使用 PyTorch 构建并训练一个简单的 CNN 模型进行图像分类
在深度学习领域,卷积神经网络(CNN)是处理图像分类任务的强大工具。本文将通过一个简单的示例,展示如何使用 PyTorch 构建、训练和测试一个 CNN 模型,用于对食品图像进行分类。

1. 数据准备
在开始之前,我们需要准备数据集。假设我们有一个食品图像数据集,分为训练集和测试集,分别存储在 train 和 test 文件夹中。每个文件夹中包含多个子文件夹,每个子文件夹代表一个类别,其中包含该类别的图像。
为了方便模型训练和测试,我们需要生成两个文本文件(train.txt 和 test.txt),分别记录训练集和测试集中每个图像的路径及其对应的类别标签。以下是生成这些文件的代码:
import osdef train_test_file(root, dir):file_txt = open(dir + '.txt', 'w')path = os.path.join(root, dir)for roots, directories, files in os.walk(path):if len(directories) != 0:dirs = directorieselse:now_dir = roots.split('\\')for file in files:path_1 = os.path.join(roots, file)print(path_1)file_txt.write(path_1 + ' ' + str(dirs.index(now_dir[-1])) + '\n')file_txt.close()root = r'D:\Users\妄生\PycharmProjects\机器学习\深度学习\food_dataset2'
train_dir = 'train'
test_dir = 'test'
train_test_file(root, train_dir)
train_test_file(root, test_dir)
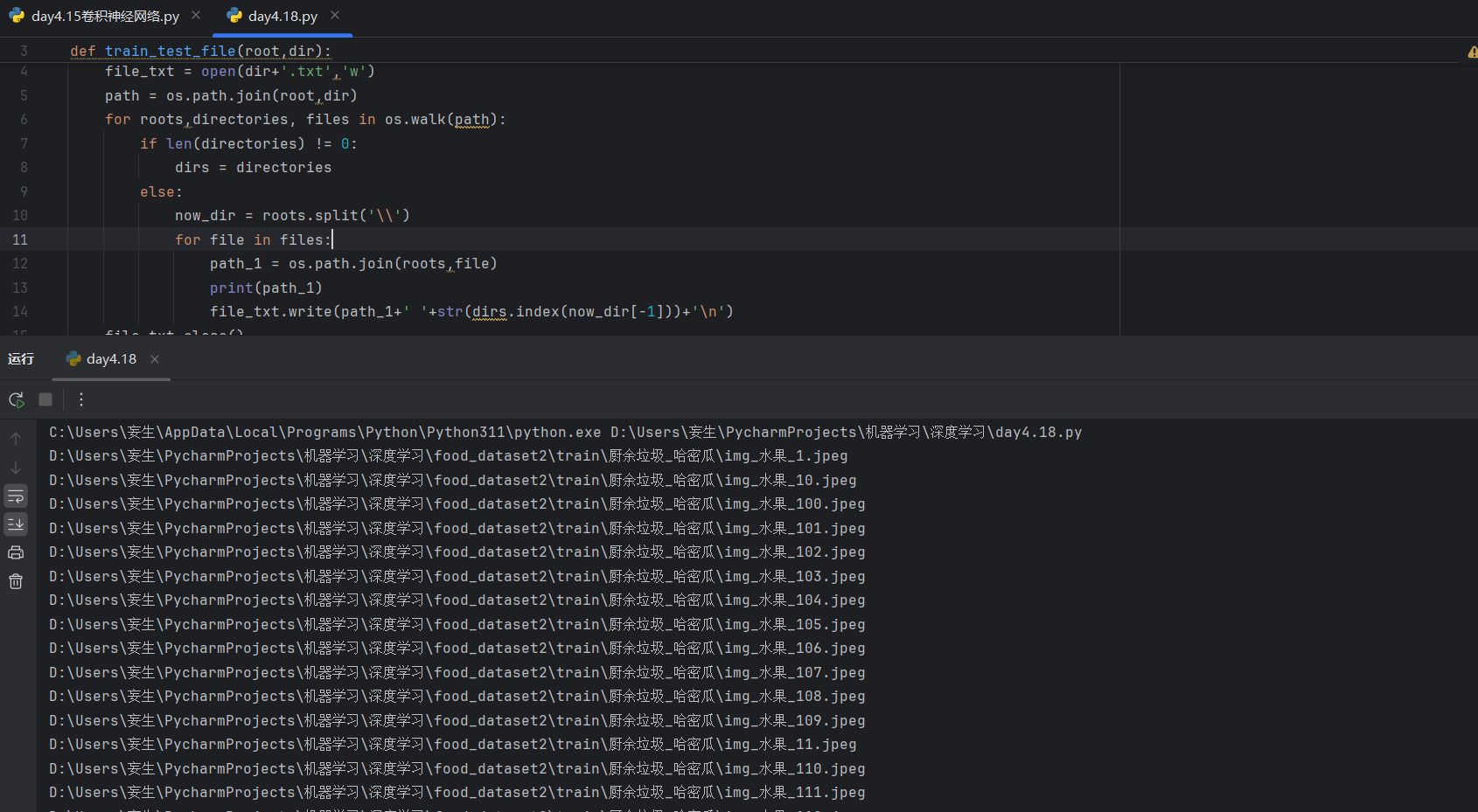
运行上述代码后,train.txt 和 test.txt 文件将被生成,每行包含一个图像路径和对应的类别标签,用空格分隔。
运行结果
2. 构建数据集类
接下来,我们需要构建一个自定义的数据集类,用于加载图像数据和标签。我们将使用 PyTorch 的 Dataset 类来实现这一点。以下是代码:
import numpy as np
from torch.utils.data import Dataset, DataLoader
import torch
from PIL import Image
from torchvision import transforms# 数据预处理转换
data_transforms = {'train': transforms.Compose([transforms.Resize([256, 256]), # 调整图像大小transforms.ToTensor(), # 将图像转换为Tensor]),'valid': transforms.Compose([transforms.Resize([256, 256]), # 调整图像大小transforms.ToTensor(), # 将图像转换为Tensor])
}# 自定义数据集类
class food_dataset(Dataset): #food_dataset是自己创建的类名称,可以改为你需要的名称def __init__(self, file_path, transform=None): #类的初始化,解析数据文件txtself.file_path = file_pathself.imgs = []self.labels = []self.transform = transformwith open(self.file_path) as f: #是把train.txt文件中图片的路径保存在 self.imgs,train.txt文件中标签保存在 sesamples = [x.strip().split(' ') for x in f.readlines()]for img_path, label in samples:self.imgs.append(img_path) #图像的路径self.labels.append(label) #标签,还不是tensor# 初始化:把图片目录加载到self,def __len__(self): #类实例化对象后,可以使用len函数测量对象的个数 ls=[12,3,4,4] len(training_data)return len(self.imgs)def __getitem__(self, idx): #关键,可通过索引的形式获取每一个图片数据及标签image = Image.open(self.imgs[idx]) #读取到图片数据,还不是tensor,BGRif self.transform: #将pil图像数据转换为tensorimage = self.transform(image) #图像处理为256*256,转换为tenorlabel = self.labels[idx] #label还不是tensorlabel = torch.from_numpy(np.array(label, dtype=np.int64)) #label也转换为tensor,return image, label# 实例化训练和测试数据集
training_data = food_dataset(file_path='./train.txt', transform=data_transforms['train'])
test_data = food_dataset(file_path='./test.txt', transform=data_transforms['valid'])# 创建数据加载器
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True) #64张图片为一个包,
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)在上述代码中,我们定义了一个 FoodDataset 类,它读取 train.txt 和 test.txt 文件中的图像路径和标签,并对图像进行预处理。我们还定义了两个数据加载器(train_dataloader 和 test_dataloader),用于批量加载数据。
3. 构建 CNN 模型
接下来,我们将构建一个简单的卷积神经网络(CNN)模型。以下是代码:
# 选择设备
device = 'cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'
print(f"{device}")# 定义CNN模型
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__()self.conv1 = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=16, kernel_size=5, stride=1, padding=2),nn.ReLU(),nn.MaxPool2d(kernel_size=2),)self.conv2 = nn.Sequential(nn.Conv2d(16, 32, 5, 1, 2),nn.ReLU(),nn.Conv2d(32, 32, 5, 1, 2),nn.ReLU(),nn.MaxPool2d(2),)self.conv3 = nn.Sequential(nn.Conv2d(32, 128, 5, 1, 2), nn.ReLU())self.out = nn.Linear(128 * 64 * 64, 20) # 这里的尺寸需要根据实际情况调整def forward(self, x):x = self.conv1(x)x = self.conv2(x)x = self.conv3(x)x = x.view(x.size(0), -1)output = self.out(x)return output# 实例化模型并移动到选择的设备
model = CNN().to(device)在上述代码中,我们定义了一个包含三个卷积层和一个全连接层的 CNN 模型。模型的输入是 RGB 图像(3 个通道),输出是 20 个类别的预测结果。
4. 训练和测试模型
接下来,我们将定义训练和测试函数,并训练和测试我们的模型。以下是代码:
# 定义训练函数
def train(dataloader, model, loss_fn, optimizer):model.train()batch_size_num = 1for x, y in dataloader:x, y = x.to(device), y.to(device)pred = model(x) # 使用model(x)而不是model.forward(x)loss = loss_fn(pred, y)optimizer.zero_grad()loss.backward()optimizer.step()loss_value = loss.item()print(f"{loss_value} {batch_size_num}")batch_size_num += 1# 定义测试函数
def test(dataloader, model, loss_fn):size = len(dataloader.dataset)num_batches = len(dataloader)model.eval()test_loss, correct = 0, 0with torch.no_grad():for x, y in dataloader:x, y = x.to(device), y.to(device)pred = model(x) # 使用model(x)而不是model.forward(x)test_loss += loss_fn(pred, y).item()correct += (pred.argmax(1) == y).type(torch.float).sum().item()# 打印预测结果和真实结果predicted_labels = pred.argmax(1).cpu().numpy() # 获取预测的类别true_labels = y.cpu().numpy() # 获取真实的类别print(f"Predicted: {predicted_labels}")print(f"True: {true_labels}")test_loss /= num_batchescorrect /= sizeprint(f"Test result: \n Accuracy: {(100 * correct)}%, Avg loss: {test_loss}")# 定义损失函数和优化器
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 训练和测试模型
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)# 训练多个周期
epochs = 10
for t in range(epochs):print(f"epoch{t + 1}\n")train(train_dataloader, model, loss_fn, optimizer)
print("done")
test(test_dataloader, model, loss_fn)
在上述代码中,我们定义了训练函数 train 和测试函数 test。在训练函数中,我们对每个批次的数据进行前向传播、计算损失、反向传播和优化器更新。在测试函数中,我们对每个批次的数据进行前向传播,计算预测结果和真实结果,并打印出来。
我们还定义了损失函数(交叉熵损失)和优化器(Adam),并训练了 10 个周期。在训练完成后,我们测试了模型的性能。
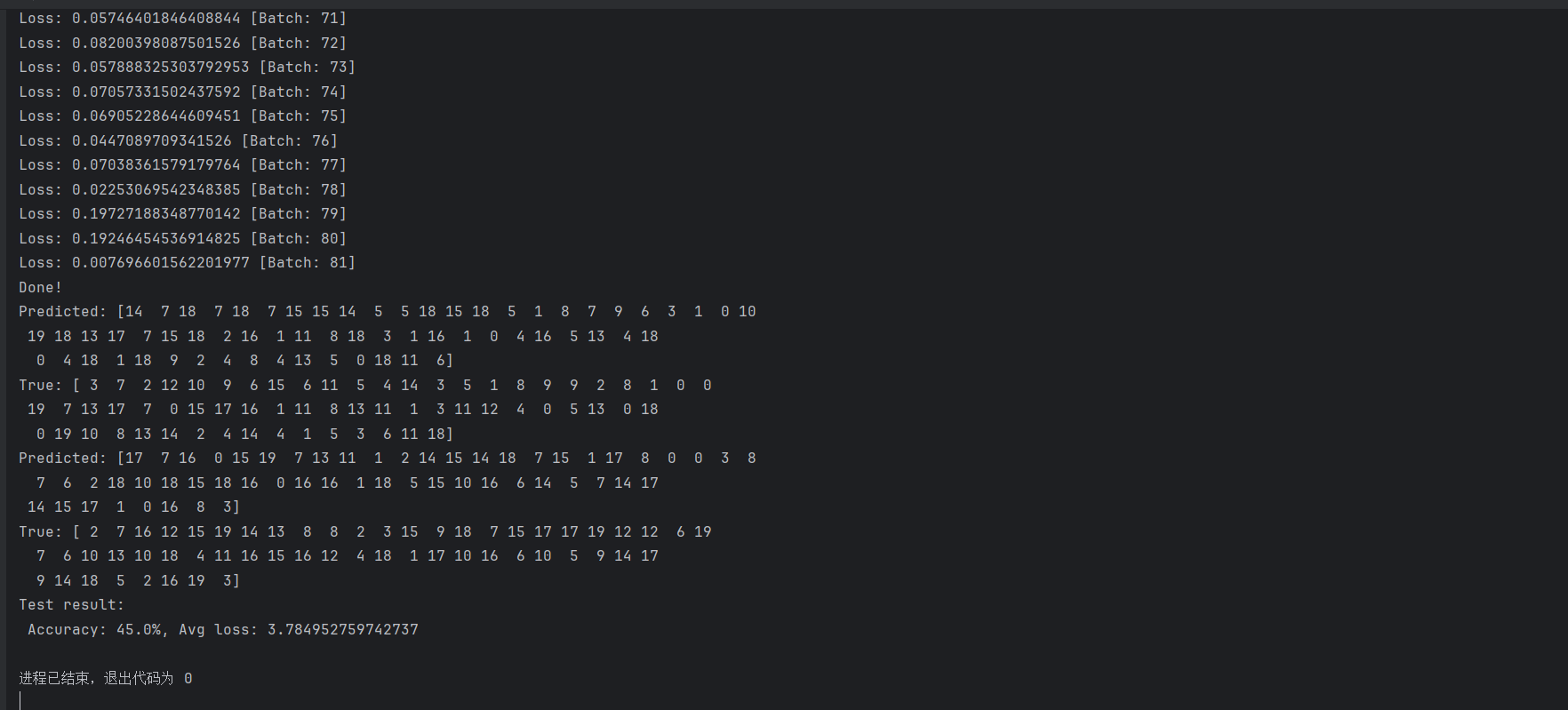
5. 结果分析
在测试阶段,模型的预测结果和真实结果将被打印出来:
`


的细胞识别程序)


