引言
在平时线上Redis维护工作中,有时候需要从Redis实例成千上万的key中找出特定前缀的key列表来手动处理数据,可能是修改他的值,也可能是删除key。
Redis提供了一个简单暴力的指令keys用来列出所有满足特定正则字符串规则的key。
127.0.0.1:6379> set codehole1 a
OK
127.0.0.1:6379> set codehole2 b
OK
127.0.0.1:6379> set codehole3 c
OK
127.0.0.1:6379> set code1hole a
OK
127.0.0.1:6379> set code2hole b
OK
127.0.0.1:6379> set code3hole b
OK
127.0.0.1:6379> keys *
1) "codehole1"
2) "code3hole"
3) "codehole3"
4) "code2hole"
5) "codehole2"
6) "code1hole"
127.0.0.1:6379> keys codehole*
1) "codehole1"
2) "codehole3"
3) "codehole2"
127.0.0.1:6379> keys code*hole
1) "code3hole"
2) "code2hole"
3) "code1hole"
这个指令使用很简单,提供一个简单的正则字符串即可,但是有明显的两个缺点
- 没有offset、limit参数,一次性吐出所有满足条件的key,万一实例中有几百w个key满足条件
- keys算法是遍历算法,复杂度为O(n), 如果实例中有千万级以上的key,这个指令就会导致Redis服务卡顿,所有读写Redis的其他指令都会被延后甚至会超时报错。因为Redis是单线程程序,顺序执行所有指令,其他指令必须等到当前的keys指令执行完后才可以继续。
Redis为了解决这个问题,在2.8版本中引入了Scan指令,Scan相比keys具有以下特点:
- 复杂度也是O(n),但是他是通过游标分步进行的,不会阻塞线程。
- 提供limit参数,可以控制每次返回结果的最大条数,limit只是一个hint(优化提示),返回的结果可多可少。
- 同keys一样,他也可以提供模式匹配功能。
- 服务器不需要为游标保存状态,游标唯一状态就是scan返回给客户端的游标整数
- 返回的结果可能会有重复,需要客户端去重
- 遍历的过程中如果有数据修改,改动后的数据能不能遍历到是不确定的。
- 单次返回的结果是空的并不意味着遍历结束,而要看返回的游标值是否为零。
Scan基础使用
向Redis里插入10000条测试数据
import redis
client = redis.StrictRedis()
for i in range(10000):client.set("key%d" % i, i)
目标找出以key99开头key列表。
scan参数提供了三个参数,分别是**cursor整数值;key的正则模式;遍历的limit hint**。第一次遍历时,cursor值为0,然后将返回结果中第一个整数值作为下一次遍历的cursor。一直遍历到返回的cursor值为0时结束。
127.0.0.1:6379> scan 0 match key99* count 1000
1) "13976"
2) 1) "key9911" 2) "key9974" 3) "key9994"。。。。。。。
127.0.0.1:6379> scan 13976 match key99* count 1000
。。。。
127.0.0.1:6379> scan 11687 match key99* count 1000
1) "0" #返回的游标为0,表示遍历结束
注意:虽然每次提供的limit是1000,但是返回的结果只有10个左右,因为这个limit不是限定返回结果的数量,而是限定服务器单次遍历的字典槽位数量(约等于)如果将limit设置为10,可能会发现返回的结果是空的,但是游标值不为0,意味着遍历还没结束。
字典的结构
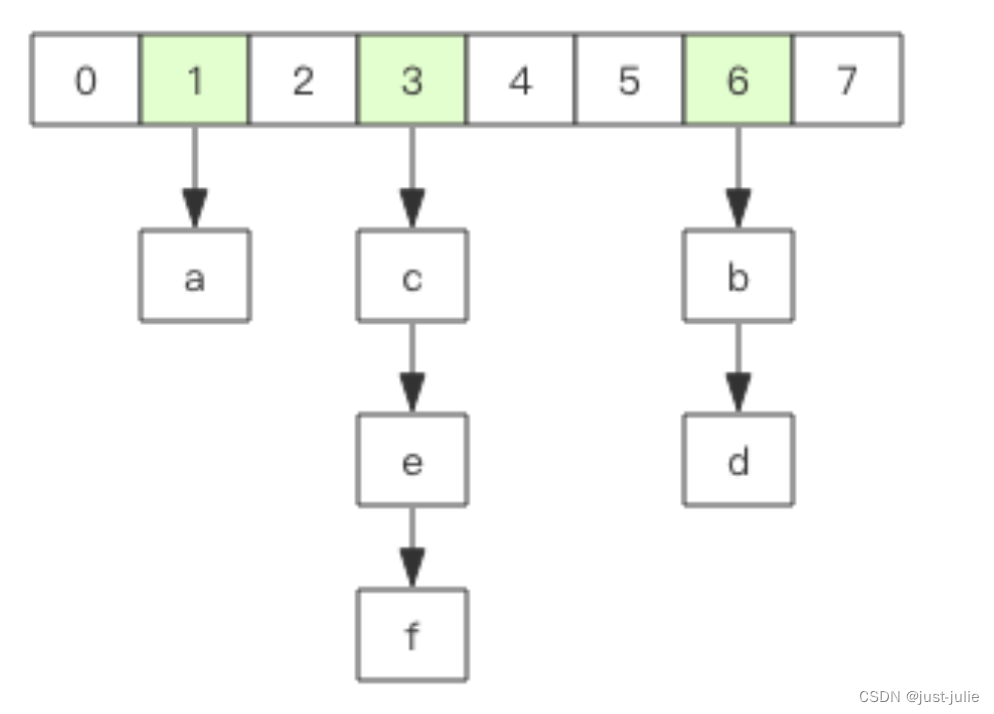
在Redis中所有的key都存储在一个很大的字典中,这个字典的结构和Java中的HashMap一样,是数组+链表结构,第一维数组的大小总是2^n(n>=0),扩容一次数组大小空间加倍,也就是n++.
scan指令返回的游标就是第一维数组的位置索引,我们将这个位置索引称为槽(slot)。如果不考虑字典的扩容缩容,直接按数组下标挨个遍历即可。limit参数表示需要遍历的槽位数,之所以返回的结果可多可少,是因为不是所有的槽位上都会挂接链表,有些槽位可能是空的,还有些槽位挂接的链表上的元素可能有多个。每一次遍历都会将limit数量的槽位上挂接的所有链表元素进行模式匹配过滤后,一次性返回给客户端。
scan遍历顺序
scan的遍历顺序非常特别,他不是从第一维数组的第0位一直遍历到末尾,而是采用了高位进位加法来遍历。之所以使用这样特殊的方式进行遍历,是考虑到字典的扩容和缩容时避免槽位的遍历重复和遗漏。
普通加法和高位进位加法的区别
高位进位加法从左边加,进位往右边移动,同普通加法正好相反,但是最终他们都会遍历所有槽位并且没有重复。
假设当前二进制表示为000,则通过高位进位加法后是100(最高位加1,无进位)。在经过高位进位加是010(最高位加1,有进位,向右传递1)
字典扩容
Java中的HashMap有扩容的概念,当loadFactor达到阈值时,需要重新分配一个新的2倍大小的数组,然后将所有的元素全部rehash挂到新的数组下面。rehash就是将元素的hash值对数组长度进行取模运算,因为长度变了,所以每个元素挂接的槽位可能也发生了变化。又因为数组的长度是2^n次方,所以取模运算等价于位与操作。
位与操作(&):对于每一对对应的位,如果两个对应位都是 1,则结果为 1,否则为 0。
假设当前字典的数组长度由8位扩容到16位,那么3号槽位011将会被rehash到3号槽位和11号槽位,也就是说该槽位链表中大约有一半的元素还是3号槽位,其他元素会放到11号槽位,11这个数字的二进制是1011,也就是对3的二进制011增加了一个高位1.
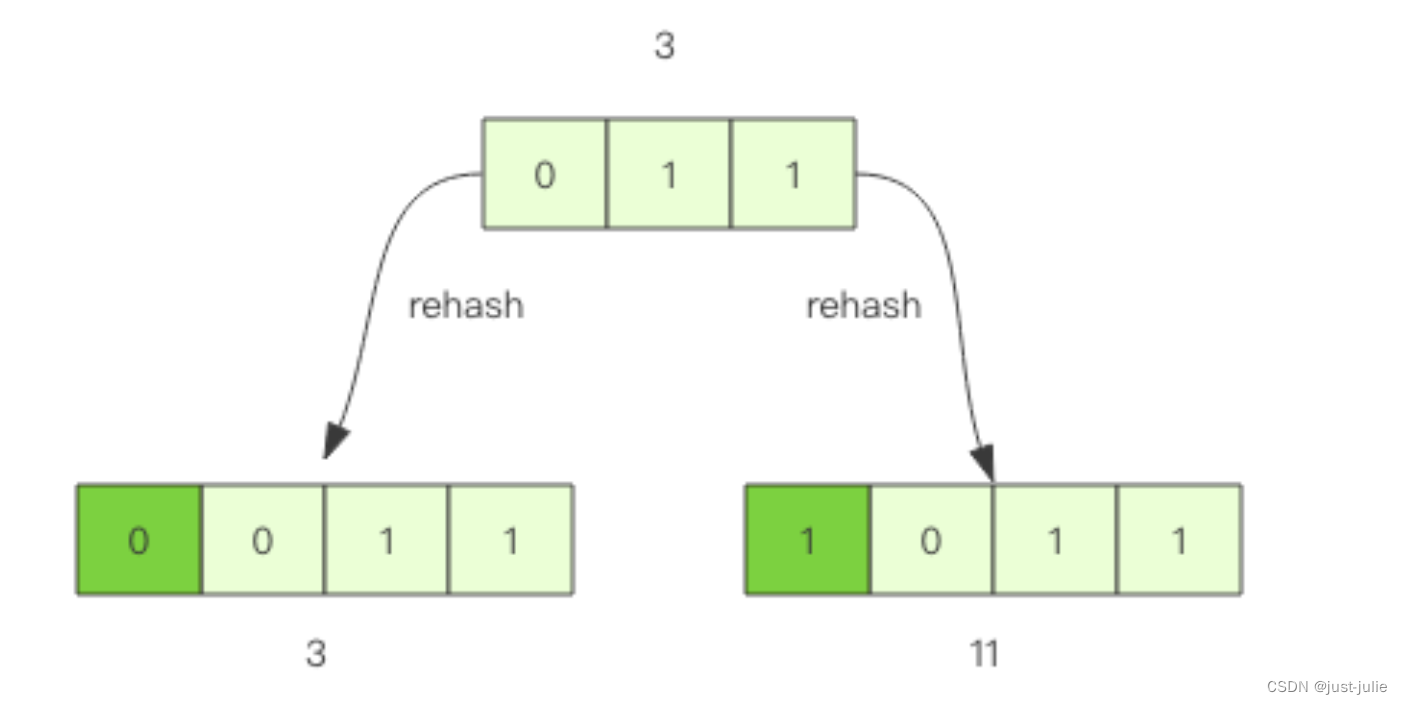
更抽象一点说,假设开始槽位的二进制数是xxx,那么该槽位中的元素将被rehash到0xxx或者1xxx(xxx+8)中。如果字典长度由16位扩容到32位,那么对于二进制槽位xxxx中的元素将被rehash到0xxxx和1xxxx中。
对比扩容缩容前后的遍历顺序
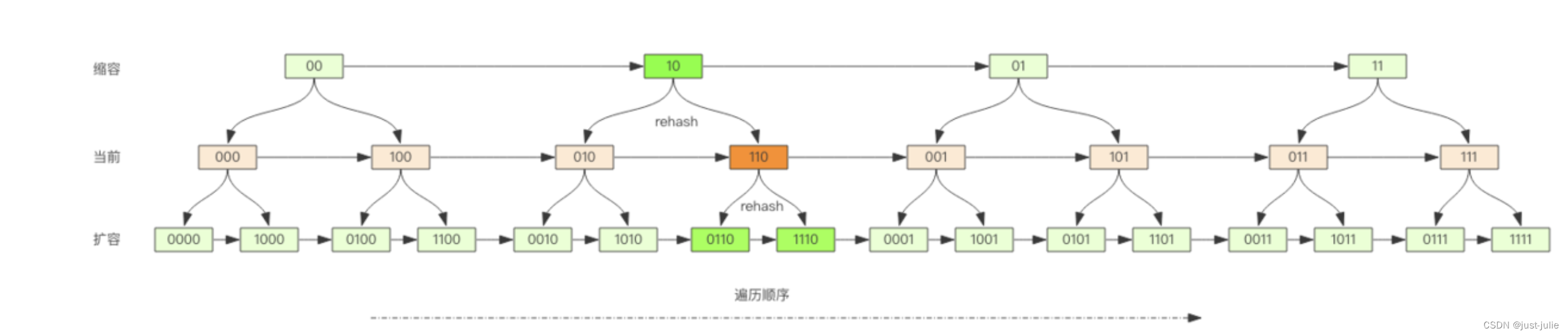
观察这张图,发现采用高位进位加法的遍历顺序,rehash后的槽位在遍历顺序上是相邻的。
假设当前即将遍历110这个位置,那么扩容后,当前槽位上的所有元素对应的新槽位是0110,1110,也就是在槽位的二进制数增加一个高位0或者1.这时,我们可以直接从0110这个槽位开始往后继续遍历,0110槽位之前的所有槽位都是已经遍历过的,这样就可以避免扩容后对已经遍历过的槽位进行重复遍历。
在考虑缩容,假设当前即将遍历110这个位置,那么缩容后,当前槽位所有的元素对应的新槽位是10,也就是去掉槽位二进制最高位。这时,我们可以直接从10这个槽位继续向后遍历,10槽位之前的所有槽位都是已经遍历过的。这样就可以避免缩容的重复遍历。不过缩容还是不太一样,他会对图中010这个槽位上的元素进行重复遍历,因为缩容后10槽位的元素是010和110上挂接的元素的融合。
渐进式rehash
Java中的HashMap在扩容时会一次性将旧数组下挂接的元素全部转移到新数组下面。如果HashMap中元素特别多,线程就会出现卡顿现象,Redis为了解决这个问题,采用渐进式rehash。
他会同时保留旧数组和新数组,然后在定时任务中以及后续对hash的指令操作中渐渐的将旧数组中挂接的元素迁移到新数组上。这意味着要操作处于rehash中的字典,需要同时访问新旧两个数组结构,如果在旧数组下面找不到元素,还需要去新数组下面寻找。
scan也需要考虑这个问题,对于rehash中的字典,需要同时扫描新旧槽位,然后将结果融合后返回给客户端。
更多的scan指令
scan指令是一系列指令,除了可以遍历所有的key之外,还可以对指定的容器集合进行遍历。比如zscan遍历zset集合元素,hscan遍历hash字典中的元素、sscan遍历set集合中的元素。
他们的原理同scan都会类似,因为hash底层就是字典,set也是一个特殊的hash(所有的value都指向同一个元素),zset内部也使用了字典来存储所有的元素内容。
大key扫描
有时候会因为业务人员使用不当,在Redis实例中会形成很大的对象,比如一个很大的hash,一个很大的zset这都是经常出现的。这样的对象对Redis的集群数据迁移带来了很大的问题,因为在集群环境下,如果某个key太大,会导致迁移卡顿。另外,在内存分配上,如果一个key太大,那么当他需要扩容时,会一次性申请更大的一块内存,这也会导致卡顿。如果这个大key被删除,内存会一次性回收,卡顿现象再次发生。
平时的业务开发中,要尽量避免大key的产生
如果观察到Redis的内存大起大落,这极有可能是因为大key导致的,这时候就需要定位出具体是哪个key,进一步定位出具体的业务来源,然后改进相关业务代码设计。
如何定位大key
为了避免对线上Redis带来卡顿,需要用到scan指令,对于扫描出来的每一个key,使用type指令获得key的类型,然后使用相应数据结构的size或者len方法来得到他的大小,对于每一种类型,保留大小的前N名作为扫描结果展示出来。
上面这样的过程需要编写脚本,比较繁琐,可以使用如下指令进行扫描。
redis-cli -h 127.0.0.1 -p 7001 –-bigkeys -i 0.1
–bigkeys: 这是一个特殊的参数,用于在 Redis 数据库中扫描并报告最大的键。这个功能可以帮助识别可能占用过多内存的键。
-i 0.1: 这个参数设置 redis-cli 命令的采样间隔,单位是秒。这里设置为 0.1 秒,意味着 redis-cli 在执行 --bigkeys 操作时每 0.1 秒采样一次,以减少对 Redis 服务器性能的影响。
之 域名解析)





(含模型建立、可运行代码、数据))