Redis SCAN 命令的详细介绍
以下是 Redis SCAN 命令的详细介绍,结合其核心特性、使用场景及底层原理进行综合说明:
工作原理图 :
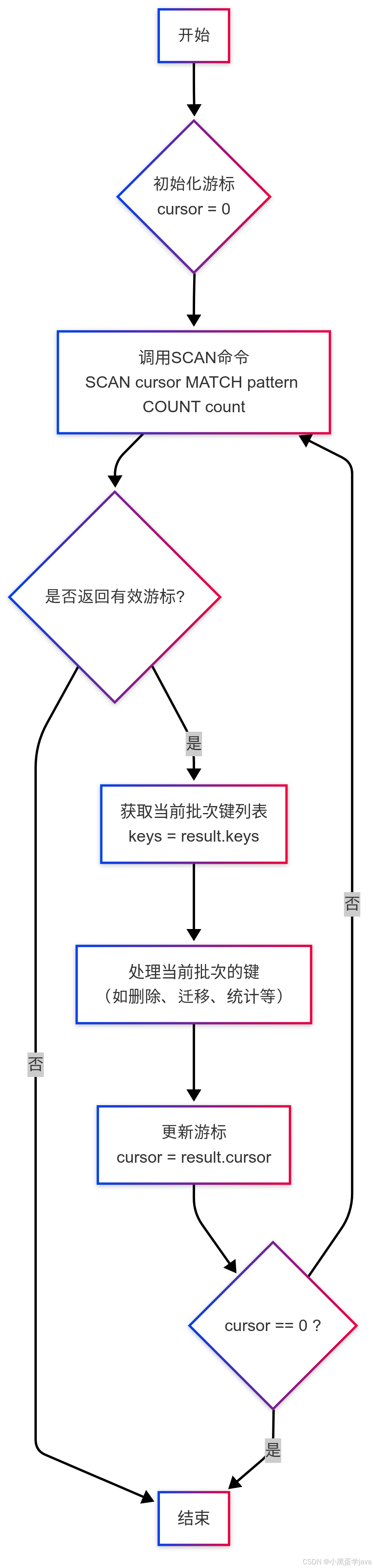
一、核心特性
-
非阻塞式迭代
- 通过游标(Cursor) 分批次遍历键,避免一次性全量扫描阻塞主线程。
- 每次迭代仅返回少量数据(默认约 10 个键),分散服务器压力。
-
弱一致性保证
- 迭代过程中若键被修改(新增/删除),可能导致重复或遗漏。
- 采用快照机制,但无法保证强一致性,需业务层处理重复数据。
-
支持模式匹配与类型过滤
-
MATCH 参数支持通配符(如user:*)过滤键名。 -
TYPE 参数(Redis 6.0+)可指定键类型(如hash、string)。
-
二、命令语法与参数
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]
- **
cursor**
初始值为0,后续使用前次返回的新游标。当游标返回0 时,迭代结束。 - **
COUNT**
建议单次返回的键数量(默认 10),但实际结果可能多于或少于该值。
(例:COUNT 1000 提示 Redis 尝试每批返回约 1000 个键) 。
三、底层原理
-
高位进位加法遍历
- 通过二进制高位进位顺序遍历字典槽(Slot),避免扩容/缩容导致的数据遗漏或重复。
- 例如:从
0000 →1000 →0100 →1100,确保新旧哈希表遍历顺序连续。
-
字典扩容与渐进式 Rehash
- 扩容时新旧哈希表共存,
SCAN 会同时遍历两个表,保证数据完整性。 - 缩容可能导致部分键被重复扫描,需客户端去重。
- 扩容时新旧哈希表共存,
四、使用场景
-
生产环境大数据量遍历
- 替代
KEYS 命令,避免因全量扫描导致服务阻塞。 - 示例:遍历百万级用户会话键(
session:*)进行清理。
- 替代
-
数据结构专用迭代
-
SSCAN(集合)、HSCAN(哈希)、ZSCAN(有序集合)支持按类型迭代元素。
-
-
模糊查询与分页
- 结合
MATCH 实现模糊匹配,利用 COUNT 近似分页控制返回量。
- 结合
五、注意事项
-
重复键处理
- 迭代期间键空间变动可能导致重复结果,需客户端去重。
-
COUNT 参数优化
- 根据数据规模调整
COUNT 值(如 1000~10000),平衡网络往返次数与单次负载。
- 根据数据规模调整
-
弱一致性的影响
- 不适用于需精确统计的场景(如实时计数),建议改用其他方案(如维护索引集合)。
使用案例:
从redis中取出数据同步到后台的其他持久化数据库 demo 这种分批扫描的方法可以避免一次返回大量 key 而导致 Redis 阻塞,同时可以根据需要对每批数据进行处理
package com.example.scan;/*** 描述: 从 Redis 批量获取暂存数据并持久化到数据库。通过SCAN分批拉取数据,确保系统稳定性* 1. 循环获取指定开头的key* 2. 判断key 的数据类型* 3. 对不同的数据类型做相应的处理* 4. 这里模拟如果是string 同步到数据库 其他只是简单的打印 后续可以根据业务场景的不通 做不同的处理* @author ZHOUXIAOYUE* @date 2025/4/21 10:20*/import redis.clients.jedis.Jedis;
import redis.clients.jedis.ScanParams;
import redis.clients.jedis.ScanResult;import java.util.List;
import java.util.Map;
import java.util.Set;public class RedisDataMigration {public static void main(String[] args) {// 初始化 Jedis 客户端Jedis jedis = new Jedis("localhost", 6379);// SCAN 命令参数设置// count 参数表示每次扫描大概处理多少条数据,这里设置为 100ScanParams scanParams = new ScanParams().match("user:*").count(100);// 如果需要,可以通过 match 设置键模式// scanParams.match("temp:*");String cursor = "0";do {// 执行 SCAN 命令ScanResult<String> scanResult = jedis.scan(cursor, scanParams);List<String> keys = scanResult.getResult();cursor = scanResult.getCursor();// 模拟持久化到数据库的操作keys.forEach(key -> {// 获取 key 的数据类型String type = jedis.type(key);System.out.println("Processing key: " + key + ",类型为:" + type);switch (type) {case "string":// 如果是字符串类型,直接调用 get 方法String strValue = jedis.get(key);System.out.println("String value: " + strValue);persistDataToDB(key, strValue);break;case "list":// 如果是列表类型,通过 lrange 获取所有列表元素List<String> listValue = jedis.lrange(key, 0, -1);System.out.println("List value: " + listValue);break;case "set":// 如果是集合类型,通过 smembers 获取所有成员Set<String> setValue = jedis.smembers(key);System.out.println("Set value: " + setValue);break;case "zset":// 如果是有序集合类型,通过 zrange 获取所有元素(默认按分数从小到大排序)Set<String> zsetValue = jedis.zrange(key, 0, -1);System.out.println("ZSet value: " + zsetValue);break;case "hash":// 如果是 Hash 类型,通过 hgetAll 获取所有键值对Map<String, String> hashValue = jedis.hgetAll(key);System.out.println("Hash value: " + hashValue);break;default:// 对于未知类型或其他类型的值,可以在这里处理System.out.println("Unknown type for key: " + key);break;}});// 可以适当休眠,避免对 Redis 服务器产生太大压力try {Thread.sleep(100);} catch (InterruptedException e) {Thread.currentThread().interrupt();System.out.println("Interrupted: " + e.getMessage());}} while (!"0".equals(cursor)); // cursor 为 "0" 时表示遍历结束jedis.close();System.out.println("数据迁移完成。");}/*** 模拟持久化数据到数据库** @param key Redis 的键* @param value Redis 的值*/private static void persistDataToDB(String key, String value) {// 此处仅作模拟,可替换为真实的数据库持久化操作System.out.println("持久化数据 - key: " + key + ", value: " + value);// 例如:// myDatabase.save(new DataEntity(key, value));}
}
总结
| 场景 | 推荐方案 | 避免方案 |
|---|---|---|
| 生产环境遍历海量键 | SCAN+ 合理COUNT值 | KEYS命令 |
| 精确统计或强一致性需求 | 维护索引集合/Lua 脚本 | 依赖SCAN结果 |
| 分页查询 | SCAN+MATCH+COUNT | 单次全量加载 |
最佳实践:
- 优先使用
SCAN 替代KEYS,并在客户端实现去重逻辑。 - 结合
TYPE 参数(Redis 6.0+)减少无效遍历。




)

)