一、前言
在当今信息呈现方式越来越多样化的背景下,如何将文字、图片甚至视频高效转化为可听的音频体验,已经成为内容创作者、教育者和研究者们共同关注的重要话题。Podcastfy是一款基于Python的开源工具,它专注于将多种形式的内容智能转换成音频,正在引领一场“可听化”的创作新风潮。
通过结合生成式人工智能(GenAI)和先进的文本转语音(TTS)技术,Podcastfy能够将网页、PDF文件、图片甚至YouTube视频等多种输入,转变为自然流畅的多语言音频对话。
与传统的单一内容转化工具不同,Podcastfy支持从短小的2分钟精华片段到长达30分钟的深度播客生成,还允许用户在音频风格、语言结构和语音模型上进行高度自定义。并且,Podcastfy以其开源特性和程序化接口,为各种场景下的内容创作提供了灵活且专业的解决方案。这一工具的推出,不仅为信息的可及性带来了重要突破,还重新定义了“声音经济”时代的内容表达方式。
二、术语介绍
2.1.Podcastfy
是一款基于 Python 开发的开源多模态内容转换工具,其核心作用是通过生成式人工智能(GenAI)技术,将文本、图像、网页、PDF、YouTube 视频等多种形式的内容,智能转化为多语言音频对话,从而革新内容创作与传播方式。
技术定位与核心功能
1. 多模态输入兼容性
- Podcastfy 支持从网页、PDF、图像、YouTube 视频甚至用户输入的主题中提取内容,并自动生成对话式文本脚本。
2.多语言与音频定制化
- 工具内置多语言支持(包括中文、英语等),可生成不同语言版本的音频,并允许调整播客的风格、声音、时长(如 2-5 分钟短片或 30 分钟以上的长篇内容),甚至模拟自然对话的互动感。
3.技术架构与开源特性
- 生成式 AI 驱动:集成 100+ 主流语言模型(如 OpenAI、Anthropic、Google 等),支持本地运行 HuggingFace 上的 156+ 模型,兼顾生成质量与隐私控制。
- 高级 TTS 引擎:与 ElevenLabs、Microsoft Edge 等文本转语音平台无缝整合,生成拟人化语音效果。
- 开源可扩展:用户可自由修改代码,定制播客生成逻辑或集成私有模型,突破闭源工具(如 Google NotebookLM)的功能限制。
2.2.Gradio
是一个开源的 Python 库,专注于快速构建交互式 Web 应用程序,尤其适用于机器学习模型、API 或任意 Python 函数的可视化展示和用户交互。通过简单代码即可生成功能丰富的界面,无需前端开发经验。
2.3.nohup 命令
是类 Unix 系统中使用的一个工具,用于在后台运行程序并使其忽略挂起信号。在使用命令行运行程序时,通常如果你关闭终端或注销用户,正在运行的程序也会被终止。使用 nohup 可以避免这种情况,让程序在后台持续运行。
三、前置条件
3.1.基础环境及前置条件
1. 操作系统:无限制
3.2.安装依赖
conda create --name podcastfy-app python=3.12
conda activate podcastfy-apppip install gradio-client==1.4.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install gradio==5.4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install podcastfy==0.4.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install python-dotenv==1.0.1 -i https://pypi.tuna.tsinghua.edu.cn/simple 四、技术实现
4.1.Gradio代码
# -*- coding:utf-8 -*-
import gradio as gr
import os
import tempfile
import logging
from podcastfy.client import generate_podcast
from dotenv import load_dotenv# Configure logging
logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger(__name__)# Load environment variables
load_dotenv()os.environ["GEMINI_API_KEY"] = 'xxxxxxxxxxxxxx-xxxxxxxx-xx'
os.environ["OPENAI_API_KEY"] = 'sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'def get_api_key(key_name, ui_value):return ui_value if ui_value else os.getenv(key_name)def process_inputs(text_input,urls_input,pdf_files,image_files,gemini_key,openai_key,elevenlabs_key,word_count,conversation_style,roles_person1,roles_person2,dialogue_structure,podcast_name,podcast_tagline,tts_model,creativity_level,user_instructions,longform
):try:logger.info("Starting podcast generation process")# API key handlinglogger.debug("Setting API keys")os.environ["GEMINI_API_KEY"] = get_api_key("GEMINI_API_KEY", gemini_key)if tts_model == "openai":logger.debug("Setting OpenAI API key")if not openai_key and not os.getenv("OPENAI_API_KEY"):raise ValueError("OpenAI API key is required when using OpenAI TTS model")os.environ["OPENAI_API_KEY"] = get_api_key("OPENAI_API_KEY", openai_key)if tts_model == "elevenlabs":logger.debug("Setting ElevenLabs API key")if not elevenlabs_key and not os.getenv("ELEVENLABS_API_KEY"):raise ValueError("ElevenLabs API key is required when using ElevenLabs TTS model")os.environ["ELEVENLABS_API_KEY"] = get_api_key("ELEVENLABS_API_KEY", elevenlabs_key)print(f'GEMINI_API_KEY: {os.environ["GEMINI_API_KEY"]},OPENAI_API_KEY: {os.environ["OPENAI_API_KEY"]}')# Process URLsurls = [url.strip() for url in urls_input.split('\n') if url.strip()]logger.debug(f"Processed URLs: {urls}")temp_files = []temp_dirs = []# Handle PDF filesif pdf_files is not None and len(pdf_files) > 0:logger.info(f"Processing {len(pdf_files)} PDF files")pdf_temp_dir = tempfile.mkdtemp()temp_dirs.append(pdf_temp_dir)for i, pdf_file in enumerate(pdf_files):pdf_path = os.path.join(pdf_temp_dir, f"input_pdf_{i}.pdf")temp_files.append(pdf_path)with open(pdf_path, 'wb') as f:f.write(pdf_file)urls.append(pdf_path)logger.debug(f"Saved PDF {i} to {pdf_path}")# Handle image filesimage_paths = []if image_files is not None and len(image_files) > 0:logger.info(f"Processing {len(image_files)} image files")img_temp_dir = tempfile.mkdtemp()temp_dirs.append(img_temp_dir)for i, img_file in enumerate(image_files):# Get file extension from the original name in the file tupleoriginal_name = img_file.orig_name if hasattr(img_file, 'orig_name') else f"image_{i}.jpg"extension = original_name.split('.')[-1]logger.debug(f"Processing image file {i}: {original_name}")img_path = os.path.join(img_temp_dir, f"input_image_{i}.{extension}")temp_files.append(img_path)try:# Write the bytes directly to the filewith open(img_path, 'wb') as f:if isinstance(img_file, (tuple, list)):f.write(img_file[1]) # Write the bytes contentelse:f.write(img_file) # Write the bytes directlyimage_paths.append(img_path)logger.debug(f"Saved image {i} to {img_path}")except Exception as e:logger.error(f"Error saving image {i}: {str(e)}")raise# Prepare conversation configlogger.debug("Preparing conversation config")conversation_config = {"word_count": word_count,"conversation_style": conversation_style.split(','),"roles_person1": roles_person1,"roles_person2": roles_person2,"dialogue_structure": dialogue_structure.split(','),"podcast_name": podcast_name,"podcast_tagline": podcast_tagline,"creativity": creativity_level,"user_instructions": user_instructions}# Generate podcastlogger.info("Calling generate_podcast function")logger.debug(f"URLs: {urls}")logger.debug(f"Image paths: {image_paths}")logger.debug(f"Text input present: {'Yes' if text_input else 'No'}")audio_file = generate_podcast(urls=urls if urls else None,text=text_input if text_input else None,image_paths=image_paths if image_paths else None,tts_model=tts_model,conversation_config=conversation_config,longform = eval(longform))logger.info("Podcast generation completed")# Cleanuplogger.debug("Cleaning up temporary files")for file_path in temp_files:if os.path.exists(file_path):os.unlink(file_path)logger.debug(f"Removed temp file: {file_path}")for dir_path in temp_dirs:if os.path.exists(dir_path):os.rmdir(dir_path)logger.debug(f"Removed temp directory: {dir_path}")return audio_fileexcept Exception as e:logger.error(f"Error in process_inputs: {str(e)}", exc_info=True)# Cleanup on errorfor file_path in temp_files:if os.path.exists(file_path):os.unlink(file_path)for dir_path in temp_dirs:if os.path.exists(dir_path):os.rmdir(dir_path)return str(e)# Create Gradio interface with updated theme
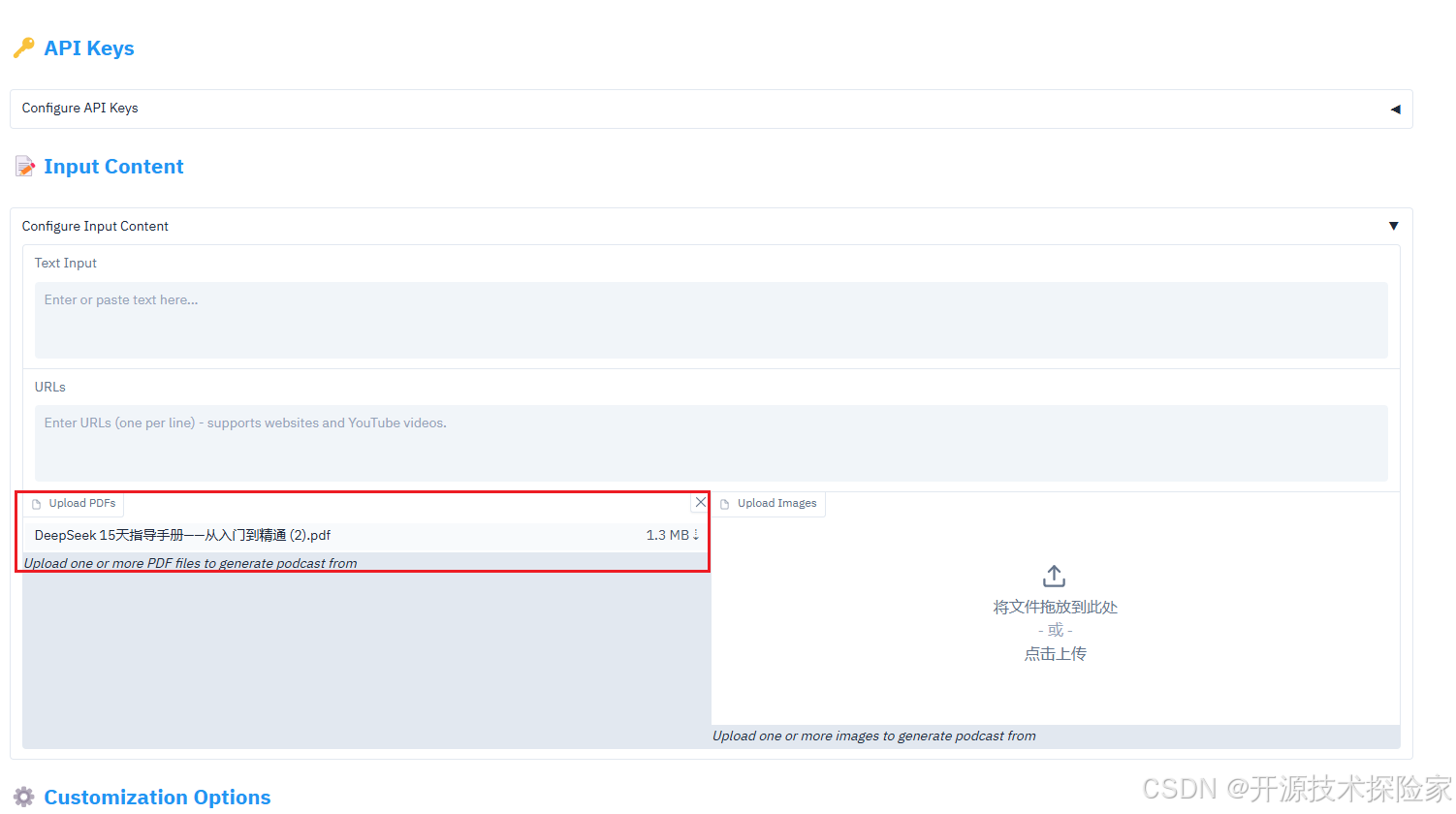
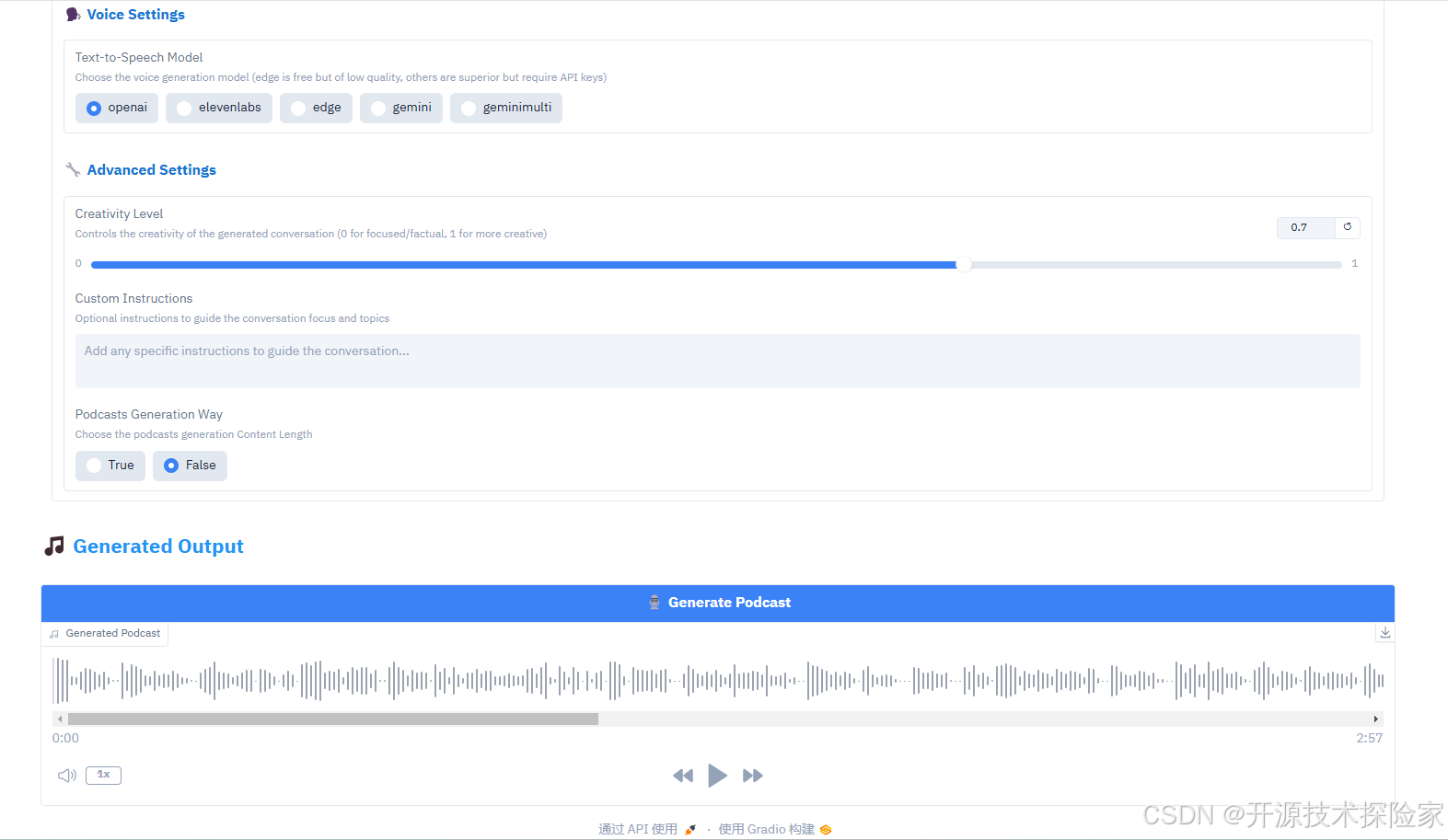
with gr.Blocks(title="Podcastfy.ai",theme=gr.themes.Base(primary_hue="blue",secondary_hue="slate",neutral_hue="slate"),css="""/* Move toggle arrow to left side */.gr-accordion {--accordion-arrow-size: 1.5em;}.gr-accordion > .label-wrap {flex-direction: row !important;justify-content: flex-start !important;gap: 1em;}.gr-accordion > .label-wrap > .icon {order: -1;}"""
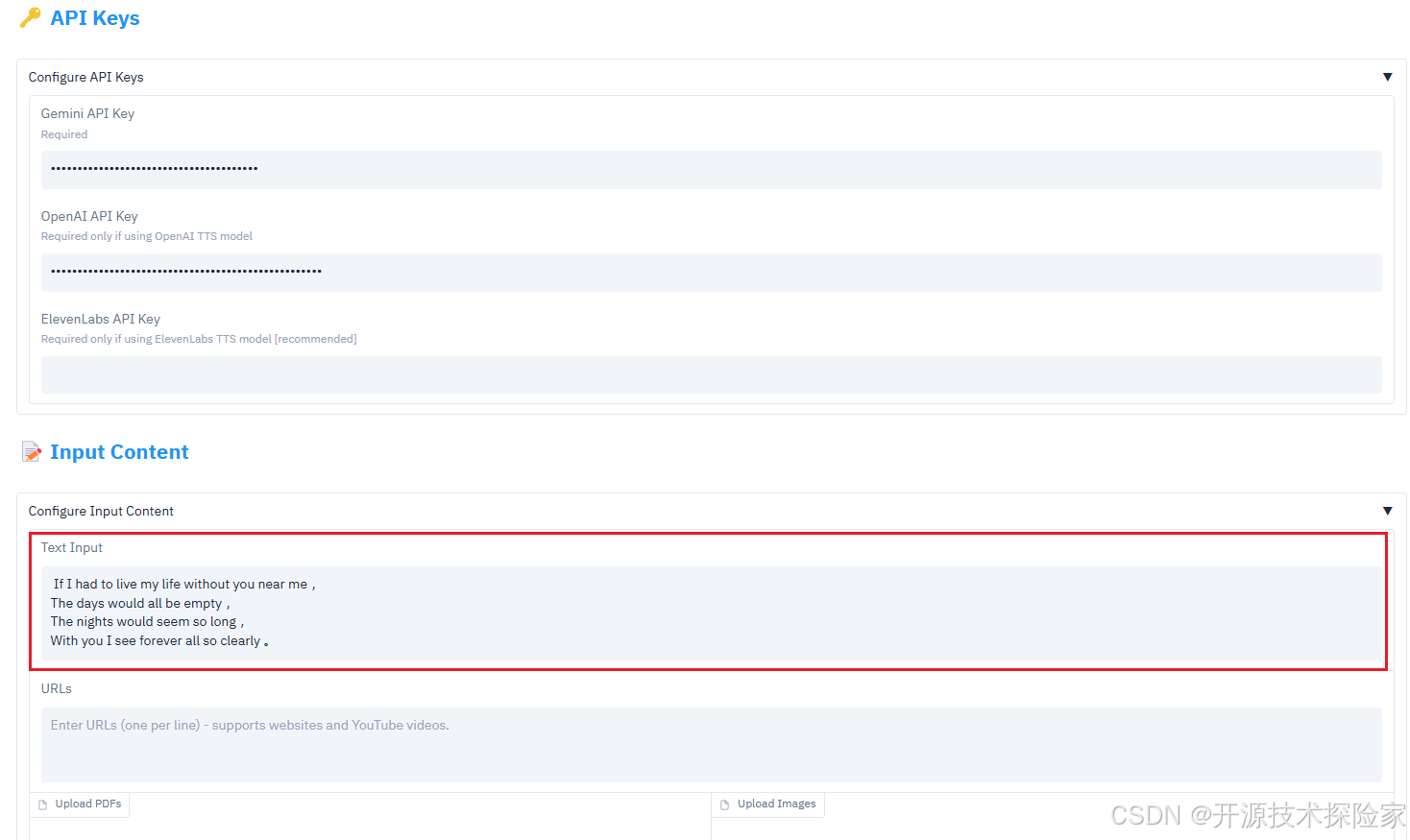
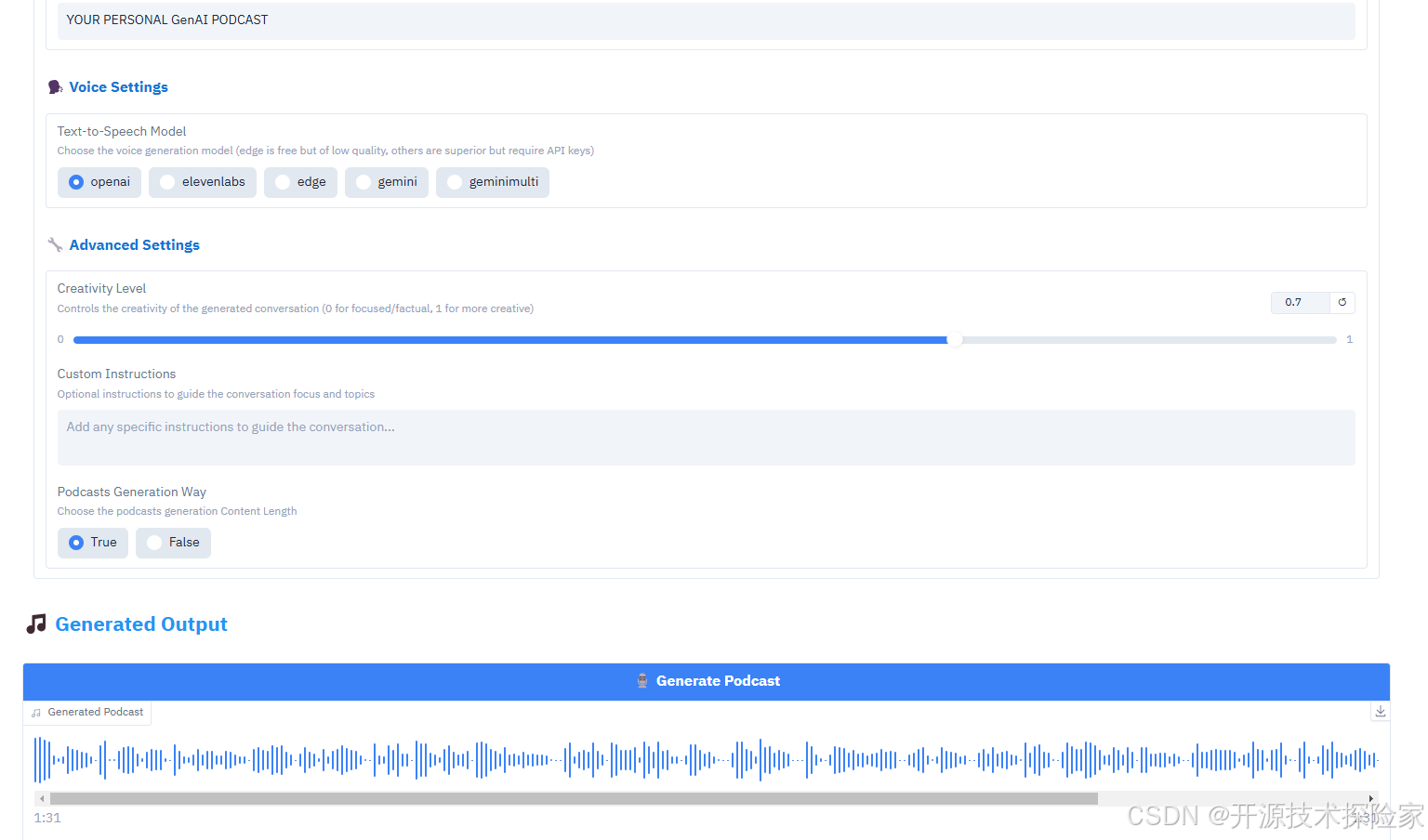
) as demo:with gr.Tab("Content"):# API Keys Sectiongr.Markdown("""<h2 style='color: #2196F3; margin-bottom: 10px; padding: 10px 0;'>🔑 API Keys</h2>""",elem_classes=["section-header"])with gr.Accordion("Configure API Keys", open=False):gemini_key = gr.Textbox(label="Gemini API Key",type="password",value=os.getenv("GEMINI_API_KEY", ""),info="Required")openai_key = gr.Textbox(label="OpenAI API Key",type="password",value=os.getenv("OPENAI_API_KEY", ""),info="Required only if using OpenAI TTS model")elevenlabs_key = gr.Textbox(label="ElevenLabs API Key",type="password",value=os.getenv("ELEVENLABS_API_KEY", ""),info="Required only if using ElevenLabs TTS model [recommended]")# Content Input Sectiongr.Markdown("""<h2 style='color: #2196F3; margin-bottom: 10px; padding: 10px 0;'>📝 Input Content</h2>""",elem_classes=["section-header"])with gr.Accordion("Configure Input Content", open=False):with gr.Group():text_input = gr.Textbox(label="Text Input",placeholder="Enter or paste text here...",lines=3)urls_input = gr.Textbox(label="URLs",placeholder="Enter URLs (one per line) - supports websites and YouTube videos.",lines=3)# Place PDF and Image uploads side by sidewith gr.Row():with gr.Column():pdf_files = gr.Files( # Changed from gr.File to gr.Fileslabel="Upload PDFs", # Updated labelfile_types=[".pdf"],type="binary")gr.Markdown("*Upload one or more PDF files to generate podcast from*",elem_classes=["file-info"])with gr.Column():image_files = gr.Files(label="Upload Images",file_types=["image"],type="binary")gr.Markdown("*Upload one or more images to generate podcast from*", elem_classes=["file-info"])# Customization Sectiongr.Markdown("""<h2 style='color: #2196F3; margin-bottom: 10px; padding: 10px 0;'>⚙️ Customization Options</h2>""",elem_classes=["section-header"])with gr.Accordion("Configure Podcast Settings", open=False):# Basic Settingsgr.Markdown("""<h3 style='color: #1976D2; margin: 15px 0 10px 0;'>📊 Basic Settings</h3>""",)word_count = gr.Slider(minimum=500,maximum=5000,value=2000,step=100,label="Word Count",info="Target word count for the generated content")conversation_style = gr.Textbox(label="Conversation Style",value="engaging,fast-paced,enthusiastic",info="Comma-separated list of styles to apply to the conversation")# Roles and Structuregr.Markdown("""<h3 style='color: #1976D2; margin: 15px 0 10px 0;'>👥 Roles and Structure</h3>""",)roles_person1 = gr.Textbox(label="Role of First Speaker",value="main summarizer",info="Role of the first speaker in the conversation")roles_person2 = gr.Textbox(label="Role of Second Speaker",value="questioner/clarifier",info="Role of the second speaker in the conversation")dialogue_structure = gr.Textbox(label="Dialogue Structure",value="Introduction,Main Content Summary,Conclusion",info="Comma-separated list of dialogue sections")# Podcast Identitygr.Markdown("""<h3 style='color: #1976D2; margin: 15px 0 10px 0;'>🎙️ Podcast Identity</h3>""",)podcast_name = gr.Textbox(label="Podcast Name",value="PODCASTFY",info="Name of the podcast")podcast_tagline = gr.Textbox(label="Podcast Tagline",value="YOUR PERSONAL GenAI PODCAST",info="Tagline or subtitle for the podcast")# Voice Settingsgr.Markdown("""<h3 style='color: #1976D2; margin: 15px 0 10px 0;'>🗣️ Voice Settings</h3>""",)tts_model = gr.Radio(choices=["openai", "elevenlabs", "edge", "gemini", "geminimulti"],value="openai",label="Text-to-Speech Model",info="Choose the voice generation model (edge is free but of low quality, others are superior but require API keys)")# Advanced Settingsgr.Markdown("""<h3 style='color: #1976D2; margin: 15px 0 10px 0;'>🔧 Advanced Settings</h3>""",)creativity_level = gr.Slider(minimum=0,maximum=1,value=0.7,step=0.1,label="Creativity Level",info="Controls the creativity of the generated conversation (0 for focused/factual, 1 for more creative)")user_instructions = gr.Textbox(label="Custom Instructions",value="",lines=2,placeholder="Add any specific instructions to guide the conversation...",info="Optional instructions to guide the conversation focus and topics")longform = gr.Radio(choices=["True", "False"],value="False",label="Podcasts Generation Way",info="Choose the podcasts generation Content Length")# Output Sectiongr.Markdown("""<h2 style='color: #2196F3; margin-bottom: 10px; padding: 10px 0;'>🎵 Generated Output</h2>""",elem_classes=["section-header"])with gr.Group():generate_btn = gr.Button("🎙️ Generate Podcast", variant="primary")audio_output = gr.Audio(type="filepath",label="Generated Podcast")# Handle generationgenerate_btn.click(process_inputs,inputs=[text_input, urls_input, pdf_files, image_files,gemini_key, openai_key, elevenlabs_key,word_count, conversation_style,roles_person1, roles_person2,dialogue_structure, podcast_name,podcast_tagline, tts_model,creativity_level, user_instructions,longform],outputs=audio_output)DEFAULT_SERVER_NAME = '0.0.0.0'
DEFAULT_PORT = 8000
DEFAULT_USER = "zhangshan"
DEFAULT_PASSWORD = '123456'if __name__ == "__main__":demo.queue().launch(debug=False,share=False,inbrowser=False,server_port=DEFAULT_PORT,server_name=DEFAULT_SERVER_NAME,auth=(DEFAULT_USER, DEFAULT_PASSWORD) )4.2.测试
4.2.1.启动Gradio服务
nohup python /podcastfy-app/gradio-server.py > /logs/podcastfy-app.log 2>&1 &浏览器访问:http://IP:8000
输入账号:zhangshan/123456
4.2.2.测试文本输入
注意:需要具备科学上网的能力
PS:服务端输出的日志:
DEBUG:openai._base_client:HTTP Response: POST https://api.openai.com/v1/audio/speech "200 OK" Headers({'date': 'Wed, 16 Apr 2025 07:20:51 GMT', 'content-type': 'audio/mpeg', 'transfer-encoding': 'chunked', 'connection': 'keep-alive', 'access-control-expose-headers': 'X-Request-ID', 'openai-organization': 'everblessed-technology-inc', 'openai-processing-ms': '1334', 'openai-version': '2020-10-01', 'strict-transport-security': 'max-age=31536000; includeSubDomains; preload', 'via': 'envoy-router-84dd794555-brjjp', 'x-envoy-upstream-service-time': '1313', 'x-ratelimit-limit-requests': '10000', 'x-ratelimit-remaining-requests': '9999', 'x-ratelimit-reset-requests': '6ms', 'x-request-id': 'req_cc00076d234569e896d01ee281a07938', 'cf-cache-status': 'DYNAMIC', 'x-content-type-options': 'nosniff', 'server': 'cloudflare', 'cf-ray': '9311ec21cd46fb30-SJC', 'alt-svc': 'h3=":443"; ma=86400'})
DEBUG:openai._base_client:request_id: req_cc00076d234569e896d01ee281a07938
DEBUG:openai._base_client:Request options: {'method': 'post', 'url': '/audio/speech', 'headers': {'Accept': 'application/octet-stream'}, 'files': None, 'json_data': {'input': "Exactly! It's not just about the present moment. It's about envisioning a future, a forever, with this person. And that forever is clear, sharply defined.", 'model': 'tts-1-hd', 'voice': 'shimmer'}}
DEBUG:openai._base_client:Sending HTTP Request: POST https://api.openai.com/v1/audio/speech
DEBUG:httpcore.http11:send_request_headers.started request=<Request [b'POST']>
DEBUG:httpcore.http11:send_request_headers.complete
DEBUG:httpcore.http11:send_request_body.started request=<Request [b'POST']>
DEBUG:httpcore.http11:send_request_body.completeDEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/1_question.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/1_answer.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/2_question.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/2_answer.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/3_question.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/3_answer.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/4_question.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/4_answer.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/5_question.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/5_answer.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/6_question.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/6_answer.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/7_question.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'mp3', '-i', '/opt/anaconda3/envs/podcastfy-app/lib/python3.12/site-packages/podcastfy/data/audio/tmp/tmpxsbm6y6y/7_answer.mp3', '-acodec', 'pcm_s16le', '-vn', '-f', 'wav', '-'])
DEBUG:pydub.converter:subprocess.call(['ffmpeg', '-y', '-f', 'wav', '-i', '/tmp/tmpytxxw8ea', '-f', 'mp3', '/tmp/tmptv8lgkb9'])4.2.3.测试文件输入
注意:需要具备科学上网的能力

测试的PDF文件共25页,大小1.3M。