PyTorch中Tensor的存储结构
Tensor数据的类型
Tensor 中数据主要有下面两种类型:
- meta data:元数据,也就是描述数据特征的数据,例如 shape、dtype、device、stride等等
- raw data:数据本身,我们可以通过
tensor.data_ptr()获取到数据存储的内存位置
参考下面案例
def tensor_struct():# meta_data / raw_datand_array = np.array([[1, 2, 3], [4, 5, 6]])# tensor = torch.tensor(nd_array) # deep copytensor = torch.from_numpy(nd_array)# raw dataprint(f"pytorch data: \n{tensor}")# print("pytorch raw data: \n", tensor.storage())print(f"numpy raw data_ptr: {nd_array.ctypes.data}")print(f"pytroch raw data_ptr: {tensor.data_ptr()}") # raw_dataprint(f"numpy data id: {id(nd_array)}", )print(f"pytorch data id: {id(tensor)}")tensor2 = tensor.reshape(1, 6)# 观察可以看到 tensor 及 tensor2 的 id 是不同的, 但是 data_ptr 却相同# tensor2 的 row_data 没有变化, meta_data 发生了变化 -> tensor2 是 tensor 的一个 viewprint(f"tensor id: {id(tensor)}")print(f"tensor2 id: ", id(tensor2))print(f"tensor pointer addr: {tensor.data_ptr()}")print(f"tensor2 pointer addr: {tensor2.data_ptr()}")
视图
首先了解一下 Pytorch 中下面的两个概念:
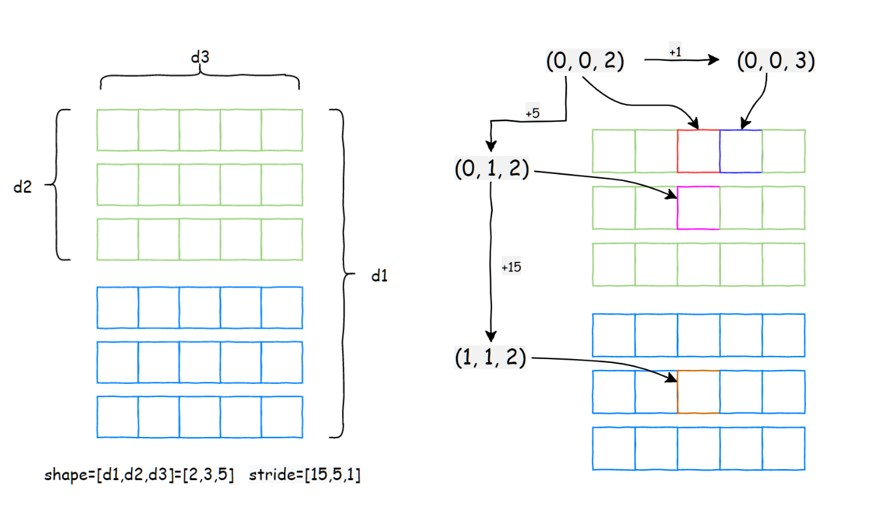
- stride() :获取张量(Tensor)的步幅信息。步幅(Stride)描述了张量在内存中相邻元素之间的距离(以元素个数为单位),对于多维张量而言,它是一个表示各维度间跳跃关系的元组
- data_ptr():获取张量(Tensor)底层数据在内存中的起始地址。这个地址是一个整数值,通常表示为一个C语言指针类型(在Python环境中表现为Python整数)
参考下面案例
# 理解 tensor 的步长
def stride_demo():tensor = torch.randn(2, 3, 5)# stride 就是 tensor 中某一个维度上, 相邻元素之间的步长(以元素个数为单位)# 对于 shape 为 2,3,5 的 tensor# 在第0维上, 两个元素之间的步长为 3*5 = 15# 在第1维上, 两个元素之间的步长为 5*1 = 5# 在第2维上, 由于是最后一个维度了, 两个相邻元素间步长就是1了tensor_stride = tensor.stride()print(f"tensor_stride: {tensor_stride}")print(f"tensor.stride(0): {tensor.stride(0)}")print(f"tensor.stride(1): {tensor.stride(1)}")print(f"tensor.stride(2): {tensor.stride(2)}")
实际上PyTorch获取指定索引位置的数据时,本质上是通过data_ptr()的位置获取多维数组的起始点,然后依据 stride() 计算指定维度走一步需要移动的位置,最终计算出当前索引的数据。
对于一个 shape 为 [2, 3, 5]的 tensor,那么它的 stride 应当为:
- 第0维:stride[0] 应当为后面两维的乘积,也就是 5*3 = 15
- 第1维:stride[1] 应当为后面一维的维度,也就是 5
- 第1维:stride[2] 上面每一个数值都是连续的,也就是1
因此,stride也就是 [15, 5, 1]
连续型与破坏连续性
Tensor中的连续性
如果 Tensor 的 stride 满足前面的定义,那么在读取数据时可以认为是连续的,在做类似矩阵乘法时读取数据的效率就会比较高。
但是有一些操作是会破坏这种连续性的
参考下面案例
def contiguous_demo():data0 = torch.randint(0, 10, (2, 5))data1 = data0.transpose(1, 0)data2 = data0.reshape(5, 2)print(f"data0: {data0}")# data1 和 data2 的 shape 相同, 但是对应位置上的值是不同的# data0: [ [3, 5, 5, 9, 2], [8, 7, 4, 9, 7] ]# data1: [ [3, 8], [5, 7], [5, 4], [9, 9], [2, 7] ]# data2: [ [3, 5], [5, 9], [2, 8], [7, 4], [9, 7] ]print(f"data1: {data1}")print(f"data2: {data2}")# data0、data1、data2 中 的data_ptr() 都是是相同的,说明 row_data 是没有变化的# transpose 以及 reshape 操作虽然数据不同,但转换以后 raw_data 是没有变化的print(f"data0 data_ptr: {data0.data_ptr()}")print(f"data1 data_ptr: {data1.data_ptr()}")print(f"data2 data_ptr: {data2.data_ptr()}")# transpose 以及 reshape 的区别在于两个操作以后 tensor 的 stride 发生了变化# 根据之前的例子对于一个 (5, 2) 的 tensor, stride 取值应当是 (2, 1)# 可以看到, reshape 以后是满足这个性质的# ------------------------ transpose 导致的不连续现象 -------------------------# tensor 在 transpose 操作之后, 读取数据的方式发生了改变, 不能像之前一样 "挨个" 读取数据# 从而发生了数据 "不连续" 的现象 !!!# 也就是说 transpose 操作本质上仍然是获取的是一个 view,但是会导致数据的不连续# ------------------------ transpose 导致的不连续现象 -------------------------print(f"data0 stride: {data0.stride()}") # (5, 1)print(f"data1 stride: {data1.stride()}") # (1, 5)print(f"data2 stride: {data2.stride()}") # (2, 1)print(f"data0 is_contiguous: {data0.is_contiguous()}") # Trueprint(f"data1 is_contiguous: {data1.is_contiguous()}") # Falseprint(f"data2 is_contiguous: {data2.is_contiguous()}") # True
可以看到 transpose 操作会与原始的 tensor 共享同一份 raw_data,但是会使得原来读取最后一个维度数据时发生不连续的现象,因此使得数据变得 “不连续” 了。
常见的破坏连续性的算子
主要有 transpose、permute、T 等等
参考下面案例
def discontinuous_operator():data0 = torch.randint(0, 10, (2, 3, 4))# transpose 指定交换 第0轴 和 第1轴data1 = data0.transpose(0, 1)# permute 指的是: 原来第0轴 -> 第2轴, 原来第1轴 -> 第0轴, 原来第2轴 -> 第1轴data2 = data0.permute(2, 0, 1)data3 = data0.Tprint(f"data0.shape: {data0.shape}") # [2, 3, 4]print(f"data1.shape: {data1.shape}") # [3, 2, 4]print(f"data2.shape: {data2.shape}") # [4, 2, 3]print(f"data3.shape: {data3.shape}") # [4, 3, 2]print(f"data0 stride: {data0.stride()}") # (12, 4, 1)print(f"data1 stride: {data1.stride()}") # (4, 12, 1)print(f"data2 stride: {data2.stride()}") # (1, 12, 4)print(f"data3 stride: {data3.stride()}") # (1, 4, 12)
contiguous() 方法
既然有些算子会破坏Tensor的连续性,那么有没有什么方法可以避免呢?
我们可以使用 Tensor 中提供的 contiguous()方法使得 Tensor 变为连续的,本质上也就是新开辟了一个数据存储空间,然后把原来的数据挪到新空间下。
参考下面案例
def contiguous_method():data0 = torch.randint(0, 10, (2, 5))# 这时候 data1 只是 data0 的一个 viewdata1 = data0.transpose(0, 1)# 此时创建了一个新的数据空间, data1 已经不是 data0 的一个 view了, 两者的 raw_data 已经不同了data1 = data1.contiguous()print(f"data1 shape: {data1.shape}")print(f"data1 stride: {data1.stride()}")# 可以看到此时 data0 与 data1 的 data_ptr 已经不同了print(f"data0 data_ptr: {data0.data_ptr()}")print(f"data1 data_ptr: {data1.data_ptr()}")
我们可以看到,对于一个不连续的 Tensor 调用 contiguous()方法后,Tensor重新变为连续的了,但是 raw_data 也发生了改变。
reshape vs view
在大部分情况下,reshape 和 view 的作用都是相同的,但是在处理不连续的 Tensor 时,两个算子处理上有所差异:
- view:直接报错
_view size is not compatible with input tensor's size and stride_ - reshape:会新开辟一个空间存储,将原有数据copy到新的存储空间当中。
参考下面案例
def view_discontinuous():data0 = torch.randint(0, 10, (2, 5))data1 = data0.transpose(0, 1)# 直接报错: view size is not compatible with input tensor's size and stridedata2 = data1.view(2, 5)print(f"data2: {data2}")def reshape_discontinuous():data0 = torch.randint(0, 10, (2, 5))data1 = data0.transpose(0, 1)# 此时程序可以跑通data2 = data1.reshape(2, 5)print(f"data0: {data0}")print(f"data1: {data1}")print(f"data2: {data2}")# 可以看到 data0 和 data1 共享一份 raw_data, 但是 data2 的 raw_data 发生了改变# 也就是说: reshape 一个不连续的 tensor, 会新创建一个空间, 将原来的数据 copy 到新的空间print(f"data0 data_ptr: {data0.data_ptr()}")print(f"data1 data_ptr: {data1.data_ptr()}")print(f"data2 data_ptr: {data2.data_ptr()}")






