每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

GPT-4o 的横空出世,正式标志着多模态 AI 进入“原生融合”新时代——不再是调用外挂工具生成图片,而是文字和图像在一个模型里“同框”出现,通通由一个脑袋搞定。
这一代模型最核心的黑科技,就是一种叫做 Transfusion 的架构。它不只是让 GPT-4o 懂图会画,还能边说边画,画完继续说,整个过程一气呵成,就像人类用语言和画笔交替表达一样自然。
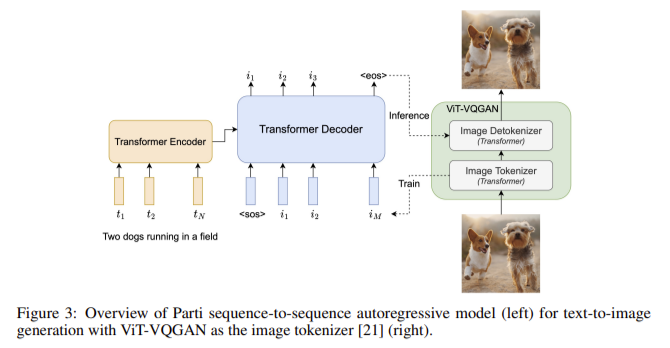
来看看 GPT-4o 的“图文合体”是怎么做到的👇
🧠 技术原理一览:Transfusion 是怎么把 Transformer 和 Diffusion 融在一起的?
以往 AI 生图走的是“外挂流”,比如 ChatGPT 搭配 DALL·E:语言模型出提示词,图像模型接单画图。这种“二人转”方式虽然能用,但图像和语言之间的信息割裂严重,图也画不精,细节还常常错位。
还有一种方式是“离散拼图流”——比如 Chameleon,把图像切成 token,就像把图拆成拼图块,一块一块生成。但这种做法有个硬伤:图像被编码成离散的 token,信息被压缩后,画面精度很容易打折,尤其是颜色渐变和细节质感容易丢失。
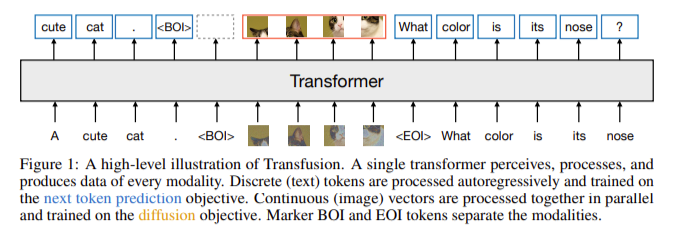
而 Transfusion 直接来一波 “跨界融合”:
- 图文同源:一个 Transformer 统领文字和图像。文本照常做 token 预测,图像部分则走 diffusion 路线,用连续向量训练去噪。
- 原生图像块:图像被编码成 latent patch(连续的向量块),再由 Transformer 接收处理,不再是用离散的 codebook token。
- 图文合一序列:训练时,图文被拼成一个大序列,图像内容用 BOI(Begin-of-Image)和 EOI(End-of-Image)包起来,模型知道什么时候在说话,什么时候在画图。
- 变身绘图工厂:当 GPT-4o 生成 BOI 后,它自动插入一组“噪声图块”作为图像 placeholder,然后开始用 diffusion 的方式,一轮轮去噪修图,直到输出高清图像,再标记 EOI 结束。
🔍 模型结构的几大亮点
- 图像压缩率惊人:一张图平均只需 16~22 个 latent patch,大大缩短生成步骤,速度比传统 diffusion 模型更快。
- 上下游完全打通:图像生成用 Transformer 原生完成,不依赖外部模块,文字上下文可以直接“指导”图片内容。
- 两种风格“接口层”:图像块可以通过线性投影进入 Transformer,也可以用小型 U-Net 编码器更深入理解图像结构。后者效果更佳。
📈 性能实测结果:完胜前代
| 指标 | GPT-4o / Transfusion | Chameleon | SDXL |
|---|---|---|---|
| FID(图像质量) | 6.78(越低越好) | 26.7 | 类似 GPT-4o |
| CLIP Score(图文匹配) | 0.63 | 0.39 | 略低 |
| 每图计算成本 | 仅为 Chameleon 的 22% | 高 | 较高 |
| 多模态能力 | 原生图文混合、多轮交互 | 一般 | 不支持交互 |
最重要的是,GPT-4o 不仅能“画图”,还能把图文混合表达带入下一步交互——比如“画完接着解释”、“修改图像细节”、“看图写故事”等等,全都能原生处理,无需插件。

❗目前小小的遗憾
- 受限于 diffusion 本身的特性,生成图像仍比纯文本慢;
- Transformer 一人扛双职,训练难度相对更高;
- 高效生成依赖巧妙的掩码机制和归一化设计,否则容易模型崩塌。
🎯 小结一下
GPT-4o 基于 Transfusion 架构,把文本生成和图像合成从“多工具拼装”进化到“全能单模”。它既保留了 Transformer 的语言理解力,又融入了 Diffusion 的图像表现力,最终形成真正“懂图说话、能画能讲”的多模态大模型。
从现在起,AI 不再是“文字一张嘴,图片另找人”,而是一个大脑多功能,边说边画、边画边想,内容表现力直接拉满。


)



