这个主要原因其实和字符集有关,不同字符集下会不一样
历史原因的Oralce中
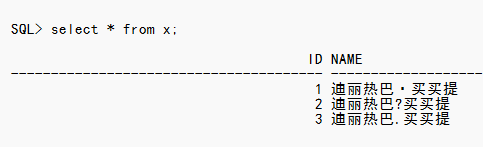
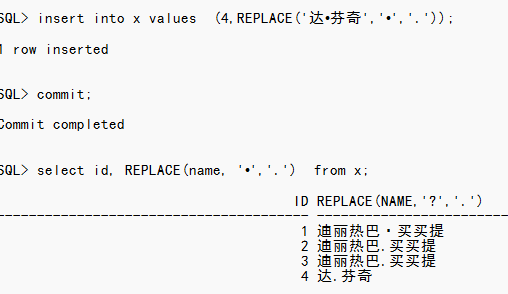
有人问我他遇到一个问题,就是醒目录入后有乱码的出现。而出现乱码的地方是维族的名字中间的 •。比如迪丽热巴·迪力木拉提 。
实验如下
注意1这条数据是用标准的点。而2这里的这个点其实是不标准的。不是字符集中的。写入可以写入。而3这条数据是我输入的英文输入法下的句号。

最后输出的结果是:
可以看出3条都是不一样的。而第二条直接是乱码。这就是开发同学反馈的问题。
那这三个分别是怎么来的?
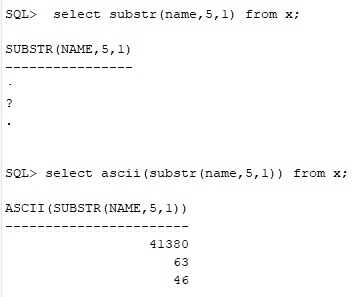
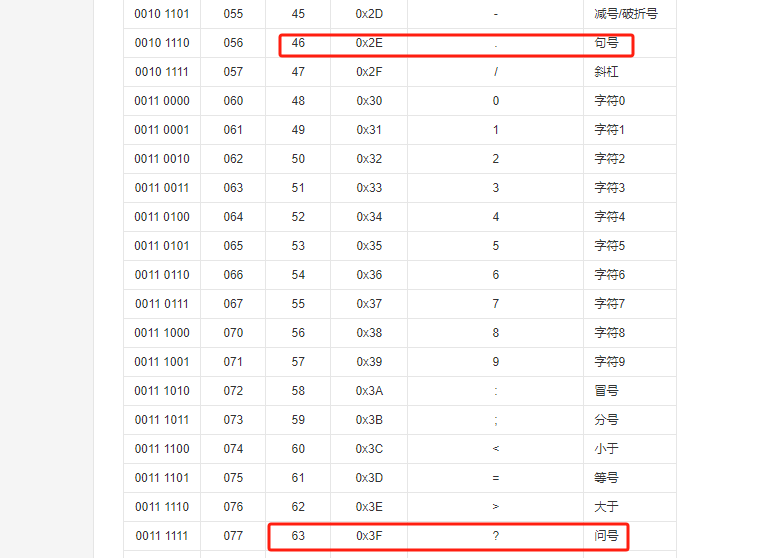
对照编码表可以看到 46是句号,而63就是问号(因为无法识别,存储进来就有问题了)。
那么怎么解决呢?
转换读
对于已知的乱码符号进行转换
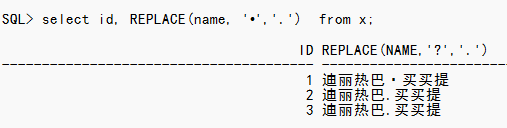
这种属于亡羊补牢的做法。
我本人更加建议是在写入时候控制好。因为不能前面任意写入(注意这里是写入不是输入),输入要统一。之前有一个系统输入企业名称。
有的是 XX(中国)
有的是XX(中国)
最终在数据库中为了找得到,就是要把全角半角的都去查,把给整个字段上套上函数。无论等号左边还是右边。这样的结果就是索引失效,全表扫描。
转换写
其实录入时候你可以运行他自由输入,但是写入时候要程序转换为统一的。我之前做公安系统的时候就是页面输入后,点击保存的时候,全部转换成统一的全角格式。(其实只要统一一种约定俗成就行)
例如这样:
而以上的问题在UTF8这上没有出现。拿一个MySQL的数据库实验。






