目录
一: 正则表达式
1.正则表达式概述
(1)正则表达式的定义
(2)正则表达式用途
2.基础正则表达式
(1)基础正则表达示例
1-查找特定字符
2-利用中括号“[]”来查找集合字符
3-查找行首“^”与行尾字符“$”
4-查找任意一个字符“.”与重复字符“*”
5-查找连续字符范围“{}”
(2)元字符总结
3.扩展正则表达式
二:文本处理器
1.sed 工具
(1)sed 命令常见用法
(2)用法示例
1-输出符合条件的文本(p 表示正常输出)
2-删除符合条件的文本(d)
3-替换符合条件的文本
4-迁移符合条件的文本
5-使用脚本编辑文件
6-sed 直接操作文件示例
2.awk 工具
(1)awk 常见用法
(2)用法示例
1-按行输出文本
2-按字段输出文本
3-通过管道、双引号调用 Shell 命令
3.sort 工具
4.uniq 工具
5.tr 工具
一: 正则表达式
1.正则表达式概述
(1)正则表达式的定义
(2)正则表达式用途
2.基础正则表达式
(1)基础正则表达示例
下面的操作需要提前准备一个名为 test.txt 的测试文件,文件具体内容如下所示。

1-查找特定字符


2-利用中括号“[]”来查找集合字符



查找包含数字的行可以通过“grep -n‘[0-9]’test.txt”命令来实现。

3-查找行首“^”与行尾字符“$”
[root@localhost ~]# grep -n '^the' test.txt


当查询空白行时,执行“grep -n‘^$’test.txt”命令即可。
[root@localhost ~]# grep -n '^$' test.txt
4-查找任意一个字符“.”与重复字符“*”
[root@localhost ~]# grep -n 'w..d' test.txt
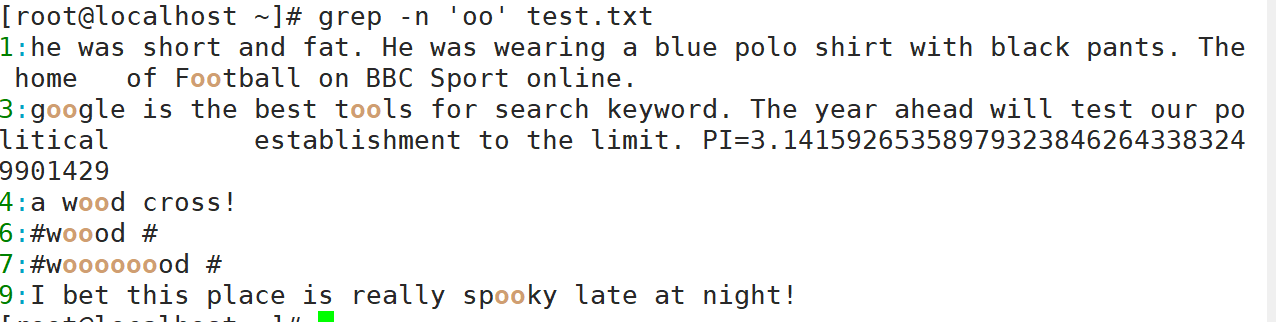
[root@localhost ~]# grep -n 'ooo*' test.txt3:The home of F oo tball on BBC Sport online.5:g oo gle is the best t oo ls for search keyword.8:a w oo d cross!11:#w ooo d #12:#w ooooooo d #14:I bet this place is really sp oo ky late at night!
查询以 w 开头 d 结尾,中间包含至少一个 o 的字符串
[root@localhost ~]# grep -n 'woo*d' test.txt
执行以下命令即可查询以 w 开头 d 结尾,中间的字符可有可无的字符串。
[root@localhost ~]# grep -n 'w.*d' test.txt
执行以下命令即可查询任意数字所在行。
root@localhost ~]# grep -n '[0-9][0-9]*' test.txt
5-查找连续字符范围“{}”
查询两个 o 的字符。
[root@localhost ~]# grep -n 'o\{2\}' test.txt
查询以 w 开头以 d 结尾,中间包含 2~5 个 o 的字符串。
[root@localhost ~]# grep -n 'wo\{2,5\}d' test.txt
查询以 w 开头以 d 结尾,中间包含 2 个或 2 个以上 o 的字符串。
[root@localhost ~]# grep -n 'wo\{2,\}d' test.txt
(2)元字符总结
| 元字符 | 作用 |
| ^ | 匹配输入字符串的开始位置。除非在方括号表达式中使用,表示不包含该字符集合。要匹配 “^” 字符本身,请使用 “\^” |
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 “$” 也匹配 ‘\n’ 或 ‘\r’ 。 要匹配 “$” 字符本身,请使用 “\$” |
| . | 匹配除 “\r\n” 之外的任何单个字符 |
| \ | 反斜杠,又叫转义字符,去除其后紧跟的元字符或通配符的特殊意义 |
| * | 匹配前面的子表达式零次或多次。要匹配 “*” 字符,请使用 “\*” |
| [] | 字符集合。匹配所包含的任意一个字符。例如, “[abc]” 可以匹配 “plain” 中的 “a" |
| [^] | 赋值字符集合。匹配未包含的一个任意字符。例如, “[^abc]” 可以匹配 “plain” 中任何一个字母 |
| [n1-n2] | 字符范围。匹配指定范围内的任意一个字符。例如, “[a-z]” 可以匹配 “a” 到 “z” 范围内的任意一个 小写字母字符。 注意:只有连字符( - )在字符组内部,并且出现在两个字符之间时,才能表示字符的范围;如 果出现在字符组的开头,则只能表示连字符本身 |
| {n} | n 是一个非负整数,匹配确定的 n 次。例如, “o{2}” 不能匹配 “Bob” 中的 “o” ,但是能匹配 “food” 中 的 “oo" |
| {n,} | n 是一个非负整数,至少匹配 n 次。例如, “o{2,}” 不能匹配 “Bob” 中的 “o” ,但能匹配 “foooood” 中 的所有 o 。 “o{1,}” 等价于 “o+” 。 “o{0,}” 则等价于 “o*" |
| {n,m} | m 和 n 均为非负整数,其中 n<=m ,最少匹配 n 次且最多匹配 m 次 |
3.扩展正则表达式
| 元字符 | 作用与示例 |
| + | 作用:重复一个或者一个以上的前一个字符 示例:执行 “egrep -n 'wo+d' test.txt” 命令,即可查询 "wood" "woood" "woooooood" 等字符串 |
| ? | 作用:零个或者一个的前一个字符 示例:执行 “egrep -n 'bes?t' test.txt” 命令,即可查询 “bet”“best” 这两个字符串 |
| | | 作用:使用或者( or )的方式找出多个字符 示例:执行 “egrep -n 'of|is|on' test.txt” 命令即可查询 "of" 或者 "if" 或者 "on" 字符串 |
| () | 作用:查找 “ 组 ” 字符串 示例: “egrep -n 't(a|e)st' test.txt” 。 “tast” 与 “test” 因为这两个单词的 “t” 与 “st” 是重复的,所以将 “a” 与 “e” 列于 “()” 符号当中,并以 “|” 分隔,即可查询 "tast" 或者 "test" 字符串 |
| ()+ | 作用:辨别多个重复的组 示例: “egrep -n 'A(xyz)+C' test.txt” 。该命令是查询开头的 "A" 结尾是 "C" ,中间有一个以上的 "xyz" 字 符串的意思 |
二:文本处理器
1.sed 工具
- 读取:sed 从输入流(文件、管道、标准输入)中读取一行内容并存储到临时的缓 冲区中(又称模式空间,pattern space)。
- 执行:默认情况下,所有的 sed 命令都在模式空间中顺序地执行,除非指定了行 的地址,否则 sed 命令将会在所有的行上依次执行。
- 显示:发送修改后的内容到输出流。在发送数据后,模式空间将会被清空。 在所有的文件内容都被处理完成之前,上述过程将重复执行,直至所有内容被处理完。
(1)sed 命令常见用法
通常情况下调用 sed 命令有两种格式,如下所示。其中,“参数”是指操作的目标文件, 当存在多个操作对象时用,文件之间用逗号“,”分隔;而 scriptfile 表示脚本文件,需要用“-f” 选项指定,当脚本文件出现在目标文件之前时,表示通过指定的脚本文件来处理输入的目标 文件。
sed [ 选项 ] ' 操作 ' 参数sed [ 选项 ] -f scriptfile 参数
- -e 或--expression=:表示用指定命令或者脚本来处理输入的文本文件。
- -f 或--file=:表示用指定的脚本文件来处理输入的文本文件。
- -h 或--help:显示帮助。
- -n、--quiet 或 silent:表示仅显示处理后的结果。
- -i:直接编辑文本文件。
- a:增加,在当前行下面增加一行指定内容。
- c:替换,将选定行替换为指定内容。
- d:删除,删除选定的行。
- i:插入,在选定行上面插入一行指定内容。
- p:打印,如果同时指定行,表示打印指定行;如果不指定行,则表示打印所有内 容;如果有非打印字符,则以 ASCII 码输出。其通常与“-n”选项一起使用。
- s:替换,替换指定字符。
- y:字符转换。
(2)用法示例
test.txt 文件为例进行演示
1-输出符合条件的文本(p 表示正常输出)
[root@localhost ~]# sed -n 'p' test.txt //输出所有内容,等同于
[root@localhost ~]# sed -n '1,5{p;n}' test.txt //输出第 1~5 行之间的奇数行(第 1、3、5 行)
[root@localhost ~]# sed -n '10,${n;p}' test.txt //输出第 10 行至文件尾之间的偶数行
以上是 sed 命令的基本用法,sed 命令结合正则表达式时,格式略有不同,正则表达式 以“/”包围。例如
[root@localhost ~]# sed -n '/the/p' test.txt //输出包含 the 的行
[root@localhost ~]# sed -n '4,/the/p' test.txt //输出从第 4 行至第一个包含 the 的行
[root@localhost ~]# sed -n '/the/=' test.txt //输出包含 the 的行所在的行号,等号(=)用来输出行号
[root@localhost ~]# sed -n '/^PI/p' test.txt //输出以 PI 开头的行
[root@localhost ~]# sed -n '/[0-9]$/p' test.txt //输出以数字结尾的行
[root@localhost ~]# sed -n '/\/p' test.txt //输出包含单词 wood 的行,\、\>代表单词边界
2-删除符合条件的文本(d)
以下示例分别演示了 sed 命令的几种常用删除用法
[root@localhost ~]# nl test.txt | sed '3d' //删除第 3 行
[root@localhost ~]# nl test.txt | sed '3,5d' //删除第 3~5 行
[root@localhost ~]# nl test.txt |sed '/cross/d'//删除包含 cross 的行,原本的第 8 行被删除;如果要删除不包含 cross 的行,用!符号表示取反操作, 如'/cross/!d'
[root@localhost ~]# sed '/^[a-z]/d' test.txt //删除以小写字母开头的行
[root@localhost ~]# sed '/\.$/d' test.txt //删除以"."结尾的行
[root@localhost ~]# sed '/^$/d' test.txt //删除所有空行
3-替换符合条件的文本
在使用 sed 命令进行替换操作时需要用到 s(字符串替换)、c(整行/整块替换)、y (字符转换)命令选项,常见的用法如下所示。
sed 's/the/THE/' test.txt //将每行中的第一个 the 替换为 THE
sed 's/l/L/2' test.txt //将每行中的第 2 个 l 替换为 L
sed 's/the/THE/g' test.txt //将文件中的所有 the 替换为 THE第 17 页 共 27 页
sed 's/o//g' test.txt //将文件中的所有 o 删除(替换为空串)
sed 's/^/#/' test.txt //在每行行首插入#号
sed '/the/s/^/#/' test.txt //在包含 the 的每行行首插入#号
sed 's/$/EOF/' test.txt //在每行行尾插入字符串 EOF
sed '3,5s/the/THE/g' test.txt //将第 3~5 行中的所有 the 替换为 THE
sed '/the/s/o/O/g' test.txt //将包含 the 的所有行中的 o 都替换为 O
4-迁移符合条件的文本
在使用 sed 命令迁移符合条件的文本时,常用到以下参数.
- H:复制到剪贴板;
- g、G:将剪贴板中的数据覆盖/追加至指定行;
- w:保存为文件;
- r:读取指定文件;
- a:追加指定内容。
sed '/the/{H;d};$G' test.txt //将包含 the 的行迁移至文件末尾,{;}用于多个操作
sed '1,5{H;d};17G' test.txt //将第 1~5 行内容转移至第 17 行后
sed '/the/w out.file' test.txt //将包含 the 的行另存为文件 out.file
sed '/the/r /etc/hostname' test.txt //将文件/etc/hostname 的内容添加到包含 the 的每行以后
sed '3aNew' test.txt //在第 3 行后插入一个新行,内容为 New
sed '/the/aNew' test.txt //在包含 the 的每行后插入一个新行,内容为 New
sed '3aNew1\nNew2' test.txt //在第 3 行后插入多行内容,中间的\n 表示换行
5-使用脚本编辑文件
使用 sed 脚本将多个编辑指令存放到文件中(每行一条编辑指令),通过“-f”选项来调 用。例如执行以下命令即可将第 1~5 行内容转移至第 17 行后。
sed '1,5{H;d};17G' test.txt //将第 1~5 行内容转移至第 17 行后
6-sed 直接操作文件示例
编写一个脚本,用来调整 vsftpd 服务配置,要求禁止匿名用户,但允许本地用户(也 允许写入)
[root@localhost ~]# vim local_only_ftp.sh
#!/bin/bash
# 指定样本文件路径、配置文件路径
SAMPLE="/usr/share/doc/vsftpd-3.0.2/EXAMPLE/INTERNET_SITE/vsftpd.conf " CONFIG="/etc/vsftpd/vsftpd.conf"
# 备份原来的配置文件,检测文件名为/etc/vsftpd/vsftpd.conf.bak 备份文件是否存在, 若不存在则使用 cp 命令进行文件备份
[ ! -e "$CONFIG.bak" ] && cp $CONFIG $CONFIG.bak
# 基于样本配置进行调整,覆盖现有文件
sed -e '/^anonymous_enable/s/YES/NO/g' $SAMPLE > $CONFIG
sed -i -e '/^local_enable/s/NO/YES/g' -e '/^write_enable/s/NO/YES/g' $CONFIG
grep "listen" $CONFIG || sed -i '$alisten=YES' $CONFIG
# 启动 vsftpd 服务,并设为开机后自动运行
systemctl restart vsftpd
systemctl enable vsftpd
[root@localhost ~]# chmod +x local_only_ftp.sh
2.awk 工具
(1)awk 常见用法
通常情况下 awk 所使用的命令格式如下所示,其中,单引号加上大括号“{}”用于设置对 数据进行的处理动作。awk 可以直接处理目标文件,也可以通过“-f”读取脚本对目标文件进 行处理。
awk 选项 '模式或条件 {编辑指令}' 文件 1 文件 2 … //过滤并输出文件中符合条件的内容
awk -f 脚本文件 文件 1 文件 2 … //从脚本中调用编辑指令,过滤并输出内容
前面提到 sed 命令常用于一整行的处理,而 awk 比较倾向于将一行分成多个“字段”然后 再进行处理,且默认情况下字段的分隔符为空格或 tab 键。awk 执行结果可以通过 print 的 功能将字段数据打印显示。在使用 awk 命令的过程中,可以使用逻辑操作符“&&”表示“与”、“||” 表示“或”、“!”表示“非”;还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、 乘、除、取余和乘方。 在 Linux 系统中/etc/passwd 是一个非常典型的格式化文件,各字段间使用“:”作为分 隔符隔开,Linux 系统中的大部分日志文件也是格式化文件,从这些文件中提取相关信息是 运维的日常工作内容之一。若需要查找出/etc/passwd 的用户名、用户 ID、组 ID 等列,执 行以下 awk 命令即可。
[root@localhost ~]# awk -F ':' '{print $1,$3,$4}' /etc/passwd
awk 包含几个特殊的内建变量(可直接用)如下所示:
- FS:指定每行文本的字段分隔符,默认为空格或制表位。
- NF:当前处理的行的字段个数。
- NR:当前处理的行的行号(序数)。
- $0:当前处理的行的整行内容。
- $n:当前处理行的第 n 个字段(第 n 列)。
- FILENAME:被处理的文件名。
- RS:数据记录分隔,默认为\n,即每行为一条记录。
(2)用法示例
1-按行输出文本
awk '{print}' test.txt //输出所有内容,等同于 cat test.txt
awk '{print $0}' test.txt //输出所有内容,等同于 cat test.txt
awk 'NR==1,NR==3{print}' test.txt //输出第 1~3 行内容
awk '(NR>=1)&&(NR//输出第 1~3 行内容
awk 'NR==1||NR==3{print}' test.txt //输出第 1 行、第 3 行内容
awk '(NR%2)==1{print}' test.txt //输出所有奇数行的内容
awk '(NR%2)==0{print}' test.txt //输出所有偶数行的内容
awk '/^root/{print}' /etc/passwd //输出以 root 开头的行
awk '/nologin$/{print}' /etc/passwd //输出以 nologin 结尾的行
awk 'BEGIN {x=0};/\/bin\/bash$/{x++};END {print x}' /etc/passwd //统计以/bin/bash 结尾的行数,等同于 grep -c "/bin/bash$" /etc/passwd
awk 'BEGIN{RS=""};END{print NR}' /etc/squid/squid.conf //统计以空行分隔的文本段落数
2-按字段输出文本
awk '{print $3}' test.txt //输出每行中(以空格或制表位分隔)的第 3 个字段
awk '{print $1,$3}' test.txt //输出每行中的第 1、3 个字段
awk -F ":" '$2==""{print}' /etc/shadow //输出密码为空的用户的 shadow 记录
awk 'BEGIN {FS=":"}; $2==""{print}' /etc/shadow //输出密码为空的用户的 shadow 记录
awk -F ":" '$7~"/bash"{print $1}' /etc/passwd //输出以冒号分隔且第 7 个字段中包含/bash 的行的第 1 个字段
awk '($1~"nfs")&&(NF==8){print $1,$2}' /etc/services //输出包含 8 个字段且第 1 个字段中包含 nfs 的行的第 1、2 个字段
awk -F ":" '($7!="/bin/bash")&&($7!="/sbin/nologin"){print}' /etc/passwd //输出第 7 个字段既不为/bin/bash 也不为/sbin/nologin 的所有行
3-通过管道、双引号调用 Shell 命令
awk -F: '/bash$/{print | "wc -l"}' /etc/passwd //调用 wc -l 命令统计使用 bash 的用户个数,等同于 grep -c "bash$" /etc/passwd
awk 'BEGIN {while ("w" | getline) n++ ; {print n-2}}' //调用 w 命令,并用来统计在线用户数
awk 'BEGIN { "hostname" | getline ; print $0}' //调用 hostname,并输出当前的主机名
3.sort 工具
在 Linux 系统中,常用的文件排序工具有三种:sort、uniq、wc 。本章将介绍前两种 工具的用法。sort 是一个以行为单位对文件内容进行排序的工具,也可以根据不同的数据类型来排 序。例如数据和字符的排序就不一样。sort 命令的语法为“sort [选项] 参数”,其中常用的选 项包括以下几种。
- -f:忽略大小写;
- -b:忽略每行前面的空格;
- -M:按照月份进行排序;
- -n:按照数字进行排序;
- -r:反向排序;
- -u:等同于 uniq,表示相同的数据仅显示一行;
- -t:指定分隔符,默认使用[Tab]键分隔;
- -o 输出文件>:将排序后的结果转存至指定文件;
- -k:指定排序区域。
4.uniq 工具
Uniq 工具在 Linux 系统中通常与 sort 命令结合使用,用于报告或者忽略文件中的重复 行。具体的命令语法格式为:uniq [选项] 参数。其中常用选项包括以下几种。
- -c:进行计数;
- -d:仅显示重复行;
- -u:仅显示出现一次的行。
5.tr 工具
tr 命令常用来对来自标准输入的字符进行替换、压缩和删除。可以将一组字符替换之后 变成另一组字符,经常用来编写优美的单行命令,作用很强大。 tr 具体的命令语法格式为:
tr [选项] [参数]
其常用选项包括以下内容。
- -c:取代所有不属于第一字符集的字符;
- -d:删除所有属于第一字符集的字符;
- -s:把连续重复的字符以单独一个字符表示;
- -t:先删除第一字符集较第二字符集多出的字符。






