25年4月来自Amazon 公司、Brown 大学和 Northestern 大学的论文“ViTa-Zero: Zero-shot Visuotactile Object 6D Pose Estimation”。
目标 6D 姿态估计是机器人技术中的一项关键挑战,尤其对于操作任务而言。虽然先前结合视觉和触觉(视觉触觉)信息的研究已显示出良好的前景,但由于视觉触觉数据有限,这些方法往往难以推广。本文介绍 ViTa-Zero,一个零样本视觉触觉姿态估计框架。关键创新在于利用视觉模型作为其主干,并基于从触觉和本体感受观察中得出的物理约束进行可行性检查和测试时间优化。具体而言,将夹持器与目标的相互作用建模为弹簧质量系统,其中触觉传感器产生吸引力,本体感受产生排斥力。通过在真实机器人设置上的实验验证该框架,证明其在代表性视觉主干和操作场景(包括抓取、目标拾取和双手交接)中的有效性。与视觉模型相比,该方法克服在跟踪手中目标姿态时一些严重的故障模式。在实验中,与 FoundationPose 相比,本方法显示 ADD-S 中 AUC 平均增加 55%,ADD 中 AUC 平均增加 60%,同时位置误差降低 80%。
机器人要想像人类一样智能地操控目标,必须能够准确感知其所在环境的状态。这种感知的一个关键方面是目标的六维姿态估计,即估计其在三维空间中的位置和方向,这是目标状态的关键表征 [1]。准确的姿态估计可以提升基于状态操控策略的性能,并提高学习效率和成功率 [2–8]。先前的研究主要集中于实例级 [9–12]、类别级 [13–15] 以及近期出现的新型目标估计 [16– 20]。尽管取得了这些进展,但与端到端视觉运动方法相比,基于状态的方法在实际应用中仍然面临着巨大的挑战 [2, 3, 21, 22]。这是因为在现实场景中,尤其是在接触频繁和手持操控任务中,姿态估计面临着诸多挑战,这些任务的特点是频繁的遮挡和动态交互 [5, 23]。
为了更好地估计手中目标的姿态,之前的研究探索视觉和触觉 (visuotactile) 感官观察的结合 [23–32]。这些研究已经显示出抓取和手持操作任务的改进,因为触觉传感器可以显示目标被遮挡的部分以增强操作过程中的姿态估计。然而,这带来一些实际挑战:(1)由于触觉传感器的脆弱性和多样性,收集视觉触觉数据集非常艰巨,因此难以在现实世界中扩展 [33]。虽然模拟提供一种潜在的解决方案,但模拟与现实之间的差距仍然很大 [7, 25, 26, 34];(2)视觉触觉模型通常会过拟合单一硬件设置和涉及丰富接触信号的场景,例如手中目标姿态估计,并且难以在静态和未遮挡场景中与视觉模型相提并论; (3)由于触觉数据的引入以及触觉传感器和夹持器的不一致性,将用于视觉模型的泛化技术应用于这些视觉触觉模型并非易事。因此,大多数模型都是传感器特定的、实例级的,这限制了它们的实用性。
本文提出 ViTa-Zero 框架,该框架通过零样本整合视觉和触觉信息来估计和跟踪新目标的 6D 姿态。
给定一个刚性目标 O,估计(在相机坐标系中)其位姿 T = (R, t) ,由其方向 R 和位置 t 组成。根据新型目标位姿估计的问题设置 [16, 17],假设目标O 的 3D 网格 M_O 是给定的或可重建的 [37, 38]。使用 RGB-D 传感器观测目标 O,并且至少在初始帧可见。
机器人。机器人 R 通过刚性连杆和关节操纵目标 O。假设机器人运动学模型和零件网格是给定的,例如通过统一机器人描述格式 (URDF),以便能够精确计算机器人的末端执行器位姿。使用手-眼标定获得末端执行器和相机坐标系之间的相对变换 [39]。
传感器。机器人 R 配备触觉传感器 S,其安装位置已知。假设传感器仅与目标 O 接触,不与自身接触。虽然主要关注基于触素(Taxel)的传感器,但该框架可以扩展到其他类型的传感器。
框架由三个模块组成:视觉估计、可行性检查和触觉改进。框架概览如图所示。首先,视觉模型估计姿态,记为 T。然后,用源自触觉信号和本体感受的约束来评估 T 的可行性。如果 T 不满足这些约束,将使用触觉和本体感受观测数据,通过测试时优化算法对其进行改进,最终得到姿态估计值,记为 T∗。
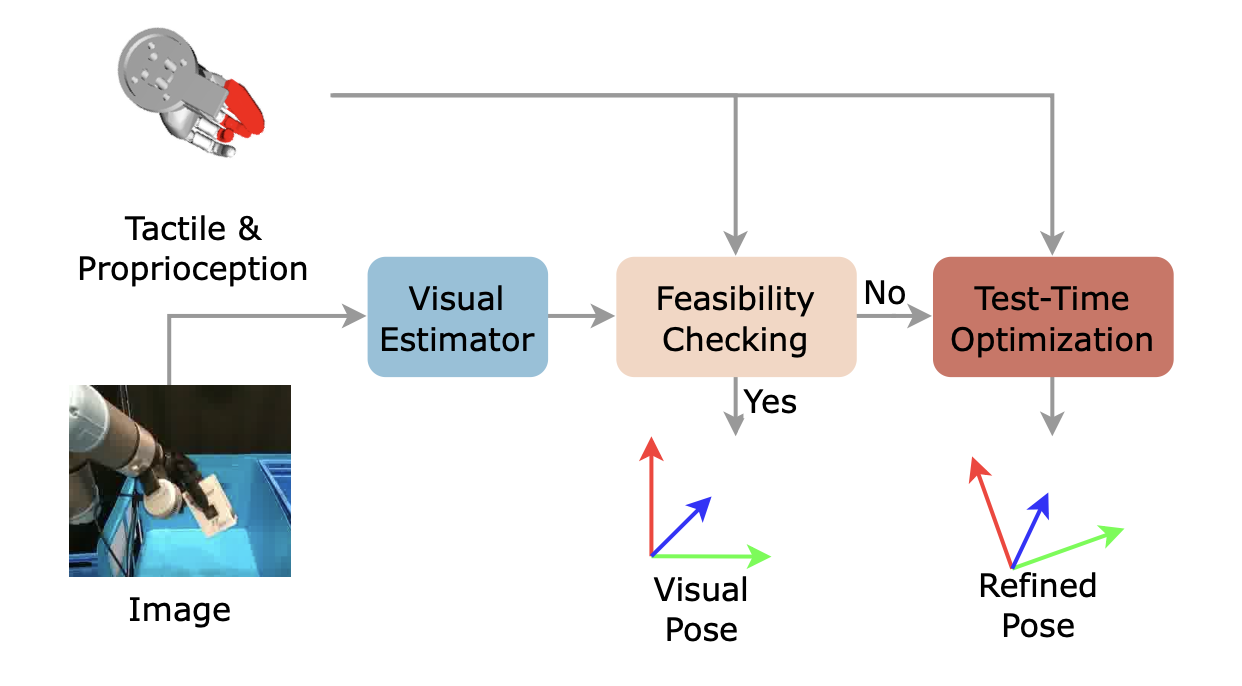
视觉估计
将视觉观测结果传入视觉模型,以获得初始姿态估计值 T。本文用 MegaPose [17] 作为 RGB 输入,作为 RGB-D 输入的采用 FoundationPose [16] 。遵循“先估计后跟踪”的流程:对第一帧使用估计模型,对后续帧使用姿态跟踪模型,以估计连续帧之间的相对姿态。实验表明,由于缺乏视觉线索,视觉模型难以应对严重遮挡和动态场景,导致操作任务中出现严重故障和累积误差。因此,利用触觉感知来优化视觉结果对于实现可靠的操作至关重要。

可行性检验
用于可行性检验的每个观测值,其几何表征为:触觉信号、目标和机器人(本体感受)。
触觉信号的表征。先前的研究将触觉信号表示为图像[40–45]和原始值[46, 47]。然而,这些表示方法在不同的传感器之间泛化能力较差,例如,基于图像的方法对于基于触素或F/T传感器无效。为了提高在不同触觉传感器之间的泛化能力,将触觉信号表示为相机坐标系中的点云 P_S,其位置可以通过正向运动学获得。对于基于触素的传感器(例如本文中使用的传感器),点值(布尔值)是通过使用二进制阈值对传感器输出进行离散化来获得的[24, 25, 47, 48]。对于基于视觉的传感器 [36, 49–51],可以通过深度估计 [23, 35, 52–55] 获取点云。
目标表征。给定目标网格 M_O,在网格上随机采样点获取姿态估计用于接触约束检查的模型点云 P_O。进一步使用体素化对 P_O 进行下采样,以创建体素网格 V_O,从而加快碰撞检查速度。
机器人表征。用由关节角度参数化的网格表示 M_R 来表示机器人 R,而不是直接使用关节角度或末端执行器位置 [27, 46, 47, 56],因为后者仅适用于机器人实施例且缺乏直接的物理解释。该网格被转换为下采样点云 P_R,并使用与目标网格相同的下采样技术来加速可行性检查。
- 接触约束:触觉点云 P_S 中的每个点必须与目标模型点云上的某个点接触。
- 穿透约束:机器人模型上的任何点都不应穿透目标模型,反之亦然。此约束通过检查变换后的目标体素网格 T(V_O) 与机器人模型点云 P_R 之间的重叠(交集)来强制执行。
3)运动学约束:目标的运动必须是物理上可行的。对目标位置的一阶微分约束可以防止不切实际的运动,例如对称目标在帧间姿态翻转,从而确保目标的运动符合实际动力学。
测试-时优化
如果视觉姿态估计值 T 不满足任何约束条件,使用测试-时优化方法对其进行优化。采用一个包含引力弹簧和斥力弹簧的弹簧-质量模型。弹簧产生的弹性势能为 0.5 kx^2(根据胡克定律),其中 x 是弹簧的位移。与之前将弹簧质量模型应用于手部抓握合成的研究 [57–59] 不同,其重新用于基于触觉和本体感受反馈的目标姿态优化。优化目标是找到一个相对姿态 T_∆,使两个弹簧的总势能最小化。
引力弹簧将目标拉向处于接触状态的触觉传感器,并在目标与所有此类传感器完全接触时达到其静止长度。斥力弹簧阻止机器人模型 P_R 和目标模型 P_O 之间的穿透。
将相对姿态 T_∆ 参数化为相对旋转 R_∆(使用 RoMa 库 [60] 以角度轴形式表示)和相对平移 t_∆。对参数应用 L2 正则化以稳定优化过程。
在后续帧中,对 T∗ 进行姿态跟踪。
用 PyTorch [61] 和 Adam [62] 求解器实现算法。为了简化优化过程,用激活的 Taxel 的平均平移变化来初始化 T_∆。这种初始化策略可以平滑优化过程并提高整体性能。
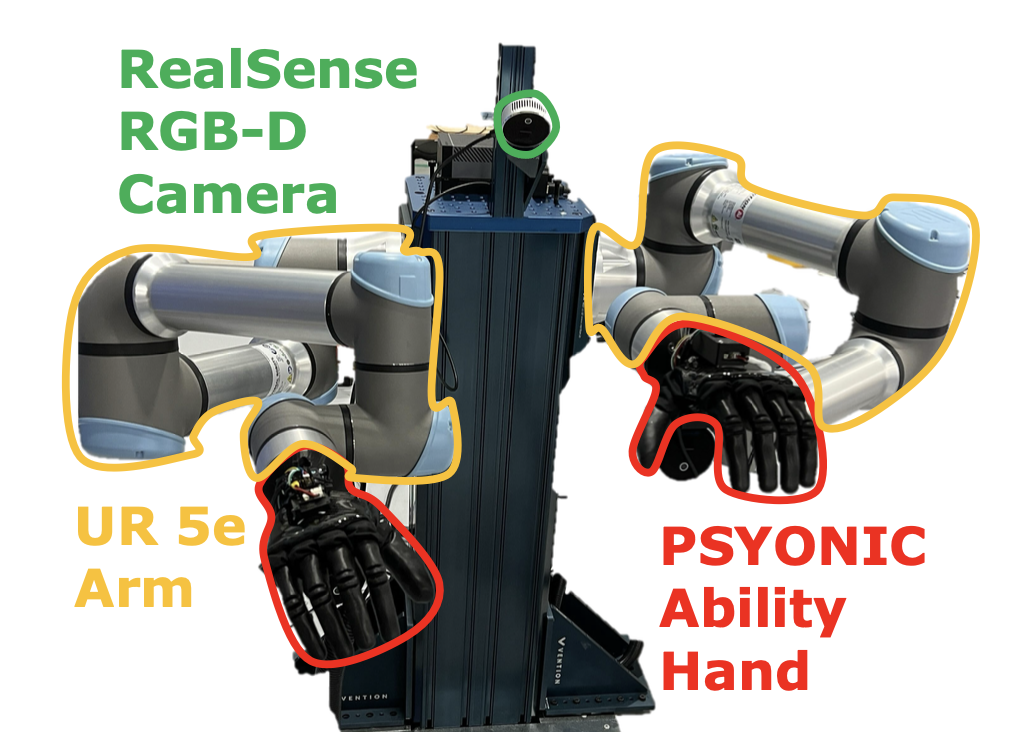
在现实世界的机器人平台(如图所示)上评估方法,该平台由两个 Universal Robots UR5e 机械臂和两个 PSYONIC Ability 手组成。拟人手有五个手指,每个手指的指尖配备六个 FSR 传感器以提供触觉感知。有关该平台的更多详细信息,请参阅 [46]。视觉感知由 RealSense RGB-D 摄像头提供,具体来说是 D455 和 L515 型号的组合。
虽然该框架旨在泛化到各种具身和触觉传感器,但本文重点关注 Ability 手平台在从 Amazon.com 购买的五个日常物品(如图所示)上进行测试,这些物品可以轻松被 Ability 手握住,并且它们不属于 Objaverse [63] 和 GSO 数据集 [64]。因此,这五个目标被认为是后续实验的新目标。

在可行性检验中,设定接触阈值 θ_c = 0.05,允许穿透阈值 θ_p = 0.008,运动阈值 θ_d = 0.03。对于测试时优化算法,优化器的学习率设为 10^−3,迭代次数根据经验调整为10。损失函数参数设置如下:吸引能量权重 k_a = 1,排斥能量权重 k_r = 1000,L2正则化参数 λ = 1000。在后续实验中,将方法与目前最先进的新型目标姿态估计模型 MegaPose (RGB) 和 FoundationPose (RGB-D) 进行比较。使用现成的模型[65, 66]获得这些模型所需的分割掩码和边框。
 与 models.objects.filter)

![[mysql]数据类型精讲](http://pic.xiahunao.cn/nshx/[mysql]数据类型精讲)
)

