自然语言处理中的一项常见任务是分类任务。该任务的目标是训练模型为输入文本分配一个标签或类别(见图4-1)。文本分类在全球范围内广泛应用于多种场景,包括情感分析、意图检测、实体抽取和语言检测等领域。无论是表示型语言模型(如BERT)还是生成型语言模型(如GPT),它们对分类任务的影响均不可忽视。
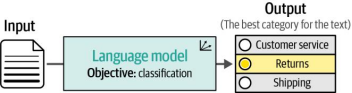
图 4-1. 使用语言模型对文本进行分类。
在本章中,我们将探讨利用语言模型进行文本分类的多种方法。作为使用预训练语言模型的入门指引,我们将呈现这个领域的全景视图。鉴于文本分类的广泛性,我们将通过多种技术方案深入探索语言模型的潜力:
•基于表征模型的文本分类(第113页)。展示非生成式模型在分类任务中的灵活性,涵盖任务专用模型与通用嵌入模型的应用。
•基于生成式模型的文本分类(第127页)。解析如何将生成式语言模型应用于分类任务,对比分析开源与闭源两类语言模型的实践应用。
值得关注的是,本章聚焦于如何善用经过海量数据预训练的语言模型(如图4-2所示)。通过对表征模型和生成式模型的双维度剖析,我们将系统比较这两类核心架构在分类场景中的差异化表现,并深入探讨其技术特性。
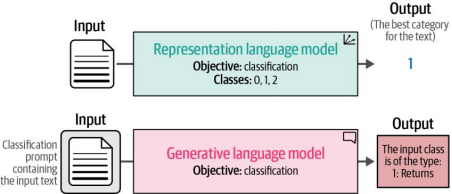
图 4-2 尽管表示模型和生成模型均可用于分类,但它们的方法不同。
本章介绍了各种语言模型,包括生成式和非生成式的。我们将了解用于加载和使用这些模型的常见包。
尽管这本书关注的是大型语言模型(LLM),但强烈建议将这些示例与经典的但强大的基线进行比较,例如使用TF-IDF表示文本并在其上训练逻辑回归分类器
电影评论的情感分析
您可以在Hugging Face Hub(一个不仅用于托管模型还提供数据存储服务的平台)找到我们用于探索文本分类技术的数据。我们将使用广为人知的"烂番茄"数据集来训练和评估我们的模型。1该数据集包含来自烂番茄平台的5,331条正面电影评论和5,331条负面电影评论。
为了加载这些数据,我们将使用本书中始终会用到的datasets软件包
1 Bo Pang and Lillian Lee. “Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales.” arXiv preprint cs/0506075 (2005
from datasets import load_dataset# Load our datadata = load_dataset("rotten_tomatoes")DatasetDict({train: Dataset({features: ['text', 'label'],num_rows: 8530})validation: Dataset({features: ['text', 'label'],num_rows: 1066})test: Dataset({features: ['text', 'label'],num_rows: 1066})})数据被拆分为训练集、测试集和验证集。在本章中,我们将使用训练集来训练模型,并利用测试集验证结果。需要注意的是,如果您已经使用训练集和测试集进行超参数调优,那么额外的验证集可用于进一步验证泛化能力。让我们来看看训练集中的一些示例:
data["train"][0, -1]
{'text': ['the rock is destined to be the 21st century\'s new " conan " and that he\'s going to make a splash even greater than arnold schwarzenegger ,jean-claud van damme or steven segal .','things really get weird , though not particularly scary : the movie is all portent and no content .'], 'label': [1, 0]
这些短评要么被词元为正面(1),要么被词元为负面(0)。这意味着我们将专注于二元情感分类。
基于表征模型的文本分类
使用预训练表示模型进行分类通常分为两种形式:要么使用任务特定模型,要么使用嵌入模型。如前文所述(如图4-3所示),这些模型是通过在特定下游任务上对基础模型(如BERT)进行微调而创建的。
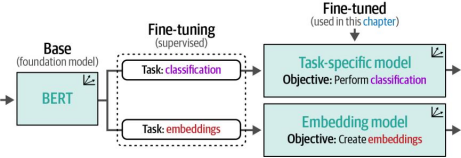
图4-3基础模型会被微调以适应特定任务,例如执行分类或生成通用嵌入。
任务特定模型是一种表示模型(如BERT),专为特定任务(如情感分析)而训练。如第1章所述,嵌入模型会生成通用嵌入,这些嵌入可用于分类以外的多种任务,例如语义搜索(参见第8章)。
第11章介绍了对BERT模型进行分类任务微调的过程,而第10章则讲解了如何创建嵌入模型。在本章中,我们将两种模型均保持冻结状态(不可训练),仅使用其输出,具体如图4-4所示。
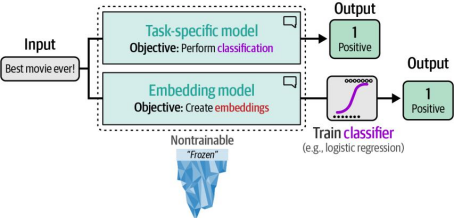
图4-4. 直接通过任务专用模型执行分类,或通过通用嵌入间接进行分类。
我们将利用由他人已经为我们微调过的预训练模型,并探索如何将其应用于对我们选定的电影评论进行分类。
选择合适的模型并非如你想象中那么简单——目前Hugging Face Hub上已有超过6万种文本分类模型,而在本文撰写时生成嵌入的模型更超过8000种。此外,选择适合你用例的模型至关重要,需考虑其语言兼容性、底层架构、体积大小及性能表现。
让我们从底层架构入手。正如第1章所述,BERT作为一种广为人知的编码器-only架构,是创建任务特定模型和嵌入模型的热门选择。虽然像GPT系列这样的生成式模型非常强大,但编码器-only架构同样在特定任务场景中表现出色,且通常体积更为小巧。
多年来,BERT衍生出众多变体,包括RoBERTa²、DistilBERT³、ALBERT⁴和DeBERTa⁵,每种模型均在各种不同语境下训练。图4-5展示了部分知名BERT类模型的概览。
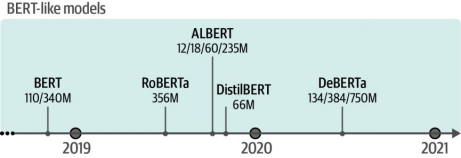
图4-5 常见BERT类模型发布时间线。这些模型被视为基础模型,其主要设计目的是用于在下游任务中进行微调
为工作选择合适的模型本身就是一种艺术形式。尝试那些在拥抱人脸的中心上 可以找到的数千个预训练模型是不可行的,所以我们需要有效地使用我们所选 择的模型
2 Yinhan Liuet et al. “RoBERTa: A robustly optimized BERT pretraining approach.” arXiv preprint
arXiv:1907.11692 (2019).
3 Victor Sanh et al. “DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.” arXiv preprint arXiv:1910.01108 (2019).
4 Zhenzhong Lan et al. “ALBERT: A lite BERT for self-supervised learning of language representations.” arXiv preprint arXiv:1909.11942 (2019).
5 Pengcheng He et al. “DeBERTa: Decoding-enhanced BERT with disentangled attention.” arXiv preprint arXiv:2006.03654 (2020)
不过,以下几个模型都是很好的起点,能让你了解这类模型的基本性能表现。请将它们视为可靠的基准线:
• BERT base model (uncased)
• RoBERTa base model
• DistilBERT base model (uncased)
• DeBERTa base model
• bert-tiny
• ALBERT base v2
针对任务专用模型,我们选择Twitter-RoBERTa-base作为情感分析模型。这是在推文数据上微调过的RoBERTa模型。尽管该模型并非专为影评训练,但探索其泛化能力颇具趣味。
在选择生成嵌入的模型时,MTEB(Meta-Trained Embeddings Benchmark)排行榜是极佳的起点。该榜单汇集了开源和闭源模型在多个任务中的基准测试表现。选择时需注意:不仅要考量模型性能,实际解决方案中推理速度的重要性也不容忽视。因此,本节将全程采用sentence-transformers/all-mpnet-base-v2作为嵌入模型。这是一款小巧但高效的模型,在保证性能的同时具有出色的推理效率。
使用任务特定模型
既然我们已经选定了任务特定的表征模型,现在就开始加载我们的模型吧:
from transformers import pipeline# Path to our HF modelmodel_path = "cardiffnlp/twitter-roberta-base-sentiment-latest"# Load model into pipelinepipe = pipeline(model=model_path,tokenizer=model_path,return_all_scores=True,device="cuda:0")在加载模型的同时,我们也会加载负责将输入文本转换为独立令牌的分词器(如图4-6所示)。虽然该参数无需手动指定(因其会自动加载),但它展示了模型内部机制的具体运作过程。
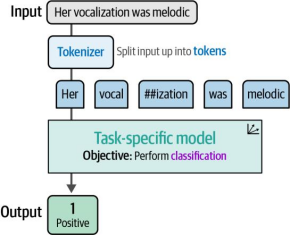
图4-6 输入句子必须先经过分词器处理后,才能被任务特定模型处理。
这些词元是大多数语言模型的核心,正如第2章深入探讨的那样。这些词元的主要优势在于,即使它们从未出现在训练数据中,也可以通过组合生成表征,如图4-7所示。
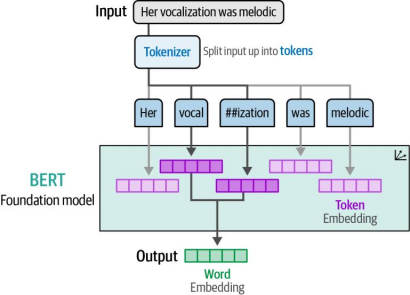
如图4-7 所示,即使将未知单词分解为词元,词嵌入仍可被生成。
在加载完所有必要组件后,我们就可以直接在数据的测试集分割部分应用我们的模型了:
import numpy as npfrom tqdm import tqdmfrom transformers.pipelines.pt_utils import KeyDataset# Run inferencey_pred = []for output in tqdm(pipe(KeyDataset(data["test"], "text")),total=len(data["test"])):negative_score = output[0]["score"]positive_score = output[2]["score"]assignment = np.argmax([negative_score, positive_score])y_pred.append(assignment)现在我们已经生成了预测结果,剩下的工作就是评估了。我们创建了一个简单函数,方便在本章的各个环节中使用:
from sklearn.metrics import classification_reportdef evaluate_performance(y_true, y_pred):"""Create and print the classification report"""performance = classification_report(y_true, y_pred,target_names=["Negative Review", "Positive Review"])print(performance)接下来,让我们创建我们的分类报告:
evaluate_performance(data["test"]["label"], y_pred)精确率 召回率 F1分数 支持度
负面评价 0.76 0.88 0.81 533
正面评价 0.86 0.72 0.78 533
准确性 0.80 1066
宏平均 0.81 0.80 0.80 1066
加权平均 0.81 0.80 0.80 1066
要读取生成的分类报告,让我们首先从探索如何识别正确预测和错误预测开始。根据预测正确(真)与预测错误(假)、以及预测正确类别(正)与错误类别(负)之间存在四种组合关系。我们可以将这些组合以矩阵形式直观呈现,这种矩阵通常被称为混淆矩阵(如图4-8所示)。
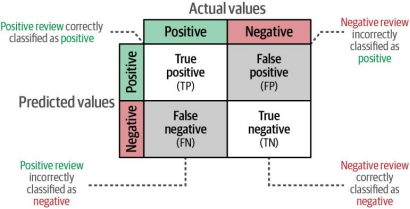
图4-8混淆矩阵描述了我们可以做出的四种预测类型。
利用混淆矩阵,我们可以推导出多个公式来描述模型的质量。在前文生成的分类报告中,我们可以看到四种方法,分别是精确率、召回率、准确率和F1分数:
•精确率衡量了模型找出的结果中有多少是相关的,这反映了相关结果的准确性
•召回率反映了模型找到了多少相关的类别,这体现了它找出所有相关结果的能力
•准确率表示模型在所有预测中做出了多少正确预测,这反映了模型的整体正确性
•F1分数综合了精确率和召回率,从而衡量模型的整体性能。
图4-9展示了这四个指标,并通过上述分类报告对它们进行了说明
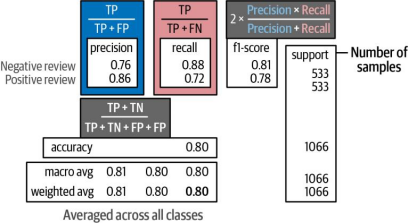
图4-9分类报告阐述了用于评估模型性能的多个指标
为了提升选定模型的性能,我们可以采取多种不同措施,其中包括:
1.选择针对本领域数据(即电影评论)训练的模型,例如DistilBERT-base-uncased-finetuned-SST-2(针对电影评论的微调版本)
2.将关注点转向其他类型的表征模型,特别是嵌入模型(embedding models)
基于嵌入的分类任务
在前面的例子中,我们使用了针对特定任务的预训练模型进行情感分析。但如果找不到针对该任务预训练的模型呢?是否需要我们自行微调表示模型?答案是否定的!
如果你有足够的计算资源(参见第11章),确实可能在某些时候需要自行微调模型。但并非所有人都能获得强大的计算资源,这时通用嵌入模型就派上用场了。
与之前的示例不同,我们可以采用更经典的方法自行执行部分训练过程。此处不再直接使用表征模型进行分类,而是改用嵌入模型生成特征。这些特征随后可输入分类器,从而形成如图4-10所示的两步法。
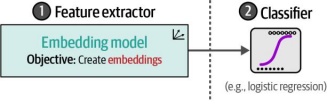
图4-10特征提取步骤与分类步骤相互分离。
这种分离的主要优势在于无需对嵌入模型进行成本高昂的微调。相反,我们可以在CPU上训练逻辑回归等分类器。
第一步中,如图4-11所示,我们使用嵌入模型将文本输入转换为嵌入表示。值得注意的是,该模型同样保持冻结状态,训练过程中不会更新其参数。
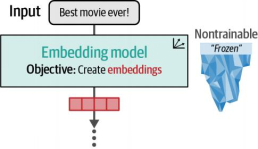
图4-11第一步中,我们使用嵌入模型提取特征并将输入文本转换为嵌入表示
我们可以使用sentence-transformers库来执行这一步,这是一个基于预训练嵌入模型构建的流行工具包6。
创建嵌入的过程非常简单直接:
from sentence_transformers import SentenceTransformer# Load modelmodel = SentenceTransformer("sentence-transformers/all-mpnet-base-v2")# Convert text to embeddingstrain_embeddings = model.encode(data["train"]["text"], show_progress_bar=True) 正如我们在第1章中提到的,这些嵌入是输入文本的数值表示。嵌入的值或维 数取决于底层的嵌入模型。让我们在我们的模型中探索一下:
train_embeddings.shape
(8530, 768)
这表明我们输入的8,530个文档中的每一个都具有768维的嵌入空间,因此每个嵌入向量都包含768个数值特征。
在第二步中,这些嵌入向量将作为图4-12所示分类器的输入特征。该分类器是可训练模型,其形式不限于逻辑回归(logistic regression),只要能够实现分类功能即可采用任意架构。
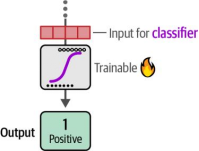
图4-12我们将嵌入作为特征,在训练数据集上训练逻辑回归模型
我们将保持这一步骤简单直接,使用逻辑回归作为分类器。要训练该模型,我们只需将生成的嵌入与对应的标签组合使用即可:
6 Nils Reimers and Iryna Gurevych. “Sentence-BERT: Sentence embeddings using Siamese BERT-networks.” arXiv preprint arXiv:1908.10084 (2019)
from sklearn.linear_model import LogisticRegression# Train a logistic regression on our train embeddingsclf = LogisticRegression(random_state=42)clf.fit(train_embeddings, data["train"]["label"])接下来,让我们评估我们的模型:
# Predict previously unseen instancesy_pred = clf.predict(test_embeddings)evaluate_performance(data["test"]["label"], y_pred)精确率 召回率 F1分数 支持度
负面评价 0.85 0.85 0.85 533
正面评价 0.86 0.85 0.85 533
准确性 0.85 1066
宏平均 0.85 0.85 0.85 1066
加权平均 0.85 0.85 0.85 1066
通过在我们现有的嵌入模型基础上训练分类器,我们成功获得了0.85的F1分数!这证明了在保持底层嵌入模型参数冻结的同时,训练轻量级分类器的可行性
在本例中,我们使用sentence-transformers库进行嵌入抽取,该过程通过GPU加速推理。不过,我们可以通过调用外部API来生成嵌入,从而消除对GPU的依赖。当前主流的嵌入生成方案包括Cohere和OpenAI提供的服务。如此一来,整个流水线便可以完全在CPU上运行。
如果我们没有词元数据怎么办?
在我们之前的示例中,我们利用了已标注数据,但在实际应用中这并非总是可行的。获取标注数据是一项资源密集型任务,可能需要投入大量的人工劳动。此外,收集这些标签是否真的值得?
为了验证这一点,我们可以进行零样本分类——即使没有任何标注数据,也能探索任务是否具备可行性。虽然我们知道标签的定义(即其名称),但并没有标注数据来支撑这些标签。零样本分类试图预测输入文本的标签,即使模型从未接受过这些标签的训练(如图4-13所示)。
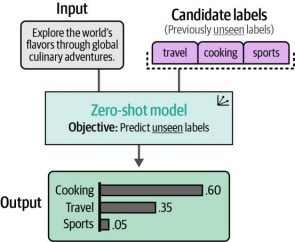
图4-13. 在零样本分类中,我们没有标注数据,只有标签本身。零样本模型决定输入如何与候选标签相关联
若要使用嵌入方法进行零样本分类,我们可以采用一个巧妙的技巧:基于标签应具备的特征进行描述。例如,电影评论的负向标签可被描述为"这是一条负面电影评论"。通过描述并嵌入标签和文档,我们便获得了可以处理的数据。如图4-14所示,这一过程使我们能够在不实际拥有任何标注数据的情况下,自动生成目标标签。
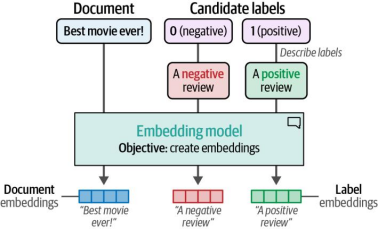
图4-14 为了嵌入标签,我们首先需要为它们提供一个描述(例如"一篇负面电影评论")。然后即可通过sentence-transformers进行嵌入
我们可以使用.encode函数像之前那样创建这些标签嵌入:
# Create embeddings for our labelslabel_embeddings = model.encode(["A negative review", "A positive review"]为文档分配标签时,我们可以采用文档与标签配对之间的余弦相似度方法。这是通过计算向量间夹角的余弦值来实现的,具体公式为:先求取嵌入表示的点积,再除以两个向量模长的乘积(如图4-15所示)。
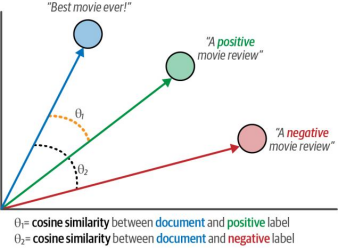
图4-15余弦相似性是两个向量或嵌入之间的夹角。在本例中,我们计算文档与两个可能标签(正面和负面)之间的相似度。
我们可以使用余弦相似度来检查给定文档与候选标签的描述的相似程度。选择 与文档相似性最高的标签,如图4-16所示。
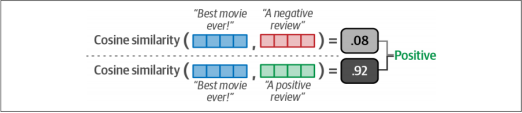
图4-16 在将标签描述和文档嵌入后,我们可以针对每对标签文档使用余弦相似度进行匹配
要进行嵌入的余弦相似度计算,只需将文档嵌入与标签嵌入进行比对,获得最佳匹配对:
from sklearn.metrics.pairwise import cosine_similarity# Find the best matching label for each documentsim_matrix = cosine_similarity(test_embeddings, label_embeddings)y_pred = np.argmax(sim_matrix, axis=1)好了,就是这样!我们只需要为标签想出名称,就能执行分类任务了。我们来看看这种方法效果如何:
evaluate_performance(data["test"]["label"], y_pred)
| 精确度 | 召回率 | f1分数 | 支持度 | |
| 负面评价 | 0.78 | 0.77 | 0.78 | 533 |
| 正面评价 | 0.77 | 0.79 | 0.78 | 533 |
| 精度 | 0.78 | 1066 | ||
| 宏平均 | 0.78 | 0.78 | 0.78 | 1066 |
| 加权平均 | 0.78 | 0.78 | 0.78 | 1066 |
如果你对基于Transformer模型的零样本分类有所了解,可能会好奇为何我们选择用嵌入(embeddings)而非其他方式来说明这一点。虽然自然语言推理模型在零样本分类任务中表现出色,但本示例旨在展示嵌入在多种任务中的独特灵活性。正如本书中反复提到的,嵌入几乎存在于所有语言人工智能的应用场景中,它们虽常被低估,却是实现核心技术突破的关键组件。
考虑到我们完全没有使用任何标签数据,F1分数达到0.78已经非常出色了!这充分展现了嵌入技术的多功能性与实用价值,尤其是在应用过程中稍有创意的话,就能将其转化为强大的工具。
让我们来测试一下这个创意。我们最初确定的标签名称是"A nega‐tive/positive review"(负面/正面评价),但这个名字还有改进空间。我们可以根据数据特性将其具体化为更明确的"A very negative/positive movie review"(非常负面/正面的电影评论)。这样一来,嵌入模型就会捕捉到两个关键信息:首先是这是影评文本,其次能更聚焦于两类极端的情绪表达。尝试一下这种调整,观察会对最终的分类结果产生怎样的影响。
使用生成模型进行文本分类
与我们所做的工作有明显不同,基于生成式语言模型(如OpenAI的GPT模型)的文本分类其工作原理略有差异。这些模型通过接收输入文本并生成对应文本,因此得名"序列到序列模型"(sequence-to-sequence models)。这与图4-17所示的任务特定模型形成鲜明对比——后者输出的不再是生成文本,而是具体的类别标签。
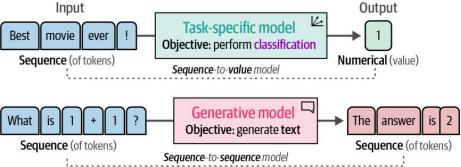
图4-17. 任务特定模型从token序列中生成数值,而生成模型则从token序列中生成token序列
这些生成式模型通常需要经过多种任务的训练,但它们并不能直接适用于您的具体使用场景。例如,如果我们给生成式模型一篇没有任何上下文的电影评论,它根本不知道该如何处理。我们需要帮助模型理解上下文,并引导其朝着我们期望的方向输出答案。如图4-18所示,这一引导过程主要通过您提供的指令或提示(prompt)来实现。通过迭代优化提示词来获得理想输出的过程称为提示工程(prompt engineering)。
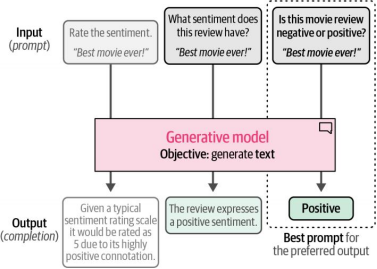
图4-18 提示工程允许对提示词进行更新,以提高模型生成的输出效果
在本节中,我们将演示如何在不使用我们自己的《烂番茄》数据集的情况下,利用不同类型的生成模型进行分类。
使用文本到文本的迁移Transformer
本书中,我们将主要探讨类似BERT的仅编码器(表征型)模型,以及类似ChatGPT的仅解码器(生成型)模型。然而正如第1章所述,原始Transformer架构实际上是由编码器-解码器组成的。与仅解码器模型类似,这些编码器-解码器模型都属于序列到序列模型,通常被归类为生成式模型。
利用这种架构的一个有趣模型家族是文本到文本迁移Transformer,即T5模型。如图4-19所示,其架构与原始Transformer相似,通过堆叠12个解码器和12个编码器构成7。
7 Colin Raffel et al. “Exploring the limits of transfer learning with a unified text-to-text transformer.” The Journal of Machine Learning Research 21.1 (2020): 5485–5551.
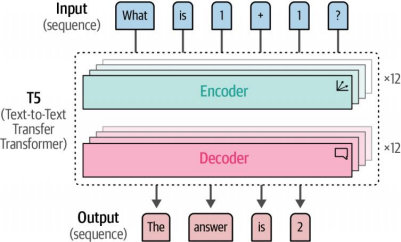
图4-19T5架构与原始Transformer模型相似,均采用编码器-解码器(encoder-decoder)架构
通过这种架构,这些模型首先采用掩码语言建模进行预训练。如图4-20所示,在训练的第一阶段,预训练过程中并非对单个token进行掩码处理,而是对一组或多组token(即token跨度)进行掩码操作。
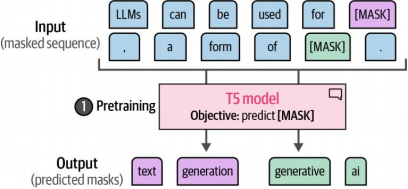
图4-20 在训练的第一步——即预训练阶段,T5模型需要预测可能包含多个词元的掩码。
训练的第二步,即对基础模型进行微调,才是真正魔法发生的地方。与针对某一特定任务进行微调不同,每个任务都会被转换为一个序列到序列(sequence-to-sequence)任务并进行同步训练。如图4-21所示,这种方法使模型能够在各种不同任务上进行训练。
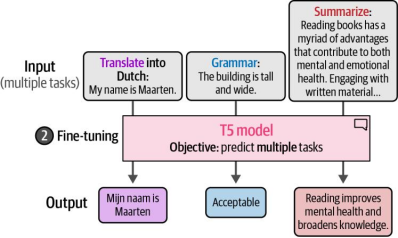
图4-21 通过将特定任务转换为文本指令,T5模型可在微调过程中训练以完成多种任务
该方法在论文《Scaling Instruction-Finetuned Language Models》中得到了扩展,该论文引入了超过一千个在微调阶段更贴近我们所熟知的GPT模型指令形式的任务[8]。这一方法催生了受益于如此多样任务类型的Flan-T5系列模型。若要使用这个预训练的Flan-T5模型进行分类任务,我们需要首先通过"文本到文本生成"(text2text-generation)任务来加载模型——这种任务类型通常专用于此类编码器-解码器架构的模型。
# Load our modelpipe = pipeline("text2text-generation",model="google/flan-t5-small",device="cuda:0")FLAN-T5模型提供多种规格(flan-t5-small/base/large/xl/xxl),我们将使用最小的版本来加快速度。不过您也可以尝试更大的模型,看看是否能获得更好的效果。
与我们的任务专用模型不同,我们不能简单地输入一些文本并指望它能自动输出情感分析结果。相反,我们需要明确地指示模型执行这个任务。
8 Hyung Won Chung et al. “Scaling instruction-finetuned language models.” arXiv preprint arXiv:2210.11416 (2022).
因此,我们在每个文档前添加提示语:"下列句子是积极还是消极?":
# Prepare our dataprompt = "Is the following sentence positive or negative? "data = data.map(lambda example: {"t5": prompt + example['text']})DatasetDict({
train: Dataset({
features: ['text', 'label', 't5'],
num_rows: 8530
})
validation: Dataset({
features: ['text', 'label', 't5'],
num_rows: 1066
})
test: Dataset({
features: ['text', 'label', 't5'],
num_rows: 1066
})
})
在创建更新后的数据后,我们可以按照与特定任务示例类似的方式运行管道:
# Run inferencey_pred = []for output in tqdm(pipe(KeyDataset(data["test"], "t5")),total=len(data["test"])):text = output[0]["generated_text"]y_pred.append(0 if text == "negative" else 1)由于该模型生成的是文本,我们确实需要将文本输出转换为数值形式。输出词"negative"被映射为0,而"positive"则被映射为1。这些数值现在使我们能够以与以往相同的方式测试模型的质量:
evaluate_performance(data["test"]["label"], y_pred)
| 精确度 | 召回率 | f1分数 | 支持度 | |
| 负面评价 | 0.83 | 0.85 | 0.82 | 533 |
| 正面评价 | 0.85 | 0.83 | 0.84 | 533 |
| 精度 | 0.84 | 1066 | ||
| 宏平均 | 0.84 | 0.84 | 0.84 | 1066 |
| 加权平均 | 0.84 | 0.84 | 0.84 | 1066 |
凭借0.84的F1分数,显而易见,这款Flan-T5模型令人惊叹地展现了生成式模型的初步能力。
尽管本书通篇着重探讨开源模型,但语言人工智能领域另一重要的组成部分是闭源模型——尤其是ChatGPT。虽然原始版ChatGPT模型(GPT-3.5)的底层架构并未公开,但从其名称可以推断,该模型基于我们此前在GPT系列中见过的仅解码器架构。幸运的是,OpenAI分享了训练流程的重要环节——偏好调整的概要。如图4-22所示,OpenAI首先为输入提示(指令数据)手动创建了期望的输出,并利用这些数据构建了其首个模型变体。

图4-22 由指令(提示)和输出组成的手动标注数据被用于执行微调(指令调整)
OpenAI利用该模型生成了多个输出结果,并由人工对这些结果从最佳到最差进行了排序。如图4-23所示,这一排序结果表明了对特定输出结果的偏好(偏好数据),并据此打造了最终的ChatGPT模型
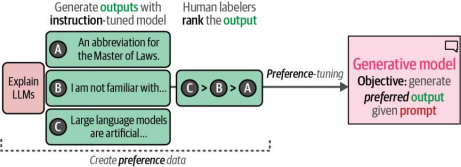
图4-23 通过手动排序的偏好数据被用于生成最终模型——ChatGPT
使用偏好数据而非指令数据的主要优势在于其呈现的细微差别。通过展示好输出与更好输出之间的差异,生成模型学会生成更接近人类偏好的文本。在第12章中,我们将深入探讨微调与偏好微调方法的运作原理,并指导您如何亲自实践这些技术。
使用闭源模型的流程与我们此前见过的开源案例存在显著差异。此时无需加载模型,而是可以通过OpenAI的API访问模型服务。
在进行分类示例之前,您需要先完成以下准备工作:
1.访问 https://oreil.ly/AEXvA 注册免费账户
2.在此页面创建API密钥:https://oreil.ly/lrTXl
完成上述步骤后,您便可通过API密钥与OpenAI服务器进行通信。我们可以用这个密钥创建客户端实例:
import openai# Create clientclient = openai.OpenAI(api_key="YOUR_KEY_HERE")通过使用这个客户端,我们可以创建名为chatgpt_generation的函数,该函数允许我们基于特定的提示、输入文档和选定的模型来生成文本:
def chatgpt_generation(prompt, document, model="gpt-3.5-turbo-0125"):"""Generate an output based on a prompt and an input document."""messages=[{"role": "system","content": "You are a helpful assistant."},{"role": "user","content": prompt.replace("[DOCUMENT]", document)}]chat_completion = client.chat.completions.create(messages=messages,model=model,temperature=0)return chat_completion.choices[0].message.content接下来,我们需要创建一个模板来让模型执行分类任务:
# Define a prompt template as a baseprompt = """Predict whether the following document is a positive or negativemovie review:[DOCUMENT]If it is positive return 1 and if it is negative return 0. Do not give anyother answers."""# Predict the target using GPTdocument = "unpretentious , charming , quirky , original"chatgpt_generation(prompt, document)本模板仅是一个示例,您可以根据需要随意修改。目前,我们将其保持尽可能简单,以说明如何使用此类模板。
在您将其应用于潜在的大型数据集之前,始终记录您的使用情况至关重要。像OpenAI这样的外部API,若进行大量请求,可能会快速产生高额费用。撰写本文时,使用"gpt-3.5-turbo-0125"模型运行我们的测试数据集需3美分,该费用由免费账户覆盖,但未来可能发生变化。
在处理外部API时,你可能会遇到速率限制错误。当调用API过于频繁时,这些错误就会发生——某些API会限制你每分钟或每小时的使用频率。为了防止这类错误,我们可以采用多种重试请求的方法,其中一种被称为指数退避(exponential backoff)。该方法会在每次遇到速率限制错误时执行短暂延迟,然后重试失败的请求。如果再次失败,延迟时间会按指数级增长,直到请求成功或达到最大重试次数。
若要在OpenAI中使用这种方法,官方提供了非常详细的入门指南,能帮助你快速上手实践。
接下来,我们可以对测试数据集中的所有评论进行预测以获得结果。如果您希望保留免费额度用于其他任务,可以选择跳过这一步。
# You can skip this if you want to save your (free) creditspredictions = [chatgpt_generation(prompt, doc) for doc in tqdm(data["test"]["text"])]与上一个示例类似,我们需要将输出从字符串转换为整数,以便评估其性能:
# Extract predictionsy_pred = [int(pred) for pred in predictions]# Evaluate performanceevaluate_performance(data["test"]["label"], y_pred)| 精确度 | 召回率 | f1分数 | 支持度 | |
| 负面评价 | 0.87 | 0.97 | 0.92 | 533 |
| 正面评价 | 0.96 | 0.86 | 0.91 | 533 |
| 精度 | 0.91 | 1066 | ||
| 宏平均 | 0.92 | 0.91 | 0.91 | 1066 |
| 加权平均 | 0.92 | 0.91 | 0.91 | 1066 |
0.91的F1分数已经让我们初步领略了这款将生成式人工智能推向大众的模型的性能。然而,由于我们无从知晓该模型训练所用的数据,这类评估指标并不能被直接用于模型的衡量。根据现有信息,它实际上可能正是用我们的数据集训练的!在第十二章中,我们将深入探讨如何对开源模型和闭源模型进行更普适性的综合评估。
总结
本章我们探讨了多种文本分类任务的不同技术方法,从完整模型的微调到完全不进行调优!表面上看文本分类似乎简单,实则涉及大量创造性的技术手段。
本章我们通过生成式语言模型和表征式语言模型两种途径进行了文本分类实践,目标是为评论情感分析赋予标签。我们重点研究了两类表征模型:任务专用模型(在专门的情感分析大数据集上预训练)展示了预训练模型在文档分类中的优势;嵌入模型则生成了多用途特征表示,作为训练分类器的输入。
在生成式模型方面,我们同样探索了两种类型:开源的编码器-解码器模型Flan-T5,以及闭源的仅解码器模型GPT-3.5。这些生成式模型在文本分类应用中表现出色,无需特定领域数据或标注数据集的额外训练。
下一章我们将继续聚焦分类任务,但转向无监督分类领域。当面对没有标签的文本数据时,我们能开展哪些工作?又能提取何种信息?本章将重点讨论数据聚类分析,以及如何通过主题建模技术为聚类结果命名。通过这种方式,即使在没有标注数据的情况下,我们仍能有效挖掘文本数据中的潜在模式和语义结构。

)


