昇思25天学习打卡营第05天 | 数据变换 Transforms
文章目录
- 昇思25天学习打卡营第05天 | 数据变换 Transforms
- Common Transforms
- Compose
- Vision Transforms
- Text Transform
- PythonTokenizer
- Lookup
- Lambda Transforms
- 数据处理模式
- Pipeline模式
- Eager模式
- 总结
- 打卡
通常情况下的原始数据不能直接输入到网络中进行训练,需要对数据进行预处理。
mindspoer.dataset提供了面向图像、文本、音频等数据类型的Transforms,也支持Lambda函数。
Common Transforms
mindspore.dataset.transforms.Compose:将多个数据增强操作组合使用;mindspore.dataset.transforms.Concatenate:在输入数据的某一个轴上进行数组拼接,目前仅支持1D数组的拼接;mindspore.dataset.transforms.Duplicate:将输入的数据列复制得到新的数据列,每次仅可以输入1个数据列进行复制;mindspore.dataset.transforms.Fill:将Tensor的所有元素填充为指定值;mindspore.dataset.transforms.Mask:用给定条件判断输入的 Tensor,返回一个掩码Tensor;mindspore.dataset.transforms.OneHot:对标签进行OneHot编码;mindspore.dataset.transforms.PadEnd:对输入Tensor进行填充,要求pad_shape与输入Tensor的维度一致;mindspore.dataset.transforms.RandomApply:指定一组数据增强处理及被应用的概率;mindspore.dataset.transforms.RandomChoice:从一组数据增强变换中随机选择一个进行应用;mindspore.dataset.transforms.RandomOrder:随机打乱数据增强处理的顺序;mindspore.dataset.transforms.Slice:对输入进行切片;mindspore.dataset.transforms.TypeCast:将输入Tensor转换为指定类型;mindspore.dataset.transforms.Unique:对输入张量进行唯一运算,每次只支持对一个数据列进行变换。
Compose
composed = transforms.Compose([vision.Rescale(1.0 / 255.0, 0),vision.Normalize(mean=(0.1307,), std=(0.3081,)),vision.HWC2CHW()]
)
通过Compose将缩放、标准化、图像格式转换组合为一个变换进行使用。
Vision Transforms
mindspore.dataset.vision.AdjustBrightness:调整亮度;mindspore.dataset.vision.AdjustContrast:调整对比度;mindspore.dataset.vision.AdjustGamma:伽马矫正;mindspore.dataset.vision.AdjustHue:调整色调;mindspore.dataset.vision.AdjustSaturation:调整饱和度;mindspore.dataset.vision.AdjustSharpness:调整锐度;mindspore.dataset.vision.Affine:进行仿射变换,保持图像中心不动;mindspore.dataset.vision.AutoAugment:应用AutoAugment数据增强方法;mindspore.dataset.vision.AutoContrast:自动对比度;mindspore.dataset.vision.BoundingBoxAugment:随即标注边界框区域,应用给定图像变换;mindspore.dataset.vision.CenterCrop:对输入图像中心区域裁剪;mindspore.dataset.vision.ConvertColor:更改色彩空间;mindspore.dataset.vision.Crop:裁剪指定区域;mindspore.dataset.vision.CutMixBatch:对输入批次的图像和标注应用剪切混合转换;mindspore.dataset.vision.CutOut:裁剪给定数量的正方形区域;mindspore.dataset.vision.Decode:解码为RGB格式;mindspore.dataset.vision.Equalize:直方图均衡化;mindspore.dataset.vision.Erase:使用指定的值擦除输入图像;mindspore.dataset.vision.FiveCrop:在输入PIL图像的中心和四个角处分别裁剪指定大小的子图;mindspore.dataset.vision.GaussianBlur:使用指定的高斯核对输入图形进行模糊;mindspore.dataset.vision.Grayscale:将输入PIL图像转换为灰度图;mindspore.dataset.vision.HorizontalFlip:水平翻转;mindspore.dataset.vision.HsvToRgb:将输入的HSV格式numpy.ndarray转换为RGB格式;mindspore.dataset.vision.HWC2CHW:将图像的shape从<H, W, C>转换为<C, H, W>;mindspore.dataset.vision.Invert:对RGB图像进行色彩反转;mindspore.dataset.vision.LinearTransformation:使用指定的变换方阵和均值向量对输入的numpy.ndarray图像进行线性变换;mindspore.dataset.vision.MixUp:随机混合一批输入的numpy.ndarray图像及其标签;mindspore.dataset.vision.MixUpBatch:对输入批次的图像和标签应用混合转换;mindspore.dataset.vision.Normalize:根据均值和方差对输入图像归一化;mindspore.dataset.vision.NormalizePad:根据均值和方差对输入图像归一化,然后填充一个全零的额外通道;mindspore.dataset.vision.Pad:填充图像;mindspore.dataset.vision.PadToSize:将图像填充到固定大小;mindspore.dataset.vision.Perspecctive:进行透视变换;mindspore.dataset.vision.Posterize:减少图像颜色通道的比特位数,使图像变得高对比和颜色鲜艳,类似于海报或印刷品的效果;mindspore.dataset.vision.RandAugment:应用RandAugment数据增强方法;mindspore.dataset.vision.RandomAdjustSharpness:以给定概率随机调整锐度;mindspore.dataset.vision.RandomAffine:应用随机仿射变换;mindspore.dataset.vision.RandomAutoContrast:以给定概率自动调整对比度;mindspore.dataset.vision.RandomColor:随即调整颜色;mindspore.dataset.vision.RandomColorAdjust:随机调整亮度、对比度、饱和度和色调;mindspore.dataset.vision.RandomCrop:随机区域裁剪;mindspore.dataset.vision.RandomCropDecodeResize:裁剪、解码、调整尺寸大小的组合;mindspore.dataset.vision.RandomCropWithBBox:在随机位置进行裁剪并调整边界框;mindspore.dataset.vision.RandomEqualize:以给定概率随机进行直方图均衡化;mindspore.dataset.vision.RandomErasing:按照指定的概率擦除numpy.ndarray图像上随机矩形区域内的像素;mindspore.dataset.vision.RandomGrayscale:按指定概率将PIL图像转换为灰度图;mindspore.dataset.vision.RandomHorizontalFlip:按概率随机进行水平翻转;mindspore.dataset.vision.RandomHorizontalFlipWithBBox:按概率对输入图形及其边界框进行随机水平翻转;mindspore.dataset.vision.RandomInvert:按概率随机反转图像颜色;mindspore.dataset.vision.RandomLighting:将AlexNet PCA的噪声添加到图像中;mindspore.dataset.vision.RandomPerspective:按概率对PIL图像进行透视变换;mindspore.dataset.vision.RandomPosterize:随机减少图像颜色通道的比特位数,使图像变得高对比度和颜色鲜艳;mindspore.dataset.vision.RandomResizedCrop:对输入图像随机裁剪,并使用指定的mindspore.dataset.vision.Inter插值方式调整为指定尺寸大小;mindspore.dataset.vision.RandomResizedCropWithBBox:对输入图形随机裁剪且随机调整纵横比,并将处理后的图像调整为指定的尺寸大小,并调整边界框;mindspore.dataset.vision.RandomResize:使用随机选择的mindspore.dataset.vision.Inter插值方式去调整尺寸大小;mindspore.dataset.vision.RandomResizeWithBBox:使用随机选择的mindspore.dataset.vision.Inter插值方式去调整它的尺寸大小,并调整边界框的尺寸大小;mindspore.dataset.vision.RandomRotation:在指定角度范围内,随机旋转输入图形;mindspore.dataset.vision.RandomSelectSubpolicy:从策略列表中随机选择一个子策略应用于输入图像;mindspore.dataset.vision.RandomSharpness:在固定或随即范围内调整锐度;mindspore.dataset.vision.RandomSolarize:在给定阈值范围内随机选择一个子范围,对子范围内的像素,将像素值设置为(255-原像素);mindspore.dataset.vision.RandomVerticalFlip:以概率随机进行垂直翻转;mindspore.dataset.vision.RandomVerticalFlipWithBBox:以概率对图像和边界框进行随机垂直翻转;mindspore.dataset.vision.Rescale:基于给定缩放因子和平移因子调整像素值;mindspore.dataset.vision.Resize:使用给定的mindspore.dataset.vision.Inter插值方式调整为指定的尺寸大小;mindspore.dataset.vision.ResizedCrop:裁切图像指定区域并放缩到指定大小;mindspore.dataset.vision.ResizeWithBBox:调整给定尺寸大小,并调整边界框的尺寸大小;mindspore.dataset.vision.RgbToHsv:将RGB格式的numpy.ndarray图像转换为HSV格式;mindspore.dataset.vision.Rotate:旋转指定度数;mindspore.dataset.vision.SlicePatches:在水平和垂直方向上将Tensor切片为多个块;mindspore.dataset.vision.Solarize:通过反转阈值内的所有像素值,对输入图形进行曝光;mindspore.dataset.vision.TenCrop:在输入PIL图像的中心与四个角处分别裁剪为指定尺寸大小的子图,并将其翻转图一并返回;mindspore.dataset.vision.ToNumpy:将输入PIL图像转换为numpy.ndarray图像;mindspore.dataset.vision.ToPIL:将numpy.ndarray格式的解码图像转换为PIL.Image.Imagemindspore.dataset.vision.ToTensor:将PIL图像或numpy.ndarray图像转换为指定类型的numpy.ndarray图像,像素从 [ 0 , 255 ] [0, 255] [0,255]放缩为 [ 0.0 , 1.0 ] [0.0, 1.0] [0.0,1.0],shape将从<H, W, C> 调整为 <C, H, W>;mindspore.dataset.vision.ToType:将输入转换为指定MindSpore或NumPy数据类型;mindspore.dataset.vision.TrivialAugmentWide:使用TrivialAugmentWide数据增强方法;mindspore.dataset.vision.UniformAugment:从指定序列中均匀采样一批数据处理操作,并按顺序随机执行;mindspore.dataset.vision.VerticalFlip:垂直翻转。
Text Transform
文本数据需要有分词(Tokenize)、构建词表、Token转Index等操作。
PythonTokenizer
分词操作时文本数据的基础处理方法,PythonTokenizer允许用户自由实现分词策略,随后利用map操作将分词器应用到输入文本中:
texts = ['Welcome to Beijing']
test_dataset = GeneratorDataset(texts, 'text')def my_tokenizer(content):return content.split()test_dataset = test_dataset.map(text.PythonTokenizer(my_tokenizer))
Lookup
Lookup为词表映射变换,用来将Token转换为Index。使用Lookup之前需要构造词表,一般可以加载已有的词表或使用Vocab生成词表。
vocab = text.Vocab.from_dataset(test_dataset)
test_dataset = test_dataset.map(text.Lookup(vocab))
Lambda Transforms
Lanbda Transform可以加载任意定义的Lambda函数,提供足够的灵活度。
test_dataset = GeneratorDataset([1, 2, 3], 'data', shuffle=False)
test_dataset = test_dataset.map(lambda x: x * 2)def func(x):return x * x + 2
test_dataset = test_dataset.map(lambda x: func(x))
数据处理模式
Pipeline模式
Pipeline模式需要使用map方法,将数据变换交由map调度,由map负责启动和执行给定的Transform。
这种模式能够在资源条件下允许的情况下获得更高的性能。
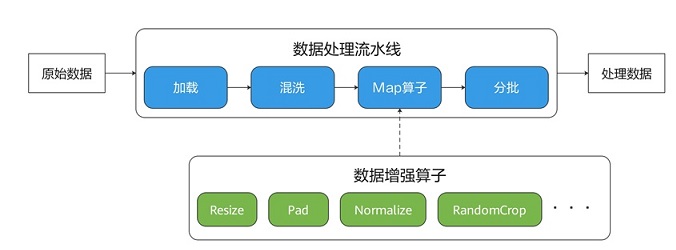
Eager模式
在Eager模式下,执行Transforms不需要依赖map,而是直接以函数式调用的方式执行Transforms。因此代码更为简洁且能立即执行得到结果,适合在小型数据增强实验、模型推理等轻量化场景中使用。

总结
通过这一小节的内容,对MindSpore中的数据变换有了深入的了解,通过查阅官方文档,对每一类数据所提供的Transform有了大概的认识,此外还了解了一般的文本数据处理流程,了解了两种数据处理模式。
打卡




![[electron] electron の 快速尝试](http://pic.xiahunao.cn/nshx/[electron] electron の 快速尝试)
中的KITTI数据文件配置!)
