Hive之扩展函数(UDF)
1、概念讲解
当所提供的函数无法解决遇到的问题时,我们通常会进行自定义函数,即:扩展函数。Hive的扩展函数可分为三种:UDF,UDTF,UDAF。
UDF:一进一出
UDTF:一进多出
UDAF:多进一出
2、UDF的基本实现
业务功能介绍
此处创建的UDF业务功能介绍:给定三个参数,参数一和参数二为日期,参数三为不同维度(年,季度,月,周,日)。根据不同维度计算两日期之间相差的值。
一:依赖
<dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>3.1.2</version>
</dependency>
二:接口的定义
UDF基本接口定义
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;import java.util.Objects;//校验:若无法匹配,则抛异常
public interface UDFCom {//校验传参的数量与元素default void validateArgs(Object[] args,int size) throws UDFArgumentException {//校验 数量 是否为空if (size>0 && Objects.isNull(args) || args.length<size){throw new UDFArgumentException(size+"args must be provided");}//size 之内的元素进行验证for (int i=0 ;i < size ; i++){if (Objects.isNull(args[i])){throw new UDFArgumentException("type of args["+i+"] null");}}}//校验所有类型为基本类型default void validateAllPrimitiveArgs(Object[] args,int size) throws UDFArgumentException{for (int i = 0; i < size; i++) {// ObjectInspector: 解析并获取内部数据结构信息的工具// getCategory():提取类型// PRIMITIVE:基本类型if (((ObjectInspector)args[i]).getCategory() != ObjectInspector.Category.PRIMITIVE){throw new UDFArgumentException("only support primitive type");}}}
}
日期接口定义(业务需求)
import org.apache.hadoop.hive.ql.metadata.HiveException;//校验:若无法匹配,则抛异常
public interface DateCom {//日期的格式验证default void validateDateFormat(String...dateStrArr) throws HiveException {for (String s : dateStrArr) {if (!s.matches("\\d{4}-(0?[1-9]|1[0-2])-(0?[1-9]|[1-2][0-9]|3[0-1])")){throw new HiveException("date format illegal : " + s);}}}
}
三:方法的实现
package com.ybg.hive.ql.func.udf;import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Calendar;
import java.util.Objects;public class UDFDataDiffByUnit extends GenericUDF implements UDFCom, DateCom {//管理参数的【类型】 => 验证@Overridepublic ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {//验证validateArgs(arguments,2);// 验证参数数量及元素validateAllPrimitiveArgs(arguments,2);// 验证类型是否为基本类型return PrimitiveObjectInspectorFactory.javaStringObjectInspector;// 传进来参数为字符串}//管理参数的【值】 => 验证 + 业务@Overridepublic Object evaluate(DeferredObject[] arguments) throws HiveException {/*** 验证*/validateArgs(arguments,2);//验证数量/*** 业务功能*/String strDateSmall = arguments[0].get().toString();//获取【参数一】的日期String strDateBig = arguments[1].get().toString();//获取【参数二】的日期//日期格式的验证validateDateFormat(strDateSmall,strDateBig);//比较日期大小:规定 前面日期 < 后面日期SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");Calendar dateSmall = Calendar.getInstance();Calendar dateBig = Calendar.getInstance();try {dateSmall.setTime(sdf.parse(strDateSmall));dateBig.setTime(sdf.parse(strDateBig));} catch (ParseException e) {throw new HiveException(e);}if (dateSmall.after(dateBig)){throw new HiveException("dateSmall by arg1 > dateBig by arg2");}//根据不同情况进行计算String unit = arguments[2].get().toString().toLowerCase();int intUnit = 0;switch (unit){case "y":// 2019-10-15 2020-8-15intUnit = Calendar.YEAR;break;case "q": case "m":intUnit = Calendar.MONTH;break;case "w": case "d":intUnit = Calendar.DATE;break;default:throw new HiveException("not support unit by arg3 : " + unit);}int diff = -1;while (true){diff++;dateSmall.add(intUnit,1);if (dateSmall.after(dateBig)) {//结束的标志break;}}switch (unit){case "q":diff/=3;break;case "w":diff/=7;break;}return diff;}@Overridepublic String getDisplayString(String[] children) {return Objects.isNull(children) || children.length==0 || null == children[0] ? null : children[0];}
}
四:打jar包上传至HDFS
第一步:打执行jar包,选择选择 package 选项。
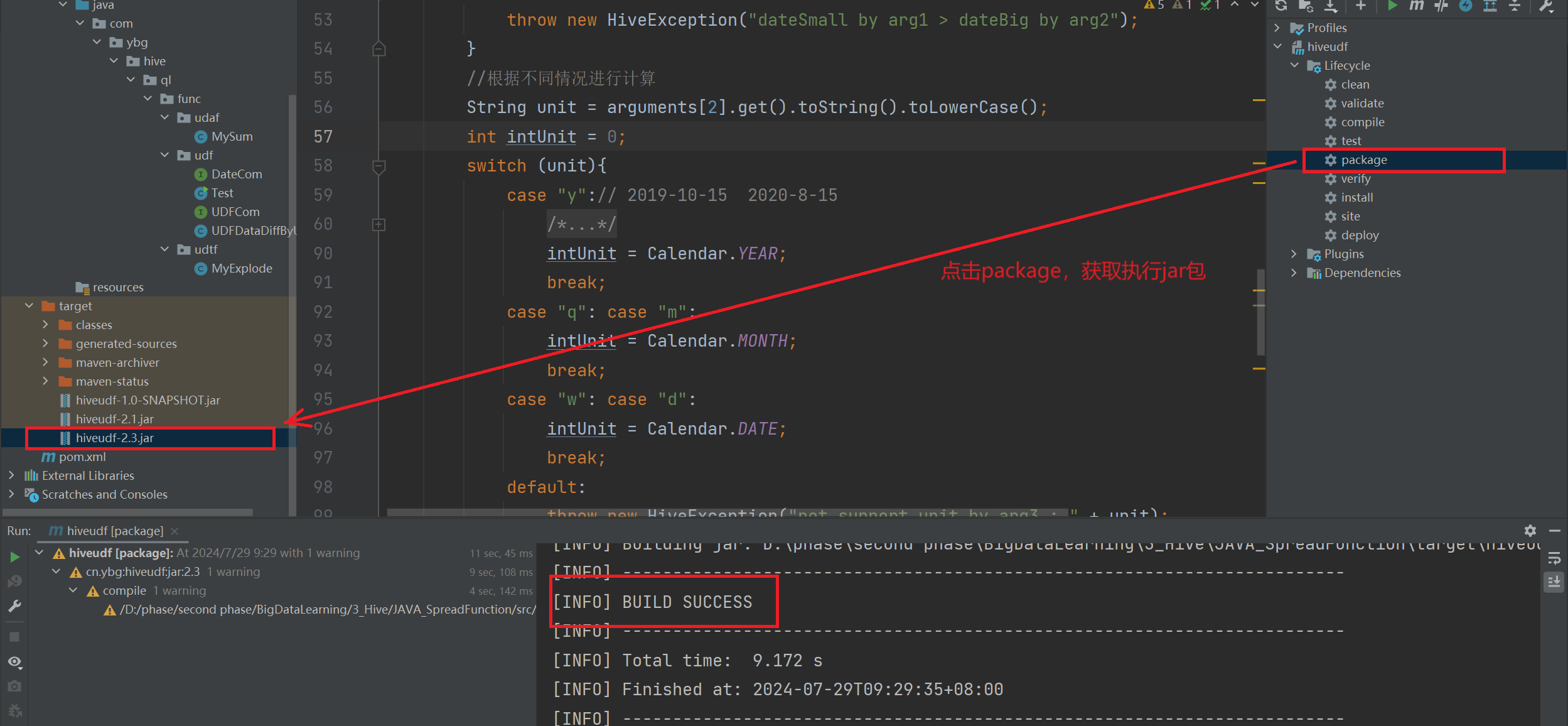
第二步:找到jar包的物理磁盘位置(右键点击jar包 => Open in => Explorer)
第三步:将jar包上传至HDFS
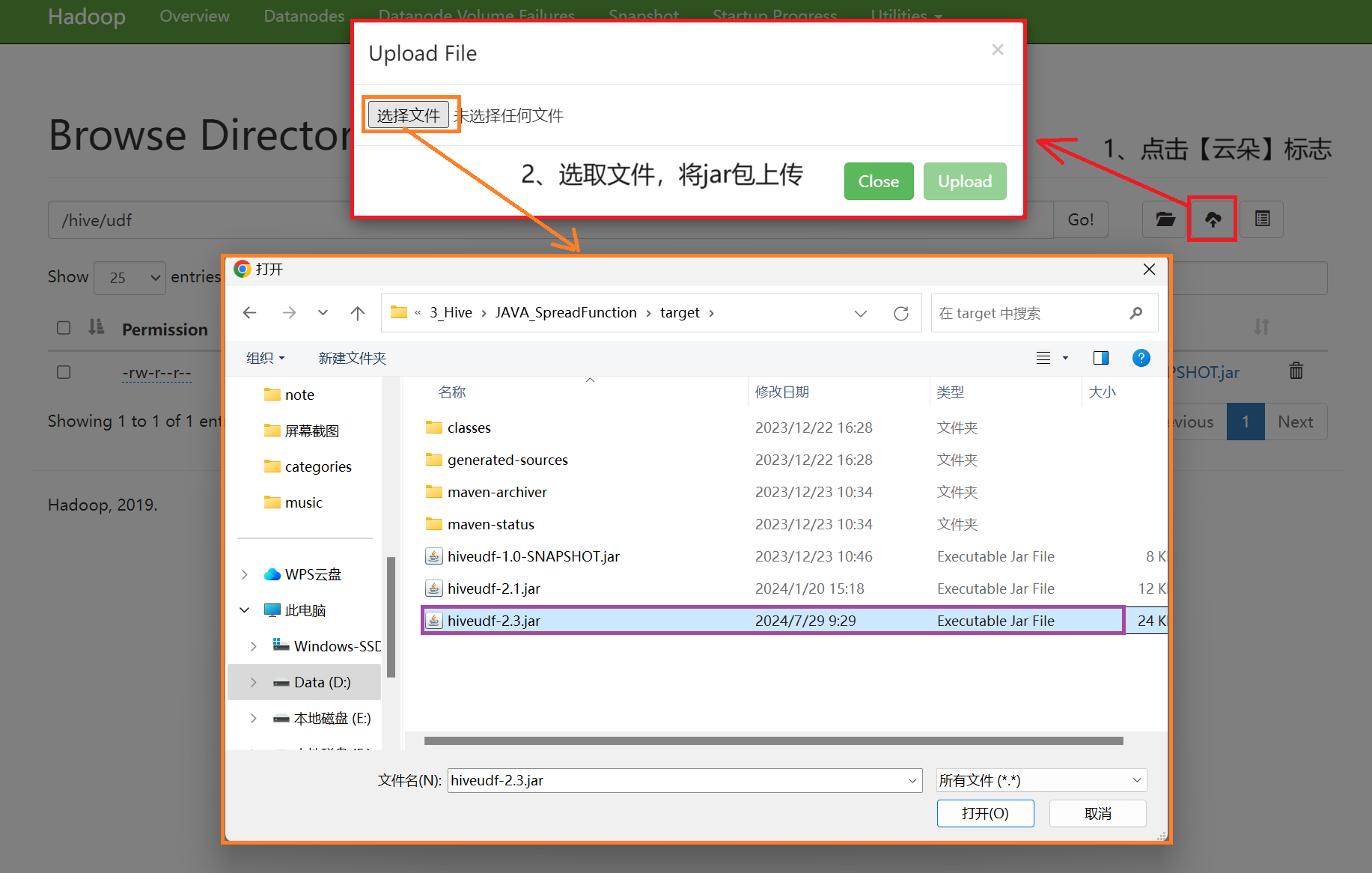
五:创建 hive udf 映射至hdfs jar包并指定主类
基本语法:
全包路径:右键 => copy path => copy reference
create function fl_day as '继承了GenericUDF的全包路径'
using jar 'hdfs上的jar包的路径';
实际运用:
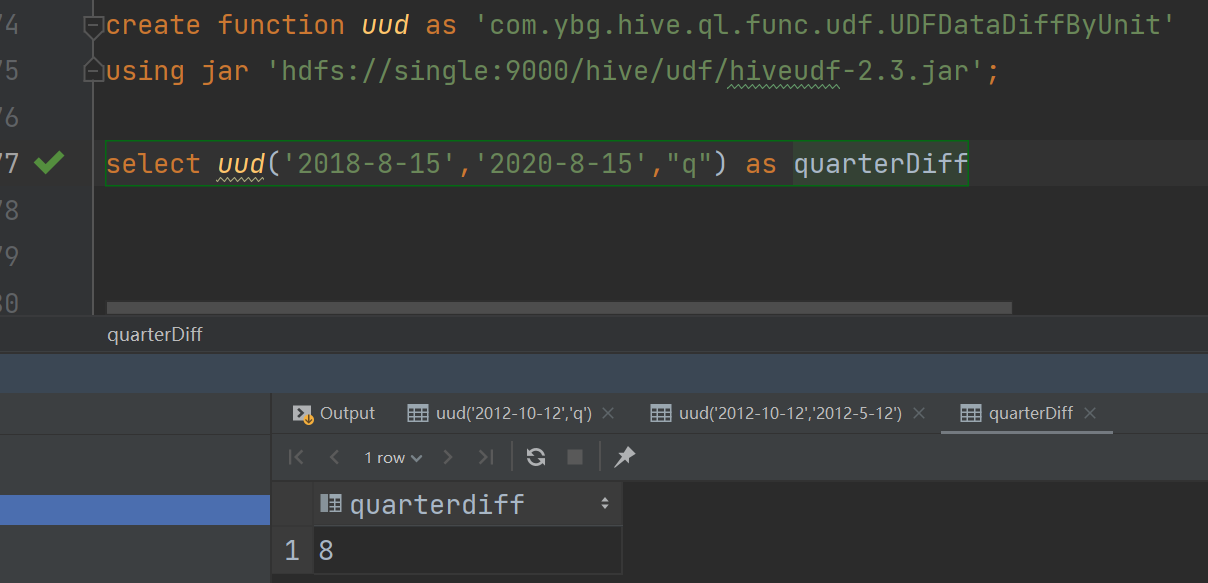
-- 创建连接
create function uud as 'com.ybg.hive.ql.func.udf.UDFDataDiffByUnit'
using jar 'hdfs://single:9000/hive/udf/hiveudf-2.3.jar';
-- 测试
select uud('2018-8-15','2020-8-15',"q") as quarterDiff
六:后期更新函数
第一步:先删函数drop function if exists 函数名;
第二步:关闭连接File -> Close Project
第三步:重新注入create function uud as 'com.ybg.hive.ql.func.udf.UDFDataDiffByUnit'using jar 'hdfs://single:9000/hive/udf/hiveudf-1.0-SNAPSHOT.jar';






)