π0.5 论文
通过异构数据协同训练与分层推理,用中等规模的目标数据(400小时)实现了大规模泛化能力,为现实世界机器人学习提供了新范式。


高层推理(high-level) 根据当前观测和任务指令预测子任务(如“打开抽屉”)。低层推理(low-level) 基于当前观测和子任务生成具体动作序列。低级推理动作能够受益于其他机器人收集的数据;高级推理能从网络上的语义示例,高级注释预测中受益。
- 输入:多摄像头图像、语言指令、机器人本体状态(关节位姿)。
- 输出:高层语义子任务(文本 token)和底层动作序列(连续向量)。
- 模态交互:图像通过视觉编码器嵌入,文本和动作通过独立编码器处理,通过双向注意力机制(不同于 LLM 的因果注意力)交互。
- 动作专家(Action Expert:专用于 flow matching 的小型 Transformer,生成高精度连续动作。
- 注意力掩码:限制动作 token 与文本/图像 token 的单向信息流,避免信息泄露。

模型的核心分布为 π θ ( a t : t + H , ℓ ^ ∣ o t , ℓ ) \pi_{\theta}(\mathbf{a}_{t:t+H},\hat{\ell}|\mathbf{o}_{t},\ell) πθ(at:t+H,ℓ^∣ot,ℓ) 其中 ℓ \ell ℓ 是整体任务提示, ℓ ^ \hat{\ell} ℓ^ 是各个子任务的提示。
将联合分布拆解为高层次和低层次两个子任务:
π θ ( a t : t + H , ℓ ^ ∣ o t , ℓ ) = π θ ( a t : t + H ∣ o t , ℓ ^ ) π θ ( ℓ ^ ∣ o t , ℓ ) \pi_\theta(\mathbf{a}_{t:t+H},\hat{\ell}\left|\mathbf{o}_t,\ell\right)=\pi_\theta(\mathbf{a}_{t:t+H}\left|\mathbf{o}_t,\hat{\ell}\right.)\pi_\theta(\hat{\ell}\left|\mathbf{o}_t,\ell\right) πθ(at:t+H,ℓ^∣ot,ℓ)=πθ(at:t+H ot,ℓ^)πθ(ℓ^∣ot,ℓ)
动作的 token 采用 π 0 − f a s t \pi_0-fast π0−fast 的 token,但这种离散化表示不适合实时推理,因为需要昂贵的自回归解码推理,故而提出了一个结合 FAST 分词器和迭代整合流场来预测动作:
min θ E D , τ , ω [ H ( x 1 : M , f θ l ( o t , l ) ) ⏟ 文本token交叉熵损失 + α ∥ ω − a t : t + H − f θ a ( a t : t + H τ , ω , o t , l ) ∥ 2 ⏟ 流匹配MSE损失 ] \min_{\theta}\mathbb{E}_{D,\tau,\omega}\left[\underbrace{\mathcal{H}(x_{1:M},f_{\theta}^{l}(o_{t},l))}_{\text{文本token交叉熵损失}}+\alpha\underbrace{\|\omega-a_{t:t+H}-f_{\theta}^{a}(a_{t:t+H}^{\tau,\omega},o_{t},l)\|^{2}}_{\text{流匹配MSE损失}}\right] θminED,τ,ω 文本token交叉熵损失 H(x1:M,fθl(ot,l))+α流匹配MSE损失 ∥ω−at:t+H−fθa(at:t+Hτ,ω,ot,l)∥2
阶段一:预训练(VLM模式)
- 仅使用文本token损失(α=0)
- 将动作视为特殊文本 token(FAST编码),继承语言模型强语义能力
- 采用
<control mode> joint/end effector区分末端执行器和关节 - 各数据集动作维度单独归一化至 [-1,1](采用1%与99%分位数)
| 数据类型 | 符号 | 数据量 | 关键特性 | 作用 |
|---|---|---|---|---|
| 移动机械臂家庭数据 | MM | 400小时 | 100+真实家庭环境,清洁/整理任务(图7) | 目标场景直接适配 |
| 多环境静态机械臂数据 | ME | 跨200+家庭 | 轻量化单/双机械臂,安装于固定平台 | 增强物体操作多样性 |
| 跨本体实验室数据 | CE | 含OXE数据集 | 桌面任务(叠衣/餐具收纳等)+移动/固定基座机器人 | 迁移无关场景技能(如咖啡研磨) |
| 高层子任务标注数据 | HL | 全数据集标注 | 人工标注原子子任务(如"拾取枕头")+关联定位框 | 实现分层推理能力 |
| 多模态网络数据 | WD | 百万级样本 | 图像描述(COCO)、问答(VQAv2)、室内场景物体检测(扩展标注) | 注入语义先验知识 |
阶段二:微调(混合模式
- 引入动作专家分支,逐步提升α
- 流匹配分支从文本 token 条件生成动作,建立语言-动作关联
推理流程
- 自回归解码:生成语义子任务 ℓ ^ \hat{\ell} ℓ^(如“拿起盘子”)
- 条件去噪:基于 ℓ ^ \hat{\ell} ℓ^ 执行10步流匹配去噪,输出连续动作 a t : t + H a_{t:t+H} at:t+H
实验结果
Q1: π 0.5 \pi_{0.5} π0.5 能否有效泛化到全新环境中的复杂多阶段任务?
在三个未曾见过的真实环境中,使用两种类型的机器人,每个机器人被指示执行卧室和厨房的清洁任务。比较了大致对应于每个任务成功完成的步骤百分比。

A!: 能够在各种家庭任务中持续取得成功。泛化水平超过了以往的 VLA 模型。
Q2: π 0.5 \pi_{0.5} π0.5 泛化能力随训练数据中不同环境的数量如何变化?
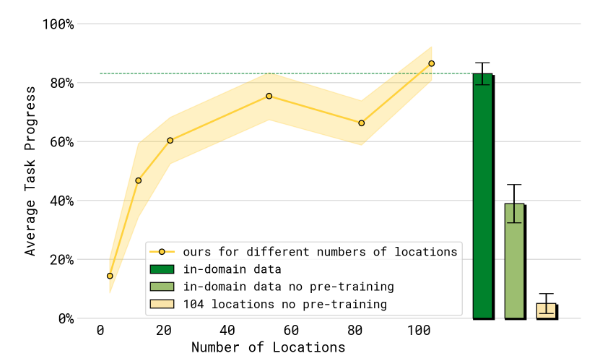
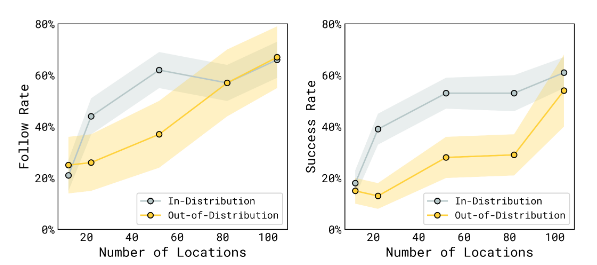
A2:随着训练位置的增加,任务之间的平均表现通常会有所提高。随着训练数据中地点数量的增加,语言跟随表现和成功率都有所提高。
Q3: π 0.5 \pi_{0.5} π0.5 各个共同训练成分对最终性能的贡献如何?
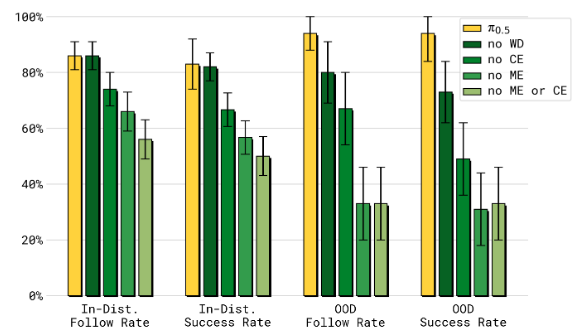
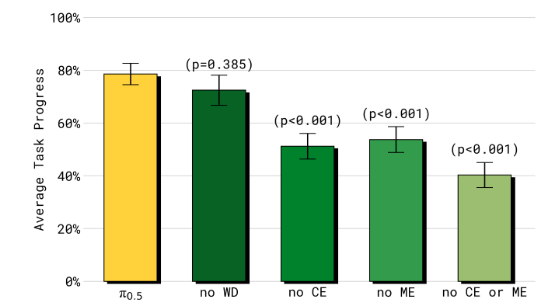
A3: π 0.5 \pi_{0.5} π0.5 从跨刚体(ME和CE)转移中获得了相当大的好处。移除网络数据(WD)会导致模型在处理异常分布(OOD)对象时表现显著变差。
Q4: π 0.5 \pi_{0.5} π0.5 与 π 0 V L A \pi_0 VLA π0VLA 相比?
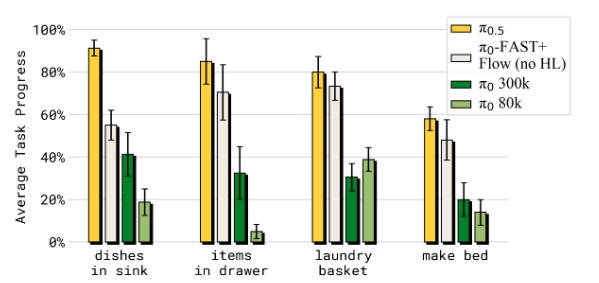
A4: π 0.5 \pi_{0.5} π0.5 显著优于 π 0 \pi_0 π0 以及增强版本 p i 0 − pi_0- pi0−-FAST+FLOW。 π 0 \pi_0 π0-FAST+FLOW 是按照混合训练设置的,但仅用包含机器人动作的数据进行训练,因此无法执行高层次推理。
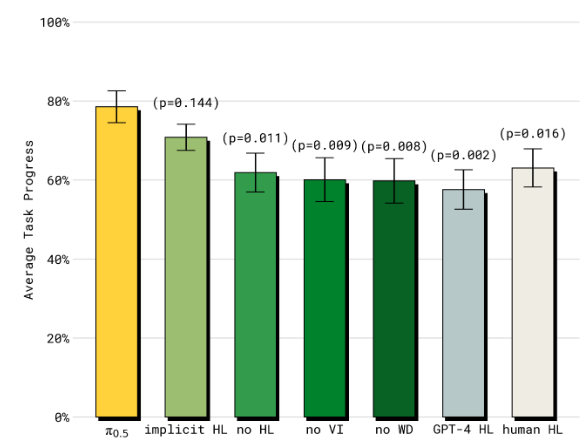
Q5: π 0.5 \pi_{0.5} π0.5 的高层推理组件有多重要?与单一的低层次推理以及显式的高层基线相比如何?
不足之处
- π 0.5 \pi_{0.5} π0.5 虽然展示了广泛的泛化能力,但在某些环境中仍存在挑战,如不熟悉的抽屉把手或机器人难以打开的橱柜。
- 一些行为在部分可观测性方面存在挑战,比如:机器人手臂遮挡了应该擦拭的溢出物。
- 在某些情况下,高层子任务推理容易分心,比如:在收拾物品时多次关闭和打开抽屉。
目前仅能处理的是相对简单的提示。
)


)

)
