目录
前言
一、循环单链表
1. 什么是循环单链表?
2. 基本操作实现
头节点初始化:
循环单链表头插与尾插
头删与尾删
二、带头循环双链表
1. 什么是带头循环双链表?
2. 基本操作实现
初始化哨兵头节点
循环双链表头插与尾插
头删与尾删
三、循环链表的优势与应用
1. 优势
2. 典型应用
结语
前言
作为数据结构中的重要内容,链表是每个程序员必须掌握的基础知识,上节课(详见不循环单链表专题)我们讲了带头单链表的模拟实现,今天我就为大家带来循环带头单链表与循环带头双链表的简单讲解,这几者之间差异不大,本质上就是寻找到你即将进行操作的节点,随后进行插入操作或者删除操作。希望能够对大家有所帮助。
一、循环单链表
1. 什么是循环单链表?
循环单链表是单链表的一种特殊形式,它的最后一个节点的指针不是NULL,而是指向头节点,形成一个环。
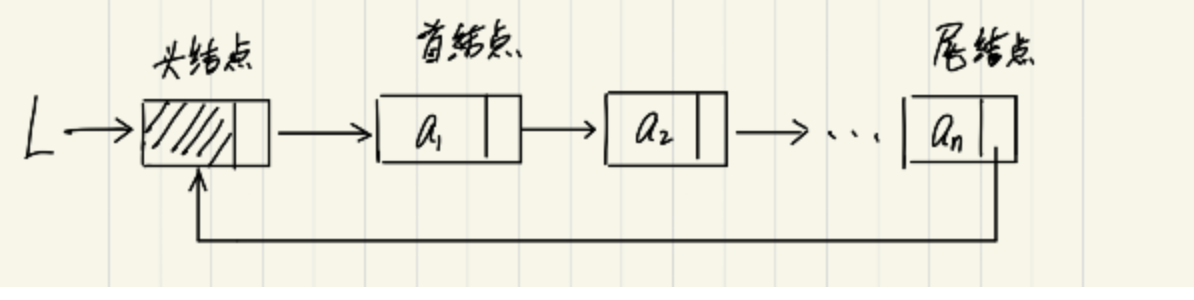
每个节点结构仍然由一个数据域与一个指向下一个节点的指针域构成:
typedef struct LNode
{int data;struct LNode* next;
}LNode,*LinkList;2. 基本操作实现
头节点初始化:
我们在上篇文章中介绍了带头不循环单链表的实现,实际上,带头循环单链表的组成代码与其相似,首先就是创建一个头节点,返回他的头指针:
LinkList ListInit()//构造头节点
{LinkList ret = new LNode;ret->next = ret;//由于要循环,所以从头指针开始就需要指向自己代表循环return ret;
}由于之前是不循环的单链表,所以在头节点初始化时我们让它的next指针指向空,但现在是循环单链表,那么我们就需要让头节点的next指针指向自己。(这样我们从头节点开始一直访问next才会不停的循环下去。
循环单链表头插与尾插
循环单链表的头插其实是与不循环单链表相同,所以代码我就直接写下来了:
void Push_front(LinkList& phead,int num)//头插
{LinkList newnode = new LNode;newnode->data = num;//存储想插入的num值//进行插入操作LinkList pnext = phead->next;newnode->next = pnext;phead->next = newnode;
}我们知道一开始的头节点的next指针仍然是自己,所以对只含头节点的链表进行一次头插,此时pnext就等于phead,因此插入操作最后的结果就是newnode->next指向的是phead,phead->next指向的是newnode。
尾插的代码其实唯一不同的就是要注意保持整条链表的循环性,维护这个链表的尾节点不断指向头节点的部分,与单链表一样,我们依旧需要去寻找最后的尾节点,但是此时尾节点的next可不再指向NULL了,而是指向phead,所以我们判断尾节点的条件也应该更新为while(pcur->next!=phead)。
void Push_pop(LinkList& phead, int num)
{LinkList newnode = new LNode;newnode->data = num;//存储想插入的num值//寻找尾节点LinkList ptail = phead;while (ptail->next != phead){ptail = ptail->next;}//找到尾节点了。//进行插入操作LinkList pnext = ptail->next;//ptail此时的next指针仍然指向pheadnewnode->next = pnext;ptail->next = newnode;
}头删与尾删
循环不循环的单链表其实影响部分只有尾部,关于头插和头删的思维其实并没有变化,只是我们在删除时进行了判断链表是否为空的操作,由于判断仍然使用的phead->next,所以这里需要改变一下,代码如下:
头删:
int Delete_front(LinkList& phead)
{LinkList pcur = phead->next;//pcur代表我们要删除的节点if (pcur == phead)//此时链表中只有一个头节点{return 0;//删除失败}//将被删除指针从链表中分离LinkList pnext = pcur->next;phead->next = pnext;//释放内存,指针置空delete pcur;pcur = NULL;//我们delete的内存,这个pcur指针还是存在的,仍然指向之前的位置。但由于那个位置已经被我们delete释放掉了//所以如果后续不再使用pcur,一定要将pcur置为空,避免产生野指针return 1;//代表删除成功
}对于尾删,循环单链表最重要的也是寻找到尾节点,之后将上一个节点的next指向phead成为新的尾节点。
int Delete_pop(LinkList& phead)
{LinkList pcur = phead->next, prew = phead;//pcur需要指向我们要删除的节点,prew我们让它永远在pcur的上一个节点处,方便用来删除尾节点if (pcur == phead)//空链表{return 0;//删除失败}//寻找被删除的节点,当pcur->next为phead,就代表为尾节点while (pcur->next!=phead)//新的判断尾节点的条件{pcur = pcur->next;//寻找尾节点prew = prew->next;//同时也需要更新prew,使其永远指向尾节点的上一个节点。}//将被删除指针从链表中分离//此时是循环单链表,步骤不能进行省略LinkList pnext = pcur->next;//实质上就是让pnext等于pheadprew->next = pnext;//释放内存,指针置空delete pcur;pcur = NULL;//我们delete的内存,这个pcur指针还是存在的,仍然指向之前的位置。但由于那个位置已经被我们delete释放掉了//所以如果后续不再使用pcur,一定要将pcur置为空,避免产生野指针return 1;//代表删除成功
}大家可以从这些基础操作看到,实际上,循环单链表相比于不循环单链表,只改变了判断尾指针的逻辑,我们不循环单链表的尾指针的next是一直保持为空的,但是如果我们把这个空想象成phead头节点,自然就变为循环链表了。
关于循环单链表有一个非常著名的约瑟夫环的问题,其本质上就是对循环单链表的不断便利与删除,直至删除到只剩下一个数据节点。
二、带头循环双链表
1. 什么是带头循环双链表?
对于一个双链表,我们有以下结构来组成:
typedef struct LNode
{int data;//存储数据struct LNode* next;//指向下一个节点struct LNode* prev;//指向上一个节点
}LNode, * LinkList;
1个数据域用来存储数据,2个结构体指针prev与next,prev来指向上一个节点位置,next指向下一个节点的位置。
用我们火车的例子来解释,就是一个车厢内不止有一把前往下一个车厢的钥匙了,还有前往上一个车厢的钥匙。对于一个循环单链表来说,我们如果想找一个节点的上一个节点,只能强行把这个链表遍历一遍,但如果是循环双链表,我们就可以直接通过访问prev指针来更加快捷的访问上一个节点。
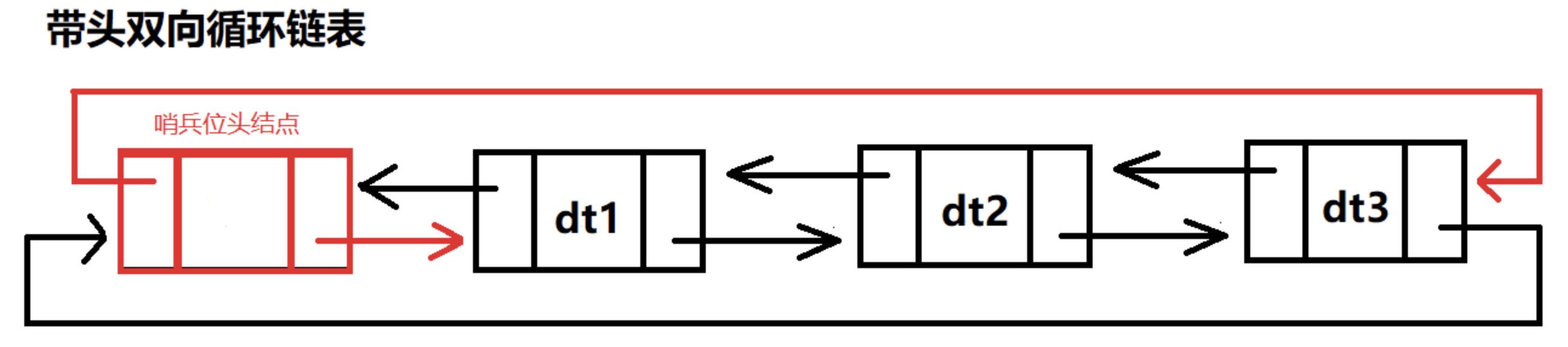
对于带头循环双链表,头节点的作用也是充当一个哨兵,供我们快速找到尾节点与首节点(第一个元素节点)
2. 基本操作实现
初始化哨兵头节点
LinkList ListInit()//构造头节点
{LinkList ret = new LNode;ret->next = ret;ret->prev = ret;return ret;
}类比循环单链表,对于循环双链表的初始化,我们同样需要将prev与next指向自己,表示是个循环链表。
循环双链表头插与尾插
循环双链表看着复杂,实际上代码操作简单很多,对于他的头插,我们仍然是创造一个新节点的思路,将其先插入链表,随后维护一下它的prev与pnext的prev指针。
void Push_front(LinkList& phead,int num)//头插
{LinkList newnode = new LNode;newnode->data = num;//存储想插入的num值//如果追求规范,这里可以选择将newnode的两个指针先指向自己//进行插入操作LinkList pnext = phead->next;newnode->next = pnext;phead->next = newnode;//在常规的插入链表操作后,需要进行对prev指针的维护newnode->prev=phead;pnext->prev=newnode;
}对于尾插操作,我们不必再去遍历寻找尾节点,根据循环双链表的特性,phead->prev就是尾节点点位置,之后直接在phead与尾节点之间进行插入就行了:
void Push_pop(LinkList& phead, int num)
{LinkList newnode = new LNode;newnode->data = num;//存储想插入的num值//寻找尾节点LinkList ptail = phead->prev;//找到尾节点了。//进行插入操作newnode->next = phead;ptail->next = newnode;//进行prev的维护newnode->prev=ptail;phead->prev=newnode;
}头删与尾删
循环双链表由于其的指针变量较多,所以删除操作稍微有点繁琐,所谓删除,就是让前后两个节点都找不到被删节点,同时我们在进行删除时也时刻要注意提醒自己小心数据的丢失。
对于头删操作,代码如下:
int Delete_front(LinkList& phead)
{LinkList pcur = phead->next;//pcur代表我们要删除的节点if (pcur == phead)//如果对于头节点本身,就说明没有数据节点,删除操作是无效的{return 0;//删除失败}//将被删除指针从链表中分离LinkList pnext = pcur->next;//这两步操作的目的是让原链表找不到被删节点phead->next = pnext;pnext->prev = phead;//释放内存,指针置空delete pcur;pcur = NULL;//我们delete的内存,这个pcur指针还是存在的,仍然指向之前的位置。但由于那个位置已经被我们delete释放掉了//所以如果后续不再使用pcur,一定要将pcur置为空,避免产生野指针return 1;//代表删除成功
}在单链表中,删除操作只用考虑将上一个节点的next不再指向被删节点,但是在双链表中,删除部分的代码同时要考虑下一个节点prev指针的影响。
尾删操作也是如此:
int Delete_pop(LinkList& phead)
{//寻找被删除的节点,根据双链表特性,phead->prev一直指向尾节点的LinkList pcur = phead->prev, prew = pcur->prev;//pcur需要指向我们要删除的节点,prew我们让它永远在pcur的上一个节点处,方便用来删除尾节点if (pcur == phead)//空链表{return 0;//删除失败}//将被删除指针从链表中分离prew->next = phead;phead->prev = prew;//指向新的尾节点//释放内存,指针置空delete pcur;pcur = NULL;//我们delete的内存,这个pcur指针还是存在的,仍然指向之前的位置。但由于那个位置已经被我们delete释放掉了//所以如果后续不再使用pcur,一定要将pcur置为空,避免产生野指针return 1;//代表删除成功
}三、循环链表的优势与应用
1. 优势
-
无NULL指针:所有节点都有有效指针指向其他节点
-
遍历方便:可以从任意节点开始遍历整个链表
-
环形结构:适合表示环形数据或循环处理场景
2. 典型应用
-
操作系统中的进程调度
-
内存管理中的空闲块管理
-
游戏开发中的循环动画
-
轮询任务处理
对于循环链表的使用,我们一定要注意,终止循环的条件。对于大部分题目,会给我们一个头指针(可能是哨兵节点,也可能是带数据的节点),我们一般不会动这个指针所指向的内容,一般是新创建一个指针pcur来指向头指针的next位置(如果存在),随后用while(pcur != phead )来进行循环遍历。
结语
循环链表是基础数据结构的重要变体,理解它们的原理和实现对于提高编程能力很有帮助。希望通过本文,你能掌握循环单链表和循环双链表的基本概念和操作方法。在实际编程中,可以根据具体需求选择合适的链表类型,来满足不同的需求。




)