在默认情况下,一个Pod在哪个Node节点上运行,是由Scheduler组件采用相应的算法计算出来的,这个过程是不受人工控制的。但是在实际使用中,这并不满足的需求,因为很多情况下,我们想控制某些Pod到达某些节点上,那么应该怎么做呢?这就要求了解kubernetes对Pod的调度规则,kubernetes提供了四大类调度方式:
- 自动调度:运行在哪个节点上完全由Scheduler经过一系列的算法计算得出
- 定向调度:NodeName、NodeSelector
- 亲和性调度:NodeAffinity、PodAffinity、PodAntiAffinity
- 污点(容忍)调度:Taints、Toleration
定向调度
定向调度,指的是利用在pod上声明nodeName或者nodeSelector,以此将Pod调度到期望的node节点上。注意,这里的调度是强制的,这就意味着即使要调度的目标Node不存在,也会向上面进行调度,只不过pod运行失败而已。
NodeName
NodeName用于强制约束将Pod调度到指定的Name的Node节点上。这种方式,其实是直接跳过 Scheduler的调度逻辑,直接将Pod调度到指定名称的节点。
创建一个pod-nodename.yaml文件
apiVersion: v1
kind: Pod
metadata:name: pod-nodenamenamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1nodeName: k8s-worker01 # 指定调度到k8s-worker01节点上
#创建Pod
[root@master ~]# kubectl create -f pod-nodename.yaml
pod/pod-nodename created#查看Pod调度到NODE属性,确实是调度到了node1节点上
[root@master ~]# kubectl get pod pod-nodename -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodename 1/1 Running 0 56s 10.244.1.87 k8s-worker01 ...... # 接下来,删除pod,修改nodeName的值为k8s-worker03(并没有k8s-worker03节点)
[root@master ~]# kubectl delete -f pod-nodename.yaml
pod "pod-nodename" deleted
[root@master ~]# vim pod-nodename.yaml
[root@master ~]# kubectl create -f pod-nodename.yaml
pod/pod-nodename created
#再次查看,发现已经向Node3节点调度,但是由于不存在k8s-worker03节点,所以pod无法正常运行
[root@master ~]# kubectl get pods pod-nodename -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodename 0/1 Pending 0 6s <none> k8s-worker03 ...... NodeSelector
NodeSelector用于将pod调度到添加了指定标签的node节点上。它是通过kubernetes的labelselector机制实现的,也就是说,在pod创建之前,会由scheduler使用MatchNodeSelector调度策略进 行label匹配,找出目标node,然后将pod调度到目标节点,该匹配规则是强制约束。
示例:
[root@master ~]# kubectl label nodes k8s-worker1 nodeenv=pro #首先分别为node节点添加标签
node/k8s-worker01 labeled[root@master ~]# kubectl label nodes k8s-worker2 nodeenv=test
node/k8s-worker02 labeled创建一个pod-nodeselector.yaml
apiVersion: v1
kind: Pod
metadata:name: pod-nodeselectornamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1nodeSelector: nodeenv: pro # 指定调度到具有nodeenv=pro标签的节点上
#创建Pod
[root@master ~]# kubectl create -f pod-nodeselector.yaml
pod/pod-nodeselector created#查看Pod调度到NODE属性,确实是调度到了node1节点上
[root@master ~]# kubectl get pods pod-nodeselector -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodeselector 1/1 Running 0 47s 100.119.84.73 k8s-worker01
......# 接下来,删除pod,修改nodeSelector的值为nodeenv: hhh(不存在打有此标签的节点)
[root@master ~]# kubectl delete -f pod-nodeselector.yaml
pod "pod-nodeselector" deleted
[root@master ~]# vim pod-nodeselector.yaml
[root@master ~]# kubectl create -f pod-nodeselector.yaml
pod/pod-nodeselector created#再次查看,发现pod无法正常运行,Node的值为none
[root@master ~]# kubectl get pods -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
pod-nodeselector 0/1 Pending 0 2m20s <none> <none># 查看详情,发现node selector匹配失败的提示
[root@master ~]# kubectl describe pods pod-nodeselector -n dev
.......
Events:Type Reason Age From Message---- ------ ---- ---- -------Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are
available: 3 node(s) didn't match node selector.Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are
available: 3 node(s) didn't match node selector.亲和性调度
亲和性调度在NodeSelector的基础之上进行了扩展,可以通过配置的形式,实现优先选择满足条件的Node进行调度,如果没有,也可以调度到不满足条件的节点上,使调度更加灵活。
Affinity主要分为三类:
- nodeAffinity(node亲和性): 以node为目标,解决pod可以调度到哪些node的问题
- podAffinity(pod亲和性) : 以pod为目标,解决pod可以和哪些已存在的pod部署在同一个拓扑域中的问题
- podAntiAffinity(pod反亲和性) : 以pod为目标,解决pod不能和哪些已存在pod部署在同一个拓扑域中的问题
NodeAffinity
pod.spec.affinity.nodeAffinityrequiredDuringSchedulingIgnoredDuringExecution Node节点必须满足指定的所有规则才可
以,相当于硬限制nodeSelectorTerms 节点选择列表matchFields 按节点字段列出的节点选择器要求列表matchExpressions 按节点标签列出的节点选择器要求列表(推荐)key 键values 值operator 关系符 支持Exists, DoesNotExist, In, NotIn, Gt, LtpreferredDuringSchedulingIgnoredDuringExecution 优先调度到满足指定的规则的Node,相当
于软限制 (倾向)preference 一个节点选择器项,与相应的权重相关联matchFields 按节点字段列出的节点选择器要求列表matchExpressions 按节点标签列出的节点选择器要求列表(推荐)key 键values 值operator 关系符 支持In, NotIn, Exists, DoesNotExist, Gt, Ltweight 倾向权重,在范围1-100。关系符的使用说明:
- matchExpressions:- key: nodeenv # 匹配存在标签的key为nodeenv的节点operator: Exists- key: nodeenv # 匹配标签的key为nodeenv,且value是"xxx"或"yyy"的节点operator: Invalues: ["xxx","yyy"]- key: nodeenv # 匹配标签的key为nodeenv,且value大于"xxx"的节点operator: Gtvalues: "xxx"示例:
创建pod-nodeaffinity-required.yaml
apiVersion: v1
kind: Pod
metadata:name: pod-nodeaffinity-requirednamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1affinity: #亲和性设置nodeAffinity: #设置node亲和性requiredDuringSchedulingIgnoredDuringExecution: # 硬限制nodeSelectorTerms:- matchExpressions: # 匹配env的值在["xxx","yyy"]中的标签- key: nodeenvoperator: Invalues: ["xxx","yyy"]# 创建pod
[root@master ~]# kubectl create -f pod-nodeaffinity-required.yaml
pod/pod-nodeaffinity-required created
# 查看pod状态 (运行失败)
[root@master ~]# kubectl get pods pod-nodeaffinity-required -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodeaffinity-required 0/1 Pending 0 16s <none> <none> ......
# 查看Pod的详情
# 发现调度失败,提示node选择失败
[root@master ~]# kubectl describe pod pod-nodeaffinity-required -n dev
......Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are
available: 3 node(s) didn't match node selector.Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are
available: 3 node(s) didn't match node selector.
#接下来,停止pod
[root@master ~]# kubectl delete -f pod-nodeaffinity-required.yaml
pod "pod-nodeaffinity-required" deleted
# 修改文件,将values: ["xxx","yyy"]------> ["pro","yyy"]
[root@master ~]# vim pod-nodeaffinity-required.yaml
# 再次启动
[root@master ~]# kubectl create -f pod-nodeaffinity-required.yaml
pod/pod-nodeaffinity-required created
# 此时查看,发现调度成功,已经将pod调度到了node1上
[root@master ~]# kubectl get pods pod-nodeaffinity-required -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ......
pod-nodeaffinity-required 1/1 Running 0 11s 10.244.1.89
node1 ......NodeAffinity规则设置的注意事项:
- 1 如果同时定义了nodeSelector和nodeAffinity,那么必须两个条件都得到满足,Pod才能运行在指定的Node上
- 2 如果nodeAffinity指定了多个nodeSelectorTerms,那么只需要其中一个能够匹配成功即可
- 3 如果一个nodeSelectorTerms中有多个matchExpressions ,则一个节点必须满足所有的才能匹配成功
- 4 如果一个pod所在的Node在Pod运行期间其标签发生了改变,不再符合该Pod的节点亲和性需求,则系统将忽略此变化
PodAffinity
首先来看一下 PodAffinity 的可配置项:
pod.spec.affinity.podAffinityrequiredDuringSchedulingIgnoredDuringExecution 硬限制namespaces 指定参照pod的namespacetopologyKey 指定调度作用域labelSelector 标签选择器matchExpressions 按节点标签列出的节点选择器要求列表(推荐)key 键values 值operator 关系符 支持In, NotIn, Exists, DoesNotExist.matchLabels 指多个matchExpressions映射的内容preferredDuringSchedulingIgnoredDuringExecution 软限制podAffinityTerm 选项namespaces topologyKeylabelSelectormatchExpressions key 键values 值operatormatchLabels weight 倾向权重,在范围1-100
topologyKey用于指定调度时作用域,例如:如果指定为kubernetes.io/hostname,那就是以Node节点为区分范围如果指定为beta.kubernetes.io/os,则以Node节点的操作系统类型来区分
创建一个参照Pod,pod-podaffinity-target.yaml
apiVersion: v1
kind: Pod
metadata:name: pod-podaffinity-targetnamespace: devlabels:podenv: pro #设置标签
spec:containers:- name: nginximage: nginx:1.17.1nodeName: node1 # 将目标pod名确指定到node1上# 启动目标pod
[root@master ~]# kubectl create -f pod-podaffinity-target.yaml
pod/pod-podaffinity-target created
# 查看pod状况
[root@master ~]# kubectl get pods pod-podaffinity-target -n dev
NAME READY STATUS RESTARTS AGE
pod-podaffinity-target 1/1 Running 0 4s创建pod-podaffinity-required.yaml
apiVersion: v1
kind: Pod
metadata:name: pod-podaffinity-requirednamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1affinity: #亲和性设置podAffinity: #设置pod亲和性requiredDuringSchedulingIgnoredDuringExecution: # 硬限制- labelSelector:matchExpressions: # 匹配env的值在["xxx","yyy"]中的标签- key: podenvoperator: Invalues: ["xxx","yyy"]topologyKey: kubernetes.io/hostname新Pod必须要与拥有标签nodeenv=xxx或者nodeenv=yyy的pod在同一Node 上,显然现在没有这样pod
# 启动pod
[root@master ~]# kubectl create -f pod-podaffinity-required.yaml
pod/pod-podaffinity-required created
# 查看pod状态,发现未运行
[root@master ~]# kubectl get pods pod-podaffinity-required -n dev
NAME READY STATUS RESTARTS AGE
pod-podaffinity-required 0/1 Pending 0 9s
# 查看详细信息
[root@master ~]# kubectl describe pods pod-podaffinity-required -n dev
......
Events:Type Reason Age From Message---- ------ ---- ---- -------Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are
available: 2 node(s) didn't match pod affinity rules, 1 node(s) had taints that
the pod didn't tolerate.
# 接下来修改 values: ["xxx","yyy"]----->values:["pro","yyy"]
# 意思是:新Pod必须要与拥有标签nodeenv=xxx或者nodeenv=yyy的pod在同一Node上
[root@master ~]# vim pod-podaffinity-required.yaml
# 然后重新创建pod,查看效果
[root@master ~]# kubectl delete -f pod-podaffinity-required.yaml
pod "pod-podaffinity-required" deleted
[root@master ~]# kubectl create -f pod-podaffinity-required.yaml
pod/pod-podaffinity-required created
# 发现此时Pod运行正常
[root@master ~]# kubectl get pods pod-podaffinity-required -n dev
NAME READY STATUS RESTARTS AGE LABELS
pod-podaffinity-required 1/1 Running 0 6s <none>
PodAntiAffinity
创建pod-podantiaffinity-required.yaml
apiVersion: v1
kind: Pod
metadata:name: pod-podantiaffinity-requirednamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1affinity: #亲和性设置podAntiAffinity: #设置pod亲和性requiredDuringSchedulingIgnoredDuringExecution: # 硬限制- labelSelector:matchExpressions: # 匹配podenv的值在["pro"]中的标签- key: podenvoperator: Invalues: ["pro"]topologyKey: kubernetes.io/hostname
新Pod必须要与拥有标签nodeenv=pro的pod不在同一Node上
# 创建pod
[root@master ~]# kubectl create -f pod-podantiaffinity-required.yaml
pod/pod-podantiaffinity-required created
# 查看pod
# 发现调度到了node2上
[root@master ~]# kubectl get pods pod-podantiaffinity-required -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE ..
pod-podantiaffinity-required 1/1 Running 0 30s 10.244.1.96
node2 ..污点和容忍
污点(Taints)
前面的调度方式都是站在Pod的角度上,通过在Pod上添加属性,来确定Pod是否要调度到指定的
Node上,其实我们也可以站在Node的角度上,通过在Node上添加污点属性,来决定是否允许Pod调度过来。
Node被设置上污点之后就和Pod之间存在了一种相斥的关系,进而拒绝Pod调度进来,甚至可以将已经存在的Pod驱逐出去。
污点的格式为: key=value:effect , key和value是污点的标签,effect描述污点的作用,支持如下三个选项:
- PreferNoSchedule:kubernetes将尽量避免把Pod调度到具有该污点的Node上,除非没有其他节点可调度
- NoSchedule:kubernetes将不会把Pod调度到具有该污点的Node上,但不会影响当前Node上已存在的Pod
- NoExecute:kubernetes将不会把Pod调度到具有该污点的Node上,同时也会将Node上已存在的Pod驱离

# 设置污点
kubectl taint nodes node1 key=value:effect
# 去除污点
kubectl taint nodes node1 key:effect-
# 去除所有污点
kubectl taint nodes node1 key-
示例:
#首先要暂停节点2
[root@k8s-worker02 ~]# systemctl stop kubelet.service# 为node1设置污点(PreferNoSchedule)
[root@master ~]# kubectl taint nodes k8s-worker01 tag=openlab:PreferNoSchedule
# 创建pod1
[root@master ~]# kubectl run taint1 --image=nginx:1.17.1 -n dev
[root@master ~]# kubectl get pod -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE taint1 1/1 Running 0 22s 100.119.84.74 k8s-worker01 # 为node1设置污点(取消PreferNoSchedule,设置NoSchedule)
[root@master ~]# kubectl taint nodes k8s-worker01 tag:PreferNoSchedule-
[root@master ~]# kubectl taint nodes k8s-worker01 tag=openlab:NoSchedule
# 创建pod2
[root@master ~]# kubectl run taint2 --image=nginx:1.17.1 -n dev
[root@master ~]# kubectl get pod taint2 -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
taint2 0/1 Pending 0 15s <none> <none> # 为node1设置污点(取消NoSchedule,设置NoExecute)
[root@master ~]# kubectl taint nodes k8s-worker01 tag:NoSchedule-
[root@master ~]# kubectl taint nodes k8s-worker01 tag=openlab:NoExecute# 创建pod3
[root@master ~]# kubectl run taint3 --image=nginx:1.17.1 -n dev
[root@master ~]# kubectl get pod taint3 -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE
taint3 0/1 Pending 0 8s <none> <none> 容忍(Toleration)
上面介绍了污点的作用,我们可以在node上添加污点用于拒绝pod调度上来,但是如果就是想将一个 pod调度到一个有污点的node上去,这时候应该怎么做呢?这就要使用到容忍。
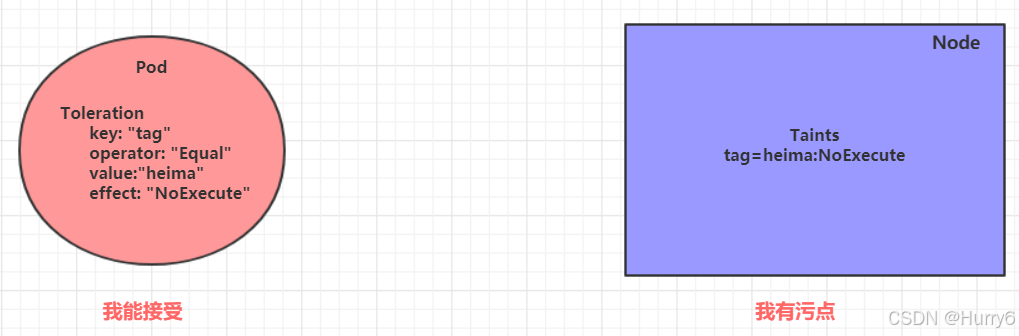
污点就是拒绝,容忍就是忽略,Node通过污点拒绝pod调度上去,Pod通过容忍忽略拒绝
由于已经在节点1上打上了 NoExecute 的污点,此时pod是调度不上去的,可以通过给pod添加容忍,然后将其调度上去
容忍的详细配置:
[root@master ~]# kubectl explain pod.spec.tolerations
......
FIELDS:key # 对应着要容忍的污点的键,空意味着匹配所有的键value # 对应着要容忍的污点的值operator # key-value的运算符,支持Equal和Exists(默认)effect # 对应污点的effect,空意味着匹配所有影响tolerationSeconds # 容忍时间, 当effect为NoExecute时生效,表示pod在Node上的停留时间示例:
创建pod-toleration.yaml
apiVersion: v1
kind: Pod
metadata:name: pod-tolerationnamespace: dev
spec:containers:- name: nginximage: nginx:1.17.1tolerations: # 添加容忍- key: "tag" # 要容忍的污点的keyoperator: "Equal" # 操作符value: "openlab" # 容忍的污点的valueeffect: "NoExecute" # 添加容忍的规则,这里必须和标记的污点规则相同[root@master ~]# kubectl create -f pod-toleration.yaml
pod/pod-toleration created# 添加容忍之后的pod
[root@master ~]# kubectl get pod pod-toleration -n dev -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-toleration 1/1 Running 0 111s 100.119.84.77 k8s-worker01 


