个人学习笔记,如有错误欢迎指正,也欢迎交流,其他笔记见个人空间
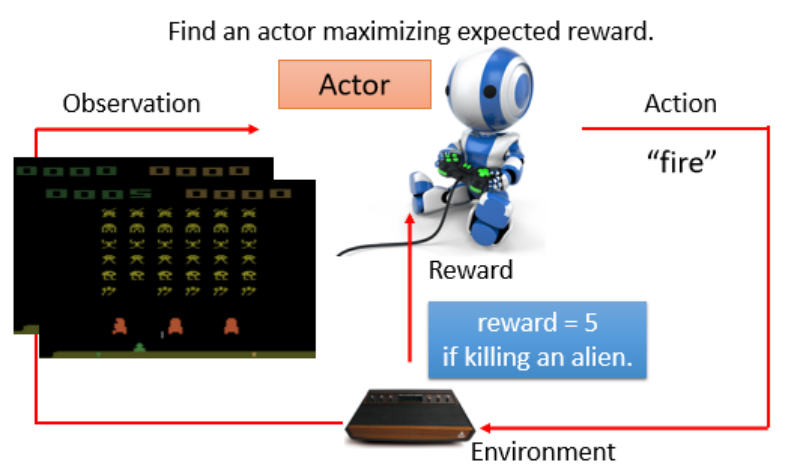
强化学习 vs 监督学习
-
监督学习(Supervised Learning):你有输入和明确的输出标签,例如图像分类。
-
强化学习(Reinforcement Learning):你不知道输出的“最佳答案”,只能通过与环境互动、收集奖励(Reward)来学习策略。
举例:
-
围棋:每一步的“最优落子”可能连人类都不知道
-
电子游戏:通过游戏画面(Observation)作出动作(Action),根据得分获得奖励
强化学习的核心结构
环境(Environment)与智能体(Actor):
-
Observation:环境给智能体的输入
-
Action:智能体输出的行为
-
Reward:环境给予智能体的反馈
智能体的目标:最大化总奖励(Total Reward)
强化学习的核心步骤和深度学习其实基本一样
Step 1:定义一个有未知参数的Function(通常称为Policy Network)
Step 2:定义Loss(负的Total Reward)
Step 3:优化参数以最大化Reward(Optimization)
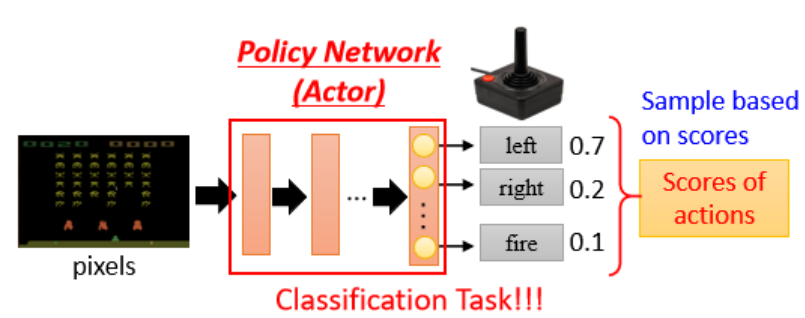
第一步: 定义一个有未知参数的函数,也就是策略函数(Policy),通常用神经网络来表示。
希望找到一个策略函数 (policy):
-
输入:当前环境的观测(observation)
-
输出:某个动作(action)或一组动作的概率
这个函数内部有很多未知参数(θ),通过训练来确定这些参数,从而让策略越来越聪明。例如用CNN处理图像输入,用MLP处理数值输入,RNN / Transformer处理历史轨迹,生成不同action的概率后,通常根据这个分布 进行采样(sampling) 来选择动作,而不是直接选择最大值(argmax),这是为了增加策略的探索性
第二步: 定义Loss
在强化学习中,我们没有 Ground Truth 标签,但依然需要定义一个目标 ——即使不能说“动作a对还是错”,但我们知道做完这个动作之后是否有奖励(Reward)。
与环境交互(Episode):
-
一个智能体从初始状态开始,连续做出动作(Action)
-
每个动作会得到一个即时奖励(Reward),如 r1,r2,...,rT
-
所有奖励累加得到:R=r1+r2+⋯+rT这个 R 又被称为 Return 或 Total Reward
目标(Objective):
-
我们希望找到策略参数 θ,使得这个总奖励 R越大越好
转换为损失函数:
-
强化学习中不像监督学习有明确的 Loss
-
所以我们把“最大化奖励”变成“最小化负的奖励”:Loss=−R
第三步:优化参数
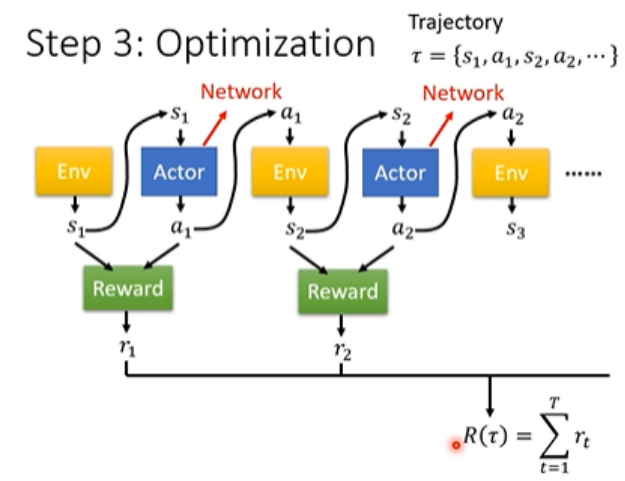
问题是则不是一个一般的优化问题,难点:
1、Actor输出是随机采样的
2、Environment是不可导黑盒子,不能反向传播
3、Reward是延迟的,无法直接分配“哪个动作贡献了多少”
Policy Gradient
一种解决RL优化问题的经典方法,核心思想如下:
-
把Actor当作一个分类器
-
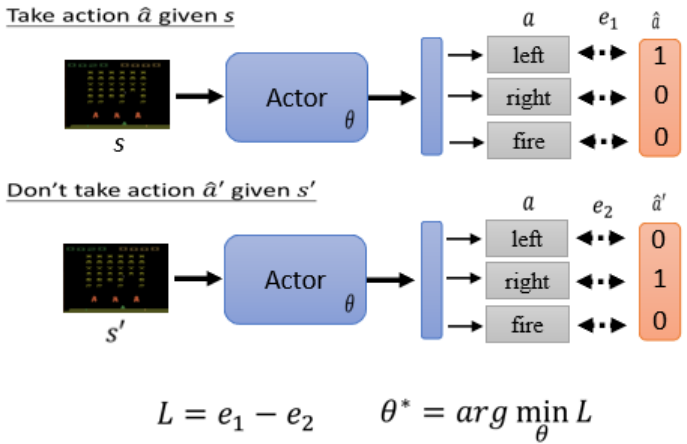
用类似Cross-entropy的Loss定义行为偏好(a和
的交叉熵作为loss,希望采取
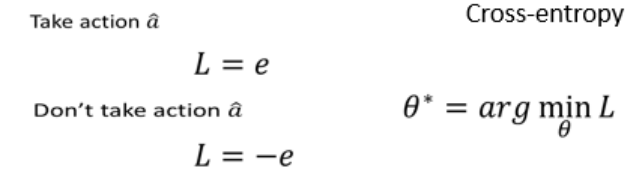
如下希望看到 s 时采取,看到 s' 时不采取
‘,则L=e1-e2。
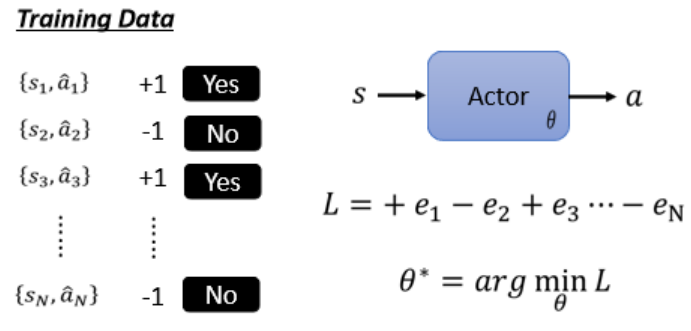
(需要收集大量s,a的一对一对的数据)
-
设定希望Actor采取or避免的行为,并赋予不同权重(An),代表采取/避免某行动的“意愿”有多强。
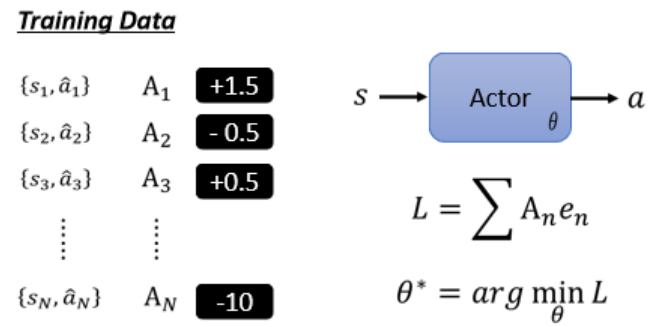
-
再用梯度下降去优化Actor网络参数,使行为更符合期望
现在的问题在于怎么定义a的好坏
初级的思路就是直接用当前时间步的 Reward来评估当前 Action 的好坏,如果r>0就认为 Action 是好的,问题是忽视了当前动作对未来的长期影响,导致“短视近利”的策略
由此产生第二个版本的想法:a有多好取决于a之后收到的所有Reward,通通加起来得到一个累计奖励G(Total Future Reward)。
优点:考虑到动作的长期影响
问题:游戏太长时,早期动作对后期奖励影响不明显,不一定是这一步的动作导致后面好的结果,导致归因失真
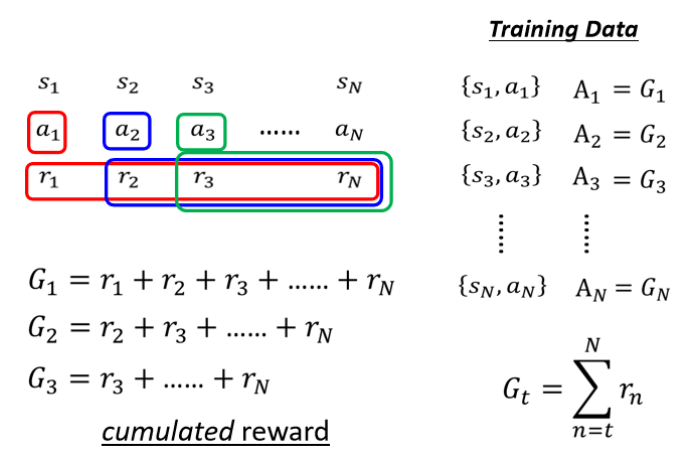
由此产生第三个版本的想法:引入折扣因子(Discount Factor)
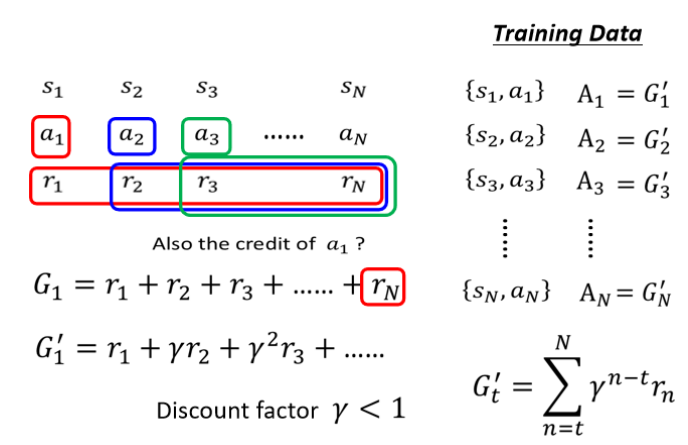
距离 at 越远的 r 对于 at 就越“不重要”,因为 γ 指数项会变大。
优点:距离当前动作越近的奖励权重越高;解决远期奖励归因问题
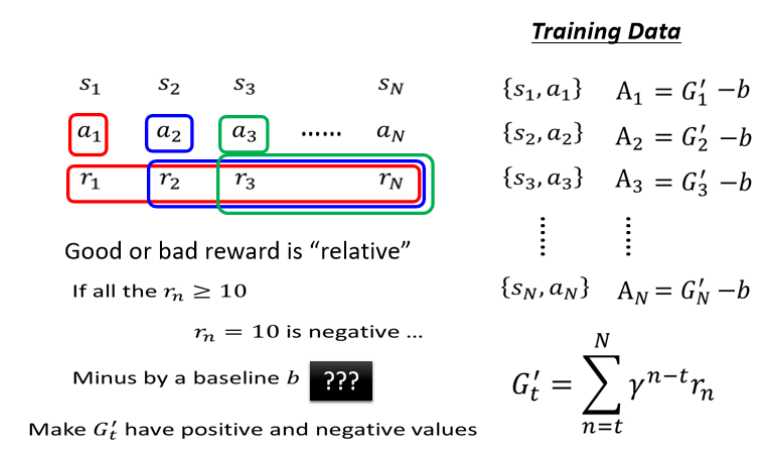
第四个版本:如果所有 Gt′ 都是正的,即使有些表现差的动作也被当作“ 好 ”进一步,因此需要做标准化, 引入基线(Baseline) b,将 Gt′−b 作为最终评价量 At。
-
目的是让评价结果“有正有负”,使训练更稳定、更有区分度
-
b 可设为均值、滑动平均、甚至预测的值(将引出 Critic)
Policy Gradient 实际操作流程
-
初始化策略网络(Actor)参数 θ
-
收集数据:用当前策略与环境交互,采样出多个 (state, action) 对
-
评估每个动作的好坏:计算 At,可以是版本 1~4 中任一种
-
定义 Loss:例如交叉熵加权 At
-
梯度上升更新Actor参数
-
重新收集数据:由于策略已改变,必须用新的策略重新采样(On-policy),重新收集数据

On-policy vs Off-policy
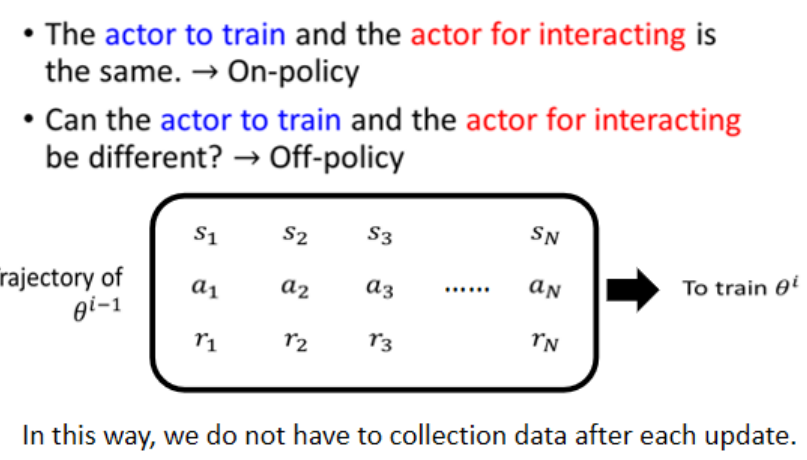
Off-policy 的代表方法:PPO(Proximal Policy Optimization),PPO 允许一定程度上“借用”旧策略的数据,同时控制策略变化幅度
听起来有点晕,李老师在课上也没有细说,查资料后我的理解Off-policy 强化学习的本质是:
“我(要训练的策略)不是亲自去做,而是看别人做,再从别人的经验中学习。”
类比总结和On-policy的区别就是:
-
On-policy:每更新一次策略,就必须重新采数据,慢又贵。
-
Off-policy:每次都用别人的策略来采集数据,然后训练你的模型(比如别人开车时采集的数据记录),但是你不能完全照搬别人的操作(因为别人的车可能技术更好),所以你要用算法纠正行为差异 。
这里有一些疑问需要解答,先了解两个概念:
行为策略:用来与环境交互、采集数据,不一定更新(通常固定)
目标策略:是你真正想要训练的策略,不断更新
疑问:如果行为策略不更新,那它的采样是不是就会重复、没有意义?为什么还能学?
答案是:不会。
即使行为策略是“固定的”,你从它那里采样的经验轨迹每次也会不同,原因有两个:1. 环境是动态的 / 有随机性,行为策略+环境共同决定采样轨迹,所以轨迹是多样的;2.行为策略本身是“随机策略”,行为策略即便固定,也有采样上的随机性
Critic
Critic 的概念
Critic 的作用是评估当前策略(Actor)的好坏,即预测在某个状态下,采用该 Actor 后可能获得的累积回报(Discounted Cumulative Reward),注意是个期望值,因为actor本身是有随机性
![]()
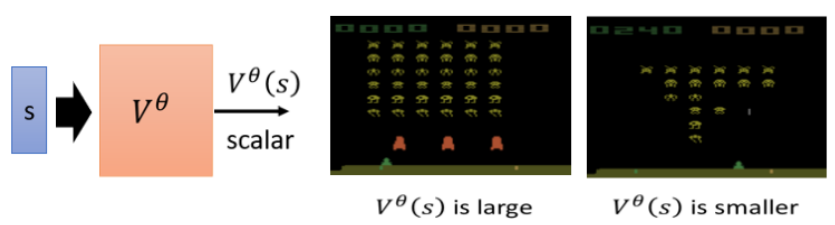
如何训练 Value Function(Critic)
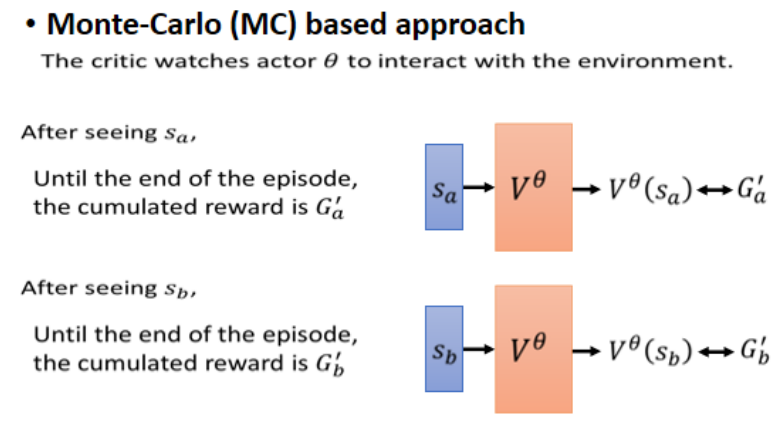
蒙特卡洛Monte-Carlo(MC)方法:
-
完整地让 Actor 玩一整局游戏,记录每个状态对应最终获得的 G 值(实际累积回报),然后训练 Critic 预测这些 G。
-
优点:简单直观。
-
缺点:需要完整回合,游戏太长或无终点时不适用。
时序差分Temporal-Difference(TD)方法:
-
使用部分轨迹更新估值。核心思想是:在不知道最终结果的情况下,通过当前奖励和下一步的估计结果来更新当前估计值
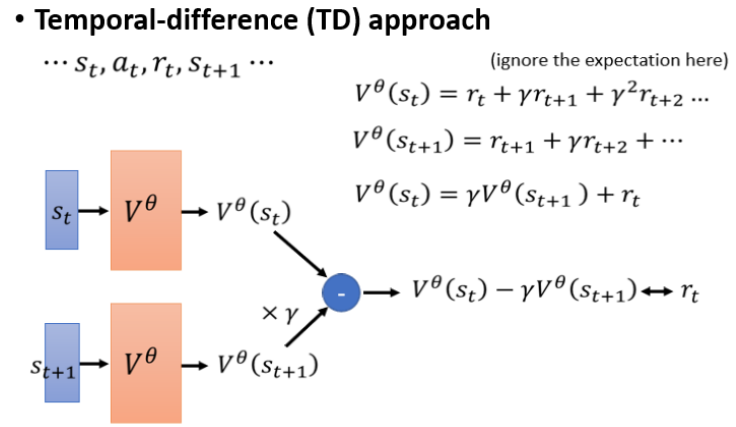
-
优点:无需完整回合,适合长或无限游戏。
-
缺点:更新可能有偏差。
MCvsTD
-
MC 使用真实累积奖励训练,更新慢但准确。
-
TD 使用估计值更新,快速但可能偏差。
-
没有绝对对错,取决于假设和实际需求。
举例:观察某一个 Actor跟环境互动玩了某一个游戏八次,当然这边为了简化计算,我们假设这些游戏都非常简单,都一个回合,就到两个回合就结束了。从下图V(sa)的算法就可以看出MC和TD的区别

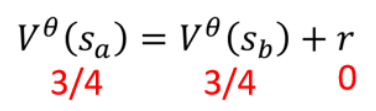

Critic 如何帮助训练 Actor
前面提到需要做标准化, 引入基线(Baseline) b,让评价结果“有正有负”,将 Gt′−b 作为最终评价量 At。这里b取多少本来是不知道的,现在可以确定了,b就是Critic估计的Actor后可能获得的累积回报V,注意这个只是一个期望值,因为Actor本身是有随机性的
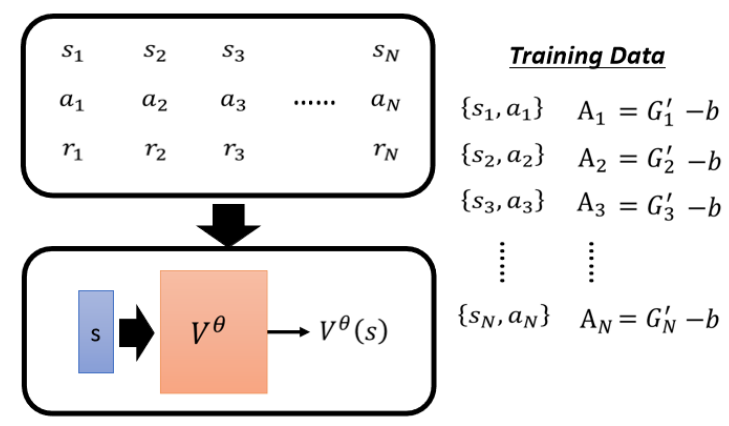
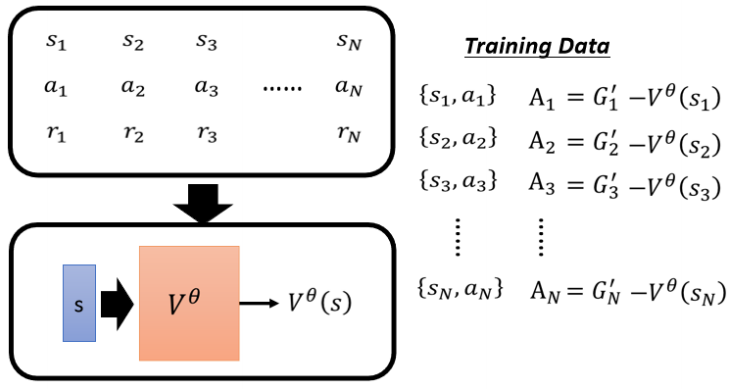
这样得到的At,如果大于0说明实际执行的动作 At 得到的结果好于平均值,是一个“好的动作",小于,说明该动作表现差于平均,是个“坏动作”。
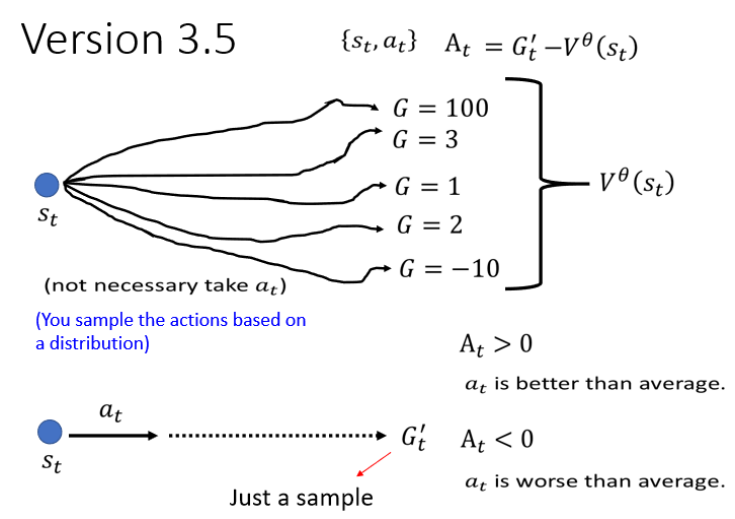
但是这种思路也不是完全没问题,用某个状态下的G减去平均值有可能会有极端情况,还有一种思路的用平均值减去平均值,就是:
-
用即时奖励
加上下一个状态的估值
来代替
,
-
这是对未来奖励的一步估计,更快、更稳定。

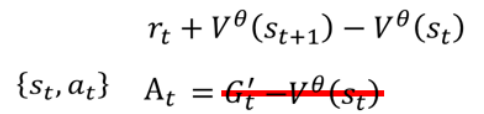
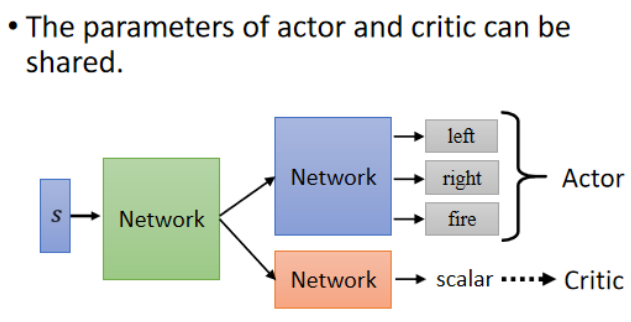
小技巧:Actor-Critic 网络共享结构
-
Actor 和 Critic 可以共享网络的前几层(例如 CNN 提取特征),仅在输出结构上有所区分:
-
Actor 输出 action 的概率分布。
-
Critic 输出一个标量的估值。
-
Deep Q Network (DQN):
-
Deep Q Network(DQN)是另一类强化学习方法,主要使用 Critic(Q function)来直接选动作。
-
DQN 有许多变形,如 Rainbow(融合多个改进技巧)。





