一、目标
如何使用 PyTorch 实现一个简单的深度神经网络(DNN)模型,并用于回归任务。该模型通过训练数据集来预测玩家在游戏中的最终排名百分比。代码通过读取数据集、数据处理、模型训练和模型评估等步骤。
二、数据集介绍
和平精英(Peace Elite)是一款受欢迎的多人在线生存射击游戏,通常被称为“绝地求生:刺激战场”。在这个游戏中,玩家被投放到一块广大的战斗区域,必须与其他玩家竞争以成为最后一个生存者。为了分析或研究《和平精英》的玩家表现,常常会收集有关比赛和玩家的数据。本数据集包含了400多万条关于玩家在游戏中的表现记录
数据集介绍
总体描述:
该数据集记录了大量玩家在不同比赛中的表现,包含了玩家的杀敌、死亡、以及使用的物品等各种重要数据。
数据集是以每一局(match)为单位进行收集,提供了丰富的统计信息,可以用于分析玩家的表现、策略以及游戏平衡性。
数据字段:
玩家ID(Id): 唯一标识每位玩家的ID。
队伍ID(groupId): 记录玩家所处的队伍,便于分析团队合作。
匹配ID(matchId): 每场比赛的唯一标识符,便于追踪每场比赛的数据。
伤害相关字段: 包括伤害(damageDealt)、伤害过的敌人数(assists)、击倒敌人数量(DBNOs)、**杀敌数量(kills)和爆头杀敌数量(headshotKills)**等,反映玩家的战斗能力。
治疗与回复: 如救援类物品使用数量(heals)和救援队友次数(revives),显示玩家的生存和团队支持能力。
移动与探索: 信息如步行距离(walkDistance)、游泳距离(swimDistance)和交通工具使用距离(rideDistance),帮助分析玩家在地图上的移动方式。
比赛结果: 包括排名(killPlace)、胜利排名百分比(winPlacePerc)及外部排名(killPoints 和 winPoints),用于评价玩家的整体表现。
数据集的应用:
表现分析: 通过分析玩家的各项数据,游戏开发者和研究人员可以识别出顶级玩家的特点和策略,从而优化游戏设计。
平衡性测试: 通过对不同 Weapons 和技能的使用情况进行统计,开发者可以评估和平精英游戏内的平衡性。
玩家行为研究: 研究玩家在不同比赛模式(如“solo”、“duo”、“squad”等)下的表现,了解玩家偏好和游戏模式的吸引力。
技术考虑:
数据集的规模超过400万条记录,适合使用大数据处理技术(如Apache Spark)进行分析和挖掘。
可能需要对数据进行清洗和预处理,以处理缺失值或异常值,从而提升分析的准确性。
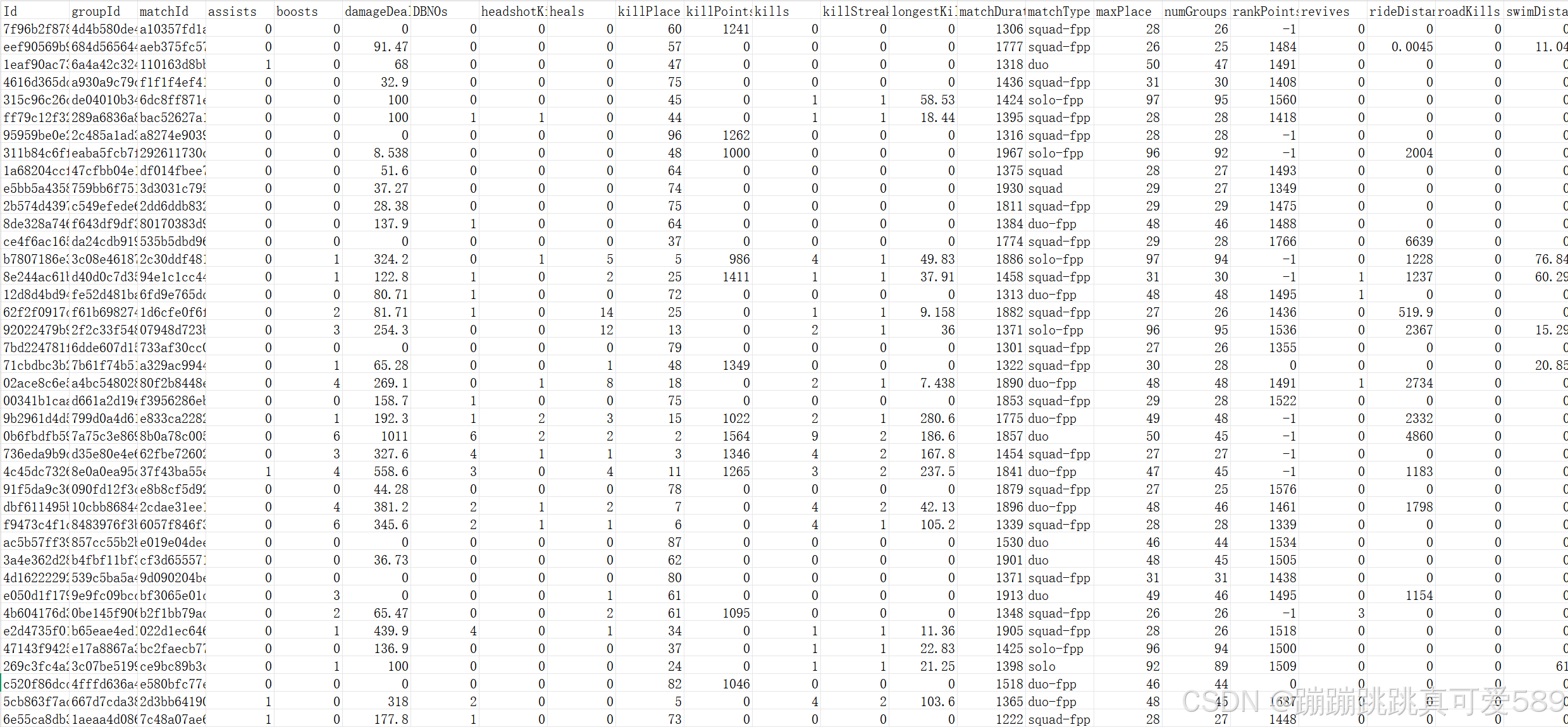
| 字段名称 | 描述 |
|---|---|
| Id | 玩家ID |
| groupId | 队伍的 ID。 如果同一组玩家在不同的比赛中比赛,他们每次都会有不同的 GroupId。 |
| matchId | 匹配的 ID(每一局一个 ID)。 |
| assists | 伤害过多少敌人(最终该敌人被队友杀害)。 |
| boosts | 使用过多少个提升性的物品 (boost items used)。 |
| damageDealt | 造成的总伤害-自己所受的伤害。 |
| DBNOs | 击倒多少敌人。 |
| headshotKills | 通过爆头而杀死的敌人数量。 |
| heals | 使用了多少救援类物品。 |
| killPlace | 杀死敌人数量的排名。 |
| killPoints | 基于杀戮的玩家外部排名。将其视为Elo排名,只有杀死才有意义。 |
| kills | 杀死的敌人的数量。 |
| killStreaks | 短时间内杀死敌人的最大数量。 |
| longestKill | 玩家和玩家在死亡时被杀的最长距离。 |
| matchDuration | 匹配用了多少秒。 |
| matchType | 单排/双排/四排;标准模式是 “solo”,“duo”,“squad”,“solo-fpp”,“duo-fpp”和“squad-fpp”;其他模式来自事件或自定义匹配。 |
| maxPlace | 在该局中已有数据的最差的队伍名词。 |
| numGroups | 在该局比赛中有玩家数据的队伍数量。 |
| rankPoints | 类似 Elo 的玩家排名。此排名不一致,并且在 API 的下一个版本中已弃用,因此请谨慎使用。值 -1 表示“无”。 |
| revives | 玩家救援队友的次数。 |
| rideDistance | 玩家使用交通工具行驶了多少米。 |
| roadKills | 在交通工具上杀死了多少玩家。 |
| swimDistance | 游泳了多少米。 |
| teamKills | 该玩家杀死队友的次数。 |
| vehicleDestroys | 毁坏了多少交通工具。 |
| walkDistance | 步行运动了多少米。 |
| weaponsAcquired | 捡了多少把枪。 |
| winPoints | 基于赢的玩家外部排名。将其视为 Elo 排名,只有获胜才有意义。 |
| winPlacePerc | 预测目标,以百分数计算,介于 0-1 之间,1 对应第一名,0 对应最后一名。 |
三、设计思路
3.1、准备工作
导入模块包
import os
import random
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import torch
from sklearn.preprocessing import StandardScaler
from torch import nn, optim
from torch.utils.data import TensorDataset, DataLoader设置随机种子保证结果的可重复性
def setup_seed(seed):# 设置 Numpy 随机数种子,确保Numpy生成的随机数序列一致np.random.seed(seed)# 设置Python内置随机数种子,保证Python内置的随机函数生成的随机数一致random.seed(seed)# 设置Python哈希种子,避免不同运行环境下哈希结果不同,影响随机数生成os.environ['PYTHONHASHSEED'] = str(seed)# 设置PyTorch 随机种子,使PyTorch生成的随机数序列可以重复torch.manual_seed(seed)# 检查是否有可用的CUDA设备(GPU)if torch.cuda.is_available():# 设置 CUDA 随机种子,保证在GPU上的随即操作可重复torch.cuda.manual_seed(seed)# 为所有 GPU 设置随机种子torch.cuda.manual_seed_all(seed)# 关闭 cudnn 自动寻找最优算法加速的功能,保证结果可重复torch.backends.cudnn.benchmark = False# 设置 cudnn 为确定性算法,确保每次运行结果一致torch.backends.cudnn.deterministic = True检测是否使用cuda
if torch.cuda.is_available():device = 'cuda'print('CUDA is useful!!')
else:device = 'cpu'print('CUDA is not useful!!')设置 pandas 显示选项
# 最多显示1000列
pd.set_option('display.max_columns', 1000)
# 显示宽度为1000
pd.set_option('display.width', 1000)
# 每列最多显示1000个字符
pd.set_option('display.max_colwidth', 1000)3.2、数据操作
读取数据
train_data = pd.read_csv("train_V2.csv")查看缺失情况,并删除
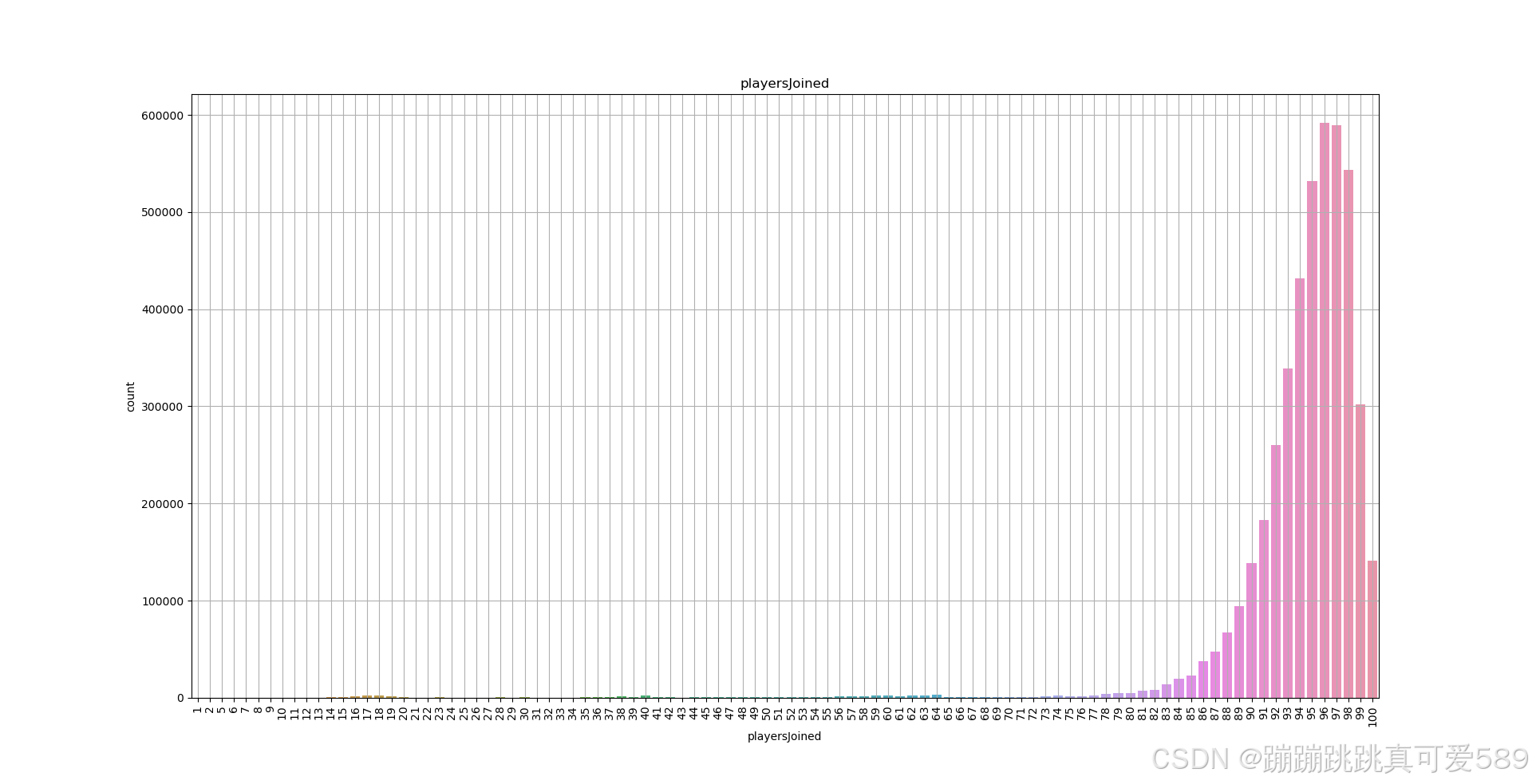
train_data = train_data.dropna(subset=['winPlacePerc']) # 删除目标列缺失的行对 'matchId' 字段进行分组求和,以计算每次比赛的人数,选取每局人数为100的数据
# 按比赛 ID 分组并统计每组的记录数量
count = train_data.groupby('matchId')['matchId'].transform('count')# 将统计结果添加到原数据集中
train_data['playersJoined'] = count # 添加表示每场比赛参与人数的新列# 选取 train_data["playersJoined"] 等于 100 的数据,即选择比赛人数为100的作为训练数据
selected_data = train_data[train_data["playersJoined"] == 100]划分特征和目标
X = selected_data.drop(['Id', 'groupId', 'matchId','winPlacePerc'], axis=1) # 特征集
y = selected_data['winPlacePerc'] # 目标集# 对 'matchType' 列进行独热编码处理
X = pd.get_dummies(X, columns=['matchType'])划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.75, random_state=42)
3.3、标准化
scaler = StandardScaler() # 实例化标准化器
X_train_scaled = scaler.fit_transform(X_train) # 拟合并转换训练集
X_test_scaled = scaler.transform(X_test) # 仅对测试集进行转换
3.4、将数据转换为PyTorch的张量
X_train_tensor = torch.tensor(X_train_scaled, dtype=torch.float32) # 转换训练特征
y_train_tensor = torch.tensor(y_train.values, dtype=torch.float32).view(-1, 1) # 转换训练目标
X_test_tensor = torch.tensor(X_test_scaled, dtype=torch.float32) # 转换测试特征
y_test_tensor = torch.tensor(y_test.values, dtype=torch.float32).view(-1, 1) # 转换测试目标
3.5、使用DataLoader去加载数据集
train_dataset = TensorDataset(X_train_tensor, y_train_tensor) # 创建张量数据集
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True) # 创建数据加载器3.6、定义模型
class DNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(DNN, self).__init__() # 调用父类构造函数self.fc1 = nn.Linear(input_size, hidden_size) # 输入层到隐藏层self.fc2 = nn.Linear(hidden_size, hidden_size) # 隐藏层到隐藏层self.fc3 = nn.Linear(hidden_size, output_size) # 隐藏层到输出层self.relu = nn.ReLU() # ReLU 激活函数def forward(self, x):# 定义前向传播x = self.relu(self.fc1(x)) # 第一个线性层与 ReLU 激活x = self.relu(self.fc2(x)) # 第二个线性层与 ReLU 激活x = self.fc3(x) # 输出层return x# 实例化模型
input_size = X_train_tensor.shape[1] # 输入特征的维数
hidden_size = 128 # 隐藏层的节点数
output_size = 1 # 输出层的节点数
model = DNN(input_size, hidden_size, output_size).to(device) # 创建模型并移动到设备3.7、定义损失函数和优化器
criterion = nn.MSELoss() # 均方误差损失
optimizer = optim.Adam(model.parameters(), lr=0.01) # Adam 优化器3.8、训练模型
num_epochs = 10 # 训练轮数for epoch in range(num_epochs):model.train() # 设置模型为训练模式total_loss = 0 # 初始化总损失for inputs, labels in train_loader:optimizer.zero_grad() # 清空梯度inputs = inputs.to(device) # 将输入移动到设备labels = labels.to(device) # 将标签移动到设备# 前向传播outputs = model(inputs) # 预测输出loss = criterion(outputs, labels) # 计算损失# 反向传播和优化loss.backward() # 反向传播计算梯度optimizer.step() # 更新模型参数total_loss += loss.item() # 累加损失avg_loss = total_loss / len(train_loader) # 计算平均损失print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {avg_loss:.4f}') # 输出每轮损失3.9、模型评估
model.eval() # 设置模型为评估模式
with torch.no_grad(): # 关闭梯度计算predictions = model(X_test_tensor.to(device)) # 预测测试集test_loss = criterion(predictions, y_test_tensor.to(device)) # 计算测试损失3.10、 可视化
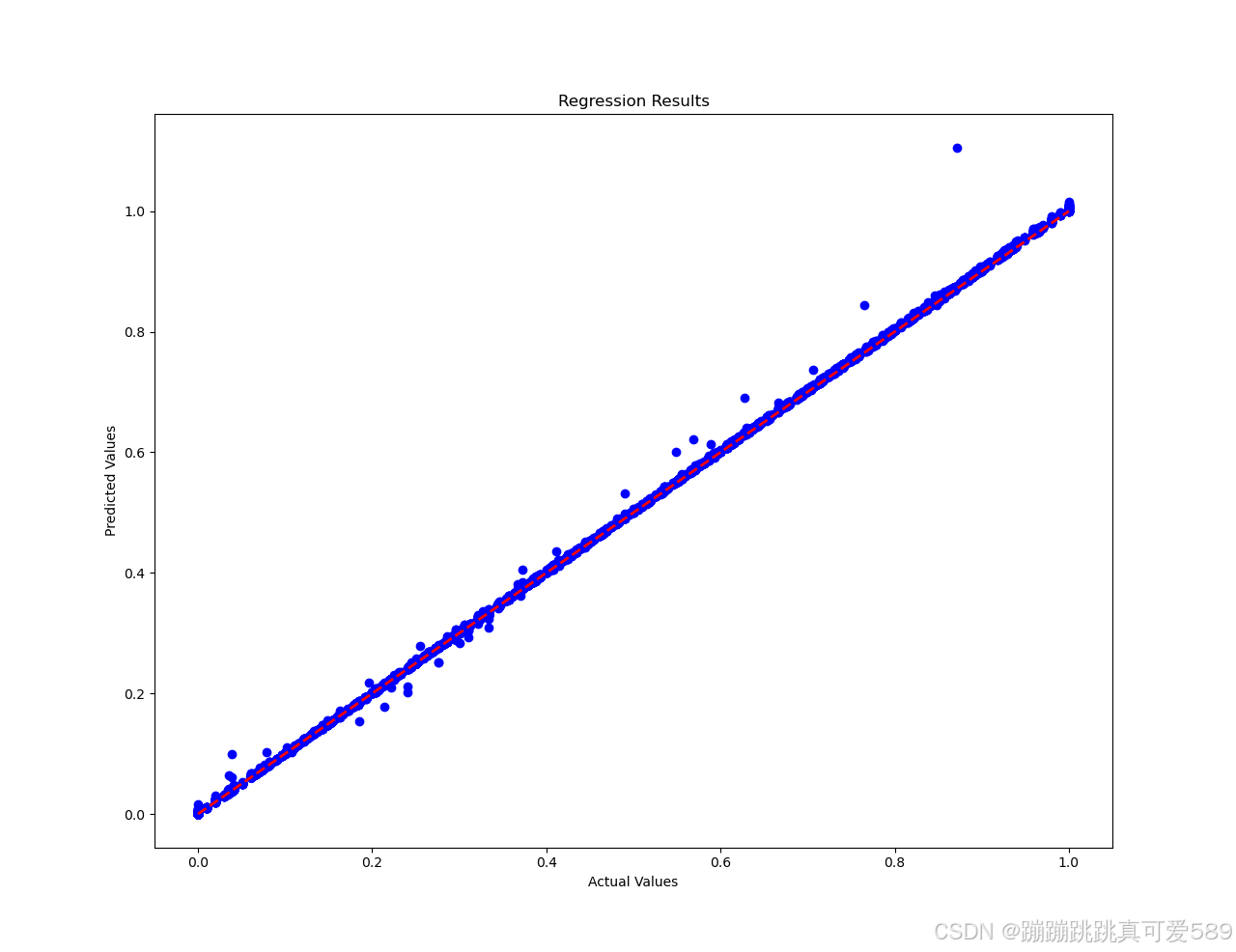
plt.figure(1)
plt.scatter(y_test_numpy, predictions, color='blue') # 绘制实际值与预测值的散点图
plt.plot([min(y_test_numpy), max(y_test_numpy)], [min(y_test_numpy), max(y_test_numpy)], linestyle='--', color='red',linewidth=2) # 绘制理想情况下的对角线
plt.xlabel('Actual Values') # X 轴标签
plt.ylabel('Predicted Values') # Y 轴标签
plt.title('Regression Results') # 图表标题# 绘制实际值和预测值的曲线
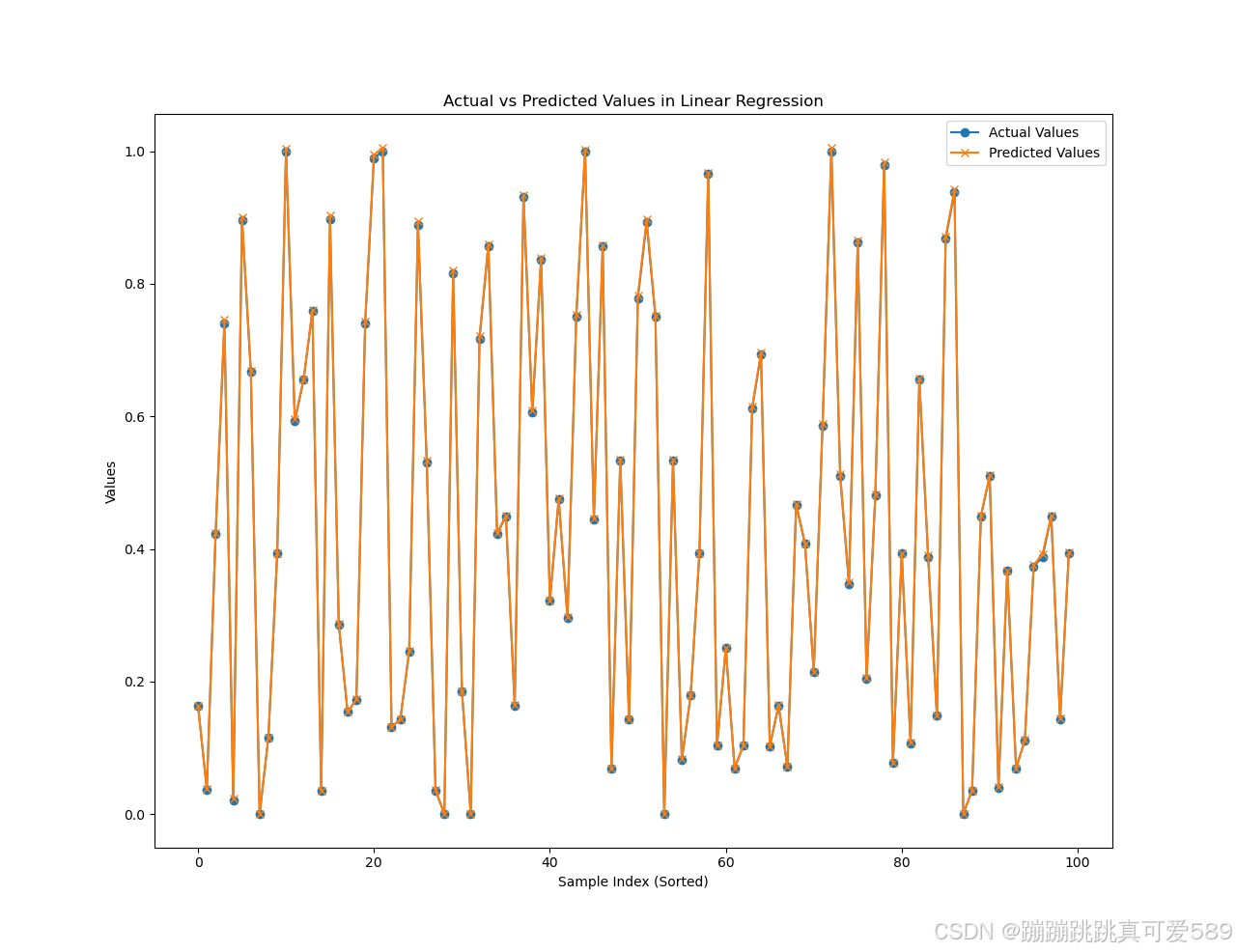
plt.figure(2)
plt.plot(y_test_numpy[-100:], label='Actual Values', marker='o') # 绘制实际值
plt.plot(predictions[-100:], label='Predicted Values', marker='x') # 绘制预测值
plt.xlabel('Sample Index (Sorted)') # X 轴标签
plt.ylabel('Values') # Y 轴标签
plt.title('Actual vs Predicted Values in Linear Regression') # 图表标题
plt.legend() # 显示图例
plt.show() # 显示图表3.11、完整代码
import os
import random
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import torch
from sklearn.preprocessing import StandardScaler
from torch import nn, optim
from torch.utils.data import TensorDataset, DataLoader
from sklearn.model_selection import train_test_split# 设置随机种子以保证结果的可重复性
def setup_seed(seed):np.random.seed(seed) # 设置 Numpy 随机种子random.seed(seed) # 设置 Python 内置随机种子os.environ['PYTHONHASHSEED'] = str(seed) # 设置 Python 哈希种子torch.manual_seed(seed) # 设置 PyTorch 随机种子if torch.cuda.is_available():torch.cuda.manual_seed(seed) # 设置 GPU 随机种子torch.cuda.manual_seed_all(seed) # 确保所有 GPU 使用相同随机种子torch.backends.cudnn.benchmark = False # 关闭 cudnn 加速torch.backends.cudnn.deterministic = True # 设置 cudnn 为确定性算法# 设置随机种子
setup_seed(0)# 检查是否有可用的 GPU,如果有则使用 GPU,否则使用 CPU
if torch.cuda.is_available():device = torch.device("cuda") # 使用 GPUprint("CUDA is available. Using GPU.")
else:device = torch.device("cpu") # 使用 CPUprint("CUDA is not available. Using CPU.")# 读取训练数据集
train_data = pd.read_csv("train_V2.csv")# 检查并删除缺失值
train_data = train_data.dropna(subset=['winPlacePerc']) # 删除目标列缺失的行# 对 'matchId' 字段进行分组求和,以计算每次比赛的人数
# 按比赛 ID 分组并统计每组的记录数量
count = train_data.groupby('matchId')['matchId'].transform('count')# 将统计结果添加到原数据集中
train_data['playersJoined'] = count # 添加表示每场比赛参与人数的新列# 选取 train_data["playersJoined"] 等于 100 的数据,即选择比赛人数为100的作为训练数据
selected_data = train_data[train_data["playersJoined"] == 100]# 将数据集划分为特征集(X)和目标集(y)
X = selected_data.drop(['Id', 'groupId', 'matchId','winPlacePerc'], axis=1) # 特征集
y = selected_data['winPlacePerc'] # 目标集# 对 'matchType' 列进行独热编码处理
X = pd.get_dummies(X, columns=['matchType'])# 将数据集按比例划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.75, random_state=42)# 使用标准化进行特征缩放
scaler = StandardScaler() # 实例化标准化器
X_train_scaled = scaler.fit_transform(X_train) # 拟合并转换训练集
X_test_scaled = scaler.transform(X_test) # 仅对测试集进行转换# 将数据转换为 PyTorch 张量
X_train_tensor = torch.tensor(X_train_scaled, dtype=torch.float32) # 转换训练特征
y_train_tensor = torch.tensor(y_train.values, dtype=torch.float32).view(-1, 1) # 转换训练目标
X_test_tensor = torch.tensor(X_test_scaled, dtype=torch.float32) # 转换测试特征
y_test_tensor = torch.tensor(y_test.values, dtype=torch.float32).view(-1, 1) # 转换测试目标# 创建数据加载器
train_dataset = TensorDataset(X_train_tensor, y_train_tensor) # 创建张量数据集
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True) # 创建数据加载器# 定义一个简单的深度神经网络模型
class DNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(DNN, self).__init__() # 调用父类构造函数self.fc1 = nn.Linear(input_size, hidden_size) # 输入层到隐藏层self.fc2 = nn.Linear(hidden_size, hidden_size) # 隐藏层到隐藏层self.fc3 = nn.Linear(hidden_size, output_size) # 隐藏层到输出层self.relu = nn.ReLU() # ReLU 激活函数def forward(self, x):# 定义前向传播x = self.relu(self.fc1(x)) # 第一个线性层与 ReLU 激活x = self.relu(self.fc2(x)) # 第二个线性层与 ReLU 激活x = self.fc3(x) # 输出层return x# 实例化模型
input_size = X_train_tensor.shape[1] # 输入特征的维数
hidden_size = 128 # 隐藏层的节点数
output_size = 1 # 输出层的节点数
model = DNN(input_size, hidden_size, output_size).to(device) # 创建模型并移动到设备# 定义损失函数和优化器
criterion = nn.MSELoss() # 均方误差损失
optimizer = optim.Adam(model.parameters(), lr=0.01) # Adam 优化器# 训练模型
num_epochs = 10 # 训练轮数for epoch in range(num_epochs):model.train() # 设置模型为训练模式total_loss = 0 # 初始化总损失for inputs, labels in train_loader:optimizer.zero_grad() # 清空梯度inputs = inputs.to(device) # 将输入移动到设备labels = labels.to(device) # 将标签移动到设备# 前向传播outputs = model(inputs) # 预测输出loss = criterion(outputs, labels) # 计算损失# 反向传播和优化loss.backward() # 反向传播计算梯度optimizer.step() # 更新模型参数total_loss += loss.item() # 累加损失avg_loss = total_loss / len(train_loader) # 计算平均损失print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {avg_loss:.4f}') # 输出每轮损失# 评估模型
model.eval() # 设置模型为评估模式
with torch.no_grad(): # 关闭梯度计算predictions = model(X_test_tensor.to(device)) # 预测测试集test_loss = criterion(predictions, y_test_tensor.to(device)) # 计算测试损失# 将预测值和目标值转换为 NumPy 数组
predictions = predictions.cpu().numpy() # 移动到 CPU 并转换为 NumPy 数组
y_test_numpy = y_test_tensor.cpu().numpy() # 将实际目标值转换为 NumPy 数组# 绘制结果
plt.figure(1)
plt.scatter(y_test_numpy, predictions, color='blue') # 绘制实际值与预测值的散点图
plt.plot([min(y_test_numpy), max(y_test_numpy)], [min(y_test_numpy), max(y_test_numpy)], linestyle='--', color='red',linewidth=2) # 绘制理想情况下的对角线
plt.xlabel('Actual Values') # X 轴标签
plt.ylabel('Predicted Values') # Y 轴标签
plt.title('Regression Results') # 图表标题# 绘制实际值和预测值的曲线
plt.figure(2)
plt.plot(y_test_numpy[-100:], label='Actual Values', marker='o') # 绘制实际值
plt.plot(predictions[-100:], label='Predicted Values', marker='x') # 绘制预测值
plt.xlabel('Sample Index (Sorted)') # X 轴标签
plt.ylabel('Values') # Y 轴标签
plt.title('Actual vs Predicted Values in Linear Regression') # 图表标题
plt.legend() # 显示图例
plt.show() # 显示图表



