HashSet在Java中是基于HashMap实现的,它实际上是将所有元素作为HashMap的key存储,而value则统一使用一个静态的Object对象(Present)作为占位符。
1.举例演示
下面我们就举例说明一下,HashSet集合中,一个节点上的链表添加数据以及树化的过程。
1.代码准备
首先我们写一个类A,用类A的对象作为放到集合中的数据。这里,我们还重写了hashCode()方法,我们知道,HashSet集合在执行add()方法添加数据时会计算其hash值,根据hash值分配在集合中的节点位置。所以我们重写了hashCode()方法,使类A的每一个对象计算的hash值都相同,都分配到同一结点,从而观察同一个节点中链表的增加。

然后,创建一个HashSet集合hashSet,
写一个for循环,循环往集合里加入A类的对象 new A(i)
为每个对象的属性n赋值i,因为每次循环的i不同,所以每个对象的属性不同,避免它们equals,无法添加

准备过程就结束了,接着我们开始debug调试
所用代码
//演示一下 一个结点的单链表的增加和表的树化import java.util.HashSet;public class HashSet_03 {public static void main(String[] args) {HashSet hashSet = new HashSet();for (int i = 1; i < 12; i++) {hashSet.add(new A(i));//向hashSet里添加A的对象,并且每个对象的属性不同,避免它们equals,无法添加//链表长度超过8后,table长度没超过64时,table长度翻倍,再往链表里添加,再翻倍,// 达到64后,再添加,table 转化为红黑树}}
}
class A{int n;public A(int n){this.n = n;}//为了让他们能添加到同一个链表,需要保证他们的hash值相同//重写Object类的hash计算方法@Overridepublic int hashCode() {return 100;//使其返回定值}
}2.调试操作
设置
由于设置不同,调试界面可能不同,这里是本文的设置,大家可以参考
操作
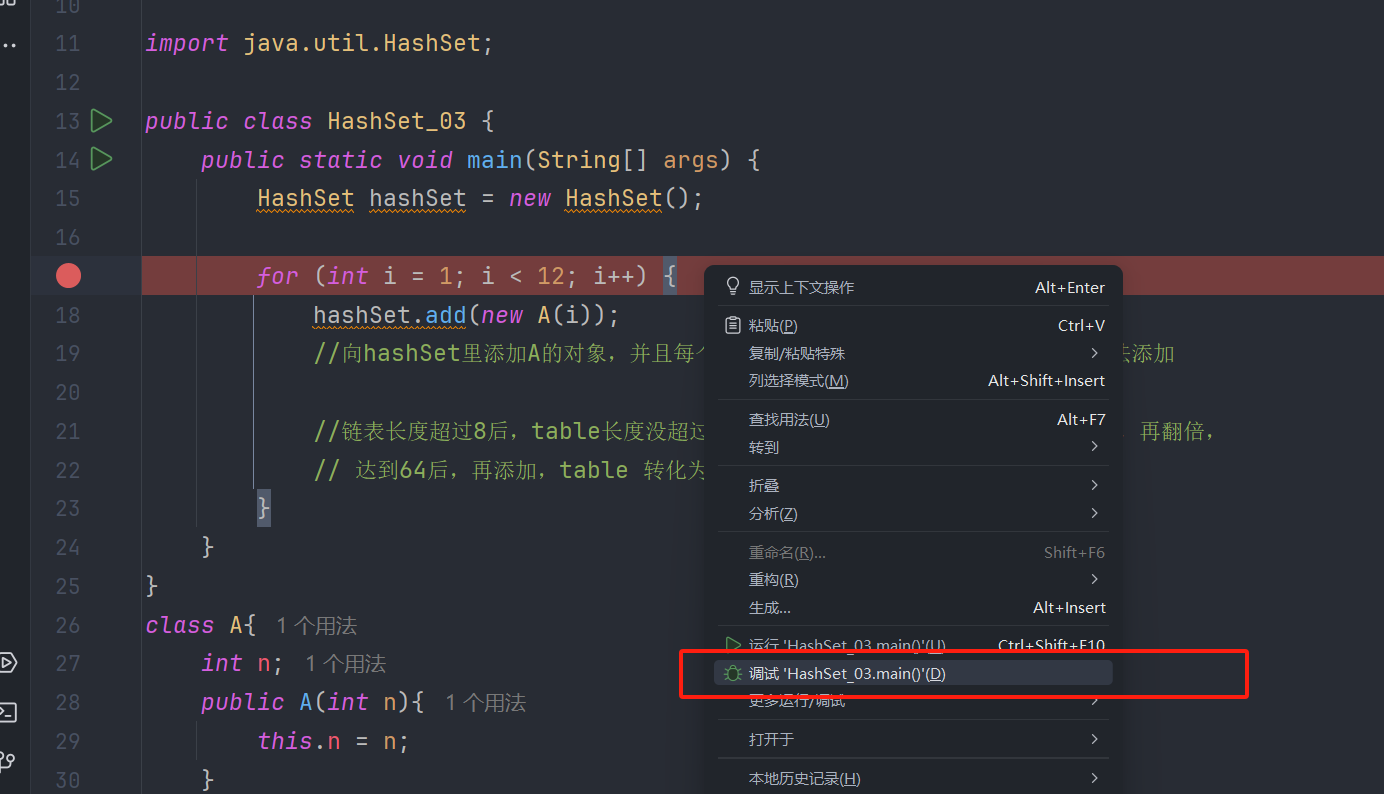
在for语句上创建断点,右键开始调试,每点击两次步进,是添加一次数据
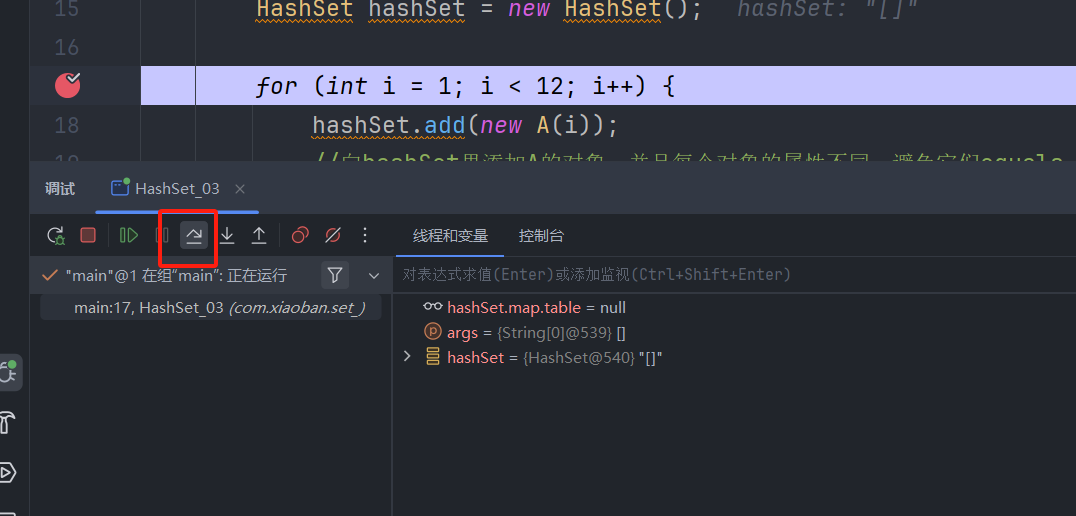
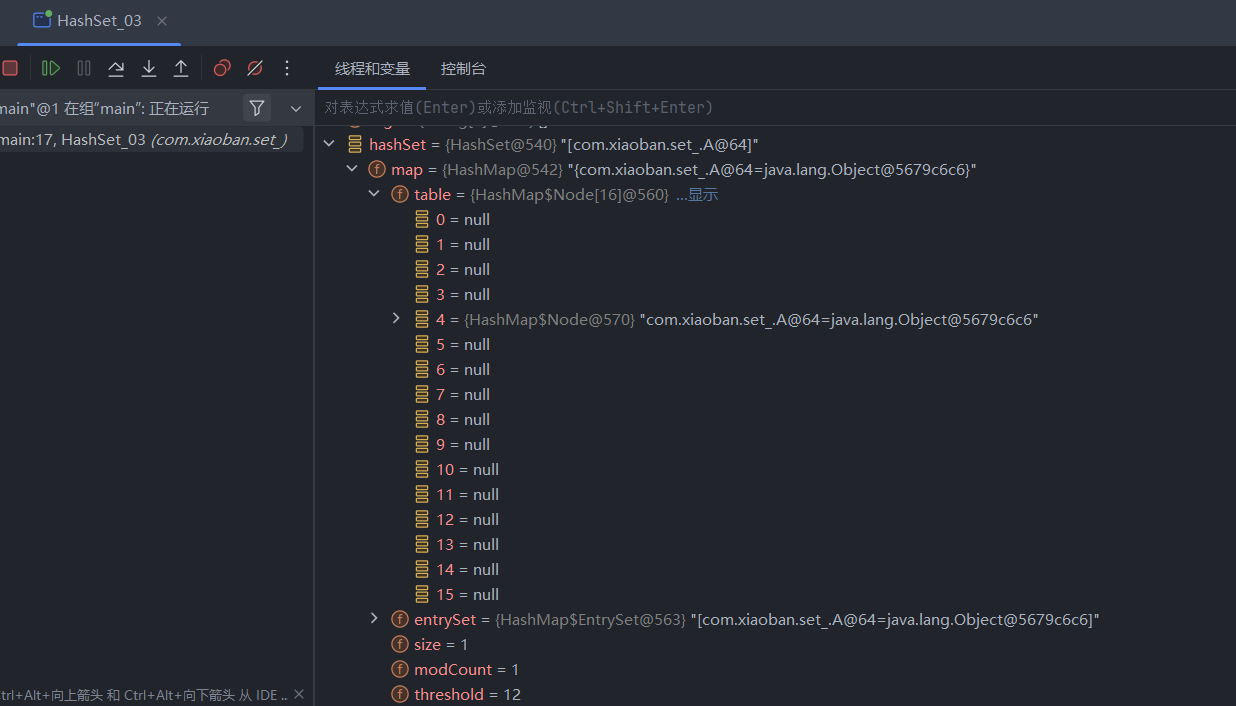
添加完第一个数据后,可以看到hashSet下面出现了一个table表,点开可以看到,当前tabel有16个节点(0-15),第一个数据被添加到了索引为4的位置。
再执行两次步进,点开4下面的next,可以看到第二个元素被添加到了4的next位置
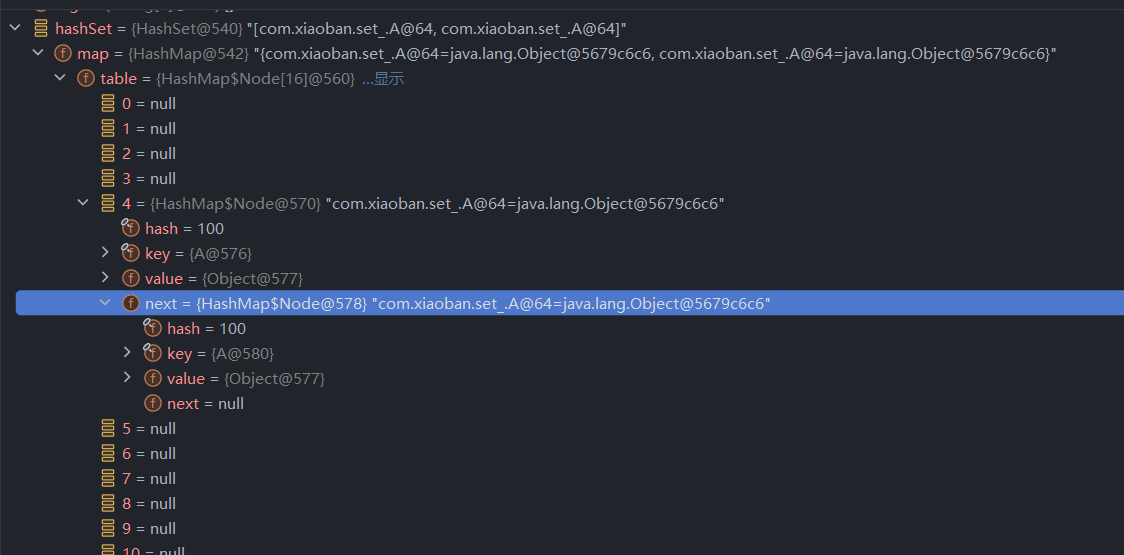
同理,添加第三个元素,可以看到第三个元素被添加到了第二个元素的next位置

以此类推,一直添加到第八个元素,

因为前面我们重写了hashCode(),使其固定返回一个值,所以所有数据的hash值都相同,自然都被分配到了4的位置,在这个结点上形成了单链表!现在已经有八个元素了
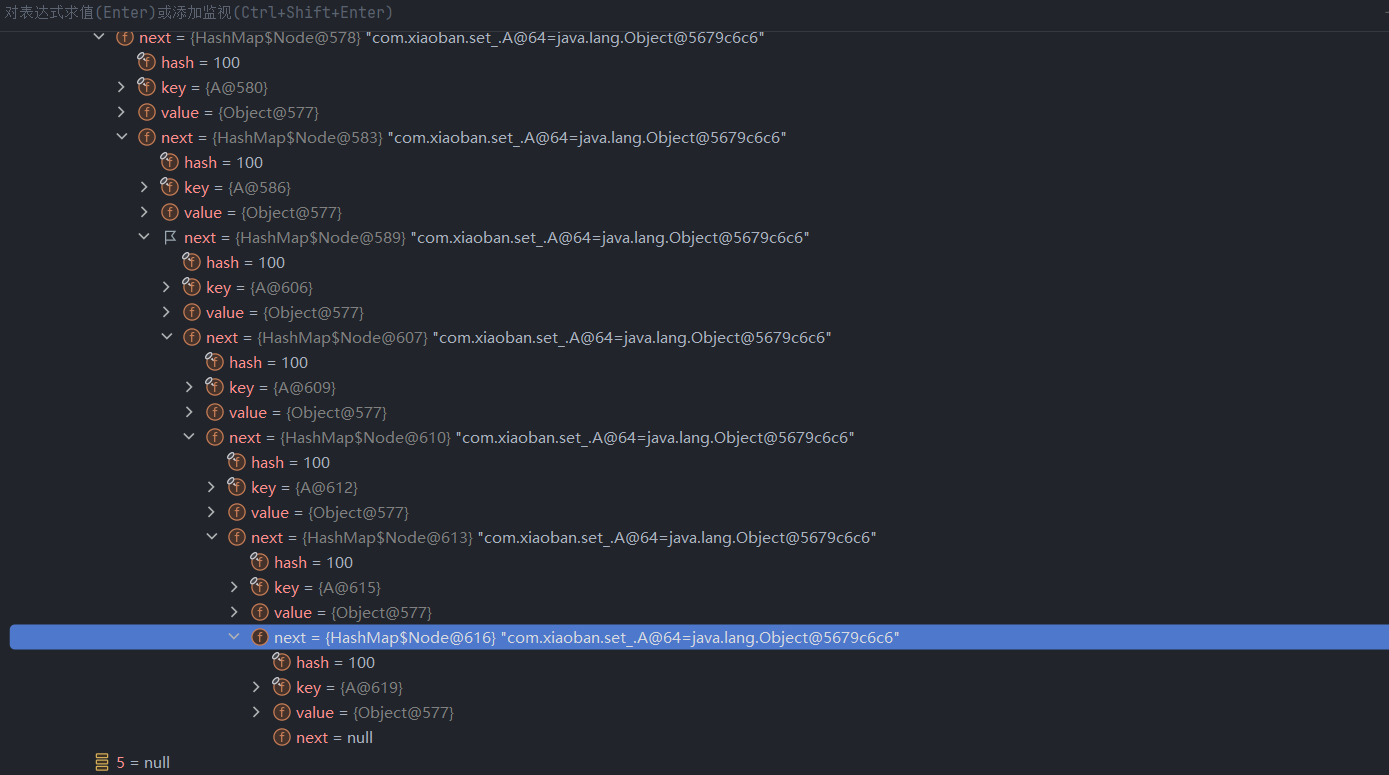
现在,table的长度依然是当初创建时初始化的16,
我们知道,HashSet集合红红黑树化的条件是,单个链表长度超过8,而且,table长度超过64
树化条件
-
链表长度阈值:当链表长度达到8时
-
数组容量阈值:同时当前HashMap的数组(table)长度必须达到64
此时单个链表长度已经是8了,我们再执行两次步进,添加第九个元素,看看会怎样?
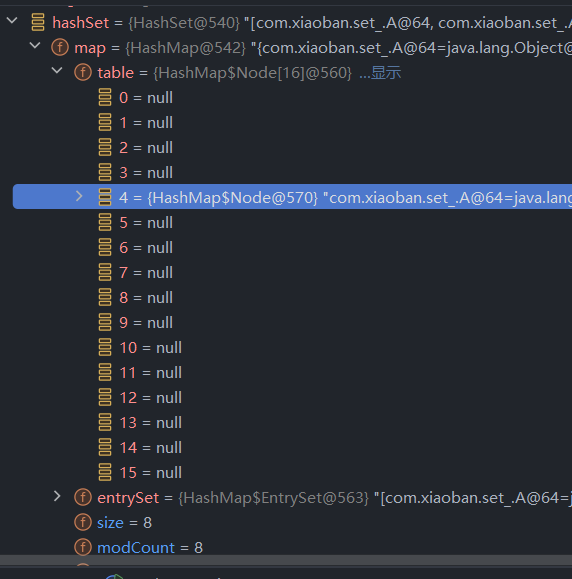
如下图,我们添加了第九个元素,而table的长度变成了32!!!!!
翻了一倍,第九个元素又添加到了第八个元素的next位置。
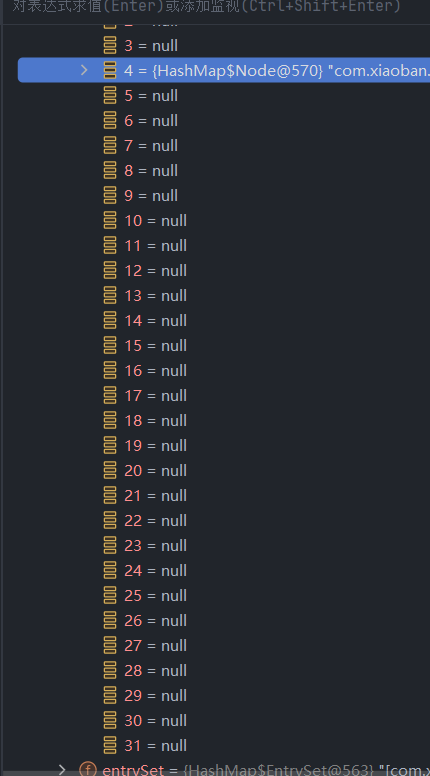
我们继续添加第十个元素!
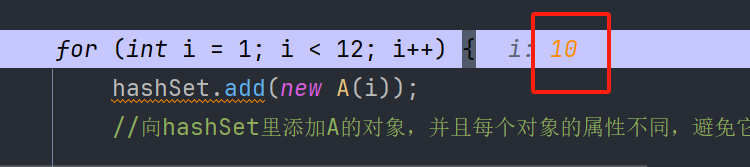
于是,table的长度又翻了一倍,变成了64(0-63)!
所有的元素也从4号结点转移到了36号结点(这是由hash值计算位置的算法导致的,不是重点)
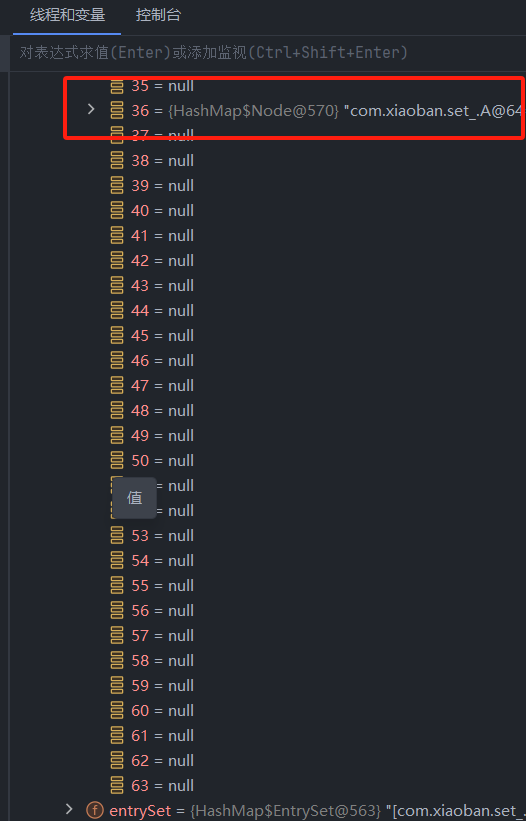
这时
树化条件
-
链表长度阈值:当链表长度达到8时(已经满足)
-
数组容量阈值:同时当前HashMap的数组(table)长度必须达到64(已经达到64)
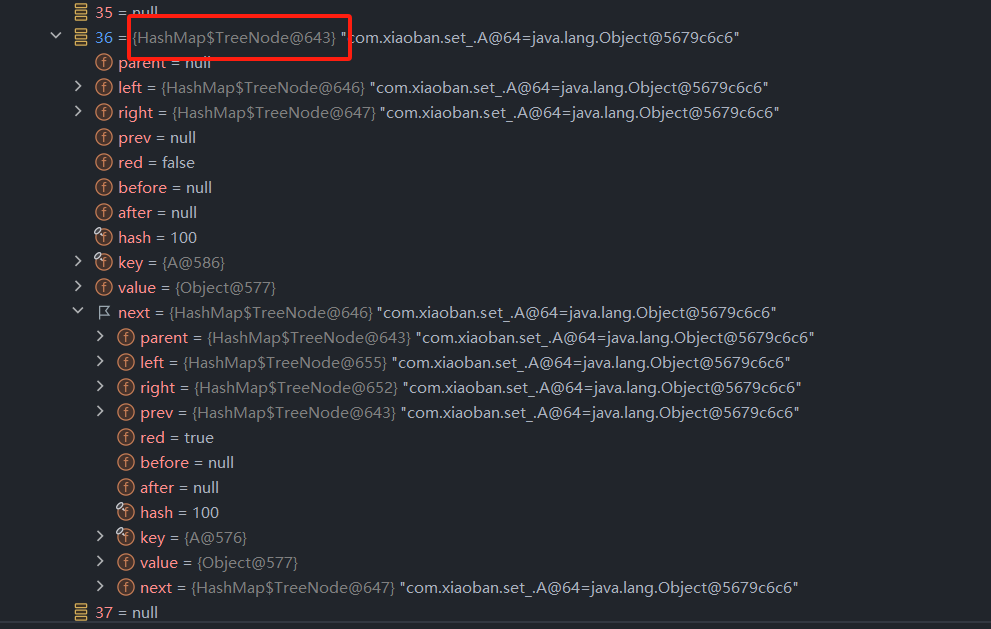
于是我们再添加第十一个数据,见证它的树化!
如下图,这个位置由Node变为了TreeNode!
结点下面的属性也变成了树节点的属性!
树化成功!
2.总结,树化的条件和过程
树化条件
-
链表长度阈值:当链表长度达到8时
-
数组容量阈值:同时当前HashMap的数组(table)长度必须达到64
如果链表长度达到8但数组长度不足64,HashMap会优先进行扩容(resize)而不是树化。
树化过程
-
链表转树:当满足上述两个条件时,HashMap会将链表转换为红黑树
-
遍历链表节点,创建对应的TreeNode节点
-
按照红黑树的规则构建树结构
-
-
树退化为链表:
-
当树节点数减少到6时,红黑树会退化为链表
-
这个阈值(6)比树化阈值(8)小,避免了频繁的树化和退化
-
源码分析
// HashMap中的树化相关代码
final void treeifyBin(Node<K,V>[] tab, int hash) {int n, index; Node<K,V> e;// 如果数组为空或长度小于64,优先扩容if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)resize();// 否则进行树化else if ((e = tab[index = (n - 1) & hash]) != null) {TreeNode<K,V> hd = null, tl = null;do {// 将普通Node转换为TreeNodeTreeNode<K,V> p = replacementTreeNode(e, null);if (tl == null)hd = p;else {p.prev = tl;tl.next = p;}tl = p;} while ((e = e.next) != null);if ((tab[index] = hd) != null)// 将TreeNode链表转换为红黑树hd.treeify(tab);}
}为什么需要树化
Java 8引入树化机制主要是为了解决哈希冲突严重时链表过长导致的性能下降问题:
-
链表查找时间复杂度:O(n)
-
红黑树查找时间复杂度:O(log n)
当哈希函数设计不佳或恶意攻击导致大量元素落入同一个桶时,树化能保证较好的性能。
![已解决:PermissionError: [Errno 13] Permission denied: ‘xxx‘](http://pic.xiahunao.cn/nshx/已解决:PermissionError: [Errno 13] Permission denied: ‘xxx‘)

之springboot+vue项目接入deepseekAPI)

)

)