提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、 数据
- 1、认识经典数据
- 1.1入门数据:MNIST、其他数字与字母识别
- (1)数据下载
- (2)查看数据的特征和标签
- 方式一:.data/.targets查看数据特征和标签
- 方式二:通过查看某一个索引值的方式来查看特征和标签
- 方式三:万能方法
- (3)数据可以化
- 方式一:PIL直接可视化
- 方式二:用一个万能公式来随机可视化五张图
- 1.2竞赛数据:ImageNet、COCO、VOC、LSUN
- 1.3景物、人脸、通用、其他
- 2、使用自己的数据/图片创造数据集
- 2.1从图像png/jpg到四维tensor
- ImageFolder
- 总结
前言
内容来源于【菜菜&九天深度学习实战课程】上班以后时间少,为了提高效率,通过抄课件的方式加深记忆,而非听课。所以所有笔记仅仅是学习工具,并非抄袭!
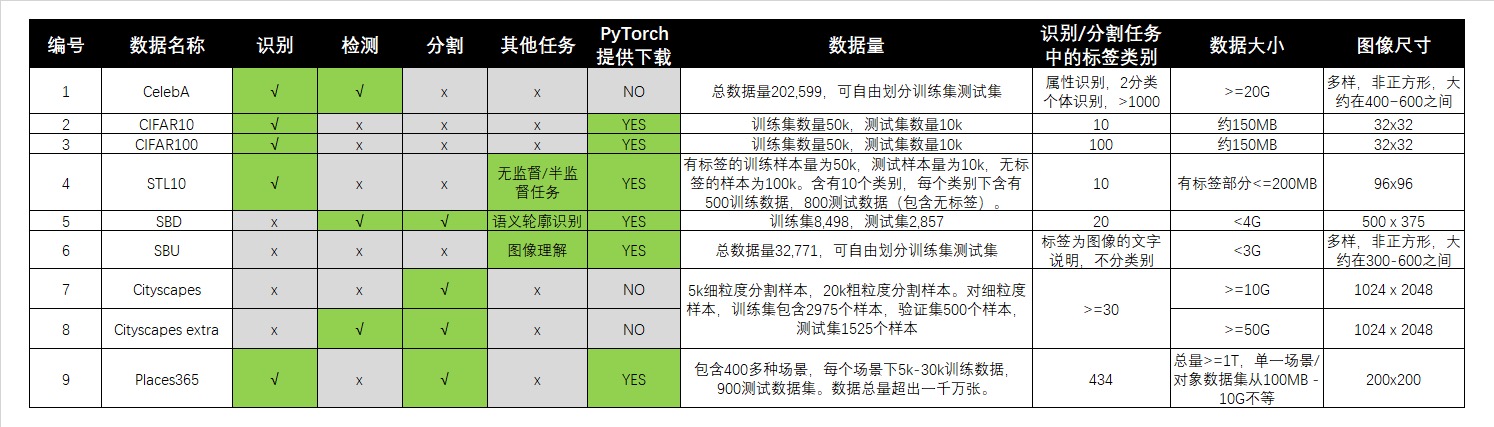
在传统机器学习中,通常会区分有监督、无监督、分类、回归、聚类等人物类别,在不同的任务重会指向不同形式的标签、不同的评估指标、不同的损失函数,这些内容会影响我们的训练和建模流程。在深度视觉以外,除了区分“回归、分类”之外,还需要区分众多的、视觉应用类别。如果只考虑图像的内容,至少有常见的三种任务:识别(recognition) 、检测(detection)、分割(segmentation)。
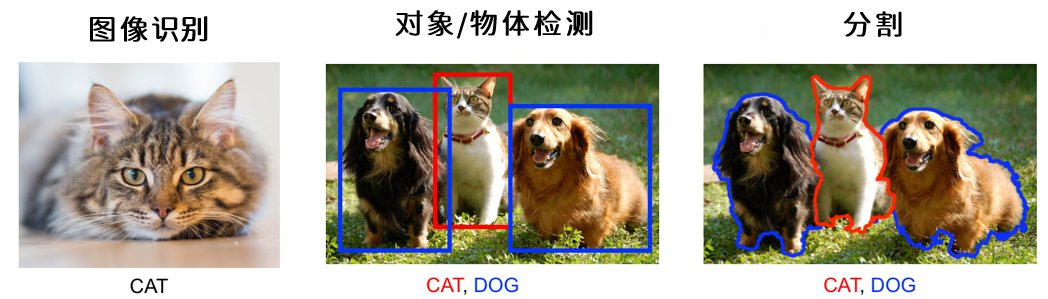
图像识别以图像中的单一对象为核心,采集信息并作出判断,任何超过单一对象的任务都不是单纯的图像识别。用于图像识别的数据集往往比较规整、比较简单,被识别物体基本轮廓完整、拍摄清晰、是图像中最容易被人眼注意到的对象。因此,图像识别适用于机场人脸识别这种简单的应用场景。
检测任务和分割任务是针对图像中多个或者单个对象进行判断的任务。因此分割和检测所使用的图像往往复杂很多。在检测任务重,首先要使用边界框(Bounding Box, bbx)对图像中的多个对象所在位置进行判断,在一个边界框容纳一个对象的前提下,再对边界框内每一个单一对象进行图像识别。因此。
检测任务的标签有两个:(1)以坐标方式确定的边界框的位置;(2)每个边界框中的物体属性。检测任务的训练流程也氛围两步:(1)定位;(2)判断。检测任务的训练数据也都是带边框的。我们可以只使用其中一个标签进行训练,但是检测任务同时训练两个标签才是最常见的情况。检测任务比较适用于大规模动态影像的识别,比如识别道路车辆、识别景区人群等。检测也是现在实际应用最为广泛的视觉任务。
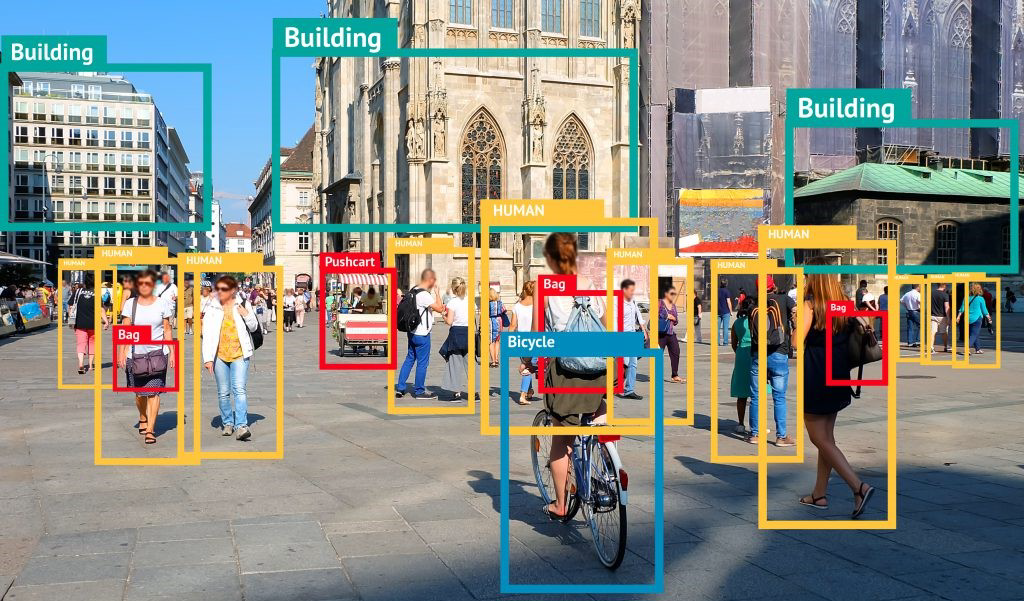
分割任务是像素级别的密集任务,需要对图像中的每个像素进行分类,因此不需要定义边界框就能够找到每个对象的“精准边界”。分割任务的标签往往只有一个,通常是对象的定义或性质(比如,这个像素是猫,这个像素是蓝天),但是标签中的类别会非常对,对于复杂的图像,标签类别可能成百上千。分割任务是现在图像领域对“理解图像”探索的前沿部分,许多具体的困难还未解决,同时,在许多实际应用场景并不需要分割任务这么”精准“的判断,因此分割的实际落地场景并不如检测来的多。比较知名的实际落地场景是美颜相机、抖音换脸特效等。
综上所述,三种任务在输出的结果及标签有所不同,但它们在一定程度上共享训练数据集,这主要是因为图像中的“对象”概念是可以人为定义的。用于图像识别的训练数据只要有适当的标签,也可以被用来检测和分割。例如,对于只有一张人脸的图像,只要训练数据存在边界框,那标签中就可以进行检测。相对的,用于检测和分割的数据如果含有大量的对象,可以被标注为“人群”这样的标签来进行识别(不过,用于检测、分割的数据拥有可以作为识别数据的标签非常少,因为检测分割数据集往往是多对象的)。

在单个任务重,也可能会遇到不同的“标签”。例如,对人脸数据,我们可以进行“属性识别”(attribute recognition)、“个体识别”(identity recognition)、“情绪识别”(emotion recognition)等不同的任务,对于同一张图像,我们的识别结果可能完全不同。

在情绪识别中,我们只拥有“情绪”这一标签,但标签类别中包含不同的情绪。在属性识别中,我们可以执行属性有限的多分类任务,也可以让每一种属性都有一个单独的标签,针对一个标签来完成二分类任务。而个体识别则是经典的人脸识别,在CelebA数据中我们使用人名作为标签来进行判断。
同样的,在场景识别、物体识别数据下(比如大规模场景识别数据LSUN),我们可能无法使用全部的数据集,因为全数据集可能会非常巨大并且包含许多我们不需要的信息。在这种情况下,标签可能是分层的,例如,场景可能分为室内和室外两种,而室内又分为卧式、客厅、厨房,室外则分为自然精光、教堂、其他建筑等,在这种情况下,室内和室外就是“上层标签”,具体的房间或景色则被认为是“下层标签”。我们通常会选择某个下层标签下的数据进行学习,例如:在LSUN中选择“教堂”或“卧室”标签进行学习:

对检测任务,我们也可能会检测不同的对象,例如:检测车牌号和检测车辆就是完全不同的标签,我们也需要从可以选择的标签中进行挑选。对于分割,则有更多的选项,我们可以执行将不同性质的物体分割开来的”语义分割“,也可以执行将每个独立对象都分割开来的”实例分割“,还可以执行使用多边形或颜色进行分割的分割方法。同时,根据分割的“细致程度”,还可以分为“粗粒度分割”(Coarse)和“细粒度分割”(Fine-grained),具体的分割程度由训练图像而定。

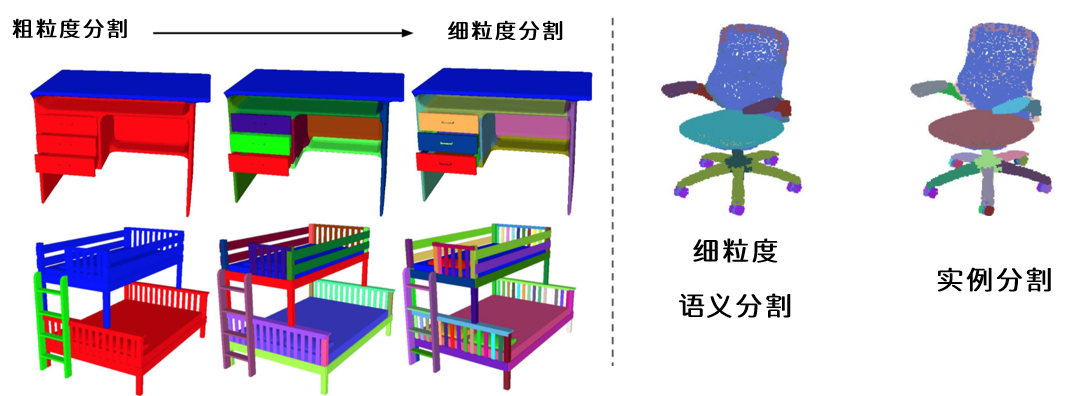
因此,在图像数据集的读取过程中,可能会发现一个图像数据集会带有很多个指向不同任务的标签、甚至很多个不同任务的训练集。遗憾的是,数据集本身并不会说明数据集所指向的任务,因此我们必须从中辨别出自己所需要的部分。torchvision.datasets模块中自带的CelebA人脸数据集就是这种情
况。如下图所示,类datasets.CelebA下没有任何文字说明,只有一个指向数据源的链接,光看PyTorch官网,我们并不能判断这个数据集是什么样的数据集。不过,这个类由参数“target_type”,这个参数可以控制标签的类型,四种标签类型分别是属性(attr)、个体(identity)、边界框(bbox)和特征(landmarks)。根据参数说明,可以看出属性是40个二分类标签,可以从中选择一个进行分类,个体是判断这个人类是哪个具体任务,这两个标签指向的是识别任务。边界框和特征都以坐标形式表示,这两个标签都指向检测任务。

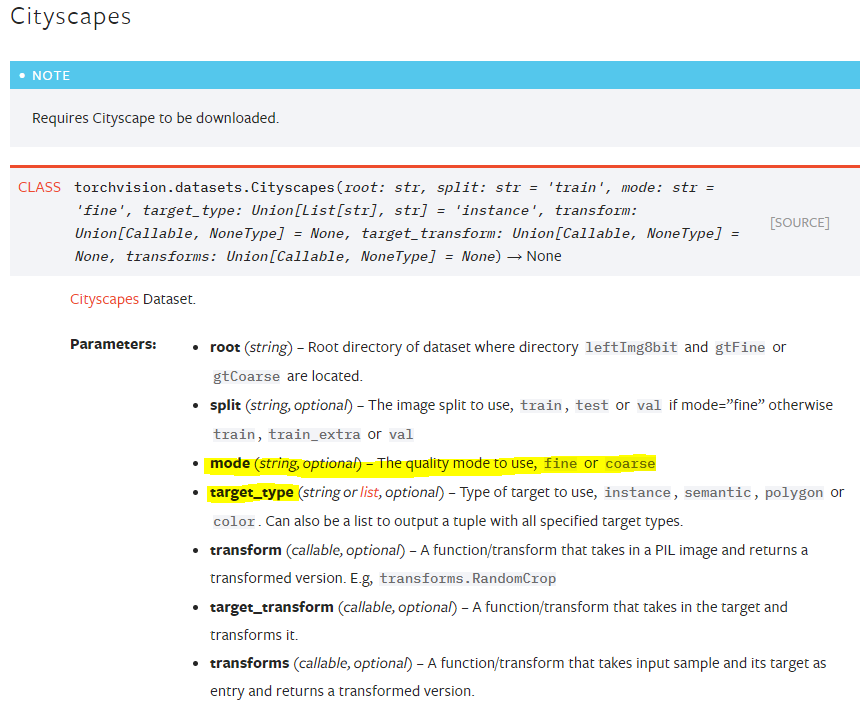
同样情况的还有Cityscapes,这个数据集的类dataset.Cityscapes下没有任何说明,但它含有参数mode和target_type,其中mode由两个模式:fine以及coarse,这两个模式表示Cityscape是一个用于分割任务额度数据集。同时,targe-type下面还有instance(实例分割)、semantic(语义分割)、polygon(多边形分割)、color(颜色分割)四种选项,所以要清晰了解自己的需求以及每种分割的含义才能正确填写这些参数。同时,我们可以一次性训练导入多个标签进行使用,如何混用这些标签来达成训练目标也成为难点之一。
再看看LSUN数据集,需要自己填写标签名称的情况:
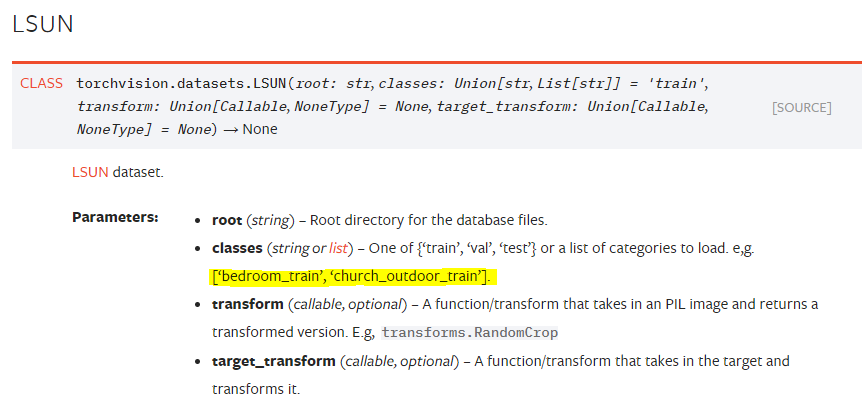
现在我们对视觉任务有了一定了解:图像数据丰富多样,在具体任务不明确的情况下,我们连最基本的数据导入都存在问题。基于对图像任务的理解,本课内容将分为上、下两部分。上以图像识别任务为主,下以视觉任务中的其他任务为主。
一、 数据
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
1、认识经典数据
1.1入门数据:MNIST、其他数字与字母识别
第一部分要介绍的是最适合用于教学和实验、几乎对所有的电脑都无负担的MNIST一族。MNIST一族是数据和字母识别的最基本的数据集,这些数据集户全都是小尺寸图像的简单识别,可以被轻松放入任意神经网络中进行训练。具体如下:
| 数据名称 | 数据说明 |
|---|---|
| FashionMINST | 衣物用品数据集 |
| MINST | 手写数字数据集 |
| KuzushijiMNIST | 日语手写平假名识别,包含48个平假名字符和一个平假名迭代标记,一个高度 |
| 不平衡的数据集 | |
| QMNIST | 与MNIST高度相似的手写数字数据集 |
| EMNIST | 与MNIST高度相似,在MNIST的基础上拓展的手写数字数据集 |
| Omniglot | 全语种手写字母数据集,包含来自50个不同字母的1623个不同的手写字符,专用于“一次性学习" |
| USPS | 另一个体系的手写数字数据集,常用来与MNIST对比 |
| SVHN | 实拍街景数字数据集(Street View House Number),是数字识别和检测中非常不同的一个数据集。有原始尺寸数据集可以下载,但在PyTorch中内置的是32x32的识别数据。注意,使用本数据需要SciPy模块的支持。 |

在PyTorch中,提供了三个与MNIST数据集相对比的数据集,分别是用于一次性学习的字母识别数据集Omniglot,另一个体系的手写数据集USPS,以及SVHN实拍街景数字数据集。这几个数据集与MNIST的区别如下图。

在深度视觉的研究中,我们很少专门就MNIST进行研究,但我们在这些简单识别数据集上设置了其他值得研究的问题。比如,在我们撰写论文或检验自己的架构时,MNIST一族是很好的基准线——他们尺寸很小,容易训练,很简单却又没有那么“简单”。一流的架构往往能够在MNIST数据集上取得99%以上的高分,而发表论文时,MNIST数据集的结果低于97%是不能接受的。单一机器学习算法能够在Fashion-MNIST数据集上取得的分数基本都在90%左右,而一流的深度学习架构至少需要达到95%以上的水准。再比如,我们常常使用平假名识别的数据集来研究深度学习中的样本不平衡问题,我们还使用Omniglot数据集来研究人脸识别(主要是个体识别 identity recognition)中常见的“一次性学习”问题(one-shot learning)。我们来重点讲讲这个“一次性学习”的问题。


在人脸识别中,我们有两种识别策略:
第一种策略是以人名为标签进行多分类,在训练样本中包含大量的同一个人的照片,测试集中也包含这个人的照片,看CNN能否正确预测出这个人的名字;而第二种策略则是一种二分类策略,在训练样本中给与算法两张照片,通过计算距离或计算某种相似性,来判断两张照片是否是同一个人,输出的标签为“是/否相似或一致”,在这种策略中,测试集的样本也是两张照片,并且测试集的样本不需要出现在训练集中。
如果基于第一种策略来执行人脸识别,则机场、火车站的人脸识别算法必须把全国人民的人脸数据都学习一遍才可能进行正确的判断。而在第二种策略中,算法只需要采集身份证/护照上的照片信息,再把它与摄像头中拍摄到的影像进行对比,就可以进行人脸识别了。这种“看图A,判断图B上的人是否与图A上的人是同一人”的学习方法,就叫做一次性学习,因为对于单一样本,算法仅仅见过一张图A而已。不难想象,实际落地的人脸识别项目都是基于一次性学习完成的。Omniglot数据集就是专门训练一次性学习的数据集。从上图可以看出,Omniglot数据集中的字母/符号对我们而言是完全陌生的,因此我们并无法判断出算法是否执行了正确的“识别”结果。而在Omniglot数据集上,算法是通过学习图像与图像之间的相似性来判断两个符号是否是一致的符号,至于这个符号是什么,代表什么含义,对Omniglot数据集来说并无意义。
字母和数字识别的数据集的尺寸都较小,因此PyTorch对以上每个数据集都提供了下载接口,因此我们无需自行下载数据,就可以使用torchvision.datasets.xxxx的方式来对他们进行调用。在网速没有太大问题的情况下,只要将download设置为True,并确定VPN是关闭状态,就可以顺利下载。注意:下载之后最好将download参数设置为False,否则只要调用目录写错,就会重新进行下载,费时也费流量。
(1)数据下载
方式一:通过torchvision.datasets.MNIST下载数据
import torch
import torchvision
import torch.nn as nn
import torchvision.transforms as transformstrain_data = torchvision.datasets.MNIST(root='/Users/gaoyuxing/Desktop/all_file/torchvision_dataset',train=True,transform=transforms.ToTensor(),download=True)test_data = torchvision.datasets.MNIST(root='/Users/gaoyuxing/Desktop/all_file/torchvision_dataset',train=True,transform=transforms.ToTensor(),download=True)
方式二:下载了数据存储在自己电脑上并调用:
import torchvision
import torchvision.transforms as transformsfminst = torchvision.datasets.FashionMNIST(root='/Users/gaoyuxing/Desktop/all_file/torchvision_dataset',train=True,download=False,transform=transforms.ToTensor())svhn = torchvision.datasets.SVHN(root='/Users/gaoyuxing/Desktop/all_file/torchvision_dataset/SVHN',split="train",download=False,transform=transforms.ToTensor())omniglot = torchvision.datasets.Omniglot(root='/Users/gaoyuxing/Desktop/all_file/torchvision_dataset',background=True, #在ominglot论文中,作者将训练集称为background,因此background代表训练集download=False,transform=transforms.ToTensor())print(fminst)
'''
Dataset FashionMNISTNumber of datapoints: 60000Root location: /Users/gaoyuxing/Desktop/all_file/torchvision_datasetSplit: TrainStandardTransform
Transform: ToTensor()'''
print(svhn)
'''
Dataset SVHNNumber of datapoints: 73257Root location: /Users/gaoyuxing/Desktop/all_file/torchvision_dataset/SVHNSplit: trainStandardTransform
Transform: ToTensor()
'''
print(omniglot)
'''
Dataset OmniglotNumber of datapoints: 19280Root location: /Users/gaoyuxing/Desktop/all_file/torchvision_dataset/omniglot-pyStandardTransform
'''
(2)查看数据的特征和标签
需要注意的是:由于深度视觉中的数据属性均有不同,如果简单得调用.data或者.targets很容易报错。本小结最后给出了一个万能方式。
方式一:.data/.targets查看数据特征和标签
当我们查看数据集时,只给出了Number of datapoints、Root location等,但我们想了解的是数据集的输入和标签,针对fminst来说,可以通过调.data的方式查看特征,.target的方式查看标签。
print(fminst.data)
'''
tensor([[[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]],[[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]],[[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]],...,[[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]],[[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]],[[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],...,[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0],[0, 0, 0, ..., 0, 0, 0]]], dtype=torch.uint8)
'''
print(fminst.targets)
'''
tensor([9, 0, 0, ..., 3, 0, 5])
'''
但是并不是所有的数据集都可以通过这种方式来查阅。这是因为:当面临的任务不同时,每个数据集的标签排布方式和意义也都不同,因此不太可能使用相同的API进行调用。
for i in [fminst, svhn, omniglot]:print(i.data.shape)
'''
torch.Size([60000, 28, 28])
(73257, 3, 32, 32)
AttributeError: 'Omniglot' object has no attribute 'data'
'''for i in [fminst, svhn, omniglot]:print(i.targets.shape)
'''
tensor([9, 0, 0, ..., 3, 0, 5])
torch.Size([60000])
AttributeError: 'SVHN' object has no attribute 'targets'
'''
方式二:通过查看某一个索引值的方式来查看特征和标签
因此,我们可以看到omniglot数据并没有data和targets属性,那么我们应该如何查看omniglot数据呢?——通过索引的方式查看某一个单独的数据
#方式一:查看某一个索引的情况
print(omniglot[0])
'''
(tensor([[[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.],...,[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.]]]), 0)
'''
#由此可以看出omniglot的每个索引是一个元组#紧接着我们可以调用每个元组中的第一个切片来查看图像数据的特征和形状
print(omniglot[0][0])
'''
tensor([[[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.],...,[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.],[1., 1., 1., ..., 1., 1., 1.]]])
'''
print(omniglot[0][0].shape)
#torch.Size([1, 105, 105]) ,omniglot数据的图像仅有一个通道,图片的形状是105*105#查看样本量
print(len(omniglot)) #19280
方式三:万能方法
如果通过索引的方式还是报错,那就要使用报错概率最低的方式:
for i in [fminst, svhn, omniglot]:for x,y in i:print(x.shape, y)break
'''
torch.Size([1, 28, 28]) 9
torch.Size([3, 32, 32]) 1
torch.Size([1, 105, 105]) 0
'''
(3)数据可以化
方式一:PIL直接可视化
如果需要查看图片,可以通过去掉transforms.Totensor()来查看
fminst = torchvision.datasets.FashionMNIST(root='/Users/gaoyuxing/Desktop/all_file/torchvision_dataset',train=True,download=False)#transform=transforms.ToTensor())#print(fminst)
#print(fminst[0])
#(<PIL.Image.Image image mode=L size=28x28 at 0x7FB843C23BB0>, 9)
print(fminst[0][0]) #(<PIL.Image.Image image mode=L size=28x28 at 0x7FB843C23BB0>, 9)
image = fminst[0][0]
image.show()

方式二:用一个万能公式来随机可视化五张图
注意:该方法要求已经将图片转换为tensor格式,即要求含有tansform = transforms.ToTensor()
def plotsample(data):fig, axs = plt.subplots(1,5,figsize=(10,10)) #建立子图for i in range(5):num = random.randint(0,len(data)-1) #首先选取随机数,随机选取五次#抽取数据中对应的图像对象,make_grid函数可将任意格式的图像的通道数升为3,而不改变图像原始的数据#而展示图像用的imshow函数最常见的输入格式也是3通道npimg = torchvision.utils.make_grid(data[num][0]).numpy()nplabel = data[num][1] #提取标签#将图像由(3, weight, height)转化为(weight, height, 3),并放入imshow函数中读取axs[i].imshow(np.transpose(npimg, (1, 2, 0)))axs[i].set_title(nplabel) #给每个子图加上标签axs[i].axis("off") #消除每个子图的坐标轴#%%plotsample(omniglot)
plt.show()

plotsample(svhn)
plt.show()
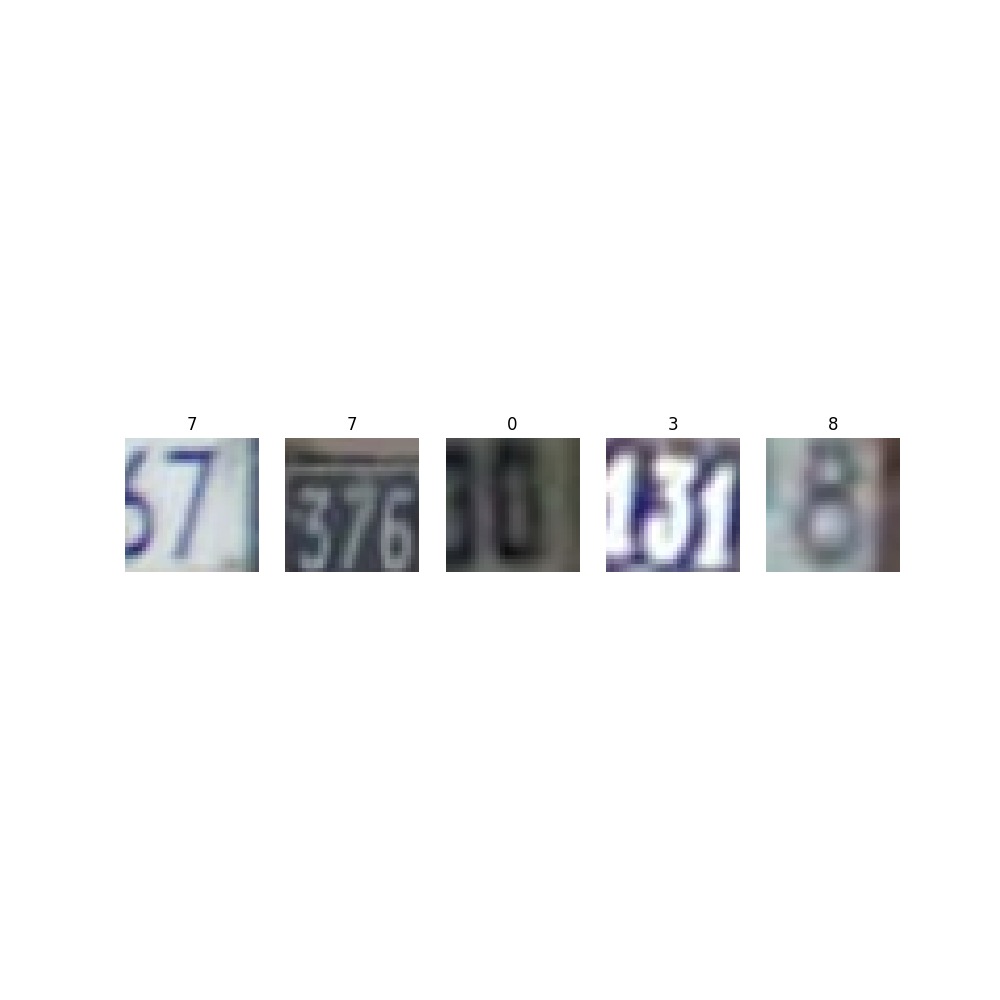
plotsample(fminst)
plt.show()

根据类的不同,参数train可能变为split,还可能增加一些其他的参数,具体可以参照datasets页面。MNIST一组的数据集户都可以被用于简单的识别项目,是测试架构的最佳数据。在提出新架构或新方法时,学者们总会在MNIST或Fashion-MNIST数据集上进行测试,并将这些数据拿到高分(>95%)作为新架构有效的证明之一。
1.2竞赛数据:ImageNet、COCO、VOC、LSUN
除了数字和字母识别以外,最熟悉且最瞩目的就是各大竞赛的主力数据。之前在讲解大规模视觉挑战赛ILSVRC的时候,介绍过ImageNet数据集,和ImageNet数据一样,竞赛数据往往诞生于顶尖大学、顶尖科研机构或大型互联网公司的人工智能实验室,属于推动整个深度学习向前发展的数据集,因此这些数据集通畅数据量巨大、涵盖类别广泛、标签异常丰富、可以被用于各类图像任务,并且每年会更新迭代,且在相关竞赛停止或关闭之后会下架数据集。作为计算机视觉的学习者,我们没有用过这些数据,但是必须要知道它们的名字和基本信息。作为计算机视觉工程师,在每个项目上线之前,都需要使用这些数据来进行测试。现在就来了解一下这些数据集吧。
| 数据名称 | 数据说明 |
|---|---|
| ImageNet2012 | ImageNet大规模视觉挑战赛(ILSVRC)在2012年所使用的比赛数据。1000分类通用数据,涵盖了动植物、人类、生活用品、食物、景色、交通工具等类别。任何互联网大厂在深度学习模型上线之前必用的数据集。2012年版本数据集由于版权原因已在全网下架,现只分享给拥有官方学术头衔的机构或个人(这意味着,在申请数据集时必须使用xxx@xxx.edu的电子邮件,任何免费的、非学术机构性质的电子邮件地址都不能获得数据申请。因此,PyTorch中的torchvision.datasets.ImageNet类已经失效。 |
| ImageNet2019 | ILSVRC在2017年之后就取消了识别任务,并将比赛赚到Kagg了上举办,现在ImageNet2019版本可以在Kaggle上免费现在,主要用于检测任务。 |
| PASCAL VOCSegmentation PASCAL VOCDetection | 模式分析,统计建模和计算机学习大赛(Pattern Analysis, Statistical Modeling and Computation Learning, PSACAL),视觉对象分类(Visual Object Classes)数据集。与ImageNet类型相似,覆盖动植物、人类、生活用品、食物、交通等类别,但数据量相对较小。在PyTorch中被分为VOCSegementation与VOCDetection两个类,分别支持分割和检测任务,虽然带有类别标签但基本不支持识别任务。同时,PyTorch支持从2007到2012年的五个版本的下载,通畅我们都是用最新版本。 |
| CocoCaptions CocoDetection | 微软Microsoft Common Objects in Context数据集,是大规模场景理解挑战赛(Large-scale Scene Understanding challenge,LSUN)中的核心数据,主要覆盖复杂的日常场景,是继ImageNet之后,最受关注的物体检测、语义分割、图像理解(Caption)方面的数据集,也是唯一关注图像理解的大规模挑战赛。其中,用于图像理解的部分是2015年之前的数据,用于检测和分割的则是2017年及之后的版本。需要安装COCO API才可以调用。PyTorch没有提供用于分割的API,但我们依然可以自己下载数据集用于分割。 |
| LSUN | 城市景观、城市建筑、人文风光数据集,包含10中场景、20中对象的大猩猩数据集。其中,场景图像被用于LSUN大规模题场景理解挑战赛。20分类包含交通工具、动物、人类等图像,可用于识别任务。在我们导入数据时,我们会选择LSUN中的某一个场景或对象进行训练,因此个人给予LSUN进行的识别任务是二分类的。 |
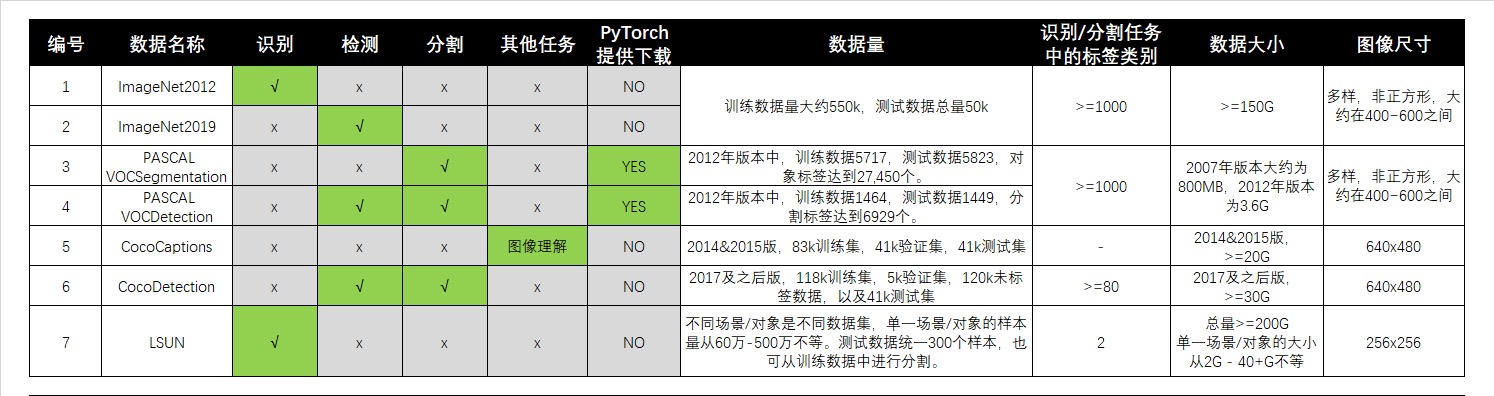
各个数据集的样图如下所示:




这类数据集最大的特点就是数据量大、原图尺寸很大,因此整个数据集所占用的存储空间也会更大。最小的VOC数据集3.6G左右,其他都在20G以上。PyTorch只提供了VOC的下载通道,但这个下载通道极不稳定,因此最好提前下载好将数据放入根目录中进行读取。
竞赛数据都来自于各大机构和大学的研究,因此其风格和调用流程不可能一致,使用每个数据集都需要进行一定的探索,还必须具备一定的英文阅读、谷歌翻译能力、GitHub使用、python脚本编程能力。课程准备了2012年的ImageNet数据集、VOC以及LSUN数据集中较小的两类数据,并准备了可以运行下载LSUN其他类别数据的python脚本和readme文档。其中VOC适用于分割和检测任务,ImageNet和LSUN适用于分类任务。
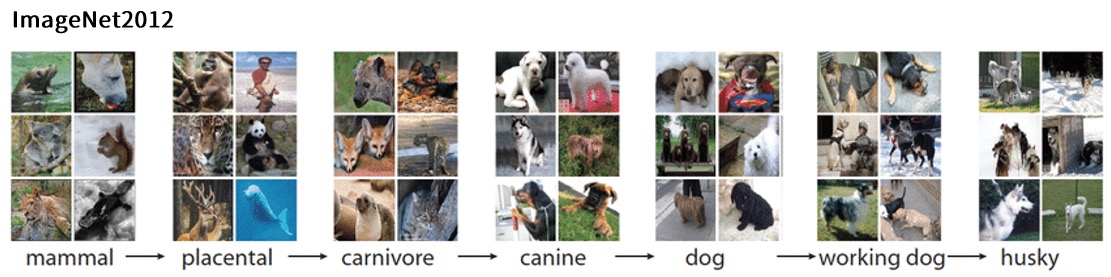
值得一提的是,LSUN竞赛现已关闭,因此测试集已无法下载,但训练集和验证集还是可以下载。LSUN各个类别的数据集大小如下所示。在课程中,我给大家下载了户外教堂以及教室两个类别,可以用于分类。
如何还需要LSUN其他类别的数据时,可以在cmd(Windows)/terminal(MAC)中执行以下命令:
#首先将cmd根目录切换到download.py所在的目录
#切换到同一个盘的不同目录
C:\Users\Admin>cd C:\dataset2\lsun-master
#切换到不同盘的目录
C:\Users\Admin>cd /d F:datasets2\lsun-master
#切换到相应目录后运行下载,其中church_outdoor是其中一个类别
F:datasets2\lsun-master>python download.py -c church_outdoor
LSUN数据集下载后是压缩文件,解压之后是LMBD(Lightning Memory-Mapped Database)数据库的文件。在深度学习中,有许多大型突袭那个数据集都是存储为LMBD文件的,因为框架Caffe和TensorFlow在早起使用了大量存储为LMBD格式的数据集。从LMBD数据库中读取的代码并不复杂,但需要多数据库和LMBD相关的基础知识。幸运的是:LSUN的LMBD文件可以直接通过PyTorch中datasets下的类来直接调用(下载老师提供的数据之后一定要把里面的数据解压出来,因为torchvision无法识别压缩包),具体的代码如下:
data_val = torchvision.datasets.LSUN(root="/Users/gaoyuxing/Desktop/all_file/torchvision_dataset/LSUN/data",classes=["church_outdoor_val"],transform=transforms.ToTensor())print(data_val)
'''
Dataset LSUNNumber of datapoints: 300Root location: /Users/gaoyuxing/Desktop/all_file/torchvision_dataset/LSUN/dataClasses: ['church_outdoor_val']StandardTransform
Transform: ToTensor()
'''print(data_val[0])
'''
(tensor([[[0.4627, 0.4627, 0.4667, ..., 0.7137, 0.7098, 0.7098],[0.4627, 0.4627, 0.4667, ..., 0.7255, 0.7176, 0.7098],[0.4627, 0.4627, 0.4667, ..., 0.7333, 0.7255, 0.7176],...,[0.3137, 0.3412, 0.3216, ..., 0.6471, 0.6392, 0.6353],[0.1961, 0.2353, 0.2078, ..., 0.6471, 0.6392, 0.6314],[0.1843, 0.2235, 0.1765, ..., 0.6510, 0.6392, 0.6314]],[[0.5647, 0.5647, 0.5686, ..., 0.7059, 0.7020, 0.7020],[0.5647, 0.5647, 0.5686, ..., 0.7176, 0.7098, 0.7020],[0.5647, 0.5647, 0.5686, ..., 0.7255, 0.7176, 0.7098],...,[0.3137, 0.3412, 0.3216, ..., 0.6510, 0.6431, 0.6392],[0.2000, 0.2392, 0.2118, ..., 0.6510, 0.6431, 0.6353],[0.1882, 0.2275, 0.1804, ..., 0.6549, 0.6431, 0.6353]],[[0.7882, 0.7882, 0.7922, ..., 0.7098, 0.7059, 0.7059],[0.7882, 0.7882, 0.7922, ..., 0.7216, 0.7137, 0.7059],[0.7882, 0.7882, 0.7922, ..., 0.7294, 0.7216, 0.7137],...,[0.3059, 0.3333, 0.3137, ..., 0.6706, 0.6627, 0.6588],[0.1804, 0.2196, 0.1922, ..., 0.6706, 0.6627, 0.6549],[0.1647, 0.2039, 0.1608, ..., 0.6745, 0.6627, 0.6549]]]), 0)
'''#随机查看五张图
plotsample(data_val)
plt.show()

只导入一个类别时,该类别是没有标签的,可以通过以下代码来验证:
check_ = 0
for x,y in data_val:check_ += y
print(check_)
#0
想要进行训练,至少得导入两个类别,进行二分类:
data_train = torchvision.datasets.LSUN(root="/Users/gaoyuxing/Desktop/all_file/torchvision_dataset/LSUN/data",classes=["church_outdoor_train", "classroom_train"],transform=transforms.ToTensor())data_val = torchvision.datasets.LSUN(root="/Users/gaoyuxing/Desktop/all_file/torchvision_dataset/LSUN/data",classes=["church_outdoor_val", "classroom_val"],transform=transforms.ToTensor())print(data_val)
'''
Dataset LSUNNumber of datapoints: 600Root location: /Users/gaoyuxing/Desktop/all_file/torchvision_dataset/LSUN/dataClasses: ['church_outdoor_val', 'classroom_val']StandardTransform
Transform: ToTensor()
'''#此时标签自动被标注为0和1
#由于循环代码在data_train上运行会爆炸,因此在验证集上跑
'''
for x,y in data_val:print(y)
'''check_ = 0
for x,y in data_val:check_ += y
print(check_)
#300
很遗憾的是,ImageNet数据集并不能使用PyTorch中的datasets下的类来直接调用(能够被pytorch直接调用的都是tar.gz格式文件或者是tar.gz解压后的文件),而VOC不能作为识别数据被使用,因此希望调用竞赛数据来完成分类任务则需要更多的技巧,接下来会在《一、2.使用自己的数据/图片创造数据集》中,将ImageNet和LSUN数据作为案例来说明,如何将压缩文件/数据库文件中的图片导出为四维tensor。
如果没有GPU,不推荐使用ImageNet。虽然比起LSUN和VOC来,ImageNet含有更丰富的数据,但是没有GPU的支持,很难对该数据进行适当的训练。如果要使用ImageNet数据,建议使用Colab等线上平台的大型GPU上训练。
1.3景物、人脸、通用、其他
如果入门数据太简单,竞赛数据又太大该怎么办呢?难道就没有尺寸适中,又非常适合初学者练习和试验的数据集吗?当然有。除了竞赛数据和入门数据,我们还有不少通用的数据集,比如:
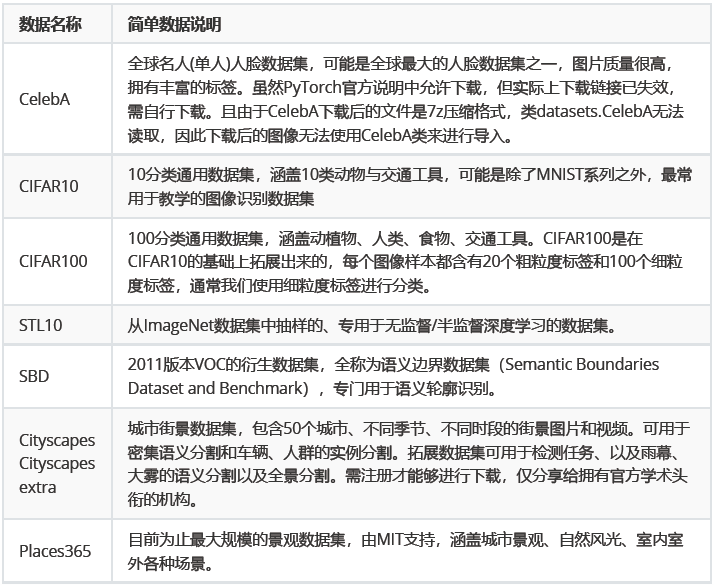
部分数据集的样例如下所示:
【CelebA】强烈推荐,一共有40种属性类别,1000个个体标签,可以用来做识别任务。

【CIFAR10 & CIFAR100】CIFAR多用于模型验证,很标准也很简单。基本上模型创新都会在CIFAR数据上跑一跑。

【STL-10】不是很推荐,多用于无监督学习任务。

【Cityscapes】

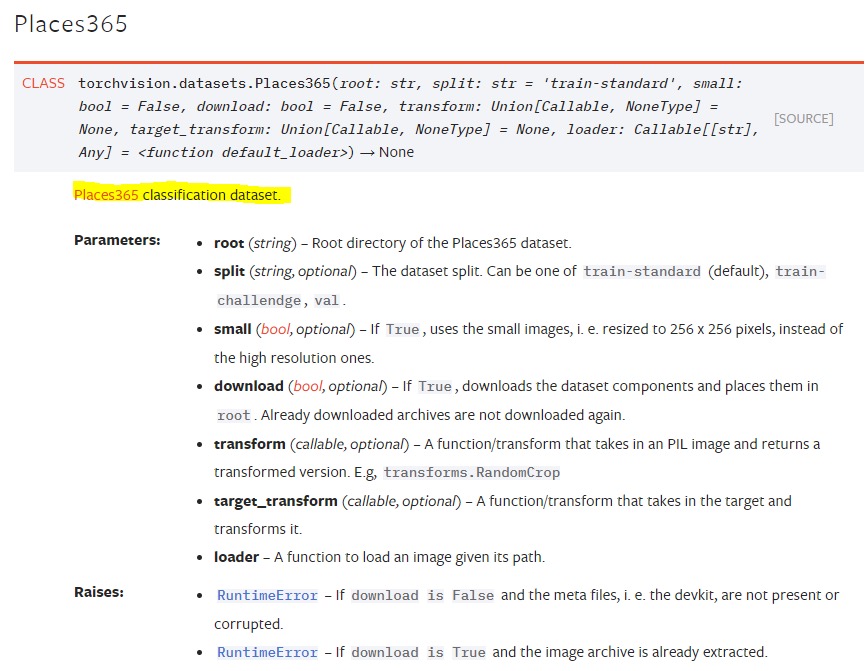
【Place365】场景非常丰富,有400多个类别,可以用于多分类任务,由MIT支持。

在图像识别中我们比较常用的是CIFAR,因此我们以CIFAR为例来调用下这个数据集:
data = torchvision.datasets.CIFAR10(root="/Users/gaoyuxing/Desktop/all_file/torchvision_dataset/cifar",train=True,download=False,transform=transforms.ToTensor())print(data)
'''
Dataset CIFAR100Number of datapoints: 50000Root location: /Users/gaoyuxing/Desktop/all_file/torchvision_dataset/cifarSplit: TrainStandardTransform
Transform: ToTensor()
'''for x,y in data:print(x, y)break#通过结果可以看出来x,y没有打包成元组的形式,是独立的print(data.data.shape)
#(50000, 32, 32, 3) 一共5万张图,每张图的尺寸是(32, 32),三通道图
#print(data.classes)
'''
['apple', 'aquarium_fish', 'baby', 'bear', 'beaver', 'bed', 'bee', 'beetle', 'bicycle', 'bottle', 'bowl', 'boy', 'bridge', 'bus', 'butterfly', 'camel', 'can', 'castle', 'caterpillar', 'cattle', 'chair', 'chimpanzee', 'clock', 'cloud', 'cockroach', 'couch', 'crab', 'crocodile', 'cup', 'dinosaur', 'dolphin', 'elephant', 'flatfish', 'forest', 'fox', 'girl', 'hamster', 'house', 'kangaroo', 'keyboard', 'lamp', 'lawn_mower', 'leopard', 'lion', 'lizard', 'lobster', 'man', 'maple_tree', 'motorcycle', 'mountain', 'mouse', 'mushroom', 'oak_tree', 'orange', 'orchid', 'otter', 'palm_tree', 'pear', 'pickup_truck', 'pine_tree', 'plain', 'plate', 'poppy', 'porcupine', 'possum', 'rabbit', 'raccoon', 'ray', 'road', 'rocket', 'rose', 'sea', 'seal', 'shark', 'shrew', 'skunk', 'skyscraper', 'snail', 'snake', 'spider', 'squirrel', 'streetcar', 'sunflower', 'sweet_pepper', 'table', 'tank', 'telephone', 'television', 'tiger', 'tractor', 'train', 'trout', 'tulip', 'turtle', 'wardrobe', 'whale', 'willow_tree', 'wolf', 'woman', 'worm']
'''print(np.unique(data.targets)) #一共100个标签
'''
[0 1 2 3 4 5 6 7 8 9]
'''data_test = torchvision.datasets.CIFAR10(root="/Users/gaoyuxing/Desktop/all_file/torchvision_dataset/cifar",train=False,download=False,transform=transforms.ToTensor())print(data_test)
'''
Dataset CIFAR10Number of datapoints: 10000Root location: /Users/gaoyuxing/Desktop/all_file/torchvision_dataset/cifarSplit: TestStandardTransform
Transform: ToTensor()
'''plotsample(data)
plt.show()

data100 = torchvision.datasets.CIFAR100(root="/Users/gaoyuxing/Desktop/all_file/torchvision_dataset/cifar",train=False,download=False,transform=transforms.ToTensor())
print(data100)
'''
Dataset CIFAR100Number of datapoints: 10000Root location: /Users/gaoyuxing/Desktop/all_file/torchvision_dataset/cifarSplit: TestStandardTransform
'''print(np.unique(data100.targets))
'''
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 2324 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 4748 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 7172 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 9596 97 98 99]
'''
plotsample(data100)
plt.show()

以上是对常用数据的介绍,对于未介绍的数据,一般如何去找?一般不推荐PyTorch自带的download功能,由于数据集尺寸不小,官网下载速度比较慢,还容易出现超时的问题,因此最好不好使用download参数。
如下图所示,对于PyTorch自带的数据集,可以从数据说明中找到这个数据集的官网或者原始地址,进入原始地址后,大部分可以找到数据的下载渠道。当然,通过原始地址下载的数据很有可能不能用torchvision.datasets来读取。
由于图像数据调用接口多不相同,在调用的时候会出现各种各样的Bug,因此如果不能用torchvision来调用时,我们可以将图片数据作为自己的数据进行处理。于是就引出了下一节的内容: 使用自己的数据/图片创造数据集。
2、使用自己的数据/图片创造数据集
如果我们拥有自己的数据集,首先要考虑的是如何将自己的数据输入到PyTorch中去。如果数据来自于网络(Kaggle下载,从论文作者处获取,从某个数据集官网下载的),那原始数据的格式可能是各种情况,最常见的是各类压缩文件、pt文件、数据库格式文件或者是png/jpg/webp等原始图像。如果数据来自于实验室、公司数据库或者是领导/导师给的数据,大概率是csv/txt/mat等结构的二维数据表。无论我们的原始数据集呈现什么样的格式,必须将其转换为四维张量,数据才能被卷积神经网络处理。对于任意压缩文件,先解压查看内部是什么内容,对于其他格式文件,可以根据需求查看本节中对应的小节。
2.1从图像png/jpg到四维tensor
ImageFolder
当我们的数据是一系列图像时,并且每个标签对应的图像是存放在单独的文件夹中时,处理方式比较简单。在torchvision中存在直接将文件夹中图片打包成tensor的类:ImageFolder,它的参数和torchvision.datasets中其他数据导入类的参数非常相似,其中root是原始图像所在的根目录,transform是希望对图像执行的具体操作。
train_dataset = torchvision.datasets.ImageFolder(root='xxx',transform=torchvision.transforms.ToTensor())
这个类可以接受.jpg、.jpeg、.png、.ppm、.bmp、 .pgm、.tif、.tiff、.webp这九种不同的图片格式输入,并且还能够通过文件夹的分类自动识别标签。 如果图片打包成一下所示的特定格式,就是用于ImageFolder这个类:

在根目录下,每个类别需要有单独的文件夹,如上图所示,cat和dog就是两个种类,而类别文件夹下可以存放多个子文件夹或者直接存放图片。图片的格式不需要统一,只要是ImageFolder能接受的9种格式即可。接下来就以celebA数据中随机提取出来的子集为例来做实验。
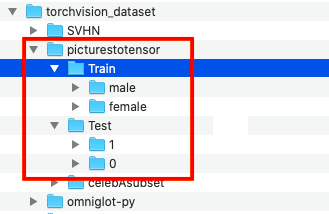
train_dataset = torchvision.datasets.ImageFolder(root="/Users/gaoyuxing/Desktop/all_file/torchvision_dataset/picturestotensor/Train",transform=torchvision.transforms.ToTensor())print(train_dataset)
'''
Dataset ImageFolderNumber of datapoints: 60Root location: /Users/gaoyuxing/Desktop/all_file/torchvision_dataset/picturestotensor/TrainStandardTransform
Transform: ToTensor()
'''for x, y in train_dataset:print(x, y)break'''
tensor([[[0.9922, 0.9922, 0.9922, ..., 0.9961, 0.9961, 0.9961],[0.9922, 0.9922, 0.9922, ..., 0.9961, 0.9961, 0.9961],[0.9922, 0.9922, 0.9922, ..., 0.9961, 0.9961, 0.9961],...,[0.9922, 0.9922, 0.9922, ..., 0.9569, 0.9255, 0.9373],[0.9922, 0.9922, 0.9922, ..., 0.9843, 0.9373, 0.9333],[0.9922, 0.9922, 0.9922, ..., 1.0000, 0.9490, 0.9412]],[[0.9059, 0.9059, 0.9059, ..., 0.9569, 0.9569, 0.9569],[0.9059, 0.9059, 0.9059, ..., 0.9569, 0.9569, 0.9569],[0.9059, 0.9059, 0.9059, ..., 0.9569, 0.9569, 0.9569],...,[0.8549, 0.8549, 0.8549, ..., 0.6784, 0.6667, 0.7020],[0.8549, 0.8549, 0.8549, ..., 0.7059, 0.6784, 0.6980],[0.8549, 0.8549, 0.8549, ..., 0.7255, 0.6941, 0.6980]],[[0.7529, 0.7529, 0.7529, ..., 0.8588, 0.8588, 0.8588],[0.7529, 0.7529, 0.7529, ..., 0.8588, 0.8588, 0.8588],[0.7529, 0.7529, 0.7529, ..., 0.8588, 0.8588, 0.8588],...,[0.6902, 0.6902, 0.6902, ..., 0.4745, 0.4706, 0.5059],[0.6902, 0.6902, 0.6902, ..., 0.4941, 0.4745, 0.5020],[0.6902, 0.6902, 0.6902, ..., 0.4941, 0.4824, 0.4980]]]) 0
'''#几种可以调用的属性
print(train_dataset.classes)
#['female', 'male']
print(train_dataset.targets)
'''
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
'''#查看具体的图像地址
print(train_dataset.imgs)
#这里展示的是每张图的图纸plotsample(train_dataset)
plt.show()
#测试集-注意更换根目录
test_dataset = torchvision.datasets.ImageFolder(root="/Users/gaoyuxing/Desktop/all_file/torchvision_dataset/picturestotensor/Test",transform=torchvision.transforms.ToTensor())print(test_dataset)
'''
Dataset ImageFolderNumber of datapoints: 62Root location: /Users/gaoyuxing/Desktop/all_file/torchvision_dataset/picturestotensor/TestStandardTransform
Transform: ToTensor()
'''
plotsample(test_dataset)
plt.show()

注意,ImageFolder只能读取根目录的子文件夹中的图片,并且一定会将子文件夹的名称作为类别。当根目录中只有一个文件夹时,则会将有图片的标签标注为0。当根目录中没有文件夹,而是直接存放图片时则会报错。
毫无疑问,ImageFolder是一个省时省力的方式,但是简单也意味着它不够灵活。当图像相关标签类别数量很少,我们还能够将图像按照它们所在的标签类别打包,当数据的标签类别比较多,或者样本量比较大的时,要将同一标签类别的样本分到不同类比的文件夹中就变得不再“省时省力”。但幸运的是,在图像的世界里,许多数据集、尤其是巨大数据集是提前按照标签“分好”的,比如我们之前看过的LSUN数据集。
对类似于LSUN的数据集,我们会按照标签类别分别对数据进行下载,如果下载后获得的数据是这个类别下的图片文件,那毫无疑问这些文件是可以按照类别被储存在单独的文件夹里的。此时我们就可以使用ImageFolder来对数据进行读取。当然了,如果你的数据不是按照标签类别进行下载,或你的标签类别是单独储存在excel或txt文件当中,我们就需要别的操作来读取数据了。
使用ImageFolder读取后的数据是无法轻易更改标签的,这是因ImageFolder继承自pytorch中的visiondataset类,标签在这个父类中生成,并与特征图一起被固定为一个元组(用来表示从特征到标签的映射)。我们可以通过ImageFolder的各种属性、或索引等方式调用出这个元组的一份复制来进行展
示,却无法直接触及到元组中的数据本身,因此我们无法通过ImageFolder的读取出的标签进行改变。虽然我们可以先从ImageFolder的结果中复制出特征图,再使用TensorDatasets重新对特征图和标签进行拼接,但Python并不支持对元组的批量操作,如果需要复制每个特征图,就必须对每个元组进行循
环。但当数据量很大时,从ImageFolder的结果中提取全部样本就会需要很多时间和算力。因此,当数据不能按照类别进行下载时,大部分深度学习研究者都不会使用ImageFolder对数据进行读取,而会选择更加灵活的方式:自己写一个读取数据用的类。
####Clasee torch.utils.data.Dataset
在PyTorch中存在一个专门帮我们构建数据集的类:Dataset,这个类在torch.utils.data模块下。属于PyTorch数据处理的经典父类之一(另一个总是使用的经典父类是nn.Moudle)。在PyTorch中,许多torchvision.datasets中读数据的类,以及TensorDataset这些合并张量来生成数据的类,都继承自Dataset。如果一个读取数据的类继承自Dataset,那它读取出的数据一定是可以通过索引的方式进行调用和查看的,而继承自其他父类的、读取数据集的功能却不一定能使用索引进行查看,这种性质让Dataset子类的构成也与其他类不同。
Dataset中规定,如果一个子类要继承Dataset,则必须在子类中定义__getitem__() 方法。从这个方法的名字(get item,获取对象)也可以看出,它是帮助我们“获取对象”的方法。这个方法中的代码必须满足三个功能:
1)读取单个图片并转化为张量
2)读取该图片对应的标签
3)将该图片的张量与对应标签打包成一个样本并输出
该样本的形式是一个元组,元组中的第一个对象是图像张量,第二个对象是该图像对应的标签。
Dataset类中包含自动循环__getitem__() 并拼接其输出结果的功能。也就是说,对于任意继承自Dataset的子类,只要我们恰当地定义了__getitem__() ,该子类的输出就一定是打包好的整个数据集。我们可以根据数据的实际情况定义__getitem__() ,可以说是实现了最大程度上的灵活性。
现在,我们使用celebA数据集举个例子。完整的celebA数据集中包含图片20万+张(图像大小20G),其中个体识别的标签为“人名”,类别有10,177个,属性识别的标签有40个,每个标签下是二分类,两种标签类别在txt中的格式不同。如果你感兴趣源文件,你可以在课程数据集的dataset3中找到它。将压缩文件解压后,即可获得具体的图像。
在课程中,我准备了包含1000张图片的celebA的子集dataset4\picturetotensor\celebAsubset文件夹中。
这个文件夹中的目录层次与dataset3中的celebA的原始数据集完全一致,只不过这个文件夹的图像和标签都只有前一千个样本。该子集仅作为读取数据用的例图,并不能被用于建模,如果需要建模请使用原始的20G大小的完整数据集。
在例图上,我们将展示如何使用继承自Dataset的类读取不同的图片和标签类别,你可以自由将数据更换为你的数据进行相同的操作。以下是我的根目录、个体识别的标签txt以及属性识别的标签txt:
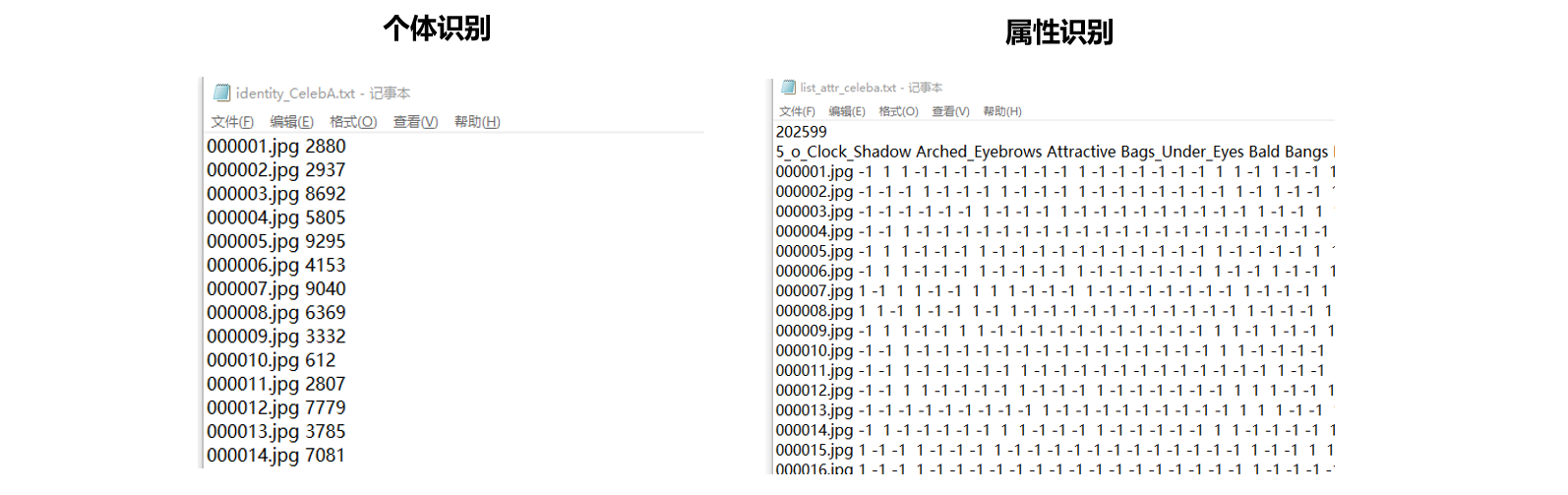
在写具体的类之前,我们可以先定义__getitem__() 方法中要求的内容,试着读取一张图片并生成样本的元组。在CV课程最开始的时候,我们使opencv中的cv.imread函数进行过图像的读取。事实上,有大量的库中都包含能够将图像转化为像素值的函数,原则上我们可以使用任何自己熟悉的函数。在本节课中我们pytorch官方推荐的scikit-learn图像处理库scikit-image来进行处理,只要你的环境中安装有sklearn。我们可以通过下面的代码进行检查:
from skimage import io#包含了所有图像的目录,没有具体到某一张图像
imgpath=r'/Users/gaoyuxing/Desktop/all_file/torchvision_dataset/picturestotensor/celebAsubset/Img/Img_celeba.7z/img_celeba'#标签文件的目录
csvpath = r'/Users/gaoyuxing/Desktop/all_file/torchvision_dataset/picturestotensor/celebAsubset/Anno/identity_CelebA_1000.txt'identity = pd.read_csv(csvpath, sep=" ", header=None) #txt文件是以空格为分割符的#print(identity.head())
'''0 1
0 000001.jpg 2880
1 000002.jpg 2937
2 000003.jpg 8692
3 000004.jpg 5805
4 000005.jpg 9295'''#读一张图
image = io.imread("/Users/gaoyuxing/Desktop/all_file/torchvision_dataset/picturestotensor/celebAsubset/Img/Img_celeba.7z/img_celeba/000001.jpg")
plt.imshow(image)
plt.axis("off")
plt.show()
#将读取的标签和图像合并idx = 0
imgpath=r'/Users/gaoyuxing/Desktop/all_file/torchvision_dataset/picturestotensor/celebAsubset/Img/Img_celeba.7z/img_celeba'
#标签文件的目录
csvpath = r'/Users/gaoyuxing/Desktop/all_file/torchvision_dataset/picturestotensor/celebAsubset/Anno/identity_CelebA_1000.txt'
identity = pd.read_csv(csvpath, sep=" ", header=None) #txt文件是以空格为分割符的imgdic = os.path.join(imgpath, identity.iloc[idx, 0])
#print(io.imread(imgdic))
image = torch.tensor(io.imread(imgdic))sample = (image, identity.iloc[idx, 1])#print(image.shape) #torch.Size([687, 409, 3])
#print(sample)
'''
(tensor([[[253, 231, 192],[253, 231, 192],[253, 231, 192],...,[254, 244, 219],[254, 244, 219],[254, 244, 219]],[[253, 231, 192],[253, 231, 192],[253, 231, 192],...,[254, 244, 219],[254, 244, 219],[254, 244, 219]],[[253, 231, 192],[253, 231, 192],[253, 231, 192],...,[254, 244, 219],[254, 244, 219],[254, 244, 219]],...,[[253, 218, 176],[253, 218, 176],[253, 218, 176],...,[244, 173, 121],[236, 170, 120],[239, 179, 129]],[[253, 218, 176],[253, 218, 176],[253, 218, 176],...,[251, 180, 126],[239, 173, 121],[238, 178, 128]],[[253, 218, 176],[253, 218, 176],[253, 218, 176],...,[255, 185, 126],[242, 177, 123],[240, 178, 127]]], dtype=torch.uint8), 2880)
'''plt.imshow(image)
plt.show()
根据以上内容可以先写一个初级版本的类来构建图像数据,将图片数据与个体标签属性组装在一起。
from torch.utils.data import Dataset
import os
from skimage import ioclass CustomDataset(Dataset):def __init__(self, root_dir, csv_file, transform = None):super(CustomDataset, self).__init__( )self.imgpath = root_dirself.identity = pd.read_csv(csv_file, sep=" ", header=None)self.transform = transformdef __getitem__(self, idx):imgdic = os.path.join(self.imgpath, self.identity.iloc[idx, 0])label = self.identity.iloc[idx, 1]image = io.imread(imgdic)sample = (image, label)return sample
接下来再写一个升级版的:
import pandas as pd
import torch
from torch.utils.data import Dataset
from torchvision import transforms
import os
import numpy as np
from skimage import ioclass CustomDataset(Dataset):def __init__(self, root_dir, csv_file, transform = None):super(CustomDataset, self).__init__()self.imgpath = root_dirself.identity = pd.read_csv(csv_file, sep=" ", header=None)self.transform = transformdef __len__(self):return len(self.identity)def __info__(self):print("CustomData")print('\t Number of sample:{}'.format(len(self.identity)))print("\t Number of classes:{}".format(len(np.unique(self.identity.iloc[:, 1]))))print("\t root_dir:{}".format(self.imgpath))def __getitem__(self, idx):#保证 idx 不是一个tensorif torch.is_tensor(idx):idx = idx.tolist()imgdic = os.path.join(self.imgpath, self.identity.iloc[idx, 0])label = self.identity.iloc[idx, 1]image = io.imread(imgdic)if self.transform != None:image = self.transform(image)sample = (image, label)return sampleimgpath=r'/Users/gaoyuxing/Desktop/all_file/torchvision_dataset/picturestotensor/celebAsubset/Img/Img_celeba.7z/img_celeba'
#标签文件的目录
csvpath = r'/Users/gaoyuxing/Desktop/all_file/torchvision_dataset/picturestotensor/celebAsubset/Anno/identity_CelebA_1000.txt'data = CustomDataset(root_dir=imgpath, csv_file=csvpath, transform = transforms.ToTensor())print(data.__info__())
'''
CustomDataNumber of sample:1000Number of classes:922root_dir:/Users/gaoyuxing/Desktop/all_file/torchvision_dataset/picturestotensor/celebAsubset/Img/Img_celeba.7z/img_celeba
'''
print(data.__len__())
#1000for x, y in data:print(x.shape, y)#torch.Size([3, 687, 409]) 2880break17.3.2将二维表及其他结构转换为四维tensor
要点1:多项式升维:from sklearn.preprocessing import PolynomialFeatures as PF. 在多项式升维中,维度指的是特征维度,而非张量的维度。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。




