一、前言
我们上一篇已经讲了 DeepSeek技术架构解析:MoE混合专家模型
这一篇我们来说一说DeepSeek的创新之一:MLA多头潜在注意力。
MLA主要通过优化KV-cache来减少显存占用,从而提升推理性能。我们知道这个结论之前,老周带大家一起梳理一下从MHA、MQA、GQA到MLA的演变历程,并着重介绍一下MLA的设计思路。
DeepSeek这次的破圈,主要的创新之一:Multi-head Latent Attention架构(MLA),作为对Grouped-Query Attention(GQA)的颠覆性升级,成功突破大模型推理效率的"不可能三角"。
技术演化三部曲:
- 全量时代:传统多头注意力(MHA)凭借完整的参数交互保证精度,却背负着O(n²)的显存消耗枷锁
- 精简革命:多查询注意力(MQA)通过共享键值对实现算力解放,但过度压缩导致知识表征瓶颈
- 平衡之道:分组查询注意力(GQA)创新性引入分组机制,在效率与性能间走出第三条道路
MLA的破局智慧:
MLA架构的突破性在于引入"潜在注意力"概念:通过动态构建隐空间投影矩阵,在保持GQA分组优势的同时,实现了三大跃升:
- 隐性知识蒸馏:构建可学习的潜在注意力模板,突破固定分组的模式局限
- 跨头参数复用:开发跨注意力头的参数共享协议,降低30%以上显存占用
- 自适应计算路由:根据输入复杂度动态分配计算资源,推理速度提升2.8倍
二、共享KV优化显存方法
2.1 MHA
MHA (多头注意力机制 Multi-Head Attention)是 Transformer 架构的核心组件,首次提出于论文 《Attention is All You Need》。其核心思想是通过并行化多组注意力头,增强模型对复杂语义模式的学习能力。每个注意力头独立捕捉输入序列的不同特征,最终将结果拼接以形成综合表征。
数学形式:
给定输入序列 a 1 , a 2 , … , a l \mathbf{a}_1, \mathbf{a}_2, \ldots, \mathbf{a}_l a1,a2,…,al( a i ∈ R d \mathbf{a}_i \in \mathbb{R}^d ai∈Rd),MHA 的流程如下:
-
拆分多头
输入向量被划分为 h h h 个子向量:
a i = [ a i ( 1 ) , a i ( 2 ) , … , a i ( h ) ] \mathbf{a}_i = [\mathbf{a}_i^{(1)}, \mathbf{a}_i^{(2)}, \ldots, \mathbf{a}_i^{(h)}] ai=[ai(1),ai(2),…,ai(h)] -
单头注意力计算
每个子向量通过独立的参数矩阵映射为 Query、Key、Value,并计算注意力:
a i ( s ) = Attention ( a i ( s ) , k z i ( s ) , v z i ( s ) ) = ∑ t ≤ i exp ( a i ( s ) k t ( s ) ⊤ ) v t ( s ) ∑ t ≤ i exp ( a i ( s ) k t ( s ) ⊤ ) \mathbf{a}_i^{(s)} = \text{Attention}\left(\mathbf{a}_i^{(s)}, k_{zi}^{(s)}, v_{zi}^{(s)}\right) = \frac{\sum_{t \leq i} \exp\left(\mathbf{a}_i^{(s)} k_t^{(s)\top}\right) v_t^{(s)}}{\sum_{t \leq i} \exp\left(\mathbf{a}_i^{(s)} k_t^{(s)\top}\right)} ai(s)=Attention(ai(s),kzi(s),vzi(s))=∑t≤iexp(ai(s)kt(s)⊤)∑t≤iexp(ai(s)kt(s)⊤)vt(s)- 参数映射:
a i ( s ) = a i W Q ( s ) , k i ( s ) = a i W K ( s ) , v i ( s ) = a i W V ( s ) \mathbf{a}_i^{(s)} = \mathbf{a}_i W_Q^{(s)}, \quad k_i^{(s)} = \mathbf{a}_i W_K^{(s)}, \quad v_i^{(s)} = \mathbf{a}_i W_V^{(s)} ai(s)=aiWQ(s),ki(s)=aiWK(s),vi(s)=aiWV(s)
其中 W Q ( s ) , W K ( s ) ∈ R d × d k W_Q^{(s)}, W_K^{(s)} \in \mathbb{R}^{d \times d_k} WQ(s),WK(s)∈Rd×dk, W V ( s ) ∈ R d × d v W_V^{(s)} \in \mathbb{R}^{d \times d_v} WV(s)∈Rd×dv,通常 d k = d v = d / h d_k = d_v = d/h dk=dv=d/h。
- 参数映射:
典型配置:
| 模型 | 输入维度 d d d | 头数 h h h | 单头维度 d k / d v d_k/d_v dk/dv |
|---|---|---|---|
| LLAMA2-7B | 4096 | 32 | 128 |
| LLAMA2-70B | 8192 | 64 | 128 |
KV Cache 与优化技术:
在自回归生成任务(逐词生成)中:
- KV Cache 机制:已生成的 Token 对应的 Key-Value 对会被缓存,避免重复计算。例如,生成第 t + 1 t+1 t+1 个 Token 时,直接复用前 t t t 个 Token 的缓存结果。
- 后续优化技术:
- MOA(Memory-Optimized Attention)
- GOA(Grouped-Query Attention)
- MLA(Multi-Layer Attention)
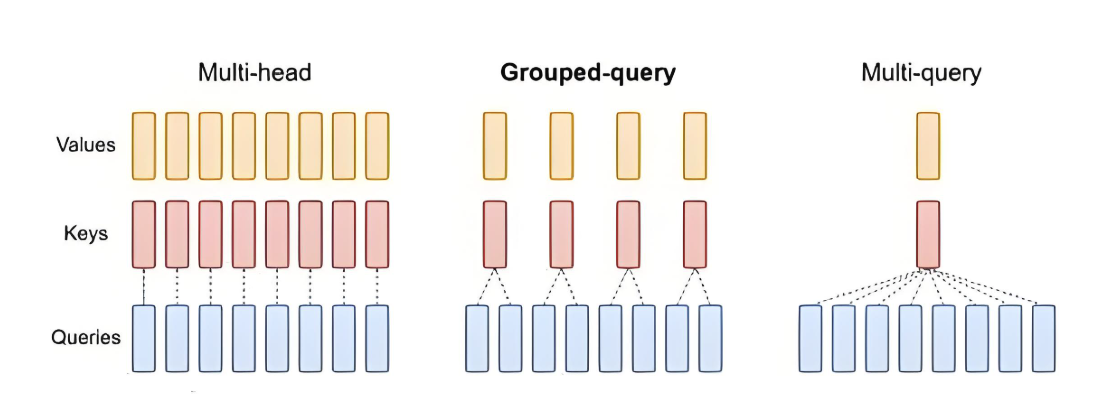
核心目标:在减少 KV Cache 内存占用的同时,尽可能保持模型性能。
关键优势:
- 并行化计算:多头设计允许并行处理不同语义特征。
- 灵活性:通过调整头数和维度,平衡模型容量与计算效率。
- 推理加速:KV Cache 机制显著提升长序列生成速度。
2.2 MHA的瓶颈
2.2.1 显存资源的有限性与动态分配
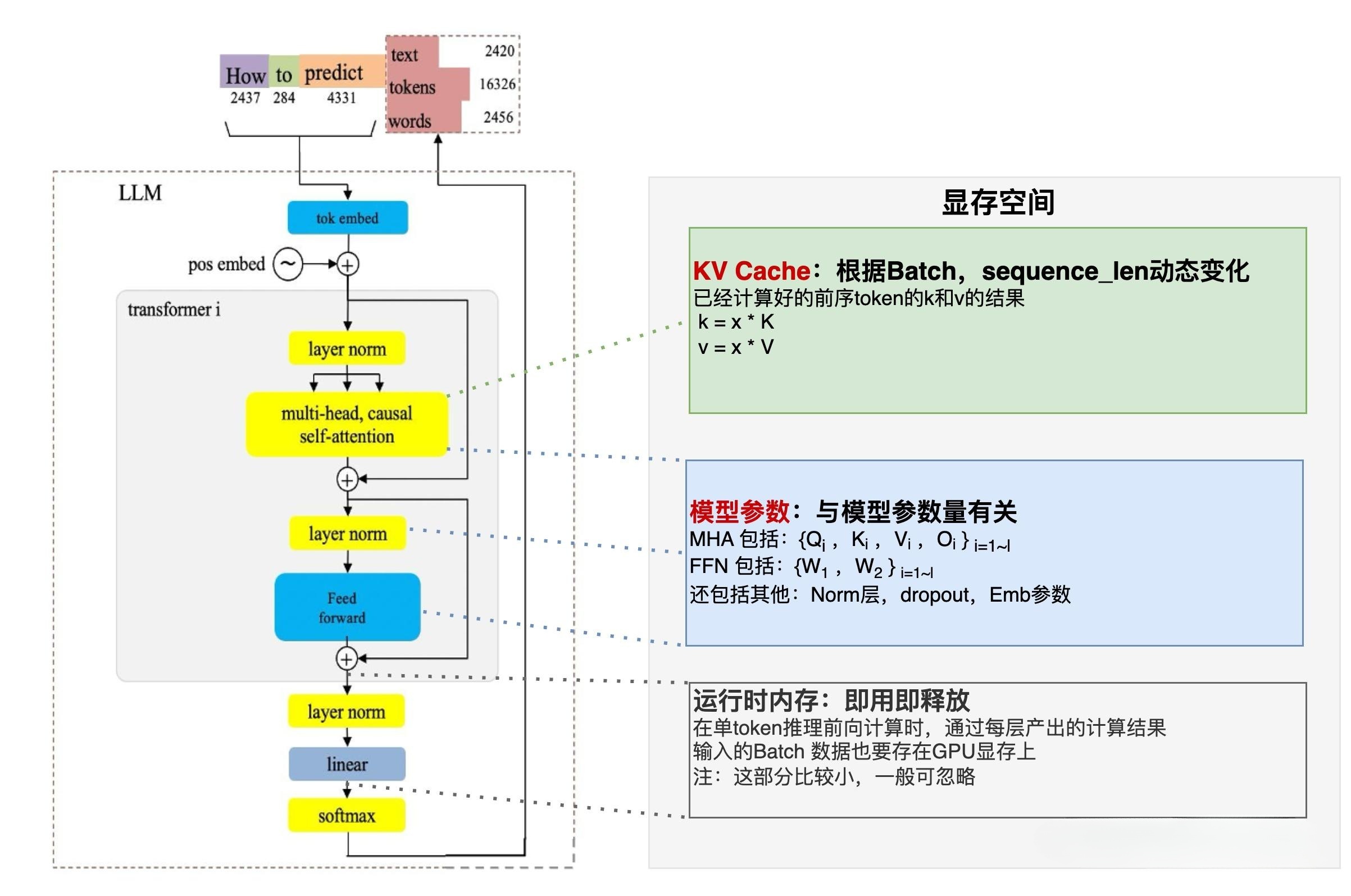
在大型语言模型(LLM)的推理过程中,GPU显存是核心资源瓶颈。显存主要分为两部分:
- 静态占用:存放模型参数和前向传播所需的激活值(Activation),其大小由模型结构决定,选定模型后即为固定值。
- 动态占用:存放KV Cache,其大小与输入序列长度(Context Length)呈线性增长。当处理长上下文任务(如长文本生成)时,KV Cache可能占据显存的主导地位,甚至超过单卡或多卡的总显存容量。
2.2.2 部署效率与通信带宽的制约
在实际部署中,需遵循以下原则:
- 设备内优先:尽可能在单卡或单机(多卡)内完成推理,避免跨设备部署。
- 通信带宽层级:
- 卡内带宽(如H100的SRAM与HBM间带宽达3TB/s)
- 卡间带宽(通过NVLink互联,约数百GB/s)
- 机间带宽(通过网络,通常不足100GB/s)
由于“木桶效应”,跨设备部署会导致性能受限于最低层级的通信带宽。例如,即使单卡H100的SRAM带宽极高,但对于长上下文任务,KV Cache的动态增长仍可能迫使模型跨卡部署,从而引入卡间通信延迟,显著拖慢推理速度。

2.2.3 降低KV Cache的核心目标
- 支持更长上下文:通过压缩KV Cache,可在单卡显存限制内处理更长的输入序列(如从4K Token扩展到16K Token)。
- 提升吞吐量:在相同显存容量下,减少KV Cache占用可支持更大的批量(Batch Size),从而提高单位时间的推理吞吐量。
- 降低成本:减少对多卡或多机的依赖,避免因通信开销导致的额外延迟和硬件成本。
要想更详细地了解这个问题,读者可以进一步阅读《FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness》、《A guide to LLM inference and performance》、《LLM inference speed of light》等论文或文章。
2.3 MQA
2.3.1 核心概念
MQA(多查询注意力机制 Multi-Query Attention)是一种减少KV Cache占用的经典方法,最早提出于2019年论文《Fast Transformer Decoding: One Write-Head is All You Need》。其核心思想是让所有注意力头(Head)共享同一组Key(K)和Value(V),从而显著降低显存中KV Cache的存储需求。MQA在LLM广泛应用前便已受到关注,体现了优化推理效率的长期研究价值。
2.3.2 数学形式
MQA通过简化多头注意力(MHA)的键值映射实现显存优化。给定输入序列 x i x_i xi,其计算流程如下:
-
共享键值映射
所有注意力头共享相同的Key和Value矩阵:
k i = x i W K ∈ R d k , W K ∈ R d × d k k_i = x_i W_K \in \mathbb{R}^{d_k}, \quad W_K \in \mathbb{R}^{d \times d_k} ki=xiWK∈Rdk,WK∈Rd×dk
v i = x i W V ∈ R d v , W V ∈ R d × d v v_i = x_i W_V \in \mathbb{R}^{d_v}, \quad W_V \in \mathbb{R}^{d \times d_v} vi=xiWV∈Rdv,WV∈Rd×dv -
独立查询映射
每个头仍保留独立的Query映射矩阵:
q t ( s ) = x t W Q ( s ) ∈ R d k , W Q ( s ) ∈ R d × d k q^{(s)}_t = x_t W_Q^{(s)} \in \mathbb{R}^{d_k}, \quad W_Q^{(s)} \in \mathbb{R}^{d \times d_k} qt(s)=xtWQ(s)∈Rdk,WQ(s)∈Rd×dk -
注意力计算
各头的注意力输出为:
o t ( s ) = Attention ( q t ( s ) , k < t , v < t ) = ∑ i < t exp ( q t ( s ) k i ) v i ∑ i < t exp ( q t ( s ) k i ) o^{(s)}_t = \text{Attention}\left(q^{(s)}_t, k_{<t}, v_{<t}\right) = \frac{\sum_{i < t} \exp\left(q^{(s)}_t k_i\right) v_i}{\sum_{i < t} \exp\left(q^{(s)}_t k_i\right)} ot(s)=Attention(qt(s),k<t,v<t)=∑i<texp(qt(s)ki)∑i<texp(qt(s)ki)vi -
输出拼接
最终输出由多头结果拼接而成:
o t = [ o t ( 1 ) , o t ( 2 ) , ⋯ , o t ( h ) ] o_t = \left[ o^{(1)}_t, o^{(2)}_t, \cdots, o^{(h)}_t \right] ot=[ot(1),ot(2),⋯,ot(h)]
2.3.3 技术优势与局限性
✅ 核心优势:
-
显存占用大幅降低
- KV Cache减少至原MHA的 1 h \frac{1}{h} h1( h h h为头数)。例如,若原始模型有32头,MQA的KV Cache仅为原来的3.1%。
- 显存节省直接支持更长上下文输入或更大批量推理。
-
参数量优化
- Key和Value的映射矩阵从多头独立变为共享,模型参数量减少近一半。
- 节省的参数量可用于增强其他模块(如FFN/GLU),平衡模型性能。
⚠️ 潜在局限:
- 表达能力受限
- 共享Key/Value可能削弱多头捕捉多样化语义特征的能力。
- 效果补偿依赖训练
- 部分任务精度损失需通过调整训练策略(如更长时间微调)弥补。
2.3.4 典型应用模型
| 模型 | 说明 |
|---|---|
| PaLM | Google的大规模语言模型系列 |
| StarCoder | 代码生成专用模型 |
| Geminir | 多模态生成模型 |
2.3.5 小结
MQA通过共享键值映射,以极低的工程复杂度实现了KV Cache的显著压缩。尽管可能牺牲部分模型灵活性,但其在显存效率和部署成本上的优势使其成为LLM推理优化的关键技术之一。后续技术(如MOA、GOA)均受MQA启发,进一步探索了精度与效率的平衡。
2.4 GQA
2.4.1 核心概念
GQA( 分组查询注意力机制Grouped-Query Attention)是一种平衡KV Cache压缩与模型性能的注意力机制,提出于论文《GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints》。其核心思想是将多头注意力(MHA)分组,每组共享同一对Key(K)和Value(V),既减少显存占用,又保留一定语义多样性。GQA可视为MHA与MQA(Multi-Query Attention)的过渡方案:
- 当组数 g = h g = h g=h 时,退化为标准MHA(无压缩)。
- 当组数 g = 1 g = 1 g=1 时,退化为MQA(压缩率最高)。
- 当 1 < g < h 1 < g < h 1<g<h 时,灵活权衡显存占用与模型效果。
2.4.2 数学形式
给定输入序列 x i x_i xi,GQA 的计算流程如下:
-
分组键值映射
将 h h h 个注意力头分为 g g g 组(需满足 g ∣ h g \mid h g∣h),每组共享独立的Key和Value矩阵:
k t ( g ′ ) = x i W k ( g ′ ) ∈ R d k , W k ( g ′ ) ∈ R d × d k k_{t}^{(g')} = x_i W_k^{(g')} \in \mathbb{R}^{d_k}, \quad W_k^{(g')} \in \mathbb{R}^{d \times d_k} kt(g′)=xiWk(g′)∈Rdk,Wk(g′)∈Rd×dk
v t ( g ′ ) = x i W v ( g ′ ) ∈ R d v , W v ( g ′ ) ∈ R d × d v v_{t}^{(g')} = x_i W_v^{(g')} \in \mathbb{R}^{d_v}, \quad W_v^{(g')} \in \mathbb{R}^{d \times d_v} vt(g′)=xiWv(g′)∈Rdv,Wv(g′)∈Rd×dv
其中 g ′ = ⌈ s ⋅ g / h ⌉ g' = \lceil s \cdot g / h \rceil g′=⌈s⋅g/h⌉ 表示第 s s s 个头所属的组编号( ⌈ ⋅ ⌉ \lceil \cdot \rceil ⌈⋅⌉ 为上取整符号)。 -
独立查询映射
每个头保留独立的Query映射矩阵:
q t ( s ) = x i W q ( s ) ∈ R d k , W q ( s ) ∈ R d × d k q_t^{(s)} = x_i W_q^{(s)} \in \mathbb{R}^{d_k}, \quad W_q^{(s)} \in \mathbb{R}^{d \times d_k} qt(s)=xiWq(s)∈Rdk,Wq(s)∈Rd×dk -
注意力计算
第 s s s 个头的注意力输出为:
o t ( s ) = Attention ( q t ( s ) , k < t ( g ′ ) , v < t ( g ′ ) ) = ∑ i < t exp ( q t ( s ) k i ( g ′ ) ) v i ( g ′ ) ∑ i < t exp ( q t ( s ) k i ( g ′ ) ) o_t^{(s)} = \text{Attention}\left(q_t^{(s)}, k_{<t}^{(g')}, v_{<t}^{(g')}\right) = \frac{\sum_{i < t} \exp\left(q_t^{(s)} k_i^{(g')}\right) v_i^{(g')}}{\sum_{i < t} \exp\left(q_t^{(s)} k_i^{(g')}\right)} ot(s)=Attention(qt(s),k<t(g′),v<t(g′))=∑i<texp(qt(s)ki(g′))∑i<texp(qt(s)ki(g′))vi(g′) -
输出拼接
最终输出由多头结果拼接而成:
o t = [ o t ( 1 ) , o t ( 2 ) , ⋯ , o t ( h ) ] o_t = \left[ o_t^{(1)}, o_t^{(2)}, \cdots, o_t^{(h)} \right] ot=[ot(1),ot(2),⋯,ot(h)]
2.4.3 技术优势与局限性
✅ 核心优势
-
显存占用优化
- KV Cache 压缩至原MHA的 g h \frac{g}{h} hg。例如,当 h = 64 h=64 h=64 且 g = 8 g=8 g=8 时,显存占用仅为原来的12.5%。
- 支持更长上下文(如从4K扩展至32K Token)或更大批量推理。
-
灵活性与性能平衡
- 通过调整组数 g g g,在显存压缩与模型效果间灵活权衡。
- 相比MQA,保留更多语义多样性,任务精度损失更小。
-
硬件部署友好
- 组数 g g g 常与单机GPU卡数对齐(如 g = 8 g=8 g=8 对应8卡部署),减少跨卡通信开销。
⚠️ 潜在局限
- 实现复杂度增加
- 分组逻辑需额外计算资源管理,可能引入工程复杂度。
- 训练依赖
- 需针对性调整训练策略(如分组初始化)以充分发挥性能。
2.4.4 典型应用模型
| 模型 | 说明 | 组数 g g g |
|---|---|---|
| LLAMA2-70B | Meta开源的大规模语言模型 | 8 |
| LLAMA3系列 | Meta最新一代开源模型 | 8 |
| TigerBot | 深度求索科技的中英双语模型 | 8 |
| DeepSeek-V1 | 深度求索的高效长文本模型 | 8 |
| Yi系列 | 零一万物开发的多模态模型 | 8 |
| ChatGLM2/3 | 智谱AI的中英双语对话模型(实际为GQA) | 2 |
2.4.5 小结
GQA通过分组共享键值映射,在MHA与MQA之间建立了可调节的显存优化路径。其核心价值在于:
- 显存效率:显著降低长上下文任务的部署门槛。
- 硬件适配:组数与GPU卡数对齐,最大化利用卡内带宽,减少通信延迟。
- 效果保障:相比MQA,更适用于对语义多样性要求较高的任务。
GQA已成为当前主流大模型(如LLAMA系列)的标配技术,并与MOA、MLA等优化方案共同推动LLM的高效落地。
2.5 MLA
2.5.1 核心概念
MLA(多头潜在注意力机制 Multi-head Latent Attention)是DeepSeek-V2提出的兼顾KV Cache压缩与模型表达能力的新型注意力机制。其核心思想是通过低秩投影与恒等变换技巧,在保持GQA(Grouped-Query Attention)显存效率的同时增强语义多样性,并兼容RoPE(旋转位置编码)。MLA被视为GQA的进阶版本,实现了“训练时增强能力,推理时压缩显存”的优化目标。
2.5.2 数学形式与关键技术
2.5.2.1 低秩投影与恒等变换
MLA通过两步操作实现显存优化:
-
训练阶段:
- 输入向量 a i a_i ai 经过低秩投影生成中间变量 c i c_i ci:
c i = a i W c ∈ R d c , W c ∈ R d × d c c_i = a_i W_c \in \mathbb{R}^{d_c}, \quad W_c \in \mathbb{R}^{d \times d_c} ci=aiWc∈Rdc,Wc∈Rd×dc - 对 c i c_i ci 进行多组线性变换生成独立的Key和Value:
k ( s ) = c i W k ( s ) , v ( s ) = c i W v ( s ) k^{(s)} = c_i W_k^{(s)}, \quad v^{(s)} = c_i W_v^{(s)} k(s)=ciWk(s),v(s)=ciWv(s)
- 输入向量 a i a_i ai 经过低秩投影生成中间变量 c i c_i ci:
-
推理阶段:
- 利用矩阵乘法的结合律,将Key和Value的投影矩阵合并到Query的映射中:
Q ( s ) K ( s ) ⊤ = ( a i W q ( s ) ) ( c i W k ( s ) ) ⊤ = a i ( W q ( s ) W k ( s ) ⊤ ) c i ⊤ Q^{(s)} K^{(s)\top} = (a_i W_q^{(s)}) (c_i W_k^{(s)})^\top = a_i (W_q^{(s)} W_k^{(s)\top}) c_i^\top Q(s)K(s)⊤=(aiWq(s))(ciWk(s))⊤=ai(Wq(s)Wk(s)⊤)ci⊤ - 通过恒等变换,仅需缓存低秩中间变量 c i c_i ci,而非完整的Key/Value,显存占用降至GQA级别。
- 利用矩阵乘法的结合律,将Key和Value的投影矩阵合并到Query的映射中:
2.5.2.2 兼容RoPE的混合设计
为解决RoPE(旋转位置编码)与MLA的冲突,MLA采用分维度混合编码:
- 低秩维度( d c d_c dc):不加RoPE,用于保留恒等变换能力。
- 高秩维度( d r d_r dr):新增RoPE编码,所有注意力头共享Key的RoPE维度。
公式示例:
Q ( s ) = [ a i W q 1 ( s ) , a i W q 2 ( s ) R i ] , K ( s ) = [ c i W k ( s ) , c i W k r R i ] Q^{(s)} = [a_i W_{q1}^{(s)}, a_i W_{q2}^{(s)} R_i], \quad K^{(s)} = [c_i W_k^{(s)}, c_i W_{kr} R_i] Q(s)=[aiWq1(s),aiWq2(s)Ri],K(s)=[ciWk(s),ciWkrRi]
其中 R i R_i Ri 为RoPE矩阵, d r d_r dr 通常设为64(总维度 d c + d r = 512 + 64 d_c + d_r = 512 + 64 dc+dr=512+64)。
2.5.3 技术优势与局限性
✅ 核心优势
-
显存效率
- KV Cache大小与GQA相同(仅需缓存 c i c_i ci),远低于MHA。
- 支持更长的上下文输入(如DeepSeek-V2支持128K Token)。
-
模型能力增强
- 通过低秩投影矩阵学习更复杂的键值映射关系,弥补GQA的表达能力损失。
-
硬件友好性
- Generation阶段(逐词生成)的带宽压力显著降低,推理速度提升。
⚠️ 潜在局限
- 计算量增加
- Prefill阶段(首Token生成)的计算复杂度略高于GQA。
- 工程复杂度
- 需额外实现分维度RoPE编码与矩阵合并逻辑。
2.5.4 典型应用:DeepSeek-V2
| 参数 | 值 | 说明 |
|---|---|---|
| 隐藏层维度 | 5120 | 模型容量基础维度 |
| 低秩维度 d c d_c dc | 512 | 控制KV Cache大小的核心参数 |
| RoPE维度 d r d_r dr | 64 | 新增位置编码维度 |
| 头数 h h h | 128 | 通过增加头数提升模型能力 |
2.5.5 与GQA/MQA对比
| 特性 | MQA | GQA | MLA |
|---|---|---|---|
| KV Cache压缩率 | 1 / h 1/h 1/h | g / h g/h g/h | d c / d d_c/d dc/d(≈1/10) |
| 表达能力 | 最低 | 中等 | 最高 |
| 兼容RoPE | 直接兼容 | 直接兼容 | 需混合维度设计 |
| 典型应用 | PaLM, StarCoder | LLAMA2/3, ChatGLM | DeepSeek-V2 |
2.5.6 小结
MLA通过低秩投影与分维度RoPE设计,在以下方面实现突破:
- 显存效率:保持GQA级别的KV Cache压缩率(约原MHA的1/10)。
- 模型能力:通过可学习的投影矩阵增强语义多样性,接近MHA效果。
- 硬件适配:优化Generation阶段的带宽瓶颈,提升长序列推理速度。
MLA代表了注意力机制从“粗暴压缩”向“精细化权衡”的演进方向,为LLM的高效部署提供了新的技术路径。
2.6 旋转位置编码(RoPE)在注意力机制中的应用
2.6.1 核心概念
旋转位置编码(Rotary Position Embedding, RoPE)是一种将绝对位置信息融入注意力机制的技术。其核心思想是通过旋转矩阵对查询(Query)和键(Key)进行位置相关的变换,使模型能够隐式学习相对位置关系。相比于传统的位置编码方法,RoPE无需显式添加位置偏置,直接通过矩阵运算实现位置感知。
2.6.2 数学形式对比
- 不带旋转位置编码
对于第 i i i 个 Token 的查询 q i q_i qi 和第 j j j 个 Token 的键 k j k_j kj,其注意力得分计算为:
q i k j ⊤ = h i W Q ( c j K V W U K ) ⊤ = h i W Q W U K ⊤ c j K V ⊤ q_i k_j^\top = \mathbf{h}_i W^Q \left(\mathbf{c}_j^{KV} W^{UK}\right)^\top = \mathbf{h}_i W^Q W^{UK\top} \mathbf{c}_j^{KV\top} qikj⊤=hiWQ(cjKVWUK)⊤=hiWQWUK⊤cjKV⊤
其中:
-
h i \mathbf{h}_i hi 为第 i i i 个 Token 的隐藏状态
-
c j K V \mathbf{c}_j^{KV} cjKV 为第 j j j 个 Token 的键值中间表示
-
W Q , W U K W^Q, W^{UK} WQ,WUK 为线性投影矩阵
此时位置信息未显式编码,模型需通过数据学习隐含的位置关系。
- 带旋转位置编码(RoPE)
引入旋转矩阵 R i R_i Ri 和 R j R_j Rj(与位置 i , j i,j i,j 相关),查询和键的计算变为:
q i R i ( k j R j ) ⊤ = h i W Q R i ( c j K V W U K R j ) ⊤ = h i W Q R i R j ⊤ W U K ⊤ c j K V ⊤ q_i R_i (k_j R_j)^\top = \mathbf{h}_i W^Q R_i \left(\mathbf{c}_j^{KV} W^{UK} R_j\right)^\top = \mathbf{h}_i W^Q R_i R_j^\top W^{UK\top} \mathbf{c}_j^{KV\top} qiRi(kjRj)⊤=hiWQRi(cjKVWUKRj)⊤=hiWQRiRj⊤WUK⊤cjKV⊤
关键特性:
- 位置相关性:旋转矩阵 R i R_i Ri 和 R j R_j Rj 与 Token 的绝对位置 i , j i,j i,j 绑定。
- 不可合并性:由于 R i R j ⊤ R_i R_j^\top RiRj⊤ 无法简化为与位置无关的固定矩阵,位置信息被显式保留。
- 相对位置编码:通过 R i R j ⊤ R_i R_j^\top RiRj⊤ 的旋转差异,模型可隐式捕捉 i i i 与 j j j 的相对位置关系。
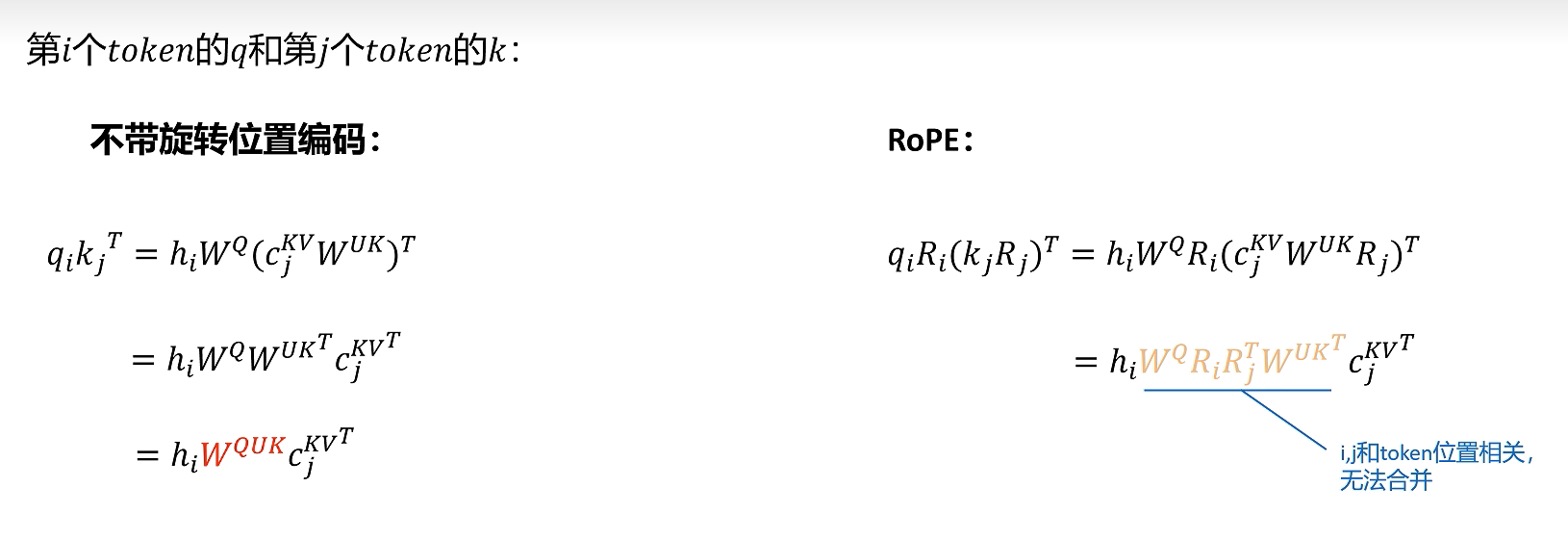
RoPE破坏了推理时矩阵提前融合的方案,DeepSeek最终想到的解决方案是:给Q、K向量增加一些维度来表示位置信息。
2.6.3 小结
RoPE通过旋转矩阵将位置信息编码到注意力机制中,实现了对相对位置关系的隐式建模。其设计平衡了计算效率与表达能力,已成为当前主流大模型(如LLAMA、DeepSeek)的标配技术。后续改进方向可能包括:
- 优化旋转矩阵的计算开销
- 增强对超长序列的泛化能力
三、DeepSeek MLA推导原理
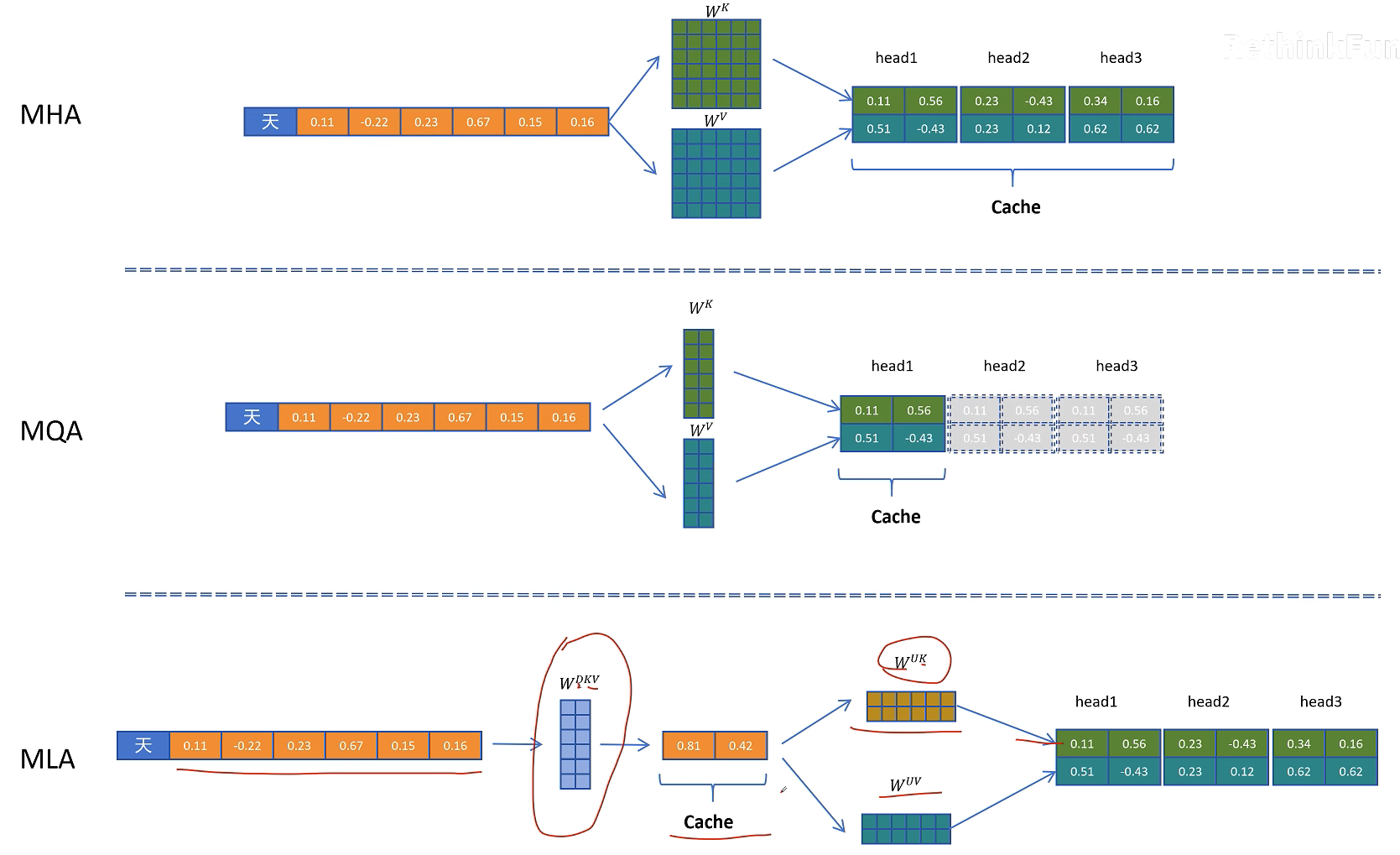
通过 W DKV W^{\text{DKV}} WDKV (D是Down的意思,降维压缩) 参数矩阵,比如之前是6个维度,经过 W DKV W^{\text{DKV}} WDKV 压缩到2维,缓存只需要缓存2维的压缩向量,在进行计算时,要用到真实的K、V向量时,再从K、V压缩向量,通过两个解压矩阵转换成之前的维度就可以了。可以对比上面那张图MLA的缓存量,MLA确实可以减少K-V Cache,但是会影响模型效果吗?

通过这个性能测试报告可以看出,MLA(Multi-head Latent Attention)在保持或提升模型性能的同时,显著降低了KV Cache占用,并优化了参数效率,尤其在大型模型中优势更为突出。
但是K-V Cache的本意是啥呢?它是为了减少推理时对之前token K、V向量计算而产生的。MLA因为缓存的压缩的K-V Cache来减少了K-V Cache的显存占用。但是,在取出缓存后,K、V不能直接使用,还是得经过解压计算才能使用,这不是在推理时又引用了解压这个额外的计算吗?这和K-V Cache的初衷是相悖的。

我们来看下K-V Cache的推理过程:

上面对应标准的MHA,下面对应的是MLA。
我们来说下MLA,通过 W DKV W^{\text{DKV}} WDKV 矩阵进行压缩,然后生成压缩的K、V的隐特征 C KV C^{\text{KV}} CKV ,将 C KV C^{\text{KV}} CKV 存储在K-V Cache。K、V向量通过将压缩的隐特征 C KV C^{\text{KV}} CKV与K向量的解压参数矩阵 W UK W^{\text{UK}} WUK进行相乘,V向量同理。得到当前token可用于注意力计算的K、V向量。
对于之前的token,从K-V Cache里取出压缩的隐特征 C KV C^{\text{KV}} CKV,然后经过K、V向量的解压参数矩阵 W UK W^{\text{UK}} WUK、 W UV W^{\text{UV}} WUV投影,得到可以计算的K、V。
看右面那个推导公式可以发现,对K进行解压操作的矩阵 W UK T W^{\text{UK}^{\text{T}}} WUKT可以和 W Q W^{\text{Q}} WQ矩阵进行融合,这个融合可以在推理之前计算好。这样我们通过矩阵计算的结合律,就可以规避MLA引入的推理时解压隐特征带来的额外计算。
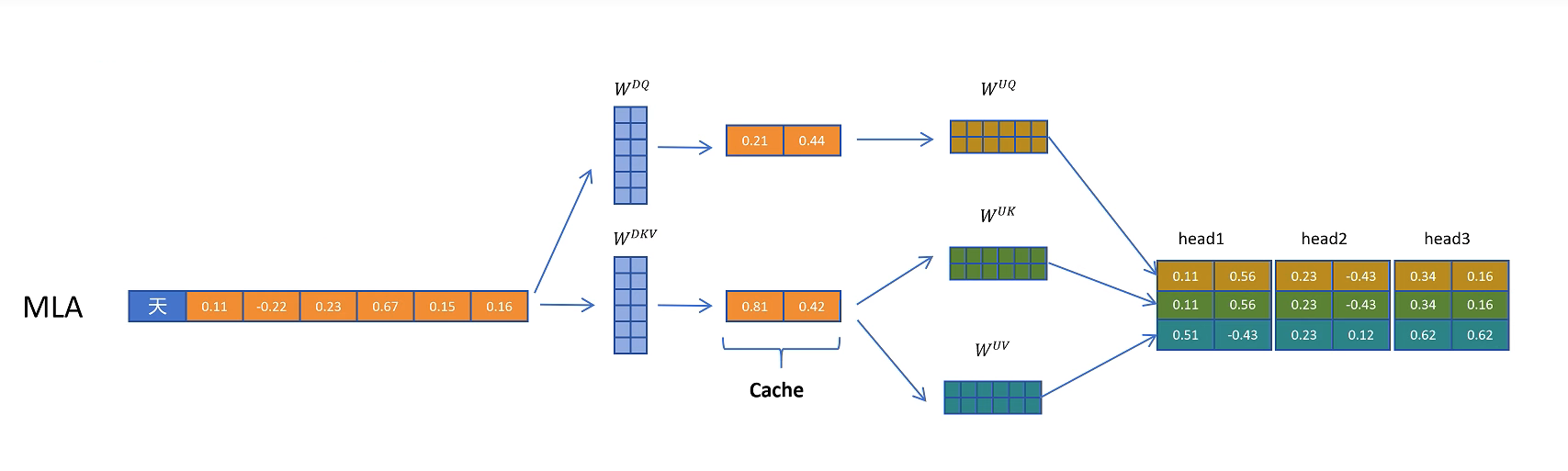
MLA除了对K、V进行了压缩外,还对Q向量进行了压缩,这样的好处是,降低了参数量而且可以提升模型性能。通过 W UQ W^{\text{UQ}} WUQ对Q向量进行了解压,但是Q的隐向量并不需要缓存,只需要换成共用的K-V压缩的隐向量即可。
好了,现在似乎所有问题都解决了。K-V Cache减少了,模型表现还提升了。但是好事多磨,刚才我们一直没有考虑旋转位置编码,也就是上面我介绍的2.6的概念。
我们知道,旋转位置编码需要对每一层的Q、K向量进行旋转,而且,根据token位置的不同,旋转矩阵的参数也不同,这里以第i个token的q和第j个token的k的点积为例:

如果不考虑旋转位置编码,则是我们上面讲的对K进行压缩的矩阵可以和 W Q W^{\text{Q}} WQ 矩阵进行融合成 W QUK W^{\text{QUK}} WQUK 。但是如果考虑旋转位置编码,因为不同位置的旋转矩阵也不同,这里我们用 R i R_i Ri和 R j R_j Rj来表示第i个和第j个token位置的旋转矩阵。可以发现如果增加了旋转矩阵,i,j和token位置相关,无法合并。所以它破坏了之前推理时矩阵提前融合的方案。
不过DeepSeek给出了这个场景的解决方案,就是给Q、K向量额外增加一些维度来表示位置信息。对于Q向量,通过 W QR W^{\text{QR}} WQR为每一个头生成一些原始特征。(其中Q代表Q向量,R代表旋转位置编码),然后通过旋转位置编码增加位置信息生成带位置信息的特征拼接到每个带注意力头的Q向量。对于K向量,通过 W KR W^{\text{KR}} WKR矩阵生成一个头,共享的特征,然后通过旋转位置编码增加位置信息复制到多个头共享位置信息。
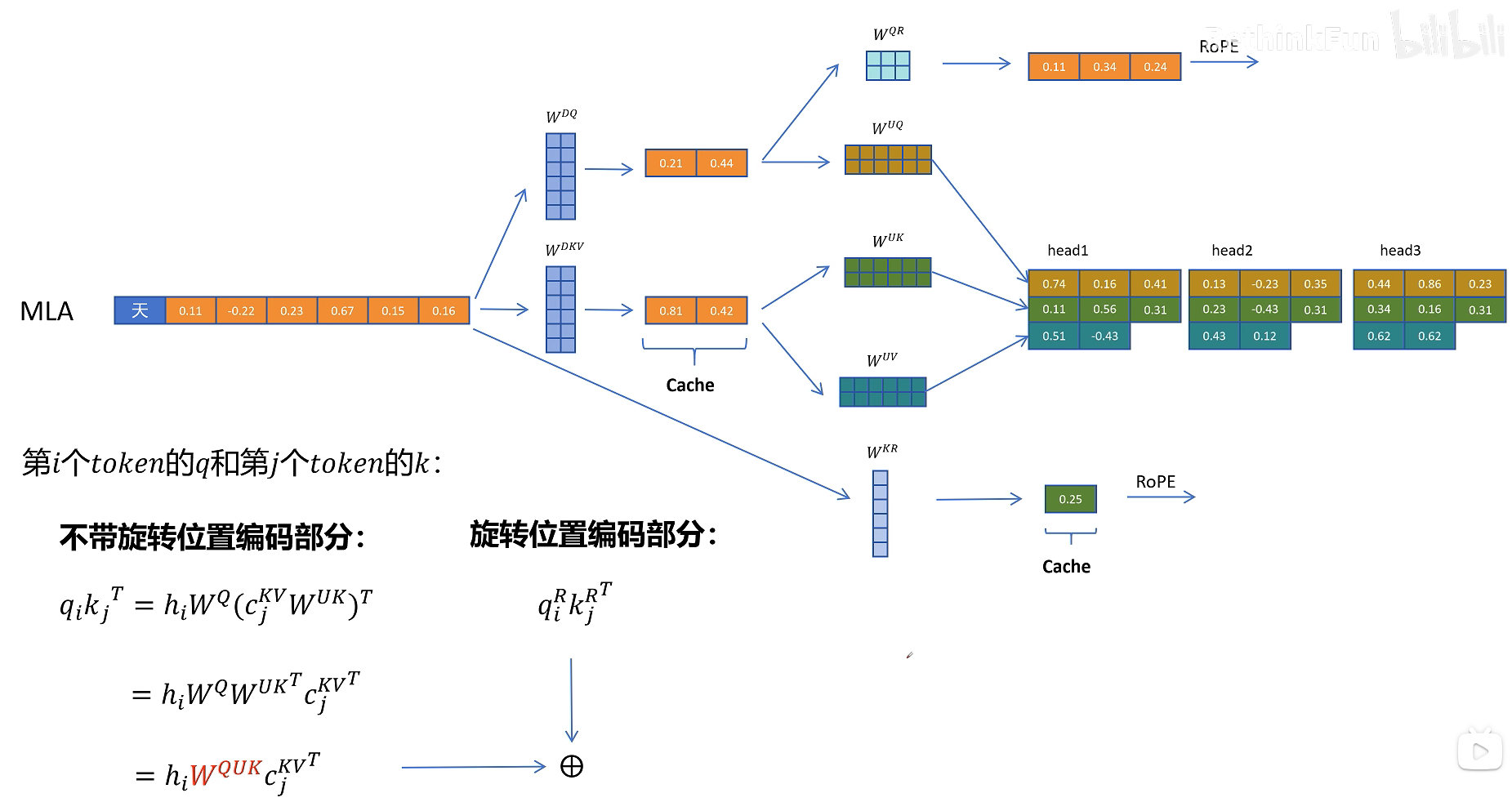
不带旋转位置编码部分与旋转位置编码部分进行点积,这样就得到了即兼容旋转位置编码压缩K-V Cache的方案,同时也可以提升模型的性能。

最后,我们来回顾下MLA论文里的架构图。首先是输入token特征h,通过它生成压缩后的KV特征,然后压缩后的KV特征解压成多头的k、v特征;从输入h生成多头共享的带旋转位置编码的 k R k^{\text{R}} kR,再把 k R k^{\text{R}} kR和 k C k^{\text{C}} kC进行合并形成最终带位置编码的k向量;再看q向量这边,解压生成多头的 c Q c^{\text{Q}} cQ向量,然后从压缩的 q C q^{\text{C}} qC向量生成多头的带位置编码的 q R q^{\text{R}} qR,然后 q R q^{\text{R}} qR与 q C q^{\text{C}} qC进行合并生成最终带位置编码的q向量。最后q、k、v向量进行多头注意力计算(其中图中带阴影部分的需要缓存)。

:回调函数与qsort函数的奥秘)
)

