大数据技术之Scala
一、面向对象
1、抽象类
1.1抽象属性和抽象方法
1)基本语法
①定义抽象类:abstract class Person{} //通过 abstract 关键字标记抽象类
②定义抽象属性:val|var name:String //一个属性没有初始化,就是抽象属性
③定义抽象方法:def hello():String //只声明而没有实现的方法,就是抽象方法
案例实操
abstract class Person {
val name: String def hello(): Unit
}
val name: String = "teacher" def hello(): Unit = {
println("hello teacher")
}
}
2)继承&重写
①如果父类为抽象类,那么子类需要将抽象的属性和方法实现,否则子类也需声明为抽象类
②重写非抽象方法需要用 override 修饰,重写抽象方法则可以不加 override。
③子类中调用父类的方法使用 super 关键字
④子类对抽象属性进行实现,父类抽象属性可以用 var 修饰;
子类对非抽象属性重写,父类非抽象属性只支持 val 类型,而不支持 var。
因为var修饰的为可变变量,子类继承之后就可以直接使用,没有必要重写
1.2、匿名子类
1)说明:
和 Java 一样,可以通过包含带有定义或重写的代码块的方式创建一个匿名的子类。
2)案例实操
abstract class Person {
val name: String def hello(): Unit
}
object Test {
def main(args: Array[String]): Unit = { val person = new Person {
override val name: String = "teacher"
override def hello(): Unit = println("hello teacher")
}
}
2、单例对象(伴生对象)
Scala语言是完全面向对象的语言,所以并没有静态的操作(即在Scala中没有静态的概念)。但是为了能够和Java语言交互(因为Java中有静态概念),就产生了一种特殊的对象来模拟类对象,该对象为单例对象。若单例对象名与类名一致,则称该单例对象这个类的伴生对象,这个类的所有“静态”内容都可以放置在它的伴生对象中声明。
2.1、单例对象语法
1)基本语法
object Person{
val country:String="China"
}
2)说明
①单例对象采用object 关键字声明
②单例对象对应的类称之为伴生类,伴生对象的名称应该和伴生类名一致。
③单例对象中的属性和方法都可以通过伴生对象名(类名)直接调用访问。
3)案例实操
//(1)伴生对象采用 object 关键字声明
object Person {
var country: String = "China"
}
//(2)伴生对象对应的类称之为伴生类,伴生对象的名称应该和伴生类名一致。class Person {
var name: String = "bobo"
}
object Test {
def main(args: Array[String]): Unit = {
//(3)伴生对象中的属性和方法都可以通过伴生对象名(类名)直接调用访
问。
println(Person.country)
}
}
2.2、apply方法
1)说明
①通过伴生对象的 apply 方法,实现不使用 new 方法创建对象。
②如果想让主构造器变成私有的,可以在()之前加上 private。
③apply 方法可以重载。
④Scala 中 obj(arg)的语句实际是在调用该对象的 apply 方法,即 obj.apply(arg)。用以统一面向对象编程和函数式编程的风格。
⑤当使用 new 关键字构建对象时,调用的其实是类的构造方法,当直接使用类名构建对象时,调用的其实时伴生对象的 apply 方法。
2)案例实操
object Test {
def main(args: Array[String]): Unit = {
//(1)通过伴生对象的 apply 方法,实现不使用 new 关键字创建对象。
val p1 = Person() println("p1.name=" + p1.name)
val p2 = Person("bobo") println("p2.name=" + p2.name)
}
}
//(2)如果想让主构造器变成私有的,可以在()之前加上 private class Person private(cName: String) {
var name: String = cName
}
object Person {
def apply(): Person = { println("apply 空参被调用") new Person("xx")
}
def apply(name: String): Person = { println("apply 有参被调用")
new Person(name)
}
//注意:也可以创建其他类型对象,并不一定是伴生对象
}
3、特质(Trait)
Scala 语言中,采用特质 trait(特征)来代替接口的概念,也就是说,多个类具有相同的特质(特征)时,就可以将这个特质(特征)独立出来,采用关键字 trait 声明。
Scala 中的 trait 中即可以有抽象属性和方法,也可以有具体的属性和方法,一个类可以混入(mixin)多个特质。这种感觉类似于 Java 中的抽象类。
Scala 引入 trait 特征,第一可以替代 Java 的接口,第二个也是对单继承机制的一种补充。
3.1、特质声明
1)基本语法
trait 特质名 { trait 主体
}
2)案例实操
trait PersonTrait {
// 声明属性
var name:String = _
// 声明方法
def eat():Unit={
}
// 抽象属性
var age:Int
// 抽象方法
def say():Unit
}
3.2、特质基本语法
一个类具有某种特质(特征),就意味着这个类满足了这个特质(特征)的所有要素, 所以在使用时,也采用了extends 关键字,如果有多个特质或存在父类,那么需要采用with 关键字连接。
1)基本语法:
没有父类:class 类名 extends 特质 1 with 特质 2 with 特质 3 …
有父类:class 类名 extends 父类 with 特质 1 with 特质 2 with 特质 3…
2)说明
①类和特质的关系:使用继承的关系。
②当一个类去继承特质时,第一个连接词是 extends,后面是with。
③如果一个类在同时继承特质和父类时,应当把父类写在 extends 后。
3)案例实操
(1)特质可以同时拥有抽象方法和具体方法
(2)一个类可以混入(mixin)多个特质
(3)所有的 Java 接口都可以当做Scala 特质使用
(4)动态混入:可灵活的扩展类的功能
(4.1)动态混入:创建对象时混入trait,而无修饰类混入该trait
(4.2)如果混入的 trait 中有未实现的方法,则需要实现
trait PersonTrait {
//(1)特质可以同时拥有抽象方法和具体方法
// 声明属性
var name: String = _
// 抽象属性
var age: Int
// 声明方法
def eat(): Unit = { println("eat")
}
// 抽象方法
def say(): Unit
}
trait SexTrait { var sex: String
}
//(2)一个类可以实现/继承多个特质
//(3)所有的 Java 接口都可以当做 Scala 特质使用
class Teacher extends PersonTrait with java.io.Serializable {
override def say(): Unit = { println("say")
}
override var age: Int = _
}
object TestTrait {
def main(args: Array[String]): Unit = { val teacher = new Teacher() teacher.say()
teacher.eat()
//(4)动态混入:可灵活的扩展类的功能
val t2 = new Teacher with SexTrait { override var sex: String = "男"
}
//调用混入 trait 的属性
println(t2.sex)
}
3.3特质叠加
由于一个类可以混入(mixin)多个 trait,且 trait 中可以有具体的属性和方法,若混入的特质中具有相同的方法(方法名,参数列表,返回值均相同),必然会出现继承冲突问题。冲突分为以下两种:
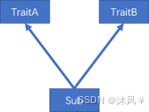
第一种,一个类(Sub)混入的两个 trait(TraitA,TraitB)中具有相同的具体方法,且两个 trait 之间没有任何关系,解决这类冲突问题,直接在类(Sub)中重写冲突方法。
第二种,一个类(Sub)混入的两个 trait(TraitA,TraitB)中具有相同的具体方法,且两个 trait 继承自相同的 trait(TraitC),及所谓的“钻石问题”,解决这类冲突问题,Scala 采用了特质叠加的策略。
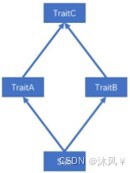
所谓的特质叠加,就是将混入的多个 trait 中的冲突方法叠加起来,案例如下,
trait Ball {
def describe(): String = { "ball"
}
}
trait Color extends Ball {
override def describe(): String = { "blue-" + super.describe()
}
}
trait Category extends Ball { override def describe(): String = {
"foot-" + super.describe()
}
}
class MyBall extends Category with Color { override def describe(): String = {
"my ball is a " + super.describe()
}
}
object TestTrait {
def main(args: Array[String]): Unit = { println(new MyBall().describe())
}
}
运行结果:

3.4、特质叠加执行顺序
思考:上述案例中的 super.describe()调用的是父 trait 中的方法吗?
当一个类混入多个特质的时候,scala 会对所有的特质及其父特质按照一定的顺序进行排序,而此案例中的 super.describe()调用的实际上是排好序后的下一个特质中的 describe() 方法。,排序规则如下:
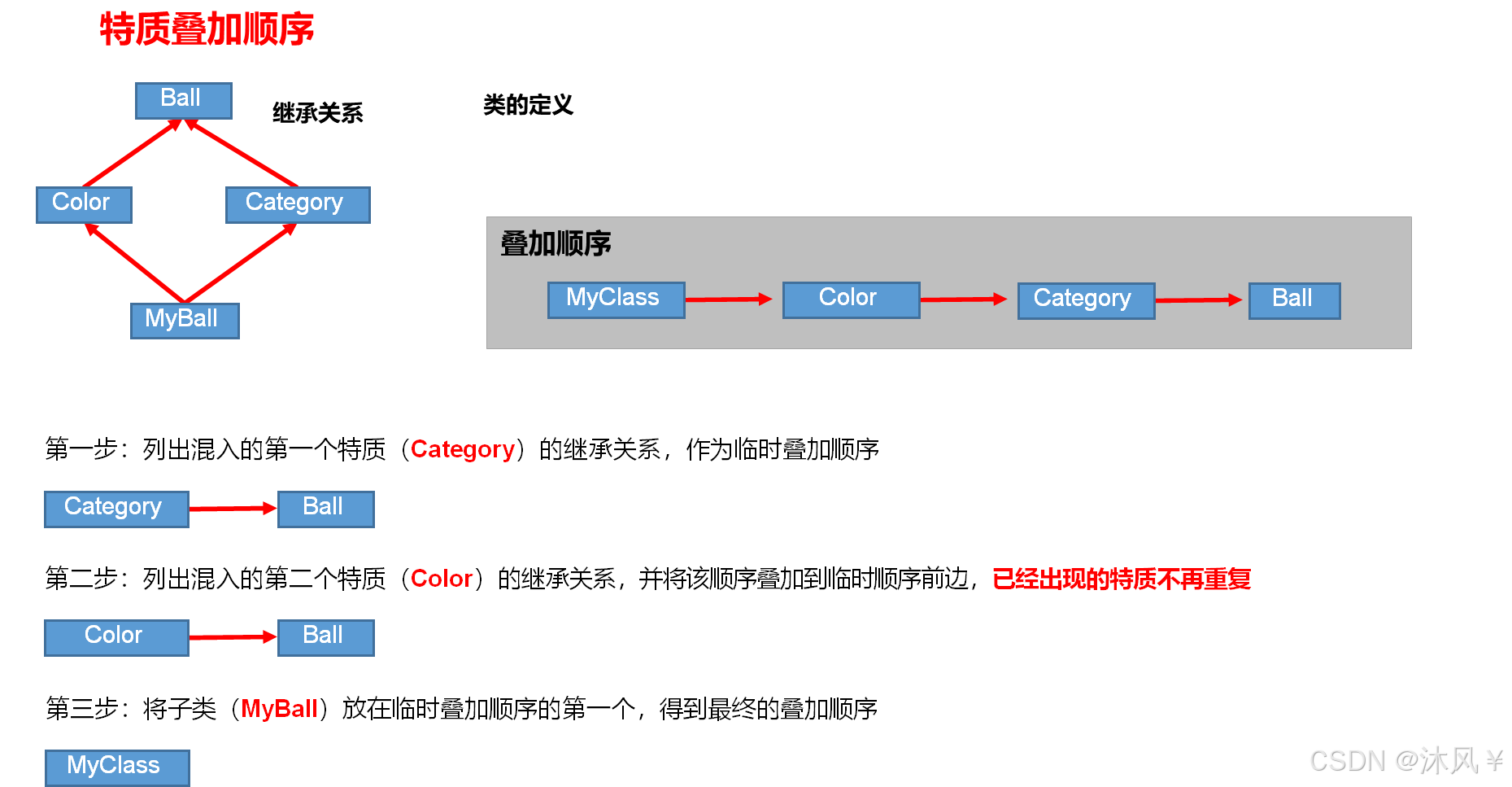
结论:
①案例中的 super,不是表示其父特质对象,而是表示上述叠加顺序中的下一个特质,即,MyClass 中的 super 指代 Color,Color 中的 super 指代Category,Category 中的super指代Ball。
②如果想要调用某个指定的混入特质中的方法,可以增加约束: super[],例如
super[Category].describe()。
3.5、特质自身类型
1)说明
自身类型可实现依赖注入的功能。
2)案例实操
class User(val name: String, val age: Int)
trait Dao {
def insert(user: User) = {
println("insert into database :" + user.name)
}
}
trait APP {
_: Dao =>
def login(user: User): Unit = { println("login :" + user.name) insert(user)
}
}
object MyApp extends APP with Dao {
def main(args: Array[String]): Unit = { login(new User("bobo", 11))
}
}
3.6、特质和抽象类的区别
①优先使用特质。一个类扩展多个特质是很方便的,但却只能扩展一个抽象类。
②如果你需要构造函数参数,使用抽象类。因为抽象类可以定义带参数的构造函数,而特质不行(有无参构造)。
4、扩展
4.1、类型检查和转换
1)说明
①obj.isInstanceOf[T]:判断 obj 是不是T 类型。
②obj.asInstanceOf[T]:将 obj 强转成 T 类型。
③classOf 获取对象的类名。
2)案例实操
class Person{
}
object Person {
def main(args: Array[String]): Unit = { val person = new Person
//(1)判断对象是否为某个类型的实例
val bool: Boolean = person.isInstanceOf[Person]
if ( bool ) {
//(2)将对象转换为某个类型的实例
val p1: Person = person.asInstanceOf[Person] println(p1)
}
//(3)获取类的信息
val pClass: Class[Person] = classOf[Person] println(pClass)
}
}
4.2、枚举类和应用类
1)说明
枚举类:需要继承 Enumeration
应用类:需要继承App
2)案例实操
object Test {
def main(args: Array[String]): Unit = {
println(Color.RED)
}
}
// 枚举类
object Color extends Enumeration { val RED = Value(1, "red")
val YELLOW = Value(2, "yellow") val BLUE = Value(3, "blue")
}
// 应用类
object Test20 extends App { println("xxxxxxxxxxx");
}
4.3、Type定义新类型
1)说明
使用 type 关键字可以定义新的数据数据类型名称,本质上就是类型的一个别名
2)案例实操
object Test {
def main(args: Array[String]): Unit = { type S=String
var v:S="abc"
def test():S="xyz"
}
}
二、集合
1、集合简介
①Scala 的集合有三大类:序列 Seq、集Set、映射 Map,所有的集合都扩展自 Iterable特质。
②对于几乎所有的集合类,Scala 都同时提供了可变和不可变的版本,分别位于以下两个包
③不可变集合:scala.collection.immutable 可变集合: scala.collection.mutable
scala 不可变集合,就是指该集合对象不可修改,每次修改就会返回一个新对象, 而不会对原对象进行修改。类似于 java 中的 String 对象
④可变集合,就是这个集合可以直接对原对象进行修改,而不会返回新的对象。类似于 java 中 StringBuilder 对象
建议:在操作集合的时候,不可变用符号,可变方法
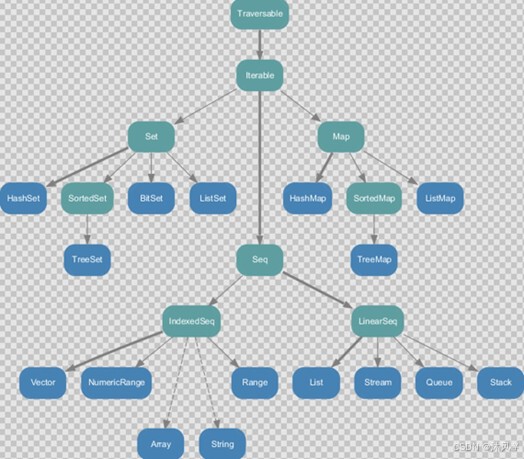
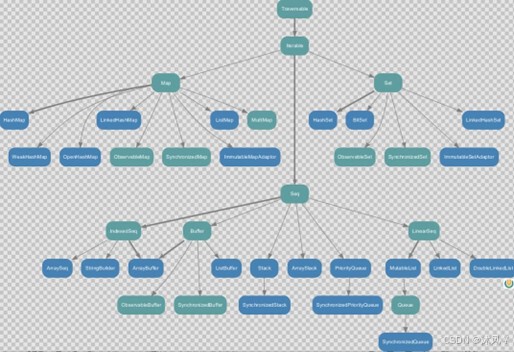
1.1、不可变集合继承图
1)Set、Map 是 Java 中也有的集合
2)Seq 是 Java 没有的,我们发现 List 归属到Seq 了,因此这里的 List 就和 Java 不是同一个概念了
3)我们前面的for 循环有一个 1 to 3,就是 IndexedSeq 下的 Range 4)String 也是属于 IndexedSeq
4)我们发现经典的数据结构比如 Queue 和 Stack 被归属到 LinearSeq(线性序列)
5)大家注意Scala 中的 Map 体系有一个 SortedMap,说明 Scala 的 Map 可以支持排序
6)IndexedSeq 和LinearSeq 的区别:
①IndexedSeq 是通过索引来查找和定位,因此速度快,比如String 就是一个索引集合,通过索引即可定位
②LinearSeq 是线型的,即有头尾的概念,这种数据结构一般是通过遍历来查找
1.2、可变集合继承图
2、数组
2.1、不可变数组
1)第一种方式定义数组
定义:val arr1 = new Array[Int](10)
①new 是关键字
②[Int]是指定可以存放的数据类型,如果希望存放任意数据类型,则指定Any
③(10),表示数组的大小,确定后就不可以变化
2)案例实操
object TestArray{
def main(args: Array[String]): Unit = {
//(1)数组定义
val arr01 = new Array[Int](4)
println(arr01.length) // 4
//(2)数组赋值
//(2.1)修改某个元素的值arr01(3) = 10
//(2.2)采用方法的形式给数组赋值arr01.update(0,1)
//(3)遍历数组
//(3.1)查看数组println(arr01.mkString(","))
//(3.2) 普 通 遍 历 for (i <- arr01) {
println(i)
}
//(3.3)简化遍历
def printx(elem:Int): Unit = { println(elem)
}
arr01.foreach(printx)
// arr01.foreach((x)=>{println(x)})
// arr01.foreach(println(_)) arr01.foreach(println)
//(4)增加元素(由于创建的是不可变数组,增加元素,其实是产生新的数
组)
println(arr01)
val ints: Array[Int] = arr01 :+ 5 println(ints)
}
}
3)第二种方式定义数组
val arr1 = Array(1, 2)
在定义数组时,直接赋初始值
使用apply 方法创建数组对象
4)案例实操
object TestArray{
def main(args: Array[String]): Unit = {
var arr02 = Array(1, 3, "bobo") println(arr02.length)
for (i <- arr02) {
println(i)
}
}
}
2.2、可变数组
1)定义变长数组
val arr01 = ArrayBuffer[Any](3, 2, 5)
①[Any]存放任意数据类型
②(3, 2, 5)初始化好的三个元素
③ArrayBuffer 需要引入scala.collection.mutable.ArrayBuffer 2)案例实操
①ArrayBuffer 是有序的集合
②增加元素使用的是 append 方法(),支持可变参数
import scala.collection.mutable.ArrayBuffer object TestArrayBuffer {
def main(args: Array[String]): Unit = {
//(1)创建并初始赋值可变数组
val arr01 = ArrayBuffer[Any](1, 2, 3)
//(2)遍历数组
for (i <- arr01) { println(i)
}
println(arr01.length) // 3 println("arr01.hash=" + arr01.hashCode())
//(3)增加元素
//(3.1)追加数据arr01.+=(4)
//(3.2)向数组最后追加数据arr01.append(5,6)
//(3.3)向指定的位置插入数据arr01.insert(0,7,8) println("arr01.hash=" + arr01.hashCode())
//(4)修改元素
arr01(1) = 9 //修改第 2 个元素的值
println(" ")
for (i <- arr01) { println(i)
}
println(arr01.length) // 5
}
}
2.3、不可变数组和可变数组的转换
1)说明
arr1.toBuffer //不可变数组转可变数组arr2.toArray //可变数组转不可变数组
①arr2.toArray 返回结果才是一个不可变数组,arr2 本身没有变化
②arr1.toBuffer 返回结果才是一个可变数组,arr1 本身没有变化
2)案例实操
object TestArrayBuffer {
def main(args: Array[String]): Unit = {
//(1)创建一个空的可变数组
val arr2 = ArrayBuffer[Int]()
//(2)追加值arr2.append(1, 2, 3)
println(arr2) // 1,2,3
//(3)ArrayBuffer ==> Array
//(3.1)arr2.toArray 返回的结果是一个新的定长数组集合
//(3.2)arr2 它没有变化
val newArr = arr2.toArray println(newArr)
//(4)Array ===> ArrayBuffer
//(4.1)newArr.toBuffer 返回一个变长数组 newArr2
//(4.2)newArr 没有任何变化,依然是定长数组val newArr2 = newArr.toBuffer newArr2.append(123)
println(newArr2)
}
}






