在深度学习,尤其是计算机视觉任务中,backbone(骨干网络),neck(颈部),head(头部)是网络的关键组成部分,各自承担了不同的功能:
1,总署:
Backbone, 译作骨干网络,主要指用于特征提取的,已在大型数据集(例如ImageNet|COCO等)上完成预训练,拥有预训练参数的卷积神经网络,例如:ResNet-50、Darknet53等;
Head,译作检测头,主要用于预测目标的种类和位置(bounding boxes),当然也可以有轨迹位置等多样的head输出
在Backone和Head之间,会添加一些用于收集不同阶段中特征图的网络层,通常称为Neck。
简而言之,基于深度学习的目标检测模型的结构是这样的:输入->主干->脖子->头->输出。主干网络提取特征,脖子提取一些更复杂的特征,然后头部计算预测输出。
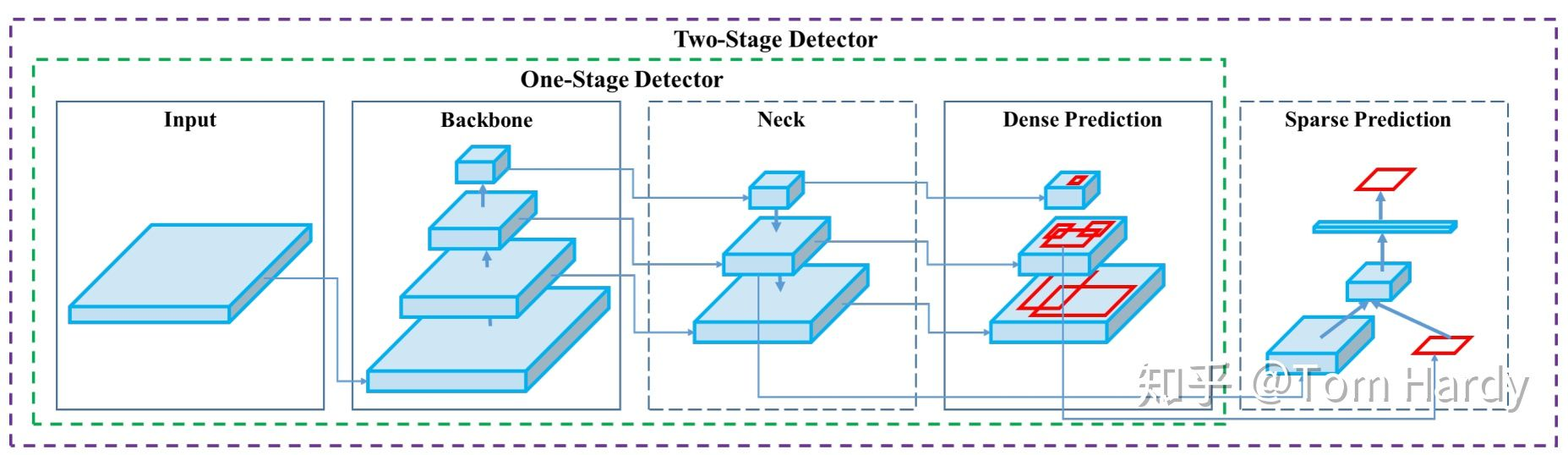
2,Bcakbone(骨干网络)
解释:主干网络,是模型的基础部分,负责从输入数据(如图像)中提取多层次,多尺度的特征,如边缘,纹理,形状等低级特征,以及物体类别,语义等高级特征。它通常由多个卷积层,池化层构成,预训练的backbone(如在大规模图像数据集上训练的模型)可迁移到其他任务,加速训练并提升性能。
举例:
ResNet:通过残差连接解决深层网络梯度小时问题,广泛用于图像分类,目标检测等任务,例如在图像分类中,ResNet提取图像的丰富特征,最后通过全连接层输出类别概率。
VGG:由多个卷积层和池化层堆叠,结构简单但有效,能提取图像的多层次特征,曾在ImageNet竞赛中表现优异
3,Neck(颈部)
解释:位于backbone和head之间,如同桥梁,对骨干网络提取的特征进一步处理,如融合多尺度特征,调整特征维度(降维或升维),增强特征表达能力,以适应后续任务需求
举例:
FPN(特征金字塔网络):在目标检测中,FPN融合backbone不同层级的特征(如高层语义信息与低层细节信息),生成多尺度特征图,提升对不同大小目标(如大物体和小物体)的检测能力
PANet:在FPN基础上引入路径聚合机制,优化特征融合结果,增强不同尺度间的信息流动,常用于实例分割等任务
4,Head(头部)
解释:网络的最后部分,负责直行具体任务,如分类,目标检测,语义分割等,它将neck处理后的特征映射到任务所需输出空间(如类别概率,边界框坐标,像素级分割结果等)
举例:
分类头:在图像中,ResNet的head通过全局平均池化(GAP)和全连接层,将backbone提取特征映射为类别概率,如判断图象是”猫“还是”狗“
检测头:在YOLO目标检测模型中,head直接预测目标位置(边界框坐标)和类别,输出多个边界框及对应类别概率,实现端对端的目标检测
分割头:在U-Net语义分割模型中,head通过卷积和上采样操作,将特征映射为输入图像同尺寸的分割结果,为每个像素分配类别标签(如区分图像中的”道路“”车辆“”行人“)
这三个部分模块化设计使得深度学习模型在不同任务中更具有通用性和灵活性,例如在目标检测框架Faster RCNN中,
ResNet作为backbone提取特征,RPN(Region Proposal Network)作为neck生成候选框,分类头和回归头作为head完成目标分类和定位。
特此解释,
分类头负责对特征图中的每个候选区域(如锚框)进行类别预测,输出其属于不同类别的概率。它通过对特征的分析,判断该区域是否包含目标以及具体属于哪一类(如汽车、行人、交通标志等)。
- 在单阶段目标检测算法 RetinaNet 中,分类头由多个卷积层堆叠而成,每一层后接 ReLU 激活函数,最终通过 sigmoid 激活函数输出每个锚框对应的类别概率。例如,判断某个锚框内是 “汽车” 的概率为 0.9,是 “行人” 的概率为 0.1。
回归头用于预测候选区域边界框的偏移量,调整其位置和大小,使 边界框更精确地匡助目标,输出的是坐标,宽度,高度等维度变化量,不涉及类别判断。
- RetinaNet 的回归头结构与分类头类似,但最后一层不经过激活函数,直接输出回归偏移量。例如,预测某锚框的中心坐标需向右移动 5 个像素,高度需增加 10 个像素,从而优化边界框的定位。
自回归头深度学习模型中用于实现自回归生成机制的关键组件,常见于自然语言处理、语音合成、视频生成等序列生成任务。其核心特点是在生成序列时,每个元素的预测依赖于之前已生成的元素,通过递归方式逐步生成完整序列,确保生成内容的逻辑和语义连贯性。
- 自然语言处理(NLP):
在 GPT 系列模型中,自回归头负责逐词生成文本。如生成句子 “我爱自然语言处理” 时,先预测 “我”,再基于 “我” 预测 “爱”,接着基于 “我爱” 预测 “自然”,依此类推,每一步都依赖前文内容。

)



