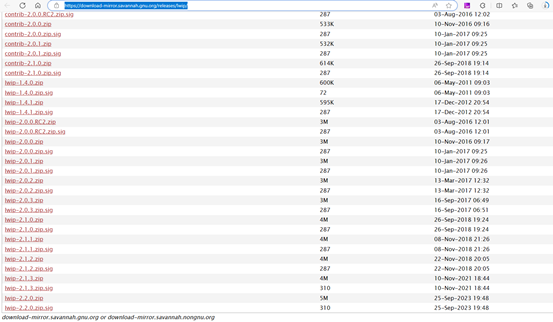
Index of /releases/lwip/ (gnu.org)
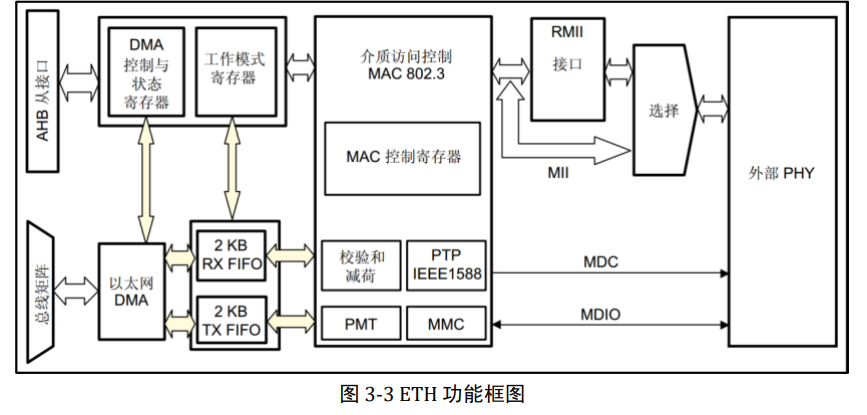
以太网(Ethernet)是互联网技术的一种,由于它是在组网技术中占的比例最高,很多人 直接把以太网理解为互联网。 以太网是指遵守 IEEE 802.3 标准组成的局域网,由 IEEE 802.3 标准规定的主要是位于 参考模型的物理层(PHY)和数据链路层中的介质访问控制子层(MAC)。在家庭、企业和学 校所组建的 PC 局域网形式一般也是以太网,其标志是使用水晶头网线来连接(当然还有其 它形式)。 IEEE 还有其它局域网标准,如 IEEE 802.11 是无线局域网,俗称 Wi-Fi。 IEEE802.15 是个人域网,即蓝牙技术,其中的 802.15.4 标准则是 ZigBee 技术。 现阶段,工业控制、环境监测、智能家居的嵌入式设备产生了接入互联网的需求,利 用以太网技术,嵌入式设备可以非常容易地接入到现有的计算机网络中。
RAW/Callback API 的优点是显著的,但缺点也是显著的: (1)基于回调函数开发应用程序时的思维过程比较复杂。在后面与 RAW/Callback API 相关的章节中可以看到,利用回调函数去实现复杂的业务逻辑时,会很麻烦,而且代 码的可读性较差。 (2)在操作系统环境中,应用程序代码与内核代码处于同一个线程,虽然能够节省任 务间通信和切换任务的开销,但是相应地,应用程序的执行会制约内核程序的执行,不同 的应用程序之间也会互相制约。在应用程序执行的过程中,内核程序将不可能得到运行, 这会影响网络数据包的处理效率。如果应用程序占用的时间过长,而且碰巧这时又有大量 的数据包到达,由于内核代码长期得不到执行,网卡接收缓存里的数据包就持续积累,到 最后很可能因为满载而丢弃一些数据包,从而造成丢包的现象。
简单来说,NETCONN API 的优缺点是: (1)相较于 RAW/Callback API,NETCONN API 简化了编程工作,使用户可以按照 操作文件的方式来操作网络连接。但是,内核程序和网络应用程序之间的数据包传递,需 要依靠操作系统的信号量和邮箱机制完成,这需要耗费更多的时间和内存,另外还要加上 任务切换的时间开销,效率较低。 (2)相较于 Socket API,NETCONN API 避免了内核程序和网络应用程序之间的数据 拷贝,提高了数据递交的效率。但是,NETCONN API 的易用性不如 Socket API 好,它需 要用户对 LwIP 内核所使用数据结构有一定的了解。
SOCKET API Socket,即套接字,它对网络连接进行了高级的抽象,使得用户可以像操作文件一样 操作网络连接。它十分易用,许多网络开发人员最早接触的就是 Socket 编程,Socket 已经 成为了网络编程的标准。在不同的系统中,运行着不同的 TCP/IP 协议,但是只要它实现了 Socket 的接口,那么用 Socket 编写的网络应用程序就能在其中运行。可见用 Socket 编写的 网络应用程序具有很好的可移植性。 不同的系统有自己的一套 Socket 接口。Windows 系统中支持的是 WinSock, UNIX/Linux 系统中支持的是 BSD Socket,它们虽然风格不一致,但大同小异。LwIP 中的 Socket API 是 BSD Socket。但是 LwIP 并没有也没办法实现全部的 BSD Socket,如果开发 人员想要移植 UNIX/Linux 系统中的网络应用程序到使用 LwIP 的系统中,就要注意这一点。 相较于 NETCONN API, Socket API 具有更好的易用性。使用 Socket API 编写的程序 可读性好,便于维护,也便于移植到其它的系统中。Socket API 在内核程序和应用程序之 间存在数据的拷贝,这会降低数据递交的效率。另外,LwIP 的 Socket API 是基于 NETCONN API 实现的,所以效率上相较前者要打个折扣。
ethernetif_init()函数是在上层管理网卡 netif 的到时候会被调用的函数,如使用 netif_add()添加网卡的时候,就会调用 ethernetif_init()函数对网卡进行初始化,其实该函数 的最终调用的初始化函数就是 low_level_init()函数,我们目前只有一个网卡,就暂时不用 对该函数进行改写,直接使用即可,它内部会将网卡的 name、output、linkoutput 等字段进 行初始化,这样子就能将内核与网卡无缝连接起来。 ethernetif_input()函数的主要作用就是调用 low_level_input()函数从网卡中读取一个数据 包,然后解析该数据包的类型是属于 ARP 数据包还是 IP 数据包,再将包递交给上层,在 无操作系统的时候 ethernetif_input()就是一个可以直接使用的函数,已经无需我们自己去修 改,内核会周期性处理该接收函数。而在多线程操作系统的时候,我们一般会将其改写成 一个线程的形式,可以周期性去调用 low_level_input()网卡接收函数;也可以使用中断的形 式去处理,当这个线程将在尚未接收到数据包的时候,处于阻塞状态,当收到数据包的时 候,中断利用操作系统的 IPC 通信机制来唤醒线程去处理接收到的数据包,并将数据包递 交上层,这样子的效率会更加高效,事实上我们也是这样子处理的。
PBUF_POOL 类型的 pbuf 与 PBUF_RAM 类型的 pbuf 都是差不多的,其 pbuf 结构体与 数据缓冲区也是存在于连续的内存块中,但它的空间是通过内存池分配的,这种类型的 pbuf 可以在极短的时间内分配得到,因为这是内存池分配策略的优势,在网卡接收数据的 时候,LwIP 一般就使用这种类型的 pbuf 来存储接收到的数据,申请 PBUF_POOL 类型时, 协议栈会在内存池中分配适当的内存池个数以满足需要的数据区域大小。
pbuf 的释放要小心,如果 pbuf 是串成链表的话, pbuf 在释放的时候,就会把 pbuf 的 ref 值减 1,然后函数会判断 ref 减完之后是不是变成 0,如果是 0 就会根据 pbuf 的类型调 用内存池或者内存堆回收函数进行回收。然后这里就有个很危险的事,对于这个 pbuf_free() 函数,用户传递的参数必须是链表头指针,假如不是链表头而是指向链表中间的某个 pbuf 的指针,那就很容易出现问题,因为这个 pbuf_free()函数可不会帮我们检查是不是链表头, 这样子势必会导致一部分 pbuf 没被回收,意味着一部分内存池就这样被泄漏了,以后没办 法用了。同时,还可能将一些尚未处理的数据回收了,这样子整个系统就乱套了。
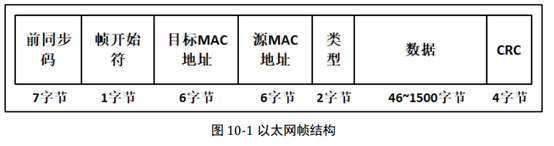
在以太网帧中,目标 MAC 地址可以分成三类,单播地址、多播地址和广播地址。单 播地址通常是与某个网卡的 MAC 地址对应,它要求以太网第一个字节的 bit0(最先发出去 的位)必须是 0;而多播地址则要求第一个字节的 bit0 为 1,这样子多播地址就不会与任何 网卡的 MAC 地址相同,可以被多个网卡同时接收;广播地址的 48 位 MAC 地址全为 1, 也就是 FF-FF-FF-FF-FF-FF, 同一局域网内的所有网卡都会收到广播的数据包。
所以 ARP 缓存表是一个动态更新的过程,为什么要动态更新呢?因为以太网的物理性 质并不能保证数据传输的是可靠的。以太网发送数据并不会知道对方是否已经介绍成功, 而两台主机的物理线路不可能一直保持有效畅通,那么如果不是动态更新的话,主机就不 会知道另一台主机是否在工作中,这样子发出去的数据是没有意义的。比如两台主机 A 和 B,一开始两台主机都是处于连接状态,能正常进行通信,但是某个时刻主机 B 断开了, 但是主机 A 不会知道主机 B 是否正常运行,因为以太网不会提示主机 B 已经断开,那么主 机 A 会一直按照 MAC 地址发送数据,而此时在物理链路层就已经是不通的,那么这些数 据是没有意义的,而如果 ARP 动态更新的话,主机 A 就会发出 ARP 请求包,如果得不到 主机 B 的回应,则说明无法与主机 B 进行通信,那么就会删除 ARP 表项,就无法进行通 信。
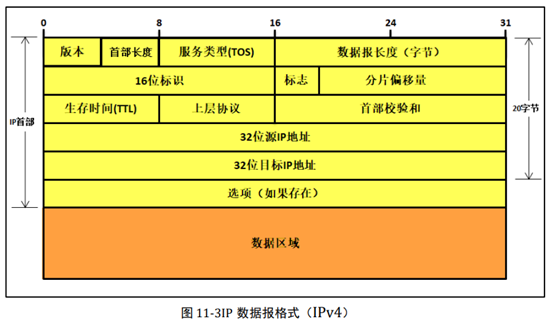
可能很多人都会有疑问:为什么 TCP/IP 协议在传输层与网络层都执行差错检测?首先, 在 IP 层只对 IP 首部计算了检验和,而传输层检验和是对整个 TCP/UDP 报文段进行的。这样子在每个路由器对 IP 数据报首部检查校验能提高效率,直到 IP 数据报到达目标 IP 地址。
IP 数据报分片
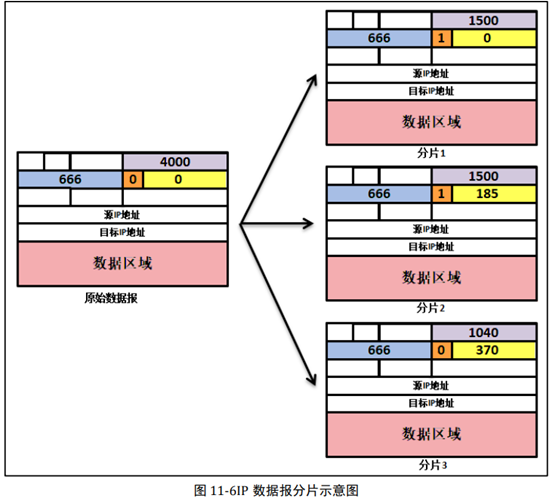
一个主机打算发送 4000 字节的 IP 数据报(20 字节 IP 首部加上 3980 字节 IP 数据区域, 假设没有 IP 数据报首部选项字段),且该数据报必须通过一条 MTU 为 1500 字节的以太网 链路。这就意味着源始 IP 数据报中 3980 字节数据必须被分配为 3 个独立的数据报分片 (其中的每个分片也是一个 IP 数据报)。假定初始 IP 数据报贴上的标识号为 666,那么第 一个分片的数据报总大小为 1500 字节(1480 字节数据大小+20 字节 IP 数据报首部),分 片偏移量为 0,第二个分片的数据报大小也为 1500 字节,分片偏移量为 185 (185*8=1480),第三个分片的数据报大小为 1040(3980-1480-1480+20),分片偏移量为 370(185+185)。
IP 数据报发送
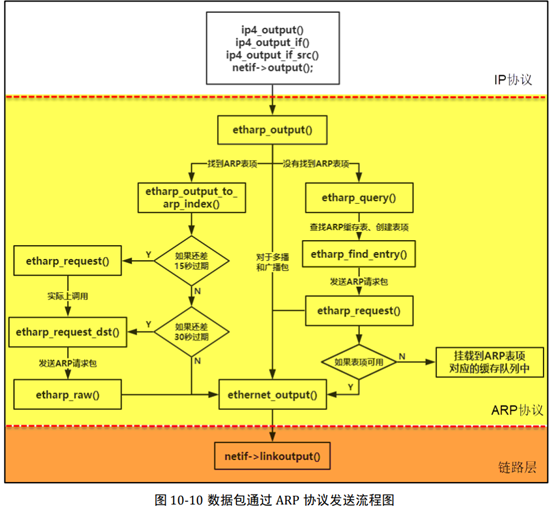
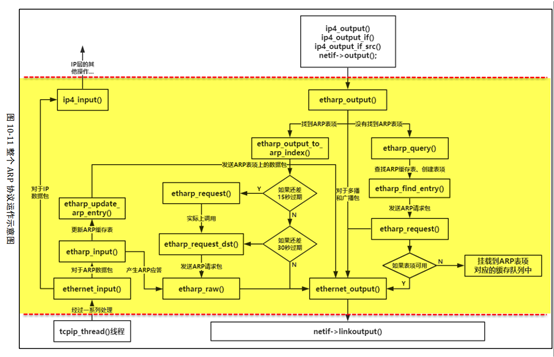
IP 协议是网络层的主要协议,在上层传输协议(如 TCP/UDP)需要发送数据时,就会 将数据封装起来,然后传递到 IP 层,IP 层首先会根据上层协议的目标 IP 地址选择一个合 适的网卡进行发送数据,当 IP 协议获得数据后将其封装成 IP 数据报的格式,填写 IP 数据 报首部对应的各个字段,如目标 IP 地址、源 IP 地址、协议类型、生存时间等重要信息。 最后在 IP 层通过回调函数 netif->output(即 etharp_output()函数)将 IP 数据报投递给 ARP 协议,再调用网卡底层发送函数进行发送,这样子自上而下的数据就发送出去,IP 协议以 目标 IP 地址作为目标主机的身份地址。
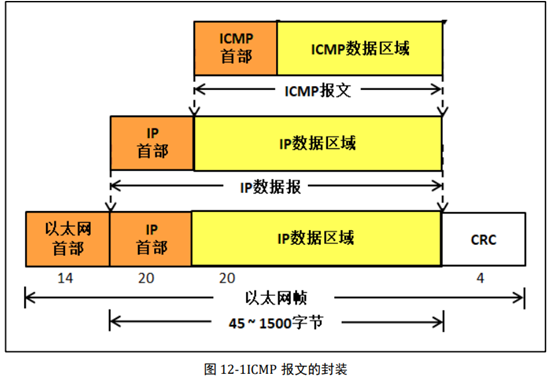
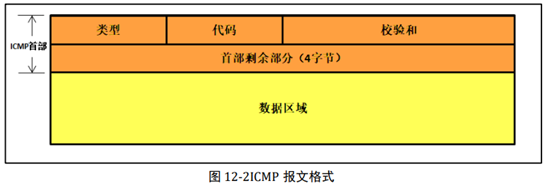
ICMP 查询报文 我们知道,ping 命令使用的就是 ICMP 查询报文,若能 ping 成功,说明网卡、IP 层、 ICMP 层都能通信正常,所以能证明 LwIP 已经移植成功了,我们一般在移植完成的时候都 会测试一下 ping 命令,查看一下是否移植成功。
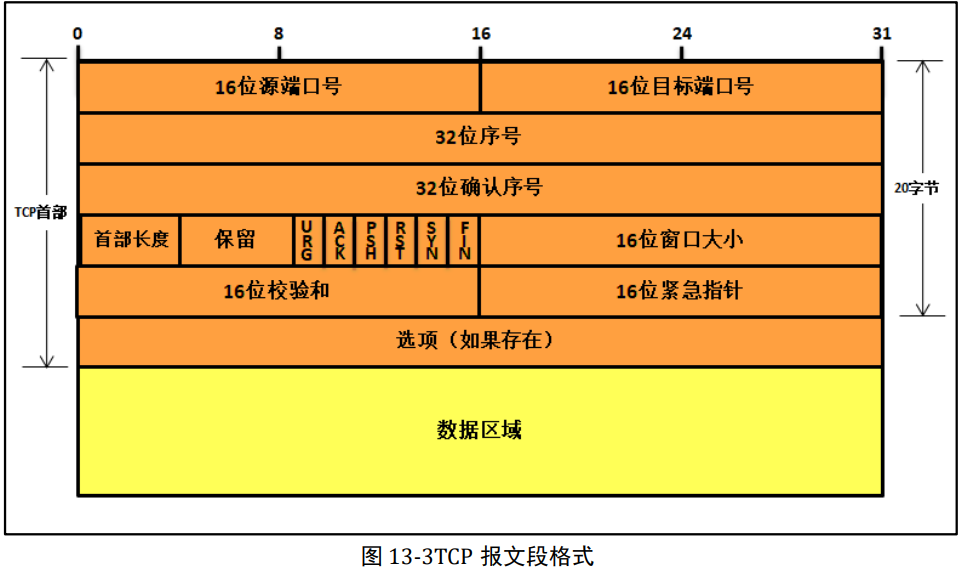
16位窗口大小
16位窗口大小表示接收方在接收数据时的可用缓冲区大小。该字段指示了发送方在不需要等待确认应答的情况下,可以连续发送给接收方的数据的最大量。


)



