代速度更快)。如果这个比例大于1500,那么应该使用序列模型。换句话说,如果拥有大量可用的训练数据,并且每个样本相对较短,那么序列模型的效果更好。
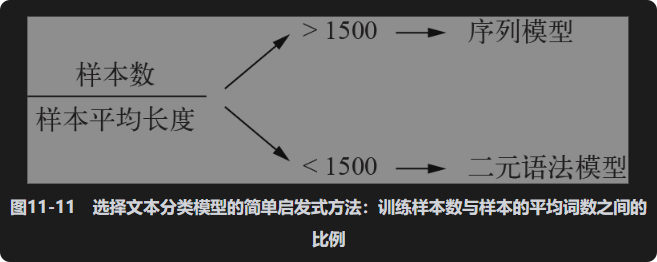
因此,如果想对包含1000个词的文件进行分类,并且你有100 000份文件(比例为100),那么应该使用二元语法模型。如果想对平均长度为40个单词的推文进行分类,并且有50 000条推文(比例为1250),那么也应该使用二元语法模型。但如果数据集规模增加到500 000条推文(比例为12 500),那么就应该使用Transformer编码器。对于IMDB影评分类任务,应该如何选择呢?我们有20 000个训练样本,平均词数为233,所以根据我们的经验法则,应该使用二元语法模型,这也证实了我们在实践中的结果。
这在直觉上是有道理的:序列模型的输入代表更加丰富、更加复杂的空间,因此需要更多的数据来映射这个空间;与此相对,普通的词集是一个非常简单的空间,只需几百或几千个样本即可在其中训练logistic回归模型。此外,样本越短,模型就越不能舍弃样本所包含的任何信息——特别是词序变得更加重要,舍弃词序可能会产生歧义。对于“this movie is the bomb”和“this movie was a bomb”这两个句子,它们的一元语法表示非常接近,词袋模型可能很难分辨,但序列模型可以分辨出哪句是负面的、哪句是正面的。对于更长的样本,词频统计会变得更加可靠,而且仅从词频直方图来看,主题或情绪会变得更加明显。第一句的意思是“这部电影很棒”,而第二句的意思是“这部电影很烂”。——译者注现在请记住,这个启发式规则是针对文本分类任务的。它不一定适用于其他NLP任务。举例来说,对于机器翻译而言,与RNN相比,Transformer尤其适用于非常长的序列。这个启发式规则只是经验法则,而不是科学规律,所以我们希望它在大多数时候有效,但不一定每次都有效。
超越文本分类:序列到序列学习
现在你掌握的工具已经可以处理大多数NLP任务了。但是,你只在一种任务上使用过这些工具,即文本分类任务。这种任务非常常见,但除此之外,NLP还包含许多内容。你将在本节中学习序列到序列模型(sequence-to-sequence model),以继续巩固前面学过的知识。序列到序列模型接收一个序列作为输入(通常是一个句子或一个段落),并将其转换成另一个序列。这个任务是许多成功的NLP应用的核心。机器翻译(machine translation):将源语言的一段话转换为目标语言的相应内容。文本摘要(text summarization):将长文档转换为短文档,并保留最重要的信息。问题答(question answering):将输入的问题转换为对它的回答。聊天机器人(chatbot):将对话提示转换为对该提示的回复,或将对话历史记录转换为对话的下一次回复。文本生成(text generation):将一个文本提示转换为完成该提示的段落。序列到序列模型的通用模板如图11-12所示。训练过程分为以下两步。编码器模型将源序列转换为中间表示。对解码器进行训练,使其可以通过查看前面的词元(从0到i-1)和编码后的源序列,预测目标序列的下一个词元i。
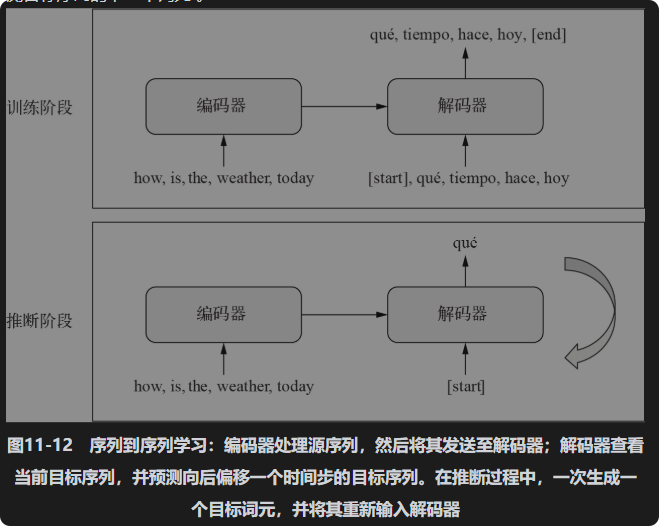
在推断过程中,我们不会读取目标序列,而会尝试从头开始预测目标序列。我们需要一次生成一个词元。(1)从编码器获得编码后的源序列。(2)解码器首先查看编码后的源序列和初始的“种子”词元(比如字符串"[start]"),并利用它们来预测序列的第一个词元。(3)将当前预测序列再次输入到解码器中,它会生成下一个词元,如此继续,直到它生成停止词元(比如字符串"[end]")。利用前面所学知识,你可以构建这种新的模型。我们来深入了解一下。
机器翻译示例
我们将在一项机器翻译任务上介绍序列到序列模型。Transformer正是为机器翻译而开发的。我们将从一个循环序列模型开始,然后使用完整的Transformer架构。我们将使用一个英语到西班牙语的翻译数据集,首先下载数据集并解压,如下所示。
!wget http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip
!unzip -q spa-eng.zip
这个文本文件每行包含一个示例:一个英语句子,后面是一个制表符,然后是对应的西班牙语句子。我们来解析这个文件,如下所示。
text_file = "spa-eng/spa.txt"
with open(text_file) as f:lines = f.read().split("\n")[:-1]
text_pairs = []
for line in lines: ←----对文件中的每一行进行遍历english, spanish = line.split("\t") ←----每一行都包含一个英语句子和它的西班牙语译文,二者以制表符分隔spanish = "[start] " + spanish + " [end]" ←----将"[start]"和"[end]"分别添加到西班牙语句子的开头和结尾,以匹配图11-12所示的模板text_pairs.append((english, spanish))
得到的text_pairs如下所示。
>>> import random
>>> print(random.choice(text_pairs))
("Soccer is more popular than tennis.","[start] El fútbol es más popular que el tenis. [end]")
我们将text_pairs打乱,并将其划分为常见的训练集、验证集和测试集。
import random
random.shuffle(text_pairs)
num_val_samples = int(0.15 * len(text_pairs))
num_train_samples = len(text_pairs) - 2 * num_val_samples
train_pairs = text_pairs[:num_train_samples]
val_pairs = text_pairs[num_train_samples:num_train_samples + num_val_samples]
test_pairs = text_pairs[num_train_samples + num_val_samples:]




(Go语言版))
