推理模型在数学和逻辑推理等任务中表现出色,但常出现过度推理的情况。本文研究发现,推理模型的隐藏状态编码了答案正确性信息,利用这一信息可提升推理效率。想知道具体如何实现吗?快来一起来了解吧!
论文标题
Reasoning Models Know When They’re Right: Probing Hidden States for Self-Verification
来源
arXiv:2504.05419v1 [cs.AI] 7 Apr 2025
https://arxiv.org/abs/2504.05419
文章核心
研究背景
近年来,推理模型在复杂推理能力上取得显著进展,如OpenAI的o1和DeepSeekR1等在数学和逻辑推理任务中表现出色,其基于搜索的推理方式是重要优势。
研究问题
- 推理模型存在过度思考的问题,在得到正确答案后仍会进行不必要的推理步骤。
- 不清楚模型在推理过程中对中间答案正确性的评估能力如何。
- 模型虽能编码答案正确性信息,但在推理时未能有效利用该信息。
主要贡献
- 验证信息编码:证实推理模型的隐藏状态编码了答案正确性信息,通过简单的探测就能可靠地提取,且探测结果校准度高,在分布内和分布外示例上都有良好表现。
- 提前预测正确性:发现模型隐藏状态包含“前瞻性”信息,能在中间答案完全生成前预测其正确性。
- 提升推理效率:将训练好的探测模型用作验证器,实施基于置信度的提前退出策略,在不降低性能的情况下,可减少24%的推理令牌数量,揭示了模型在利用内部正确性信息方面的潜力。
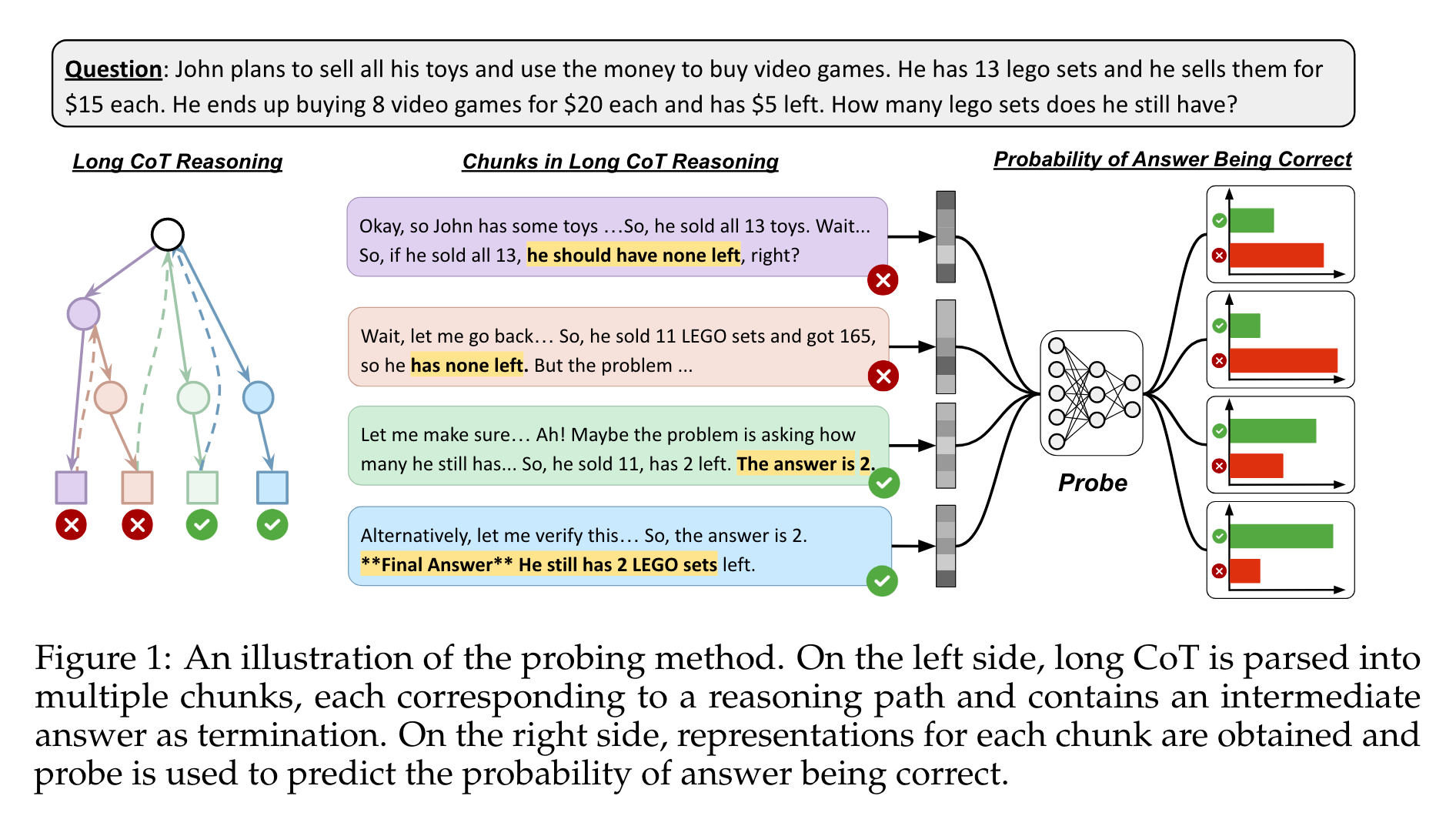
方法论精要
- 核心算法/框架:使用两层多层感知器(MLP)作为探测模型,在推理模型生成的长思维链(Chain-of-Thought,CoT)基础上,将其分割为包含中间答案的多个块,利用该探测模型从这些块对应的隐藏状态中提取信息,进而预测中间答案的正确性。
- 关键参数设计原理:由于数据集存在类别不平衡问题,多数中间答案正确,因此使用加权二元交叉熵损失函数。其中, w w w是训练数据中负样本与正样本的比例, α \alpha α是缩放不平衡权重的超参数,通过调整这些参数来优化探测模型的训练。
- 创新性技术组合:
- 数据处理创新:设计了一套独特的数据处理流程。首先,收集推理模型针对任务数据集中每个问题的响应,将推理过程中封装在标记内的推理痕迹提取出来,并以 “\n\n” 为分隔符拆分成段落。通过检测段落中的 “wait”“double-check”“alternatively” 等关键词来识别新推理路径的起始点,然后将同一推理路径的段落合并成一个块。接着,借助 Gemini 2.0 Flash 工具,从每个块中提取中间答案(若存在),并与真实答案对比判断其正确性。对于相邻且不包含中间答案的块,将其与最近的含答案块合并。最终,每个合并后的块都包含一个中间答案以及由 Gemini 生成的表示答案正确性的二进制标签,形成 ( c 1 , y 1 ) , ( c 2 , y 2 ) , . . . ( c k , y k ) {(c_{1}, y_{1}),(c_{2}, y_{2}), ...(c_{k}, y_{k})} (c1,y1),(c2,y2),...(ck,yk) 这样的数据结构,为后续探测模型的训练提供了丰富且准确的数据。
- 模型训练创新:在训练探测模型时,采用将长 CoT 分段处理后得到的块数据进行训练。对于每个块 c i c_{i} ci ,选取其最后一个令牌位置的最后一层隐藏状态作为该块的表示 e i e_{i} ei,以此构建探测数据集 D = ( e i , y i ) i = 1 N D={(e_{i}, y_{i})}_{i=1}^{N} D=(ei,yi)i=1N,这种基于块的隐藏状态表示方式能够有效捕捉推理过程中每个中间步骤的特征信息,为准确训练探测模型奠定了基础。同时,结合加权二元交叉熵损失函数进行训练,进一步提升了模型在不平衡数据上的训练效果。
- 实验验证方式:选择数学推理(GSM8K、MATH、AIME)和逻辑推理(KnowLogic)任务的数据集,使用开源的DeepSeek - R1 - Distill系列模型以及QwQ - 32B模型。通过在不同数据集上训练和测试探测模型,对比不同模型的性能,并将训练好的探测模型作为验证器,与静态提前退出策略对比,评估推理效率和准确性。
实验洞察
- 性能优势:在分布内实验中,所有探测模型的ROC - AUC得分均高于0.7,预期校准误差(ECE)低于0.1。例如,R1 - Distill - Qwen - 32B在AIME数据集上的ROC - AUC得分超过0.9。在跨数学推理数据集的实验中,部分探测模型具有良好的泛化性,如在MATH和GSM8K数据集上训练的探测模型在两个数据集之间转移时,ROC - AUC和ECE表现良好。
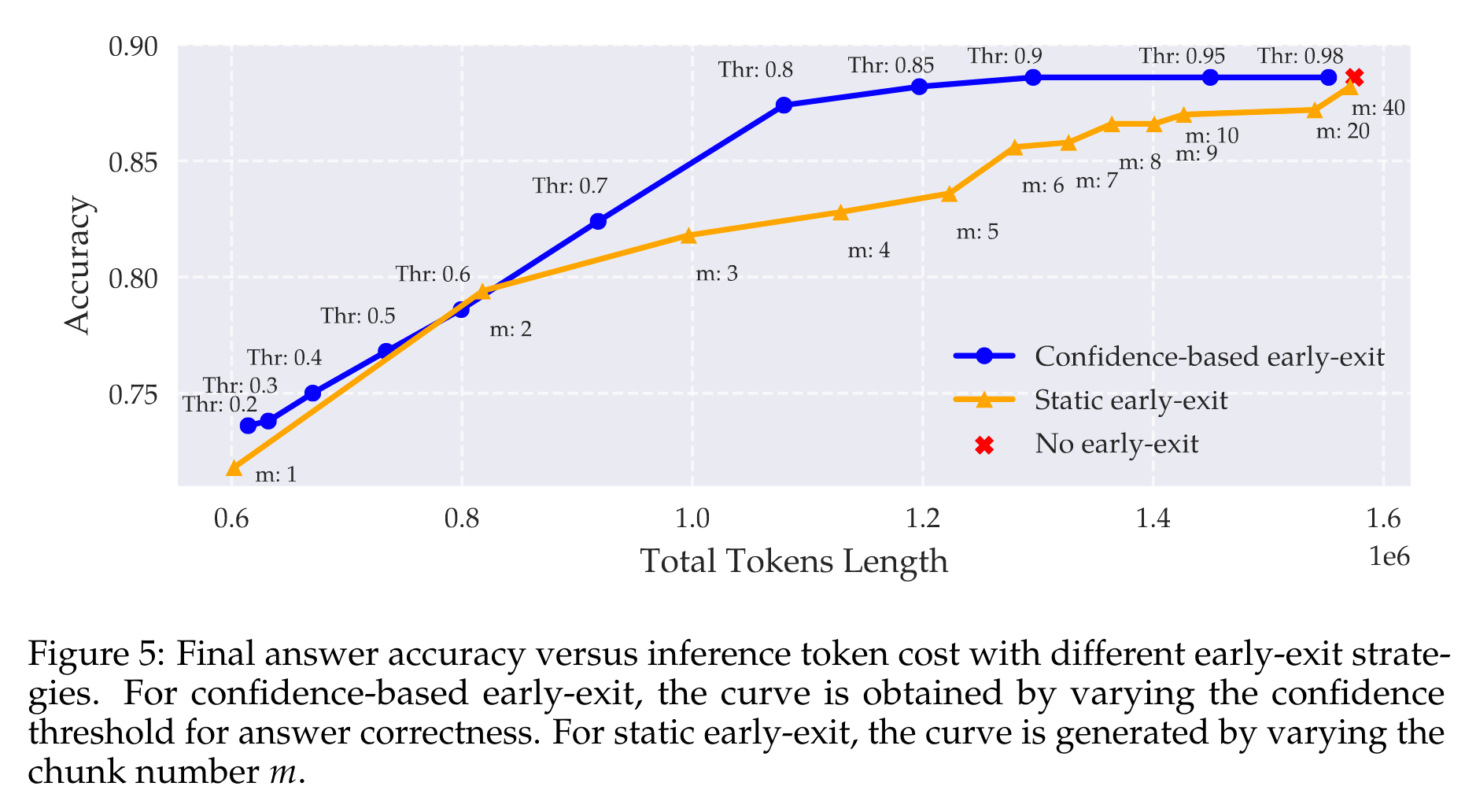
- 效率突破:使用基于探测模型置信度的提前退出策略,在MATH数据集上,当置信度阈值设为0.85时,推理准确率与不提前退出时大致相同(88.2%),但生成的令牌数量减少了约24%;当阈值设为0.9时,推理准确率为88.6%,令牌数量减少19%。且在节省相同数量令牌的情况下,该策略比静态提前退出策略的准确率高5%。
- 消融研究:训练非推理模型(Llama - 3.1 - 8B - Instruct)的探测模型并与推理模型对比,发现非推理模型探测模型的性能更差,分类得分更低,校准误差更高,表明答案正确性的编码信息在推理模型中更显著,与长CoT推理能力相关。同时,研究发现推理模型在中间答案生成前,隐藏状态就编码了正确性信息,且靠近答案生成位置的段落,探测模型性能更好。
本文由AI辅助完成。

)



