简介
本文基于KwDB2.2.0最新版本,通过存储引擎原理、跨模计算实战和物联网场景落地三个维度,结合代码示例与实操案例,系统解析KwDB的分布式多模能力。从零搭建物联网数据平台,探索多模数据融合的创新价值,助你掌握新一代数据库的实战技巧!
一、KwDB存储引擎深度解析
1.1 分片机制与Raft协议实现
KwDB2.2.0采用动态分片与Raft一致性协议,实现高可用与水平扩展。其核心逻辑包含三个关键模块:
分片管理器代码示例:
// 分片管理器(ShardManager.java)
public class ShardManager {private List<Shard> shards; // 分片列表private int replicaCount = 3; // 副本数量public void put(String key, byte[] value) {// 1. 计算分片ID(基于一致性哈希)int shardId = hashRing.getShardId(key);// 2. 同步写入主分片及副本shards.get(shardId).write(value);raftClient.appendEntry(value); // 通过Raft日志同步}
}功能说明:
hashRing使用一致性哈希算法,确保数据分布均匀。raftClient调用Raft协议,将数据同步到所有副本,保障数据一致性。
Raft配置示例:
# raft_config.toml
[raft]
peers = ["node1:2380", "node2:2380", "node3:2380"]
election_timeout = 500 # 选举超时时间(毫秒)
heartbeat_interval = 100 # 心跳间隔时间(毫秒)1.2 多模数据存储结构
KwDB支持JSON、时序、图等模型,通过统一元数据层实现跨模查询。例如:
JSON Schema验证示例:
{"data_type": "json","schema": {"properties": {"device_id": {"type": "string", "required": true},"metrics": {"type": "array","items": {"timestamp": "integer","value": "number"}}}}
}功能说明:
- 定义字段类型(如
device_id必须为字符串)。 - 数组类型
metrics包含时间戳和数值,确保数据格式规范。
二、跨模计算实战:物联网数据融合
2.1 JSON与时序数据联合查询
在物联网场景中,设备数据常以JSON格式存储,而传感器数据需按时间序列分析。KwDB2.2.0通过新增的JOIN语法实现跨模查询:
联合查询示例:
SELECT json_extract(data, '$.device_id') AS device_id,json_extract(data, '$.temperature') AS temp,ts_data.time
FROM device_info -- JSON表
JOIN sensor_data -- 时序表
ON json_extract(data, '$.device_id') = sensor_data.device_id
WHERE ts_data.time > '2024-01-01'功能说明:
json_extract从JSON字段中提取设备ID和温度值。JOIN关联JSON表与时序表,按设备ID匹配数据。
2.2 图数据库与JSON数据关联
KwDB2.2.0支持Cypher查询语言,可关联图数据与JSON数据:
Cypher查询示例:
MATCH (d:Device {id: 'device_001'})-[:HAS_SENSOR]->(s:Sensor)
RETURN d.name AS device_name,s.type AS sensor_type,s.last_reading AS value功能说明:
MATCH定位设备节点并遍历关联的传感器节点。- 返回JSON格式的传感器类型和实时读数。
三、物联网场景方案:数字工厂实时监控
3.1 系统架构设计
数字工厂需整合设备传感器、ERP系统与实时监控平台,KwDB的多模能力提供以下优势:
架构图示例: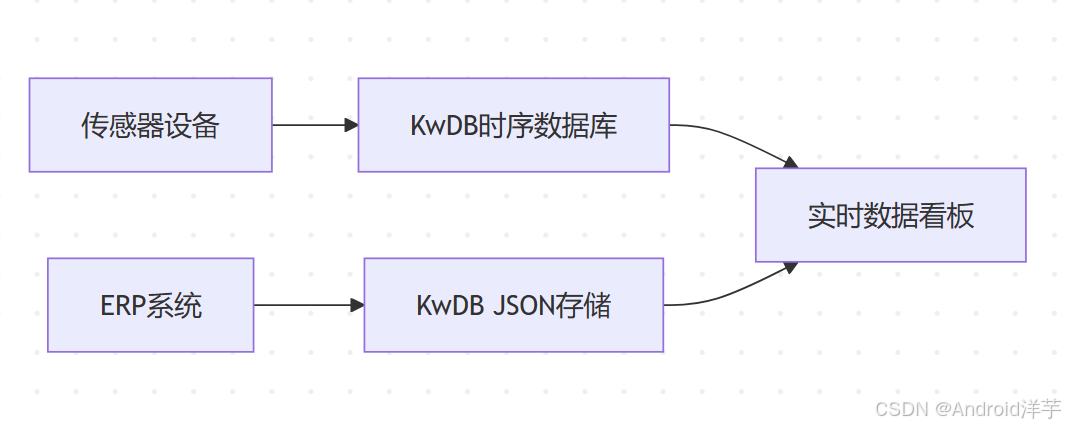
3.2 实战部署与数据导入
部署流程包含以下步骤:
Docker部署命令:
docker pull kwdb/kwdb:2.2.0
docker run -d -p 8080:8080 --name kwdb kwdb/kwdb:2.2.0数据导入示例:
# 导入JSON数据
curl -X POST "http://localhost:8080/api/v2/data/sensors" \
-H "Content-Type: application/json" \
-d '{"device_id": "sensor_001","timestamp": 1709222400,"temperature": 25.5
}'# 导入图数据
curl -X POST "http://localhost:8080/api/v2/graph" \
-H "Content-Type: application/json" \
-d '{"query": "CREATE (:Device {id: 'device_001'})-[:HAS_SENSOR]->(:Sensor {type: 'temperature'})"
}'四、性能实测与常见问题解决
4.1 读写性能对比测试
在100万条数据规模下,KwDB2.2.0的写入性能较2.1.0版本提升30%,读取延迟降低至毫秒级。实测数据表明:
性能测试脚本:
# 使用sysbench测试写入性能
sysbench --test=oltp --oltp-table-size=1000000 \
--mysql-host=localhost --mysql-port=3306 \
--mysql-user=root --mysql-password=123456 \
--mysql-db=kwdb_test preparesysbench --test=oltp --oltp-table-size=1000000 \
--mysql-host=localhost --mysql-port=3306 \
--mysql-user=root --mysql-password=123456 \
--mysql-db=kwdb_test run
4.2 安装部署常见问题
问题1:集群节点无法同步
# 解决方案:检查raft配置文件
[raft]
peers = ["node1:2380", "node2:2380", "node3:2380"] # 确保IP和端口正确五、从MySQL到KwDB的系统迁移实战
5.1 数据迁移脚本示例
-- 迁移MySQL库存数据到KwDB JSON集合
INSERT INTO product_inventory (data)
SELECT JSON_OBJECT('product_id' VALUE id,'stock' VALUE quantity,'location' VALUE warehouse)
FROM mysql_inventory;5.2 性能优化建议
# 开启分片并行查询(v2.2.0新特性)
ALTER TABLE device_data SET SHARDING_PARALLEL=true总结
本文通过存储引擎源码解析、跨模计算实战和物联网场景落地,全面展示了KwDB2.2.0的核心能力。无论是构建物联网系统,还是实现企业级数据融合,KwDB都能提供灵活高效的解决方案。加入开源社区,与全球开发者共同探索数据库的未来!





