REPLUG: Retrieval-Augmented Black-Box Language Models
REPLUG: Retrieval-Augmented Black-Box Language Models - ACL Anthology
NAACL-HLT 2024
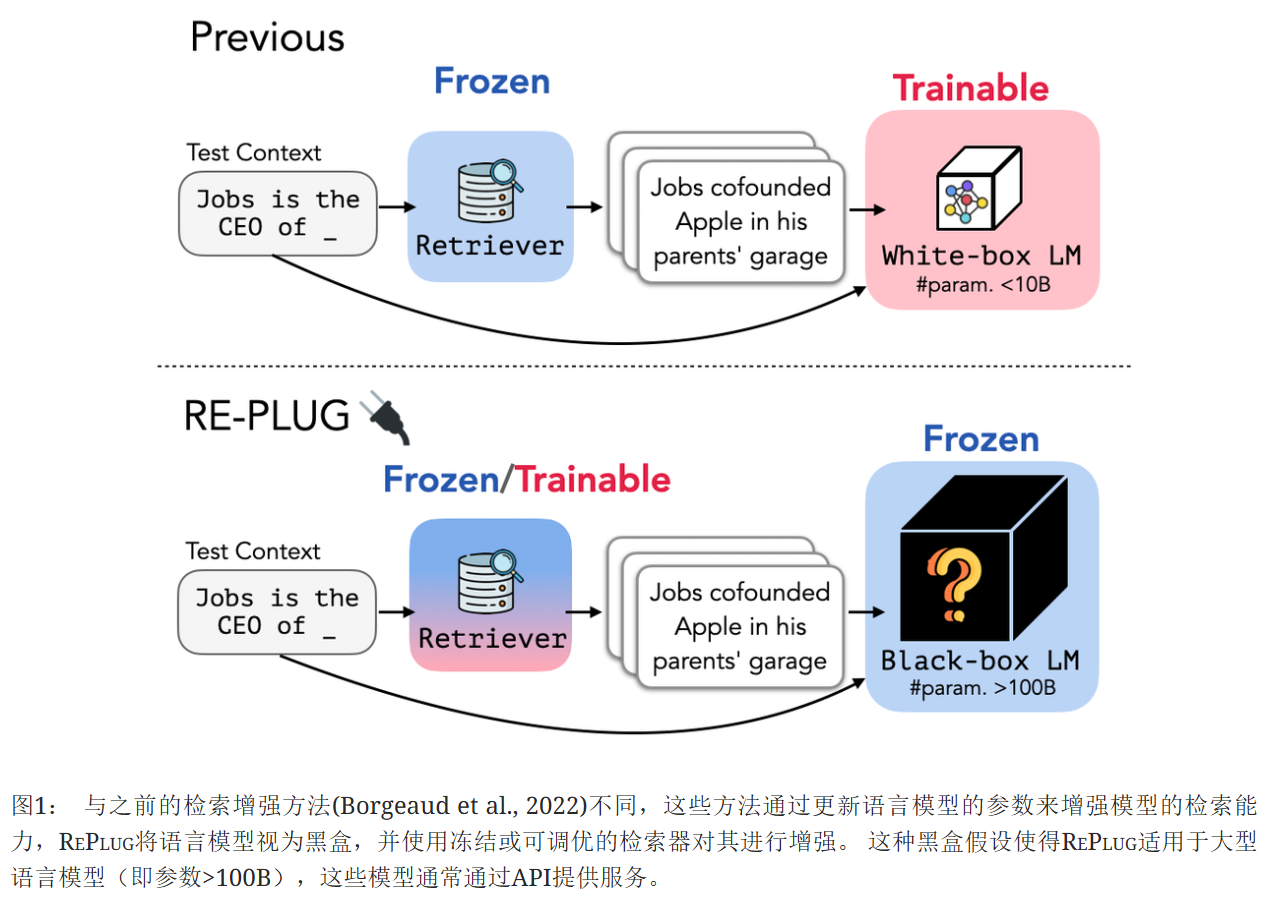 在这项工作中,我们介绍了RePlug(Retrieve and Plug),这是一个新的检索增强型语言模型框架,其中语言模型被视为黑盒,检索组件被添加为一个可调优的即插即用模块。 给定一个输入上下文,RePlug首先使用一个现成的检索模型从外部语料库中检索相关的文档。 检索到的文档被添加到输入上下文的前面,并输入到黑盒语言模型中以进行最终预测。 由于语言模型上下文长度限制了可以添加的文档数量,我们还引入了一种新的集成方案,该方案使用相同的黑盒语言模型并行编码检索到的文档,使我们能够轻松地用计算换取准确性。 如图1所示,RePlug非常灵活,可以与任何现有的黑盒语言模型和检索模型一起使用。
在这项工作中,我们介绍了RePlug(Retrieve and Plug),这是一个新的检索增强型语言模型框架,其中语言模型被视为黑盒,检索组件被添加为一个可调优的即插即用模块。 给定一个输入上下文,RePlug首先使用一个现成的检索模型从外部语料库中检索相关的文档。 检索到的文档被添加到输入上下文的前面,并输入到黑盒语言模型中以进行最终预测。 由于语言模型上下文长度限制了可以添加的文档数量,我们还引入了一种新的集成方案,该方案使用相同的黑盒语言模型并行编码检索到的文档,使我们能够轻松地用计算换取准确性。 如图1所示,RePlug非常灵活,可以与任何现有的黑盒语言模型和检索模型一起使用。
还介绍了RePlug LSR(RePlug with LM-Supervised Retrieval),这是一种训练方案,它可以进一步改进RePlug中的初始检索模型,并利用来自黑盒语言模型的监督信号。 核心思想是使检索器适应语言模型,这与之前的工作(Borgeaud et al., 2022)相反,后者使语言模型适应检索器。 我们使用了一个训练目标,该目标更倾向于检索能够提高语言模型困惑度的文档,同时将语言模型视为一个冻结的黑盒评分函数。
REPLUG
新的检索增强型LLM范式,其中语言模型被视为黑盒,检索组件被添加为一个可能可调优的模块。
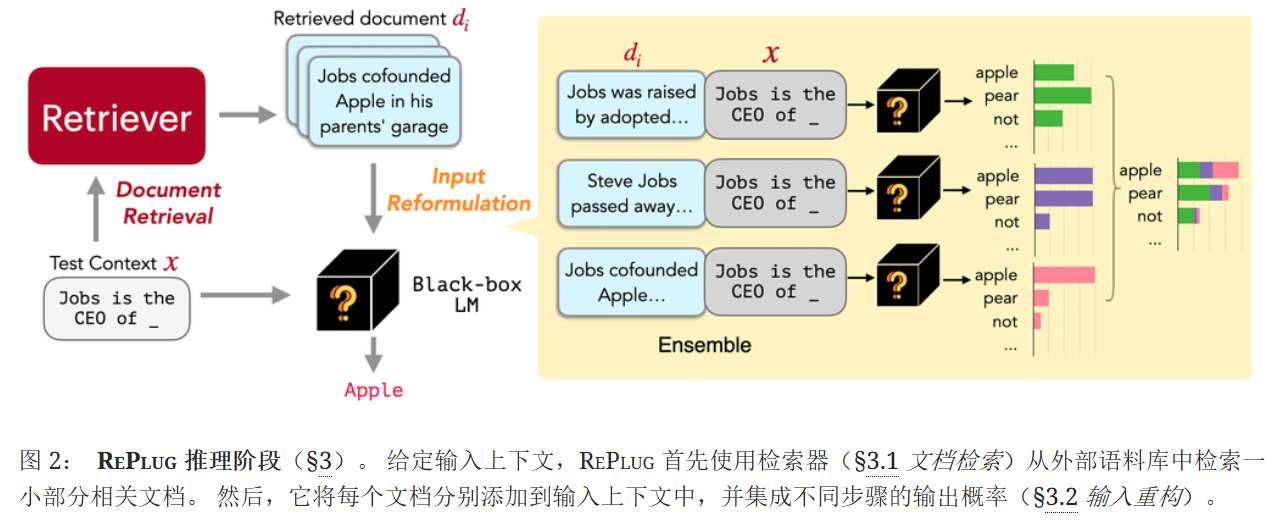
给定一个输入上下文,RePlug首先使用检索器从外部语料库中检索一小组相关文档。 把每个检索到的文档与输入上下文串联起来,通过LLM并行处理,并集成预测概率
文档检索
使用基于双编码器架构的稠密检索器,编码器把输入内容和文档进行编码:对待编码内容的token的最后一个隐藏层表示进行平均池化,实现编码映射
使用余弦相似度计算嵌入的相似度
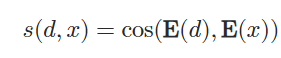
输入重构
考虑到语言模型的上下文窗口大小,将所有top-k文档添加到问题x前面的方案从根本上受到我们能够包含的文档数量(即k)的限制。
为了解决这个限制,我们采用了一种如下所述的集成策略。
假设𝒟′⊂𝒟包含k个与x最相关的文档,将每个文档d∈𝒟′添加到x前面,分别将此连接传递给LM,然后集成所有k次的输出概率。 形式上,给定输入上下文x及其前k个相关文档𝒟′,下一个符元y的输出概率计算为加权平均集成:
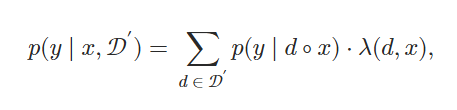
其中∘表示两个序列的连接,权重λ(d,x)基于文档d和输入上下文x之间的相似度得分:
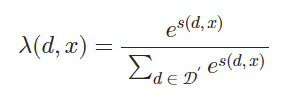
虽然这种集成方法需要运行LLM的生成总共k次,但是在每个检索到的文档和输入上下文之间执行交叉注意力,因此相对把所有的k个内容添加到x前面来说,并不会产生额外的计算成本开销
REPLUG LSR:稠密检索器训练
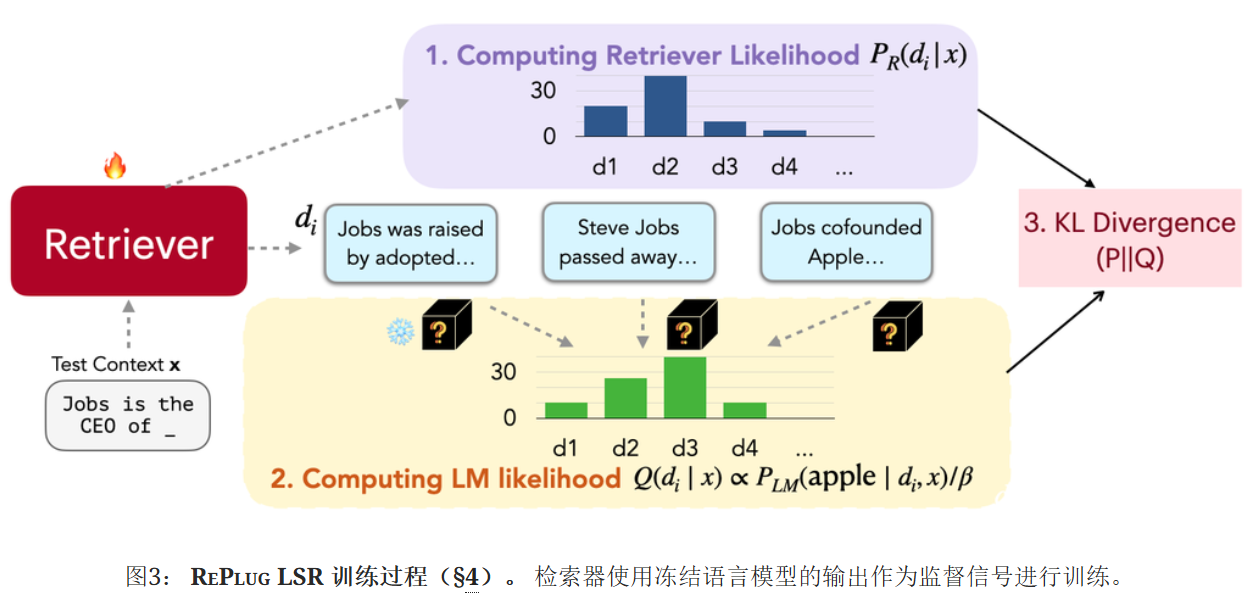
进一步提出了RePlug LSR(使用LM监督检索的RePlug),它调整了RePlug中的检索器,利用LM本身来提供关于应该检索哪些文档的监督。
可以看作是调整检索文档的概率,以匹配语言模型输出序列困惑度的概率。
也就是说希望检索器找到导致困惑度得分更低的文档
检索器的训练包括四个步骤:
检索文档并计算检索似然;通过语言模型对检索到的文档进行评分;通过最小化检索似然和LM的评分分布之间的KL三度来更新检索模型参数;异步更新数据存储索引。
1.计算检索似然
从给定输入上下文x的语料库𝒟中检索k相似度得分最高的文档𝒟′⊂𝒟。 然后计算每个检索到的文档d的检索似然:
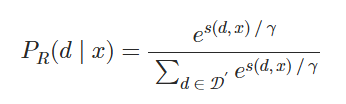
γ是一个控制softmax温度的超参数。 理想情况下,检索似然是通过对语料库𝒟中的所有文档进行边缘化计算的,但在实践中这是不可行的。 因此,我们通过仅对检索到的文档𝒟′进行边缘化来近似检索似然。
2.计算语言模型似然
使用LM作为评分函数来衡量每个文档在多大程度上可以改善LM的困惑度。 具体来说,我们首先计算P_LM(y∣d,x),即给定输入上下文x和文档d时,真实实况输出y的LM概率。概率越高,文档di在改善LM的困惑度方面就越好。 然后,我们计算每个文档d的语言模型似然值,如下所示:
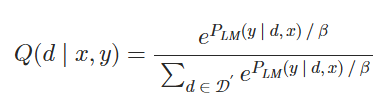
其中β是另一个超参数。
3.损失函数
给定输入上下文x和相应的真实续写y,计算检索似然值和语言模型似然值。 密集检索器通过最小化这两个分布之间的KL散度进行训练:
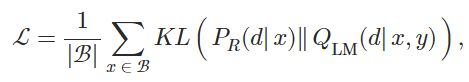
ℬ是一组输入上下文。 在最小化损失时只能更新检索模型参数
4.数据存储索引的异步更新
因为检索器中的参数在训练过程中被更新,之前计算的文档嵌入不再是最新的。每T个训练步骤重新计算文档嵌入并使用新的嵌入重建高效的搜索索引。 然后我们使用新的文档嵌入和索引进行检索,并重复训练过程。
训练设置
使用Contriever作为RePlug的检索器
对RePlug LSR,还是使用Contriever检索器,使用GPT3作为监督语言模型来计算语言模型似然
训练数据:
使用从Pile训练数据(Gao等人,2020)中采样的80万个,每个包含256个符元的序列作为我们的训练查询。 每个查询被分成两部分:前128个符元用作输入上下文x,后128个符元用作真实延续y。 对于外部语料库D,我们从Pile训练数据中采样了3600万个,每个包含128个符元的文档。 为避免简单的检索,我们确保外部语料库文档与从中采样训练查询的文档不重叠。
训练细节
预先计算外部语料库D的文档嵌入,并创建一个FAISS索引以进行快速相似性搜索。
给定一个查询x,从FAISS索引中检索前20个文档,并使用0.1的温度计算检索似然和语言模型似然。
使用Adam优化器训练检索器,学习率为2e-5,批量大小为64,预热比例为0.1。每3000步重新计算一次文档嵌入,并对检索器进行总共25000步的微调。
实验
对语言建模和下游任务(MMLU,开放域问答)进行了评估
1.语言建模
数据集:Pile数据集(Gao et al., 2020)是一个语言建模基准,包含来自网页、代码和学术论文等不同领域的文本资源。 遵循先前的工作,我们报告每个子集域的每UTF-8编码字节比特数(BPB)作为指标。
基线:将GPT-3和GPT-2系列语言模型作为基线。 来自GPT-3的四个模型(Davinci、Curie、Baddage和Ada)是只能通过API访问的黑盒模型。
在基线上添加了RePlug和RePlug LSR。 我们随机下采样Pile训练数据(128个符元的3.67亿个文档),并将它们用作所有模型的检索语料库。 由于Pile数据集已努力对训练集、验证集和测试集中的文档进行去重(Gao et al., 2020),因此我们没有进行额外的过滤。 对于RePlug和RePlug LSR,我们使用长度为128符元的上下文进行检索,并采用集成方法在推理过程中整合前10个检索到的文档。
结果:
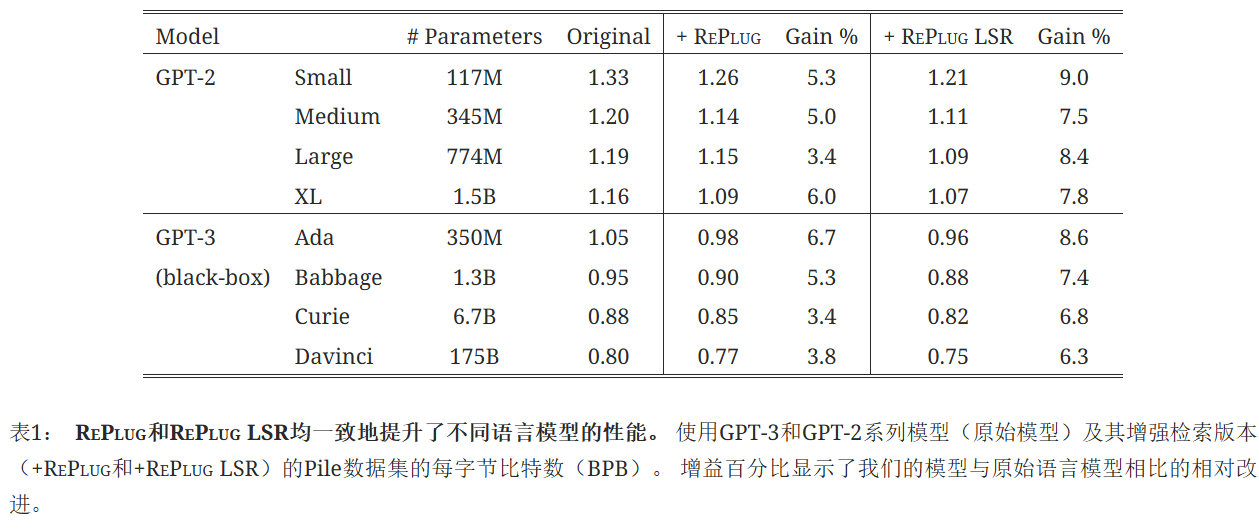
RePlug和RePlug LSR都显著优于基线。 这表明,仅仅向冻结的语言模型(即黑盒设置)添加检索模块就能有效提高不同大小的语言模型在语言建模任务上的性能。 此外,RePlug LSR始终比RePlug有较大优势。 具体来说,RePlug LSR在8个模型上的平均结果比基线提高了7.7%,而RePlug提高了4.7%。 这表明进一步使检索器适应目标语言模型是有益的。
2.MMLU
数据集:MMLU一个多项选择问答数据集,涵盖了来自57个任务的考试题,包括数学、计算机科学、法律、美国历史等。 这57个任务被分为4个类别:人文科学、STEM、社会科学和其他。 遵循 Chung等人 (2022a) 的方法,我们在5-shot上下文学习环境中评估 RePlug。
基线:第一组基线是包括Codex、PaLM和 Flan-PaLM在内的最先进的大语言模型 (LLM)。(这三个模型在MMLU排行榜上位列前三。)第二组基线由检索增强型语言模型组成。只包含Atlas因为没有其他检索增强型LLM在MMLU数据集上进行过评估。 Atlas同时训练检索器和语言模型,我们认为这是一个白盒检索LM设置。
只将RePlug和RePlug LSR添加到Codex,因为其他模型如PaLM和Flan-PaLM不对公众开放。 我们使用测试问题作为查询,从维基百科(2018年12月)中检索10个相关的文档,并将每个检索到的文档添加到测试问题前面,从而产生10个单独的输入。 然后将这些输入分别馈送到语言模型中,并将输出概率进行集成。
结果:
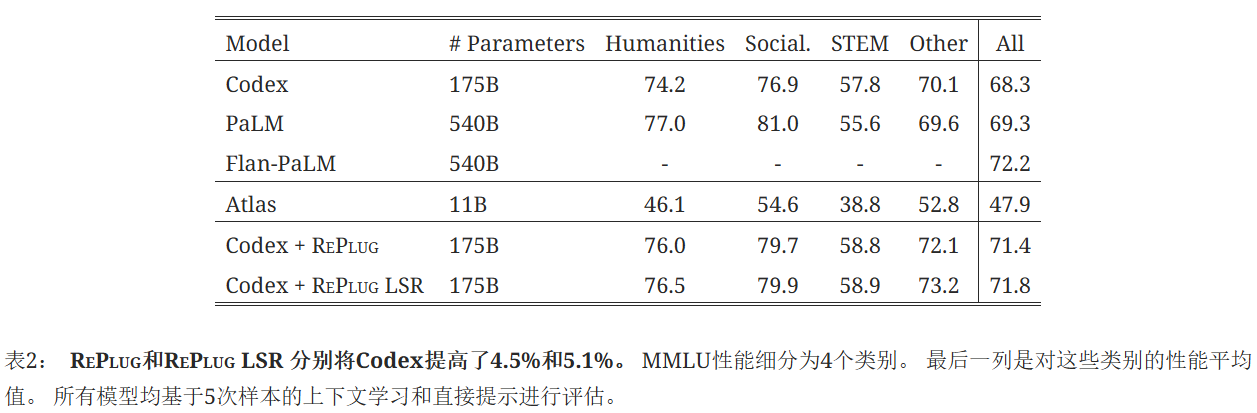
RePlug 和 RePlug LSR 分别将原始 Codex 模型的性能提高了 4.5% 和 5.1%。 此外,RePlug LSR 大大优于之前的基于检索的语言模型 Atlas,证明了我们提出的黑盒检索语言模型设置的有效性。 尽管我们的模型略微逊于 Flan-PaLM,但这仍然是一个不错的结果,因为 Flan-PaLM 的参数数量是它的三倍。 我们预计,如果我们能够访问该模型,RePlug LSR 可以进一步改进 Flan-PaLM。即使在 STEM 类别中,RePlug LSR 也比原始模型高出 1.9%。 这表明检索可以提高语言模型的解决问题的能力。
3.开放域问答
数据集:NQ和TriviaQA是两个开放域问答数据集,包含从维基百科和网络收集的问题和答案。考虑了少样本设置,其中模型只提供几个训练示例;以及全数据设置,其中模型提供所有训练示例。
基线:第一组模型由强大的大型语言模型组成,包括Chinchilla、PaLM和Codex。 所有这些模型都在少样本设置下使用上下文学习进行评估,其中Chinchilla和PaLM使用64个样本进行评估,Codex使用16个样本进行评估。第二组用于比较的模型包括检索增强型语言模型,例如RETRO、R2-D2和Atlas。所有这些检索增强型模型都在训练数据上进行了微调,无论是在少样本设置下还是使用全训练数据。 具体来说,Atlas在少样本设置下使用64个示例进行了微调。
在Codex中添加了RePlug和RePlug LSR,并使用维基百科(2018年12月)作为检索语料库,以在16样本的上下文学习中评估模型。 与语言建模和MMLU中的设置类似,我们使用我们提出的集成方法结合前10个检索到的文档。
结果:
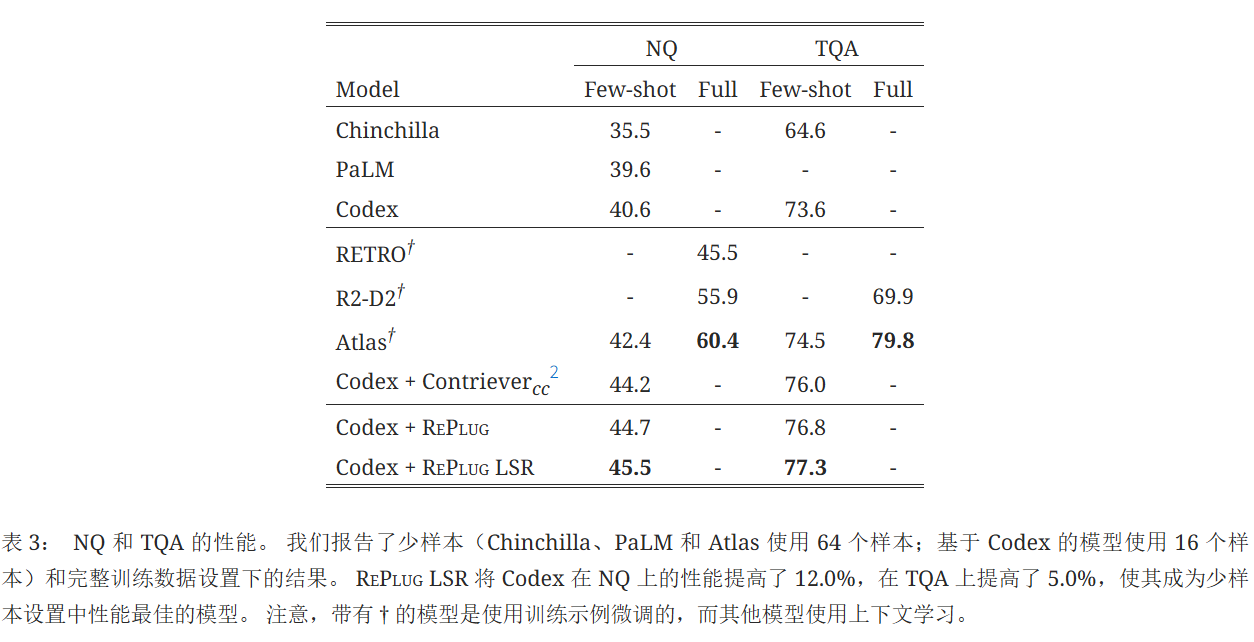
RePlug LSR在NQ上将原始Codex的性能显著提高了12.0%,在TQA上提高了5.0%。 它优于之前的最佳模型Atlas(使用64个训练示例进行了微调),在少样本设置下达到了新的最先进水平。 但是,这个结果仍然落后于在完整训练数据上微调的检索增强型语言模型的性能。 这可能是由于训练集中存在近似重复的测试问题(例如,Lewis等人 (2021) 发现NQ中32.5%的测试问题与训练集重叠)。





