大家好!我是心海
流处理技术在大数据时代正变得越来越重要,而 Apache Flink 作为领先的流处理引擎,凭借其高性能、低延迟和丰富的 API 受到了广泛关注。本文将以 Scala 语言为例,详细讲解 Flink DataStream API 的基本编程模型,从数据源、数据转换、数据输出,到窗口划分与时间概念,最后结合经典的 WordCount 案例,带大家一步步动手实践。
目录
一、DataStream API:构建流处理世界的基石
二、 基本编程实践:WordCount 示例
2.1 代码示例
2.2 代码解析
三、窗口的划分:在无限流中框定边界
3.1 时间概念
3.2 窗口划分
3.3 窗口计算
3.4 窗口计算示例
四、总结
一、DataStream API:构建流处理世界的基石
想象一下,现实世界的数据就像一条奔流不息的河流,时刻都在产生新的信息。DataStream API 就是 Flink 提供给我们的工具箱,里面装满了各种强大的工具,帮助我们捕获、转换和分析这条“数据河流”。
DataStream 编程模型:三段论
一个典型的 Flink DataStream 应用程序可以概括为以下三个核心步骤:
数据源(Source):数据的起点
数据转换(Transformation):数据的加工厂
数据输出(Sink):数据的归宿
可以用一张简单的图来表示这个过程:
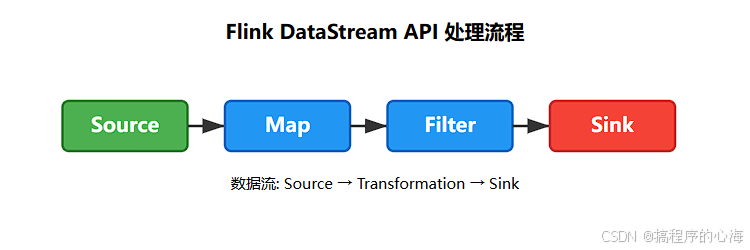
二、 基本编程实践:WordCount 示例
为了让大家更直观地理解 Flink 编程,我们以经典的 WordCount 案例来讲解。下面的示例代码使用 Scala 编写,涵盖了数据源、数据转换、窗口计算以及数据输出的全流程。
2.1 代码示例
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Timeobject WordCount {def main(args: Array[String]): Unit = {// 创建流执行环境val env = StreamExecutionEnvironment.getExecutionEnvironment// 1. 数据源:从本地集合创建数据流(实际项目中可替换为读取文件或 Kafka)val text = env.fromElements("Flink is a streaming engine","Flink supports batch processing","Scala makes Flink programming concise")// 2. 数据转换:拆分单词,转换为 (word, 1) 格式val counts = text.flatMap(_.toLowerCase.split("\\W+")).filter(_.nonEmpty).map(word => (word, 1)).keyBy(_._1).reduce((a, b) => (a._1, a._2 + b._2))// 3. 数据输出:打印到控制台(实际项目中可写入文件、Kafka 或数据库)counts.print()// 执行程序env.execute("Scala Flink WordCount Example")}
}
2.2 代码解析
-
数据源
使用env.fromElements创建一个包含多条文本数据的流。在实际生产中,可以使用env.readTextFile或者 KafkaSource 读取实时数据。 -
数据转换
-
flatMap:将每行文本拆分成单词,并转换为小写。
-
filter:过滤掉空字符串。
-
map:将每个单词映射成 (word, 1) 元组。
-
keyBy:根据单词进行分组。
-
reduce:聚合相同单词的计数。
-
-
数据输出
使用print将计算结果输出到控制台。在实际项目中可以替换成其他 Sink(例如写入 Kafka、数据库或文件)。
三、窗口的划分:在无限流中框定边界
由于流数据是无限的,我们需要将无限的流划分成有限大小的“窗口”,然后在每个窗口上进行计算。Flink 提供了灵活的窗口机制,可以根据时间、数量或其他条件来划分窗口。
无限延伸的蓝色波浪线代表数据流,上面被垂直的虚线分割成若干个矩形区域,每个矩形区域代表一个窗口。每个窗口内部包含若干个数据点。
3.1 时间概念
在定义和计算窗口时,时间是一个至关重要的概念
事件时间(Event Time)
指数据中携带的时间戳,反映数据生成的真实时间。处理时间(Processing Time)
指系统接收到数据时的时间,不受数据本身时间戳影响。摄取时间(Ingestion Time)
数据进入 Flink 系统的时间,一般介于事件时间和处理时间之间。
选择哪种时间语义取决于你的应用场景和对时间准确性的要求。事件时间通常是最准确的,但也可能涉及到处理乱序事件的问题。
3.2 窗口划分
常见的窗口类型有:
滚动窗口(Tumbling Window)
固定长度且互不重叠的窗口,如上面 WordCount 示例中的 5 秒窗口。滑动窗口(Sliding Window)
窗口大小固定,但窗口之间存在重叠部分,可设置窗口滑动步长。会话窗口(Session Window)
根据数据之间的间隔动态划分,当间隔超过设定阈值时视为新窗口。
3.3 窗口计算
在窗口内执行聚合
一旦我们定义了窗口的划分方式和使用的时间语义,就可以在每个窗口内执行各种计算,例如计数、求和、平均值、最大值、最小值等等。
Flink 提供了不同的 Window Assigners(窗口分配器)来定义如何将数据分配到窗口中,常见的有:
-
时间窗口(Time Windows): 基于时间长度划分窗口,例如滚动时间窗口(Tumbling Time Window)、滑动时间窗口(Sliding Time Window)、会话窗口(Session Window)。
-
计数窗口(Count Windows): 基于元素的数量划分窗口,例如滚动计数窗口(Tumbling Count Window)、滑动计数窗口(Sliding Count Window)。
3.4 窗口计算示例
下面是一个使用滑动窗口的示例,统计每个单词在 10 秒窗口内每隔 5 秒统计一次的计数:
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Timeobject SlidingWindowWordCount {def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironmentval text = env.fromElements("Flink streaming window example","Flink supports different time semantics","Scala and Flink make a great combination")val counts = text.flatMap(_.toLowerCase.split("\\W+")).filter(_.nonEmpty).map(word => (word, 1)).keyBy(_._1)// 定义滑动窗口:窗口长度 10 秒,滑动步长 5 秒.timeWindow(Time.seconds(10), Time.seconds(5)).sum(1)counts.print()env.execute("Scala Flink Sliding Window WordCount")}
}
flatMap(_.toLowerCase.split("\\W+")):将每行文本转换为小写,然后按非单词字符(如空格、标点符号)进行拆分,将每个单词作为一个独立的元素输出。filter(_.nonEmpty):过滤掉空字符串。map(word => (word, 1)):将每个单词映射为一个二元组(word, 1),其中word是单词,1表示该单词出现了一次。keyBy(_._1):根据二元组的第一个元素(即单词)进行分组,以便后续对每个单词进行独立的统计。.timeWindow(Time.seconds(10), Time.seconds(5)):定义一个滑动窗口,窗口长度为 10 秒,滑动步长为 5 秒。这意味着每 5 秒会生成一个新的窗口,每个窗口包含最近 10 秒内的数据。.sum(1):对每个窗口内的二元组的第二个元素(即计数)进行求和,得到每个单词在该窗口内的出现次数。
四、总结
恭喜你!通过本篇文章,你已经对 Scala 版 Flink DataStream API 的编程基础有了初步的了解。我们学习了 DataStream API 的核心组成部分:数据源、数据转换和数据输出,并通过 WordCount 示例进行了实践。同时,我们也初步接触了窗口的概念、时间语义和基本的窗口计算。
Flink DataStream API 的功能远不止于此,还有更高级的转换算子、更灵活的窗口操作、状态管理、容错机制等等等待我们去探索。在接下来的文章中,我们将继续深入学习这些更高级的主题,带你逐步成为 Flink 流处理的专家!
希望这篇文章能够帮助你迈出 Flink Scala 编程的第一步。如果你有任何问题或建议,欢迎在评论区留言交流。让我们一起在 Flink 的世界里扬帆起航!
如果这篇文章对你有所启发,期待你的点赞关注!






)