1、讲一讲Redis各种数据类型与底层实现
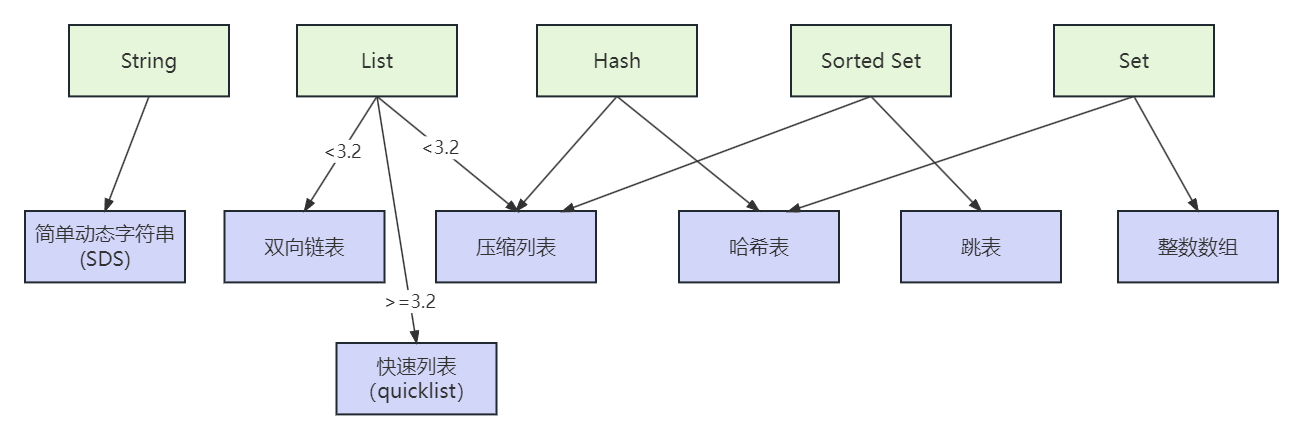
底层数据结构一共有 7 种,分别是简单动态字符串、双向链表、压缩列表、哈希表、跳表和整数数组、快速列表。它们和数据类型的对应关系如下图所示
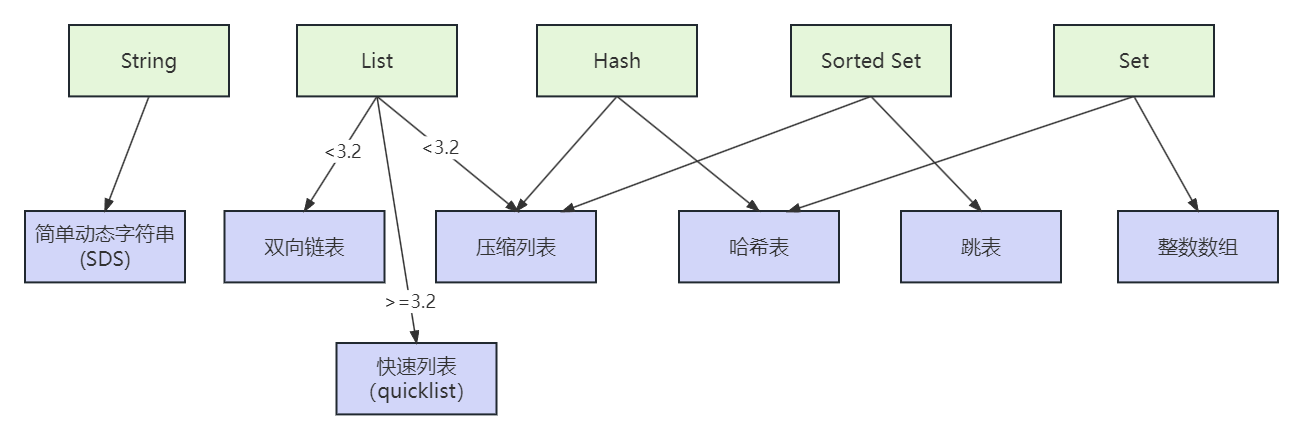
String 类型的底层实现只有一种数据结构,也就是简单动态字符串。而 List、Hash、Set 和 Sorted Set 这四种集合类型,都有两种底层实现结构。
String
Redis 的String类型使用 SDS(简单动态字符串)(Simple Dynamic String)作为底层的数据结构实现。
SDS 与 C 字符串有所不同,它不仅可以保存文本数据,还可以保存二进制数据。这是因为 SDS 使用 len 属性的值而不是空字符来判断字符串是否结束,并且 SDS 的所有 API 都会以处理二进制的方式来处理 SDS 存放在 buf[] 数组里的数据。因此,SDS 不仅能存放文本数据,还能保存图片、音频、视频、压缩文件等二进制数据。
另外,Redis 的 SDS API 是安全的,拼接字符串不会造成缓冲区溢出。这是因为 SDS 在拼接字符串之前会检查 SDS 空间是否满足要求,如果空间不够会自动扩容,从而避免了缓冲区溢出的问题。
此外,获取字符串长度的时间复杂度是 O(1),因为 SDS 结构里用 len 属性记录了字符串长度,所以获取长度的复杂度为 O(1)。相比之下,C 语言的字符串并不记录自身长度,所以获取长度的复杂度为 O(n)。这些特性使得 SDS 成为 Redis 的一个重要组成部分。
源码分析:
不同的版本的实现是有一些区别的。
老版本(3.2之前)
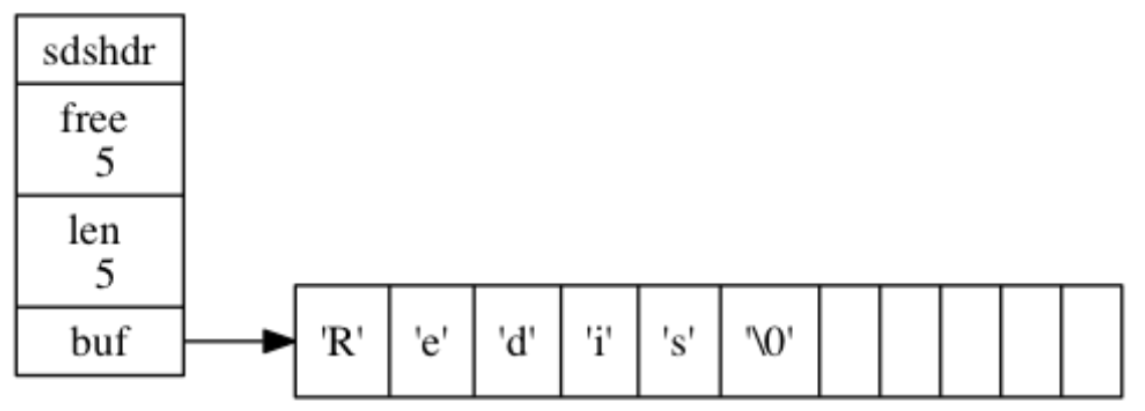
/** 保存字符串对象的结构---这里不是真实的C的源码,我写的一个简化*/
struct sdshdr {// buf 中已占用空间的长度int len;// buf 中剩余可用空间的长度int free;// 数据空间char buf[];
};新版本(3.2之后)
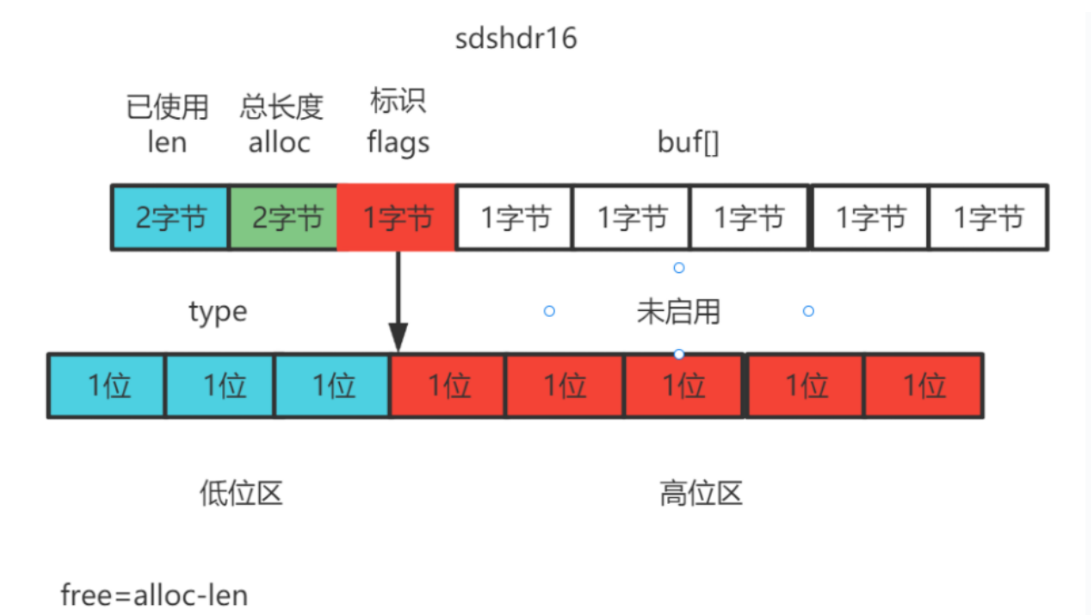
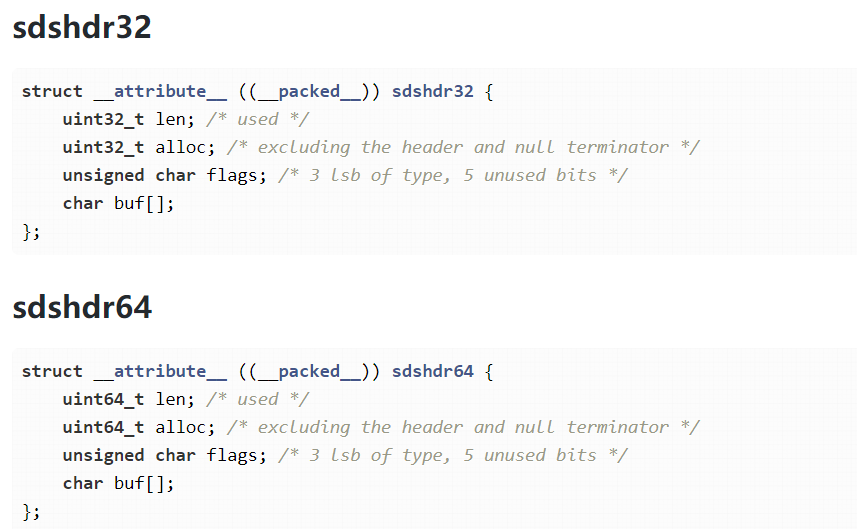
在Redis的6及6以后,会根据字符串长度不同,定义了5种的SDS结构体sdshdr5、sdshdr8、sdshdr16、sdshdr32、sdshdr64,长度分别对应,2的n次幂(2的5次幂、2的8次幂…),用于用于存储不同长度的字符串。
- sdshdr5:适用于长度小于32**<2的5次方>**的字符串。
- sdshdr8:适用于长度小于256**<2的8次方>**的字符串。
- sdshdr16:适用于长度小于65535**<2的16次方>**的字符串。
- sdshdr32:适用于长度小于4294967295**<2的32次方>**的字符串。
- sdshdr64:适用于长度大于4294967295的字符串。
通过使用不同的sdshdr结构,Redis可以根据字符串的长度选择最合适的结构,从而提高内存利用率。例如,当我们存储一个长度为3字节的字符串时,Redis会选择使用sdshdr5结构,而不会浪费额外的内存空间。
sdshdr5结构如下:
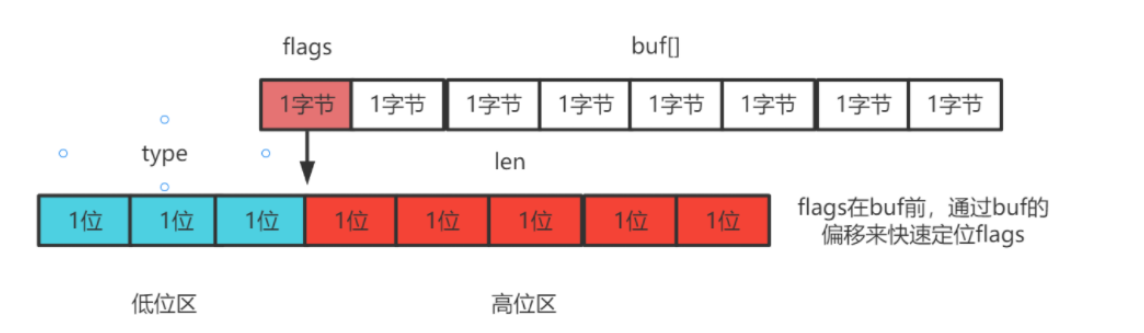
sdshdr5的结构中flags是一个char,其中低3位要标识type类型(就是存储的格式),所有就只有5位来存储len这个长度,所以就叫做sdshdr5
struct sdshdr5 {char flags; // 数据空间char buf[];
};而如果是更长的长度,Redis就需要采用sdshdr8或者sdshdr16或者更大的存储结构。
Redis的sdshdr5相对于sdshdr8少两个字段,是为了节省内存空间和提高处理短字符串的效率。根据字符串的长度范围选择适合的sdshdr结构,可以优化内存利用和性能。


从String的设计上来看,Redis已经把空间利用做到了极致,同时的也可以从sdshdr5到sdshdr8…看出设计原则:开闭原则,对修改关闭,对拓展开放。
List
在 Redis 3.2 版本之前
Redis 的 List 类型底层数据结构可以由双向链表或压缩列表实现。如果列表元素个数小于 512 个且每个元素的值都小于 64 字节,则 Redis 会使用压缩列表作为底层数据结构;否则,Redis 会使用双向链表作为底层数据结构。
在 Redis 3.2 版本之后
List 类型底层数据结构只由 quicklist 实现,代替了双向链表和压缩列表。
具体实现之类的可以看:《通过C语言深度解读Redis核心架构》这个课
https://www.mashibing.com/study?courseNo=1965§ionNo=90156&systemId=1&courseVersionId=2650
包括其他的数据类型的实现,大家感兴趣研究源码,也可以看看这个课
总结
其实我们面试被问到这样的源码问题,大家肯定不会对各种数据类型有这么高的熟悉度(通过源码去掌握),我给大家的建议是记住以下的几点即可(达到面试的要求):
1、除了String,其他的数据类型都有2种及以上的实现。
2、双向链表不用多说,就是方便两头遍历。哈希表也不用多说,也就是类似于HashMap(数组+链表)。
3、压缩列表实际上类似于一个数组,压缩列表在表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量和列表中的 entry 个数。

好处就是是连续存储空间,避免了节点之间的额外指针开销,从而减少了内存的使用量。
如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N)
所以在List的老版本实现中,随着List的增长,Redis会自动将其转换为双向链表。
4、跳表在链表的基础上,增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位
跳表使用空间换时间的做法,多层结构会多出存储,但是可以提高查询的效率。
5、快速列表比较复杂,具体还是看上面的源码课(里面有级联更新、空间效率与时间效率的折中、压缩中间节点等要点)
2、说一说Redis的Key和Value的数据结构组织?
全局哈希表
为了实现从键到值的快速访问,Redis 使用了一个哈希表来保存所有键值对。一个哈希表,其实就是一个数组,数组的每个元素称为一个哈希桶。所以,我们常说,一个哈希表是由多个哈希桶组成的,每个哈希桶中保存了键值对数据。
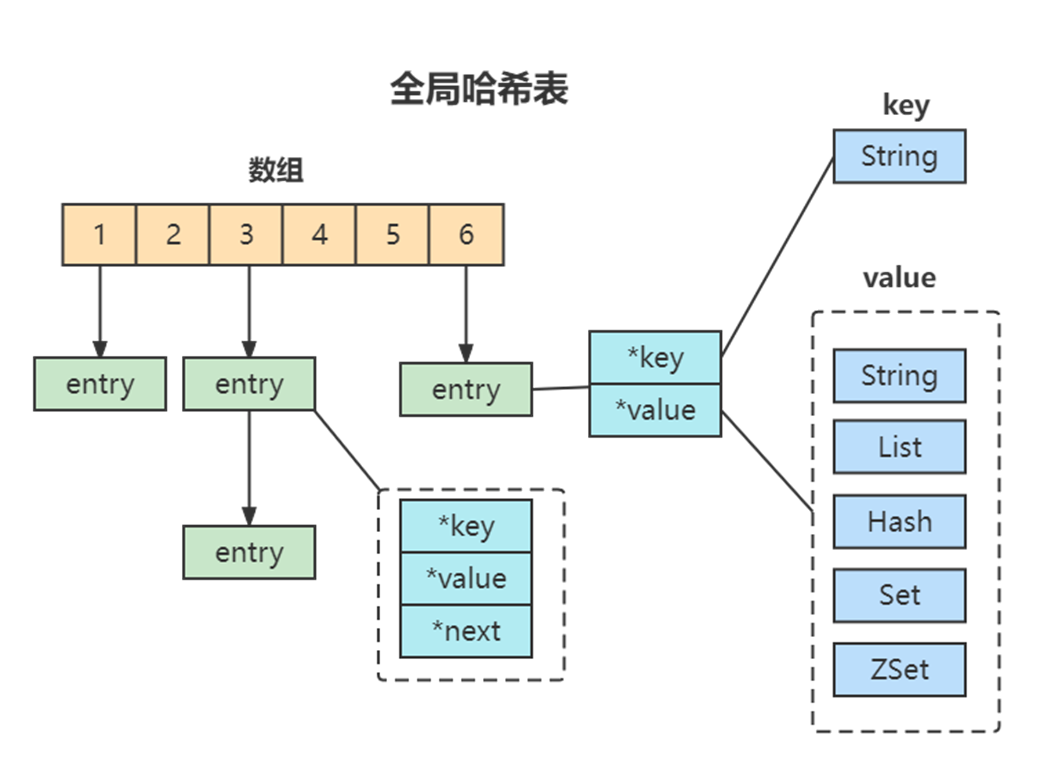
哈希桶中的 entry 元素中保存了key和value指针,分别指向了实际的键和值,这样一来,即使值是一个集合,也可以通过*value指针被查找到。因为这个哈希表保存了所有的键值对,所以,我也把它称为全局哈希表。
哈希表的最大好处很明显,就是让我们可以用 O(1) 的时间复杂度来快速查找到键值对:我们只需要计算键的哈希值,就可以知道它所对应的哈希桶位置,然后就可以访问相应的 entry 元素。
但当你往 Redis 中写入大量数据后,就可能发现操作有时候会突然变慢了。这其实是因为你忽略了一个潜在
的风险点,那就是哈希表的冲突问题和 rehash 可能带来的操作阻塞。
当你往哈希表中写入更多数据时,哈希冲突是不可避免的问题。这里的哈希冲突,两个 key 的哈希值和哈希桶计算对应关系时,正好落在了同一个哈希桶中。
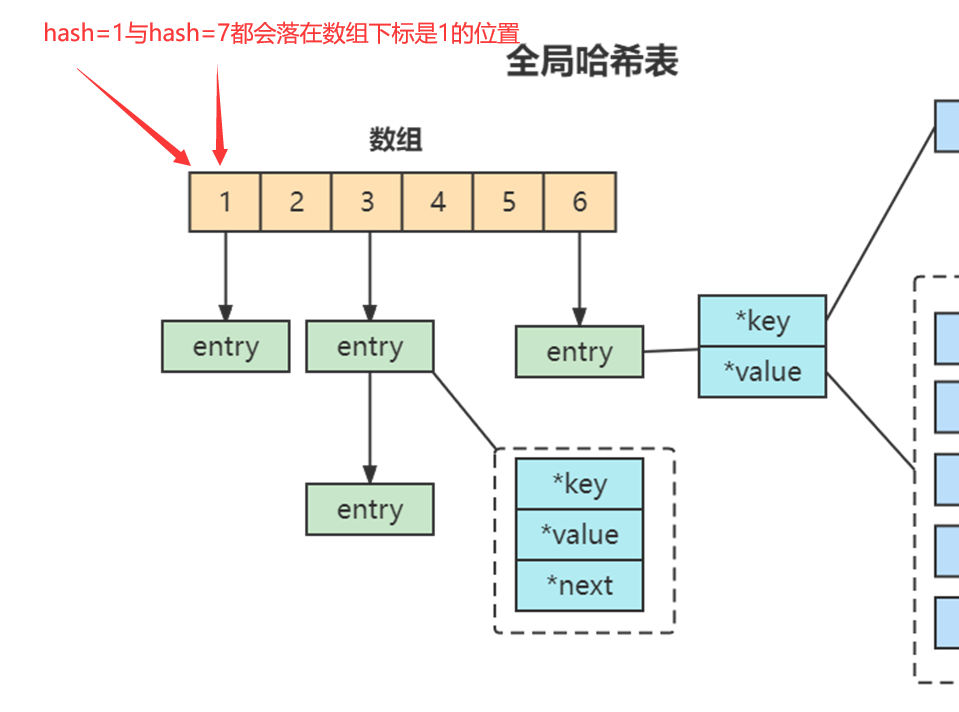
Redis 解决哈希冲突的方式,就是链式哈希。链式哈希也很容易理解,就是指同一个哈希桶中的多个元素用一个链表来保存,它们之间依次用指针连接。
当然如果这个数组一直不变,那么hash冲突会变很多,这个时候检索效率会大打折扣,所以Redis就需要把数组进行扩容(一般是扩大到原来的两倍),但是问题来了,扩容后每个hash桶的数据会分散到不同的位置,这里设计到元素的移动,必定会阻塞IO,所以这个ReHash过程会导致很多请求阻塞。
3、聊一聊Redis中的渐进式rehash
Redis的渐进式rehash是指扩展或收缩哈希表时,需要将哈希表0里面的所有键值对rehash到哈希表1里面,但这个rehash动作并不是一次性、集中式地完成的,而是分多次、渐进式地完成的。
这样做的原因在于,如果哈希表里保存的键值对数量很大时,如:上百万、上千万,一次性、集中式地完成rehash动作,会导致服务器停止服务很长时间,影响用户体验。
处理大致思路如下(举例中是做类比):
我们知道,在rehash的时候,迁移元素是必须要暂停的(如果不暂停就会发生问题,一个值)
在Redis 开始执行 rehash,Redis仍然正常处理客户端请求,但是要加入一个额外的处理:
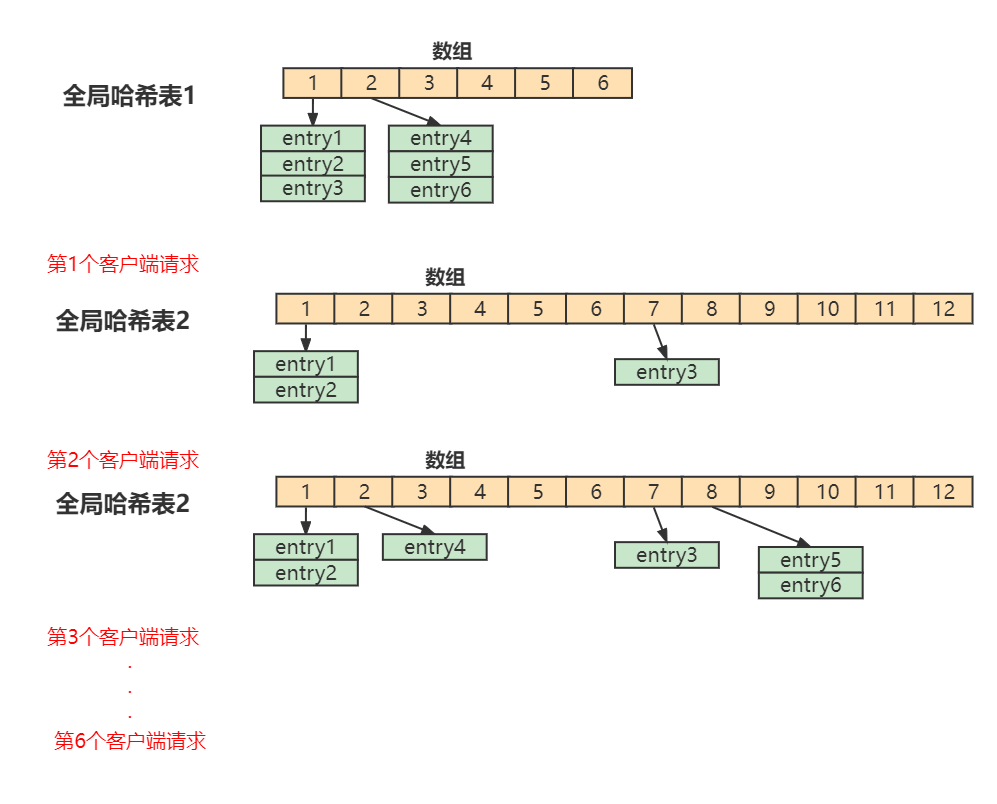
处理第1个请求时,把哈希表 1中的第1个索引位置上的所有 entries 拷贝到哈希表 2 中
处理第2个请求时,把哈希表 1中的第2个索引位置上的所有 entries 拷贝到哈希表 2 中
如此循环,直到把所有的索引位置的数据都拷贝到哈希表 2 中。
这样就巧妙地把一次性大量拷贝的开销,分摊到了多次处理请求的过程中,避免了耗时操作,保证了数据的快速访问。
实际Redis的处理不是一个数组位置,而是一批(多个数组位置)(这一批次的计算也是要通过计算能控制Redis的卡顿延时的)然后完成的操作。
4、聊一聊Redis的持久化!
Redis虽然是个内存数据库,但是Redis支持RDB和AOF两种持久化机制,将数据写往磁盘,可以有效地避免因进程退出造成的数据丢失问题,当下次重启时利用之前持久化的文件即可实现数据恢复。
RDB
RDB持久化是把当前进程数据生成快照保存到硬盘的过程。所谓内存快照,就是指内存中的数据在某一个时刻的状态记录。这就类似于照片,当你给朋友拍照时,一张照片就能把朋友一瞬间的形象完全记下来。RDB 就是Redis DataBase 的缩写。
RDB文件的生成是否会阻塞主线程
Redis 提供了两个手动命令来生成 RDB 文件,分别是 save 和 bgsave。
save:在主线程中执行,会导致阻塞;对于内存比较大的实例会造成长时间阻塞,线上环境不建议使用。
bgsave:创建一个子进程,专门用于写入 RDB 文件,避免了主线程的阻塞,这也是Redis RDB 文件生成的默认配置。
bgsave的写时复制
为了快照而暂停写操作,肯定是不能接受的。所以这个时候,Redis 就会借助操作系统提供的写时复制技术(Copy-On-Write, COW),在执行快照的同时,正常处理写操作。
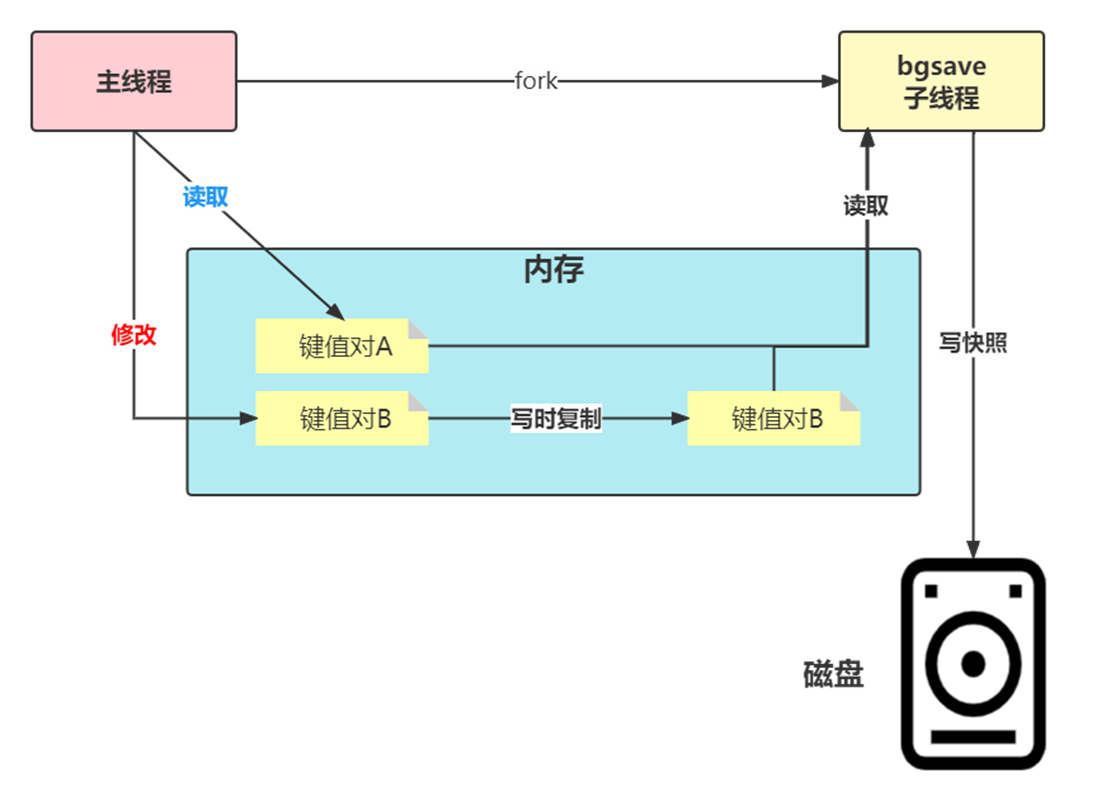
bgsave 子进程是由主线程 fork 生成的(fork这个瞬间一定是会阻塞主线程),可以共享主线程的所有内存数据。bgsave 子进程运行后,开始读取主线程的内存数据,并把它们写入 RDB 文件。
如果主线程对这些数据也都是读操作(例如图中的键值对 A),那么,主线程和bgsave 子进程相互不影响。但是,如果主线程要修改一块数据(例如图中的键值对 B),那么,这块数据就会被复制一份,生成该数据的副本。然后,bgsave 子进程会把这个副本数据写入 RDB 文件,而在这个过程中,主线程仍然可以直接修改原来的数据。
这既保证了快照的完整性,也允许主线程同时对数据进行修改,避免了对正常业务的影响。
huge pages问题
现代处理器的内存管理单元(MMU)大多都支持多种大小的page size。但内核长期以来默认使用4k大小的page size。对大于4k的页,我们统称为 “大页(huge pages”)。在某些应用场景下,使用 huge pages 可以获得更好的性能。但是Redis在实际使用Redis时是建议关掉的。原因如下:
因为fork后,父进程修改数据采用写时复制,复制的粒度为一个内存页。如果只是修改一个256B的数据,父进程需要读原来的内存页,然后再映射到新的物理地址写入。一读一写会造成读写放大。如果内存页越大(例如2MB的大页),那么读写放大也就越严重,对Redis性能造成影响。
AOF
1、AOF命令写入的内容直接是RESP文本协议格式。例如lpush lijin A B这条命令,在AOF缓冲区会追加如下文本:
*3\r\n$6\r\nlupush\r\n$5\r\nlijin\r\n$3\r\nA B
看看 AOF 日志的内容。其中,“*3”表示当前命令有三个部分,每部分都是由“$+数字”开头,后面紧跟着
具体的命令、键或值。这里,“数字”表示这部分中的命令、键或值一共有多少字节。例如,“$3 set”表示这部分有 3 个字节,也就是“set”命令。
2、Redis提供了多种AOF缓冲区同步文件策略,由参数appendfsync控制。

always
同步写回:每个写命令执行完,立马同步地将日志写回磁盘;
everysec
每秒写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘;
no
操作系统控制的写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘,通常同步周期最长30秒。
很明显,配置为always时,每次写入都要同步AOF文件,在一般的SATA 硬盘上,Redis只能支持大约几百TPS写入,显然跟Redis高性能特性背道而驰,不建议配置。
配置为no,由于操作系统每次同步AOF文件的周期不可控,而且会加大每次同步硬盘的数据量,虽然提升了性能,但数据安全性无法保证。
配置为everysec,是建议的同步策略,也是默认配置,做到兼顾性能和数据安全性。理论上只有在系统突然宕机的情况下丢失1秒的数据。(严格来说最多丢失1秒数据是不准确的)
想要获得高性能,就选择 no 策略;如果想要得到高可靠性保证,就选择always 策略;如果允许数据有一点丢失,又希望性能别受太大影响的话,那么就选择everysec 策略。
AOF重写
随着命令不断写入AOF,文件会越来越大,为了解决这个问题,Redis引入AOF重写机制压缩文件体积。AOF文件重写是把Redis进程内的数据转化为写命令同步到新AOF文件的过程。
重写后的AOF 文件为什么可以变小?有如下原因:
1)进程内已经超时的数据不再写入文件。
2)旧的AOF文件含有无效命令,如set a 111、set a 222等。重写使用进程内数据直接生成,这样新的AOF文件只保留最终数据的写入命令。
3)多条写命令可以合并为一个,如:lpush list a、lpush list b、lpush list c可以转化为: lpush list a b c。为了防止单条命令过大造成客户端缓冲区溢出,对于list、set、hash、zset等类型操作,以64个元素为界拆分为多条。
AOF重写触发
AOF重写过程可以手动触发和自动触发:
手动触发:直接调用bgrewriteaof命令。

自动触发:根据auto-aof-rewrite-min-size和 auto-aof-rewrite-percentage参数确定自动触发时机。

auto-aof-rewrite-min-size:表示运行AOF重写时AOF文件最小体积,默认为64MB。
auto-aof-rewrite-percentage :代表当前AOF 文件空间(aof_currentsize)和上一次重写后AOF 文件空间(aof_base_size)的比值。
这两个参数是同时生效的,即需要同时满足条件才会触发自动AOF重写。也就是说,AOF文件的当前大小增量必须大于auto-aof-rewrite-min-size,并且增量所占上次重写后大小的百分比必须大于auto-aof-rewrite-percentage
AOF重写过程
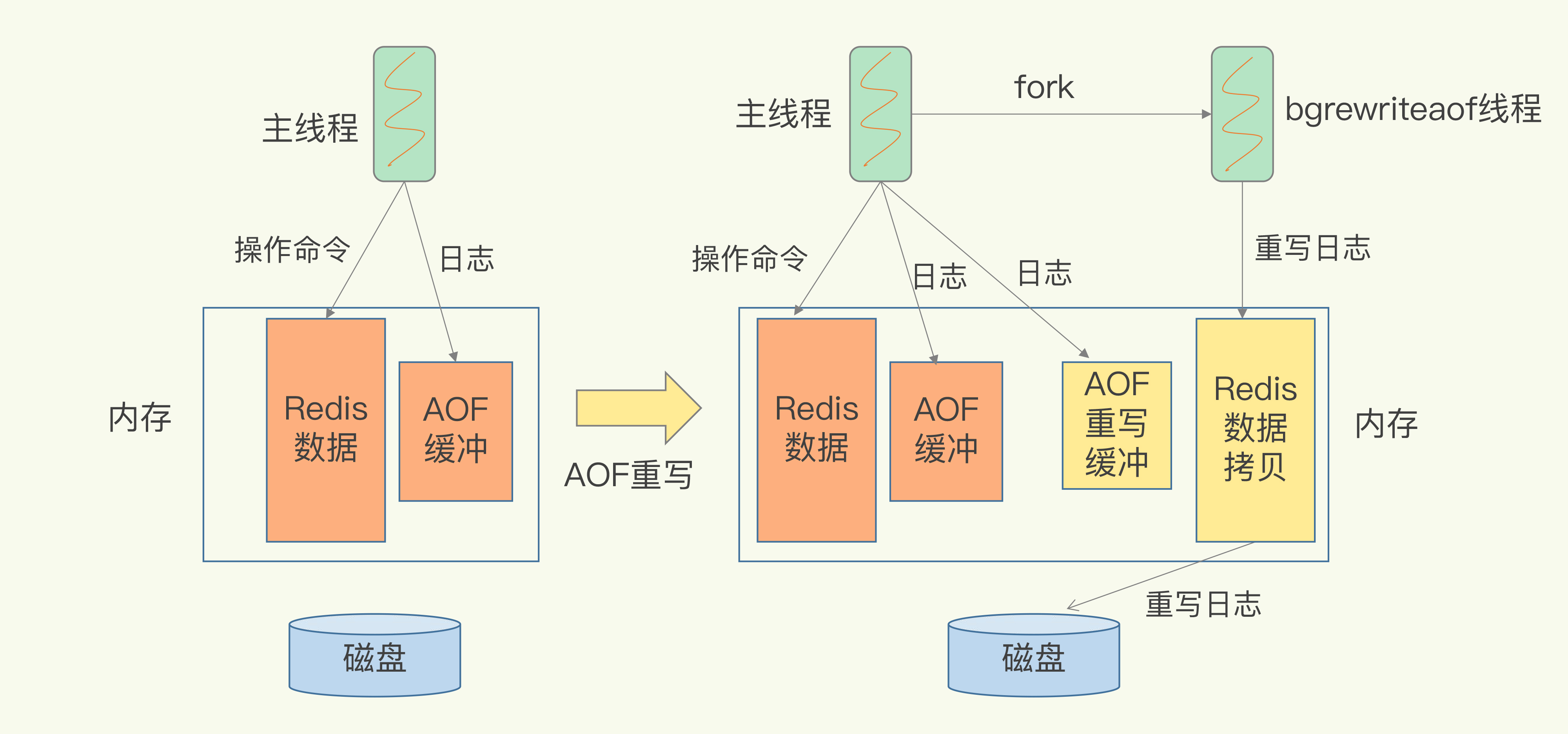
重写过程是由后台线程bgrewriteaof线程触发的。
每次执行重写时,主线程 fork 出后台的 bgrewriteaof 子进程。此时,fork 会把主线程的内存拷贝一份给 bgrewriteaof 子进程,这里面就包含了Redis的最新数据。然后,bgrewriteaof 子进程就可以在不影响主线程的情况下,逐一把拷贝的数据写成操作,记入重写日志

这个开启后,默认还是走RDB的持久化(定时/条件的触发),另外利用AOF日志记录两次快照之间的操作,这个方法既能享受到 RDB 文件快速恢复的好处,又能享受到 AOF 只记录操作命令的优势。
AOF 重写时会把 Redis 的持久化数据,以 RDB 的格式写入到 AOF 文件的开头,之后的数据再以 AOF 的格式化追加的文件的末尾

混合持久化的加载流程如下:
- 判断是否开启 AOF 持久化,开启继续执行后续流程,未开启执行加载 RDB 文件的流程;
- 判断 appendonly.aof 文件是否存在,文件存在则执行后续流程;
- 判断 AOF 文件开头是 RDB 的格式, 先加载 RDB 内容再加载剩余的 AOF 内容;
- 判断 AOF 文件开头不是 RDB 的格式,直接以 AOF 格式加载整个文件# 课堂学员的提问

1、对于数据丢失这种情况可以容忍,还是走RDB
2、不能容忍 -AOF。
3、混合比较综合。

没办法—Redis不是关系型数据库。

Hash表—数组+链表。 链表的长度(
1、是 实际放入的数据/数组的长度 = 比值,这个值越多,冲突越大,链表越长。
2、依赖于Hash算法)
使用渐进式Rehash,扩容的时机可以适度提前。

集群的情况下,分槽。
RedisCluster槽范围是0 ~16383
集群中有多少台, 去平分这些槽。 key 通过hash算法,算出是哪个槽 ,落地到哪台Redis服务上(集群状态下)

老的数据(已经迁移过的 old-hashtable 先不管) 等所有的数据迁移完了,就可以删除释放内存。

Rehash的线程是主线程。也就是处理的同一线程





: 在windows系统上部署项目1)