开门见山
曾经,PID参数整定是控制工程师的噩梦——
调Kp像相亲,大了暴躁,小了慢热;
调Ki像养猫,喂多了捣乱,喂少了记仇;
调Kd像哄女朋友,反应快了说你敷衍,反应慢了说你冷漠…
直到某天,DDPG这个强化学习界的‘海王’出现了
它拍着胸脯说:'放着我来!让AI用试错法替你承受这世间所有的毒打!
于是我们看到——PID三兄弟终于过上了被强化学习包养的生活,而工程师们喝着咖啡围观算法自己卷自己…
今天我们就来聊聊,DDPG是如何用算力帮PID实现参数自由的!
讲人话:本期带来一篇DDPG-PID算法
原理概述
PID控制基于比例(P)、积分(I)和微分(D)三部分的线性组合来生成控制信号,在具体的控制系统里主要通过调整比例增益Kp、积分增益Ki,和微分增益Kd,这3个参数调节系统的输出,使其尽可能接近期望的目标值。
传统PID参数的调整主要依赖于经验、手动调试或一些理论方法,难以找到全局最优解且适应性差。
DDPG-PID控制通过深度强化学习算法构建智能体,在与环境交互中自动学习得到最优的参数组合。智能体撷取状态,选择动作,接收奖励,并根据经验进行参数更新,不需要显式地设置PID参数,而是通过不断试错找到最优策略。
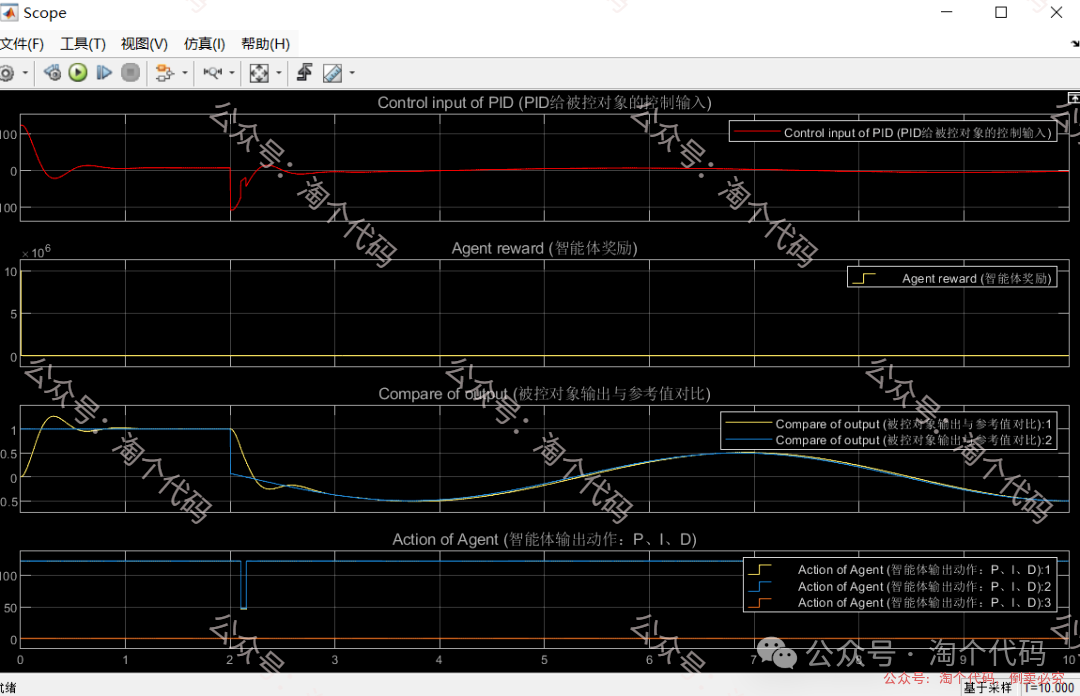
DDPG-PID控制器主要结构如下图所示。
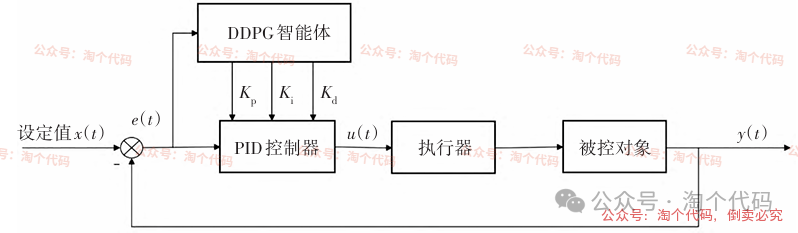
将PID控制器中的3个参数Kp、Ki、Kd作为DDPG算法的状态-动作输入,寻找能够实现最佳控制效果的PID参数。
在DDPG-PID控制的过程中,设定控制系统的输入信号为x(t),PID控制器接收输人信号,经过比例、积分、微分三个环节处理后输出控制信号u(t),执行器接收控制信号后控制被控对象达到设定值。
被控对象实际输出为控制系统的输出信号y(t),实际输出信号的反馈与期望输出值进行比较得到控制系统中的误差值e(t)。
DDPG算法对当前状态和当前状态的误差值进行采样评价,评价指标选取经典的ITAE,并考虑控制器u的变化能量;利用Actor-Critic网络根据当前得到的评价更新网络内部参数,对PID参数进行调整,逐步优化直至得到理想控制效果下最优的PID参数组合。
奖励函数设置
奖励函数在DDPG-PID中直接影响智能体行为和控制策略的学习过程。一个合理设计的奖励函数能够引导智能体在调整PID参数时,优化控制性能,而不合理的奖励函数则可能导致控制效果差,甚至使智能体偏离期望的控制行为。
本期代码奖励函数设置为经典的ITAE指标,并考虑加权控制器U的变化能量(防止控制器频繁动作)。
时间乘绝对误差积分(ITAE)公式如下:
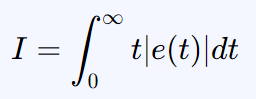
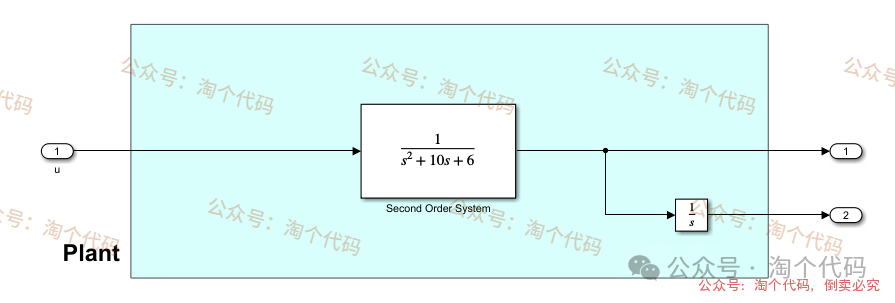
被控对象采用simulink搭建,简单易修改!这里采用一个典型的二阶系统。你也可以修改这里为任何模型!
结果展示
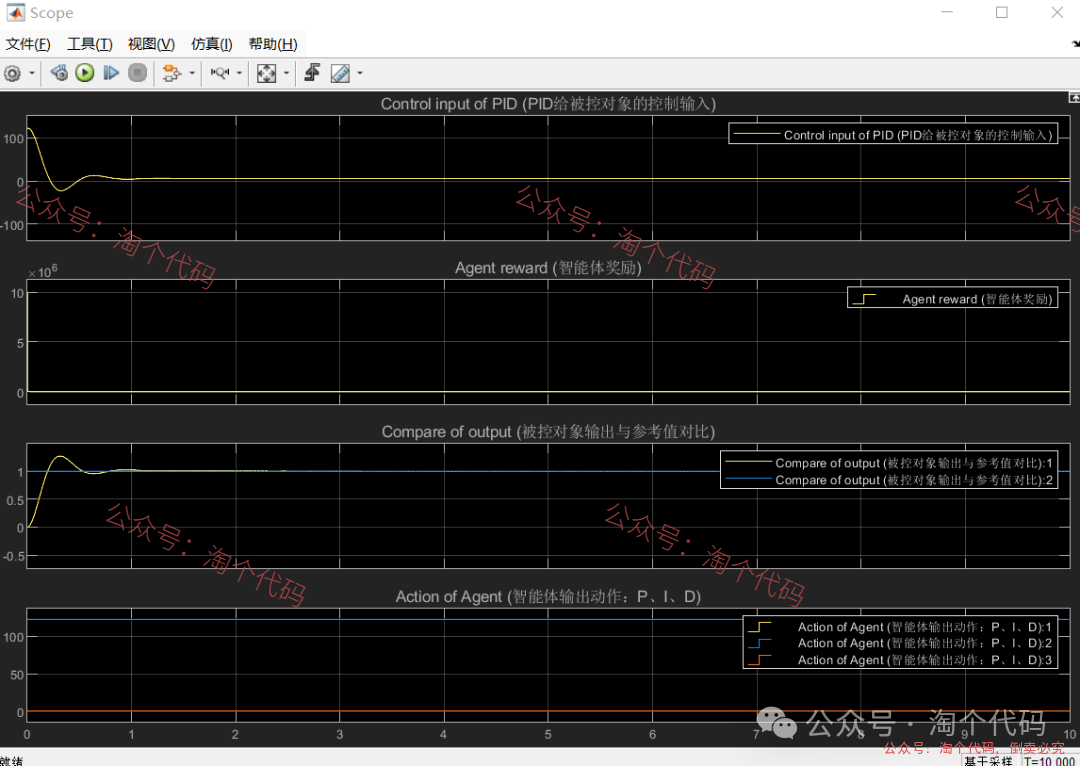
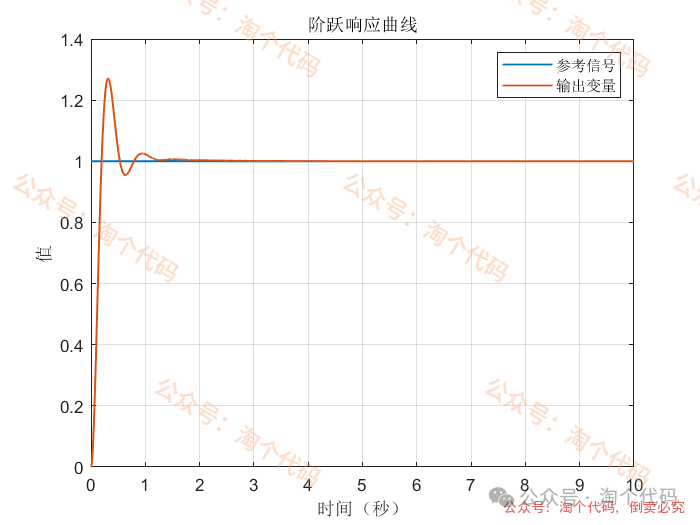
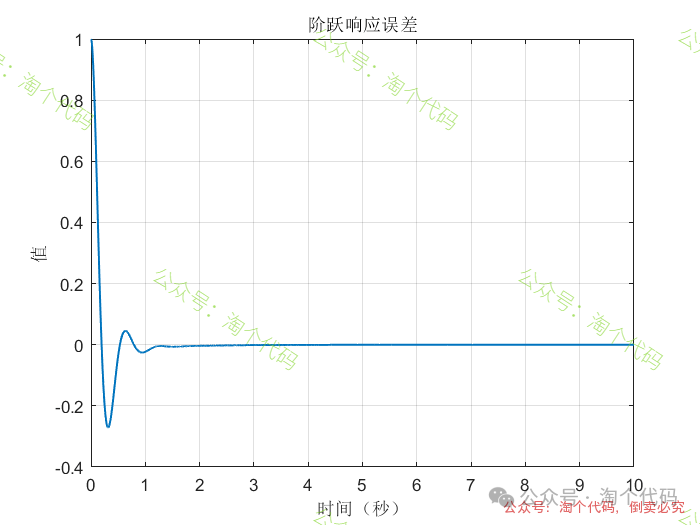
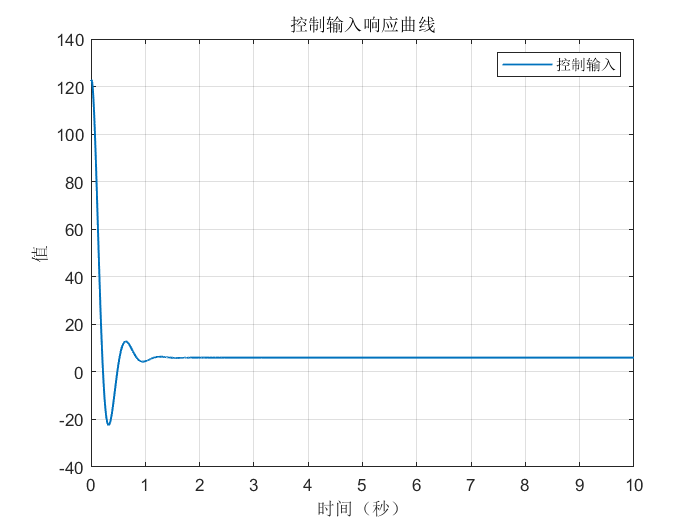
案例1:输入为阶跃信号
案例2:输入为正弦信号
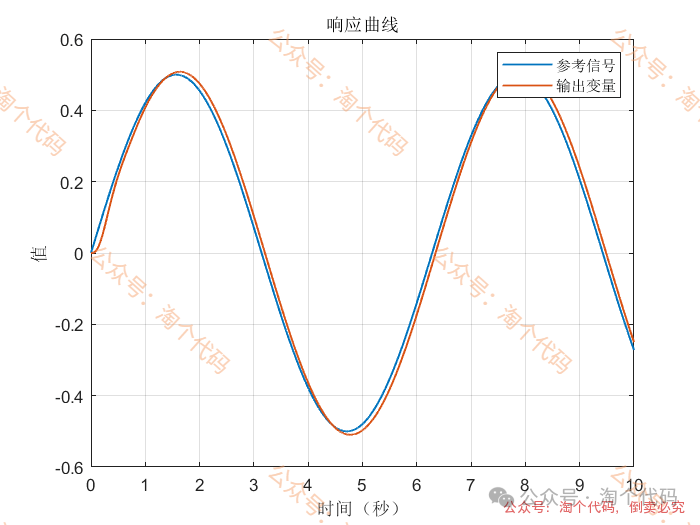
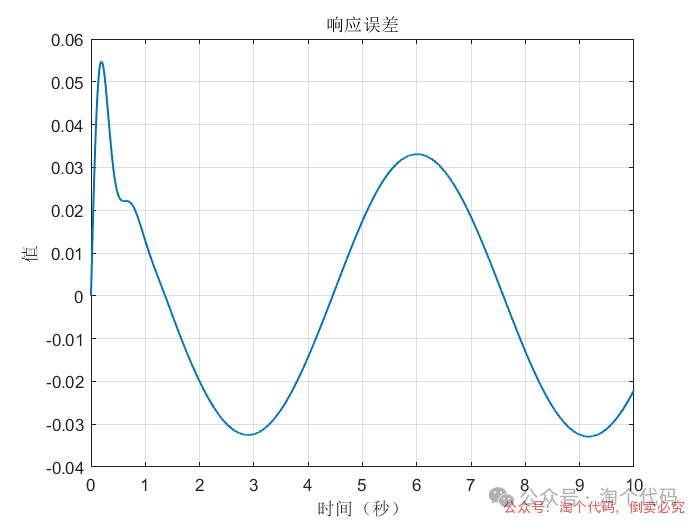
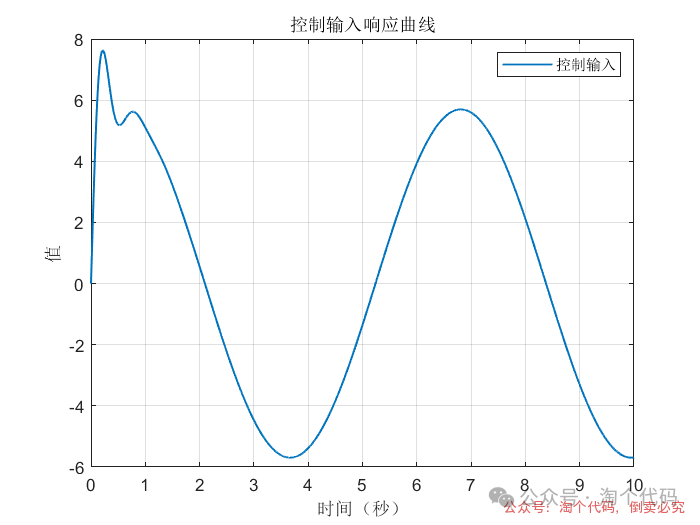
案例3:前两秒为阶跃,之后突变为正弦
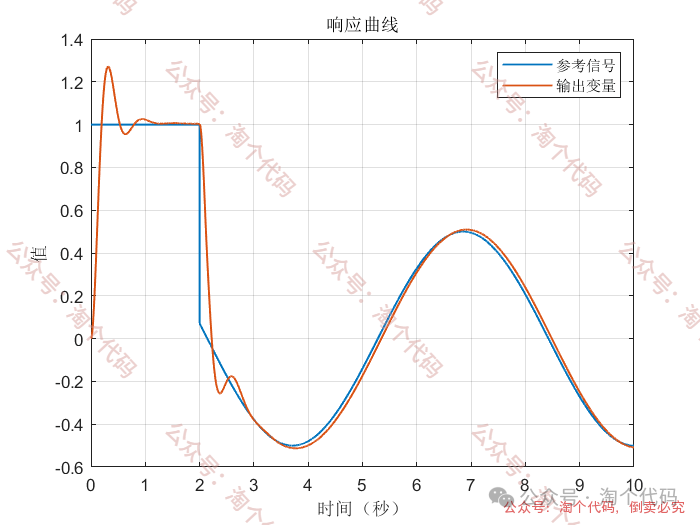
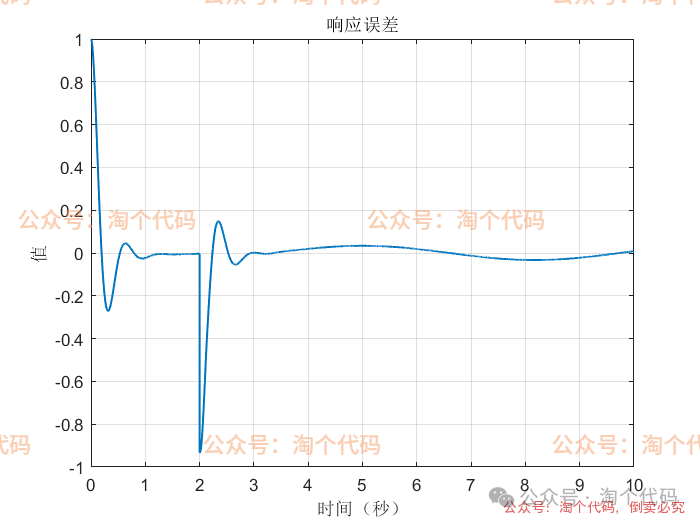
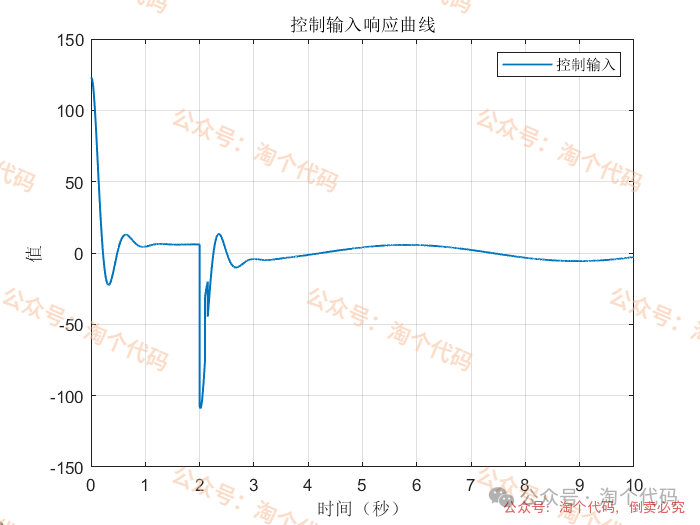
综合以上三个案例可以看出,DDPG在优化PID参数方面的性能,绝对杠杠滴!无论怎么变输入,控制器就是能跟踪上。
代码目录
执行此程序,必须使用2020a以上版本的MATLAB。另外考虑到大家的版本可能不尽相同,就生成了多个版本的slx文件,可以在代码中自行选择匹配自己版本的slx文件。
代码获取
链接:https://mbd.pub/o/bread/aJick5xy
或者点击下方阅读原文获取。
获取更多代码:

或者复制链接跳转:https://docs.qq.com/sheet/DU3NjYkF5TWdFUnpu



