
连接查询的执行过程:
- 确定第一个需要查询的表【驱动表】
- 选取代价最小的访问方法去执行单表查询语句
- 从驱动表每获取到一条记录,都需要到t2表中查找匹配的记录
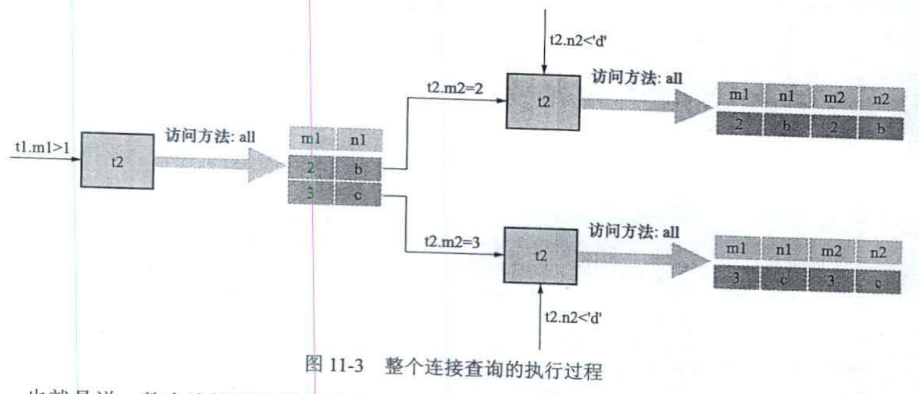
两表连接查询需要查询一次t1表,两次t2表,在两表的连接查询中,驱动表只需访问一次,被驱动表可能需要访问多次
并不是所有满足条件的驱动表记录先查询出来放到一个地方再去被驱动表查询的【如果符合条件的记录很多,需要很大的存储空间】,每获取到一条驱动表记录,就立刻到被驱动表中寻找匹配的记录
内连接和外连接
-
对于内连接的两个表,若驱动表中的记录在被驱动表中找不到匹配的记录,则该记录不会加入到最后的结果集
- 对于内连接来说,驱动表和被驱动表是可以互换的
-
对于外连接的两个表,即使驱动表中的记录在被驱动表中没有匹配的记录,也仍需要加入到结果集中
-
左外连接:左侧表为驱动表
-
右外连接:右侧表为驱动表
-
驱动表记录筛选
- where子句过滤
- On子句过滤:专门为外连接驱动表中的记录在被驱动表找不到匹配记录时是否应该把驱动表记录加入结果集中这一场景设计
-
-
嵌套循环连接
-

-
-
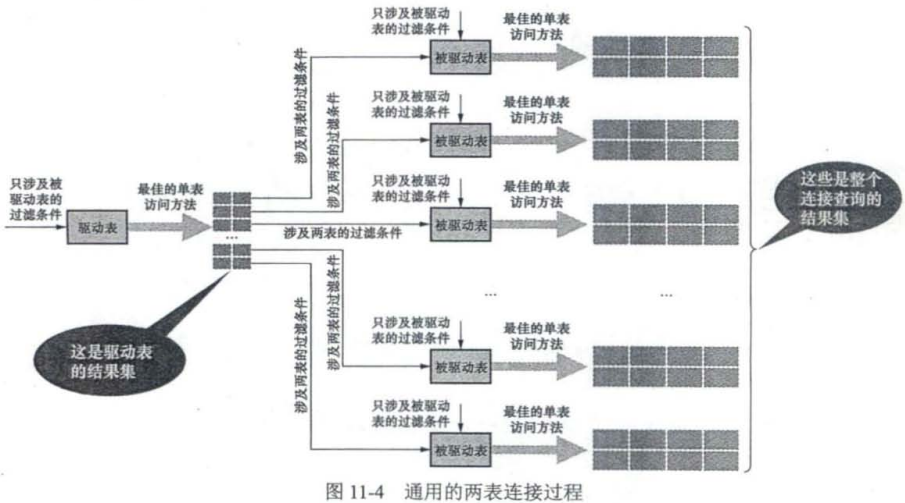
驱动表只访问一次,但被驱动表可能访问多次,且访问次数取决于对驱动表执行单表查询后的结果集中有多少条记录
-
驱动表得到一条记录->被驱动表查询匹配到结果->把组合后的记录发送给客户端,再到驱动表中获取下一条记录
-
-
使用索引加快连接速度
- 建议最好不要使用*作为查询列表,而是把真正用到的列作为查询列表
-
基于块的嵌套循环连接Block Nested-Loop Join
- Join Buffer连接缓冲区【减少被驱动表的访问次数】
-
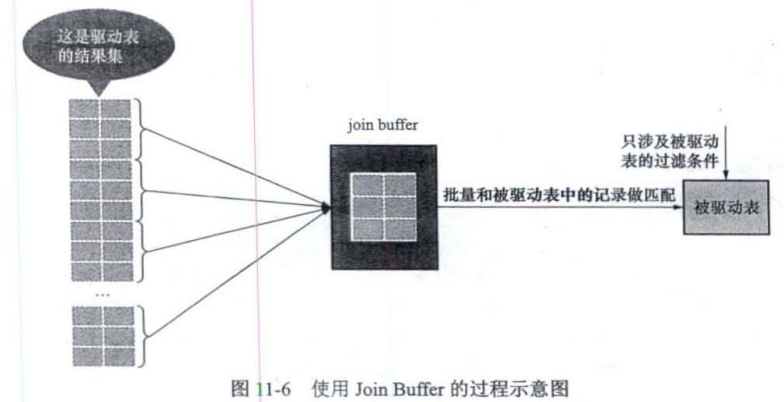
执行连接查询前申请的一块固定大小的内存,先把若干条驱动表结果集中的记录装在Join Buffer中,然后开始扫描被驱动表,每一条被驱动表的记录一次性地与Join Buffer中的多条驱动表记录进行匹配,匹配过程都在内存中完成,显著减少被驱动表的I/O代价
-
-
最好的情况是Join Buffer足够大,能容纳驱动表结果集中的所有记录,只需访问一次被驱动表就可完成连接操作
-
Join Buffer大小可以通过启动选项或系统变量join_buffer_size进行配置【默认256KB,最小128字节】
-
优化对被驱动表的查询时,最好为被驱动表加上高效率索引,实在不行可尝试调大join_buffer_size对连接查询进行优化
-
需注意,不会存放被驱动表记录的所有列,只有查询列表中的列和过滤条件中的列【最好不要用*查询】,Join Buffer可以放更多记录
-
- Join Buffer连接缓冲区【减少被驱动表的访问次数】

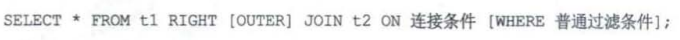
Join注意点
- 小表作为驱动表,被驱动表是否能命中索引
- 驱动表需要全表扫描,而被驱动表通过索引查询
)



