机器学习模型是进行预测和决策的强大工具。但是,构建有效且可靠的模型不仅仅是选择正确的算法或调整超参数;它还与如何准备和评估数据有关。此过程的一个重要步骤是训练-测试拆分。在本文中,我们将探讨训练-测试拆分在机器学习中的重要性、为什么重要、何时执行以及为什么建议在应用各种转换或编码之前拆分数据。
1. 了解 Train-Test 拆分
1.1 什么是 Train-Test Split?
训练-测试拆分是机器学习中的一种基本数据准备技术。它涉及将数据集分为两个子集:训练集和测试集。训练集用于训练机器学习模型,而测试集用于评估其性能。
在监督式机器学习中,使用标记数据作为指导对模型进行训练。然后,该模型从数据中学习模式,并开发一个可用于预测新传入数据的通用版本。但是,我们如何确保该模型能够准确预测看不见的数据呢?这就是训练-测试拆分的概念发挥作用的地方。
训练-测试拆分简单地定义为将我们的数据集划分为训练数据和测试数据,如下图所示。
通常,我们将数据集拆分为不同的比率,例如 80% 的训练数据和 20% 的测试数据,或 70% 的训练数据和 30% 的测试数据,其中较大的部分分配给训练。训练集需要更多数据来确保模型有足够的信息进行学习,同时仍留下足够的测试数据进行无偏评估。
有两种常见的拆分方法:随机或分层。顾名思义,随机拆分会在不考虑目标标签分布的情况下划分数据,如果整个数据集不平衡,这可能会导致子集不平衡。相比之下,分层拆分可确保在训练集和测试集中保持目标标签的分布。
对于时间序列数据,需要一种独特的方法,因为时间序列数据的属性与其他数据集的属性不同。使用顺序拆分时,训练集包含较早的数据点,而测试集包含较晚的数据点。
1.2 为什么 Train-Test Split 很重要?
-
模型评估:测试集充当看不见的真实世界数据的替代品。它允许您评估您的模型在面对新的、以前看不见的数据时可能表现如何。这种评估有助于估计模型的泛化能力。
-
偏差和过拟合检测:当模型在训练数据上表现非常好但在测试数据上表现不佳时,它可能在过度拟合训练数据。训练-测试拆分有助于检测此问题,这可以通过调整模型的复杂性来解决。
-
超参数优化:您可以使用测试集来优化模型的超参数,而不会污染评估。通过此迭代过程,您可以提高模型在处理未见数据时的性能。
2. 什么时候应该执行 train-test split?
训练-测试拆分应在机器学习工作流程的早期执行。这通常是数据收集和预处理后的第一步。拆分在任何数据转换、编码、扩展或特征工程之前完成。原因如下:
(1)数据泄漏预防:
数据预处理步骤(例如特征缩放或编码)涉及基于整个数据集的计算统计数据。如果您在这些转换之后拆分数据,则测试集中的信息可能会泄漏到训练集中。这会损害评估的完整性,因为您的模型在预处理期间已经看到了一些测试数据。
(2)现实的评估:
在预处理之前拆分数据可确保您的评估反映模型在新的、看不见的数据上的性能。它复制了模型遇到以前从未见过的数据的真实场景。
(3)后处理拆分的影响:
在数据预处理后执行 train-test split 可能会导致以下几个问题:
- 数据泄漏:如前所述,来自测试集的信息可能会泄漏到训练集中,从而导致性能估计过于乐观。
- 模型过拟合:模型可能会过度拟合到训练数据,因为它在预处理期间已经看到了测试数据。这可能会导致对新数据的泛化效果不佳。
- 不切实际的评估:评估可能无法反映模型在新的、看不见的数据上的表现,因为预处理步骤已经将其暴露给一些测试数据。
3. 如何避免机器学习陷阱
学习预测函数的参数并在相同的数据上测试它是一个方法论上的错误:一个模型只会重复它刚刚看到的样本的标签,它可能会得到一个完美的分数,但对尚未看到的数据却无法预测任何有用的东西。这种情况被称为过拟合。为了避免这种情况,在执行(有监督的)机器学习实验时,通常的做法是将部分可用数据作为测试集X_test,y_test。下面是模型训练中典型的交叉验证工作流程图。通过网格搜索技术可以确定最佳参数。
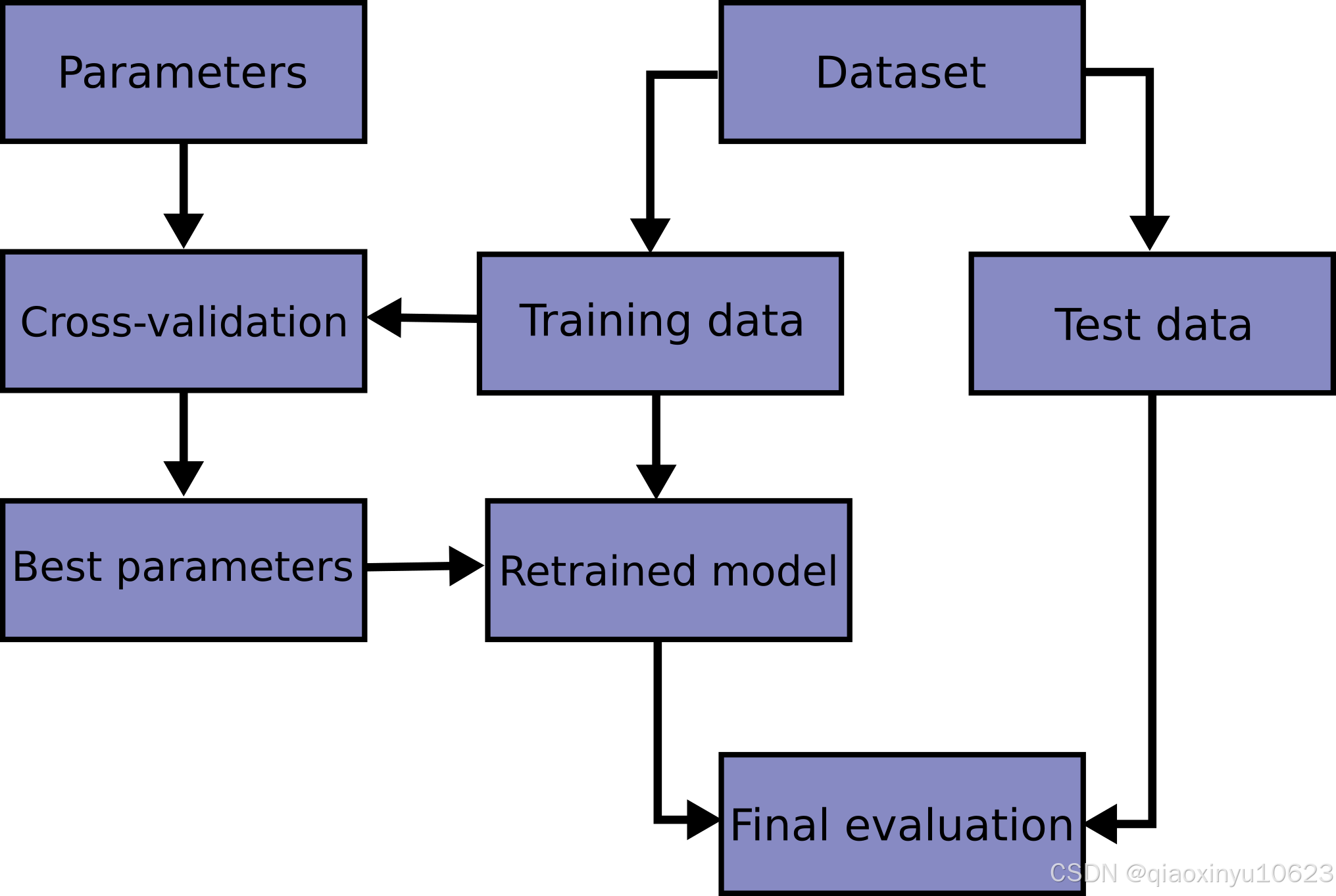
因为可以调整参数,直到估计器达到最佳性能,所以测试集仍然存在过拟合的风险。这样,有关测试集的知识可以“泄漏”到模型中并且评估指标不再报告泛化性能。为了解决这个问题,可以将数据集的另一部分作为所谓的“验证集”:训练在训练集上进行,之后对验证集进行评估,当实验似乎成功时,可以在测试集上进行最终评估。
但是,通过将可用数据划分为三个集合,我们大大减少了可用于学习模型的样本数量,并且结果可能取决于对(训练、验证)集的特定随机选择。
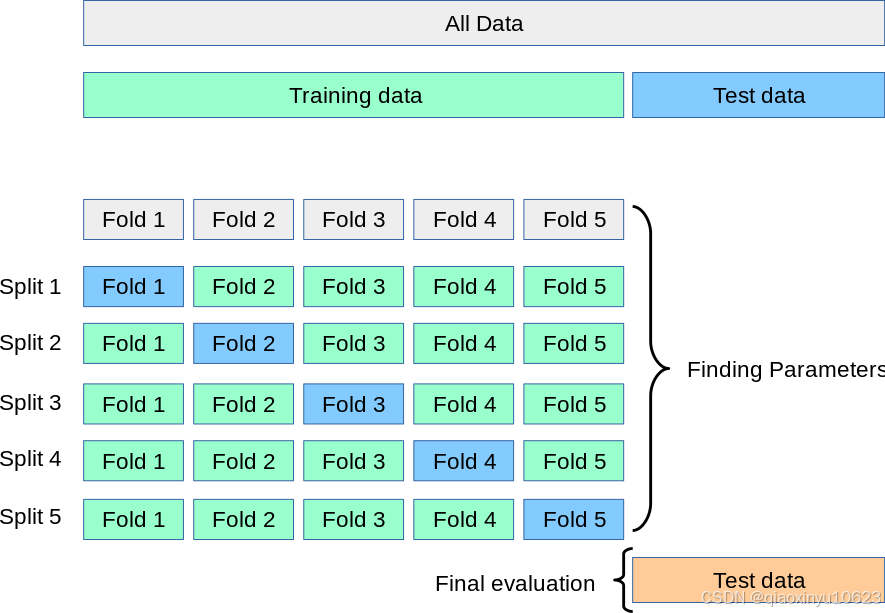
解决这个问题的方法是一个称为交叉验证(简称 CV)的程序。测试集仍应保留用于最终评估,但在执行 CV 时不再需要验证集。在模型训练期间使用,交叉验证将训练集拆分为更小的集,称为折叠。该模型使用除一个用于验证的折叠之外的所有折叠进行训练。在称为 k-fold CV 的基本方法中,训练集被分成 k 个更小的集合(其他方法如下所述,但通常遵循相同的原则)。对于每个 k 个“折叠”,都遵循以下过程:
-
使用k−1折叠作为训练数据来训练模型;
-
生成的模型在数据的剩余部分(即,它用作计算性能度量(例如准确性)的测试集。
k-fold 交叉验证报告的性能度量则是在循环中计算的值的平均值。这种方法的计算成本可能很高,但不会浪费太多数据(就像修复任意验证集时的情况一样),这在逆向推理等问题中是一个主要优势,其中样本数量非常少。
4. 结论
训练-测试拆分是机器学习管道中的关键步骤。它有助于模型评估、检测偏差和过度拟合,并有助于超参数优化。为了确保对模型进行真实且无偏见的评估,在进行任何数据预处理、编码、缩放或其他转换之前执行拆分至关重要。通过遵循这种做法,您可以构建不仅准确而且能够对新的、看不见的数据进行可靠预测的机器学习模型。
参考文献:
【1】The Significance of Train-Test Split in Machine Learning | by Ajay Verma | Artificial Intelligence in Plain English【2】Understanding Train-Test Splits
【3】2108.02497v1
【4】3.1. Cross-validation: evaluating estimator performance — scikit-learn 1.6.1 documentation
【5】Avoid machine learning pitfalls with train-test split | by Crystal Gould Perrott | Medium
:python操控autoit)



