简介
爬虫的特点:模拟用户使用浏览器,发送请求,获取响应
爬虫分类
根据爬取网站的数量,可以分为:
- 通用爬虫
- 聚焦爬虫(某一个网站的数据)
根据获取数据的目的,可以分为:
- 功能性爬虫
- 数据增量爬虫
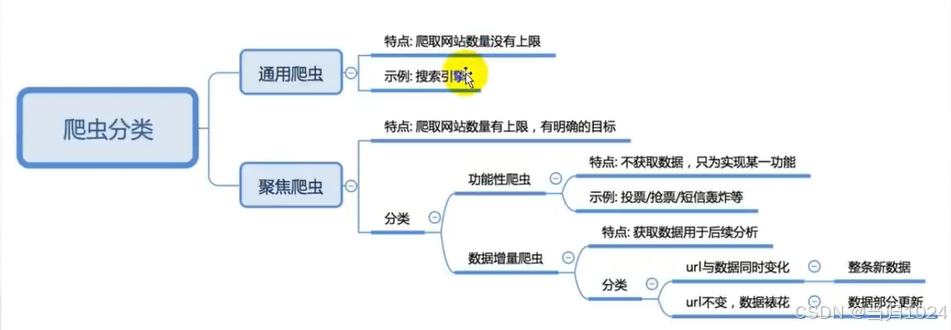
基本流程
- 使用url,模拟用户发送请求
- 获取响应
- 解析响应,获取数据
- 提取数据,并且保存数据
http协议和https协议
- http协议:
超文本传输协议,默认端口号是88- 超文本:
不仅仅限于文本,还包括图片、音频、视频- 传输协议:指使用共用约定的
固定格式来传递转换成字符串的超文本内容
- https协议:
http+ssl(安全套接字层)默认端口号是443- 带有安全套接字层的超文本传输协议
- ssl对传输的
内容进行加密
http请求/响应的步骤:
- 客户端连接到web服务器
- 发送http请求
- 服务器接受请求返回响应
- 释放连接tcp连接
- 客户端解析html内容
请求头
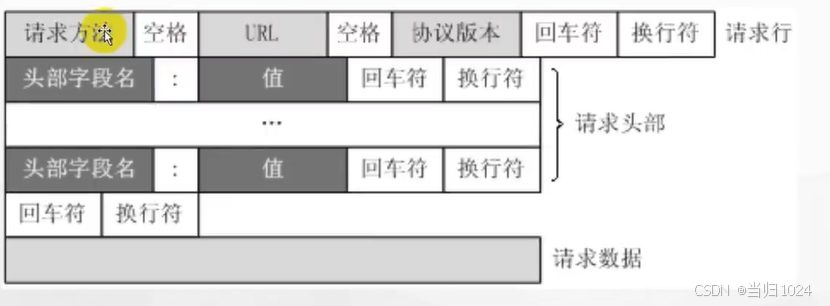
请求方法:get和post
- get:向服务器获取资源
- post:向服务器提交资源
- User-Agent:模拟正常用户
- cookie:登录保持
- referer:当前这一次请求是由哪个请求过来的






