1.数据库系统概述
1.1数据库的基本概念
数据的特性:
- 数据是有“型”和“值”之分
- 数据有定性表示和定量表示之分
- 数据受数据类型和取值范围的约束
- 数据具有载体和多种表现形式
数据库:
本质上是一个用计算机存储数据的系统。是收集计算机数据文件的仓库或容器。也可以归纳为:按照一定结构组织并长期存储在计算机内、可共享的大量数据的集合。
数据库标准定义:
数据库是按照一定结构组织并长期存储在计算机内的、可共享的大量相关数据的集合。
数据库管理系统DBMS:
定义:
安装在操作系统之上,是一个管理、控制数据库中各种数据库对象的软件系统。
DBMS可以通过调用操作系统的服务,比如进程管理、内存管理、设备管理以及文件管理等服务,为数据库用户提供、管理、控制数据库中各种数据库对象、数据库文件的接口,实现对数据的管理和维护。
功能:
1. 数据库的定义功能
2. 数据库的操纵功能
3. 数据库的运行管理
4. 数据库的的建立和维护
数据库系统包含了数据库、DBMS、软件平台与硬件支撑环境及各类人员。
数据库系统:
定义:是实现有组织、动态存储大量相关结构化数据、方便各类用户访问数据库的计算机软硬件资源的集合
特点:
1.数据结构化
2.数据的共享性高,冗余度低,易扩充
3.数据独立性高
4.数据由DBMS统一管理和控制
** 构成**:
由 数据库、数据库管理系统、软件平台、硬件平台和用户构成
三级模式结构
模式,简称概念模式,或逻辑模式。是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公用数据视图。
外模式,称为子模式或用户模式,它是对数据库用户看见和使用的局部数据的逻辑结构和特征的描述,是数据库用户的数据视图。
内模式,也称存储模式,它是对数据物理结构和存储方式的描述,是数据在数据库内部的表示方式。
二级映射
外模式映射:逻辑独立性
内模式映射:物理独立性
1.2数据库管理技术的发展
数据库系统的特点(数据库的特点):
- 数据结构化
- 数据的共享性高,冗余度低,易扩充
- 数据独立性高
- 数据由DBMS统一管理和控制
1.3数据库的系统结构
模式的定义:
模式就是数据库中全体数据的逻辑结构和特征的描述。是关于“型”的描述而不是“值”的描述
2.信息与数据模型
2.1 信息的三种世界描述
现实世界、 信息世界、 机器世界(计算机世界)
现实需求 -> 概念模型 -> 逻辑模型
| 现实世界 | 信息世界 | 计算机世界 |
| 实体 | 实例 | 记录 |
| 特征 | 属性 | 数据项 |
| 实体集 | 对象 | 数据或文件 |
| 实体间的联系 | 对象间的联系 | 数据间的联系 |
| 概念(信息)模型 | 数据模型 |
2.2数据模型
定义:是对现实世界中客观事物及事物之间联系的抽象,并用数学描述进行模拟表示。
数据处理的三层抽象描述
(1)概念层
常用的概念模型有实体-联系模型(E-R模型)
(2)逻辑层
常见的有层次模型、网状模型、关系模型和面向对象模型
(3)物理层
是数据抽象的最底层,一般都向用户屏蔽
数据模型的三要素:
(1)数据结构
(2)数据操作
(3)数据的完整性约束条件
2.3概念模型
是用于信息世界的建模,是现实世界到信息世界的第一层抽象
七大基本概念:
- 实体:客观存在并相互区别的事物
- 属性:实体所具有的某一特性
- 实体性:实体类型名和所有属性来共同表示同一类实体,例:学生(学号,姓名,性别,出生日期,所属院系)
- 实体集:同类实体的集合
- 码:可以唯一标识一个实体的属性集
- 域:实体属性的取值范围
- 联系:实体内部的联系和实体之间的联系
E-R模型
常用的有E-R模型,如下图所示
属性中带下划线的是 “码”, 是该实体的唯一特征描述,例如学生的学号
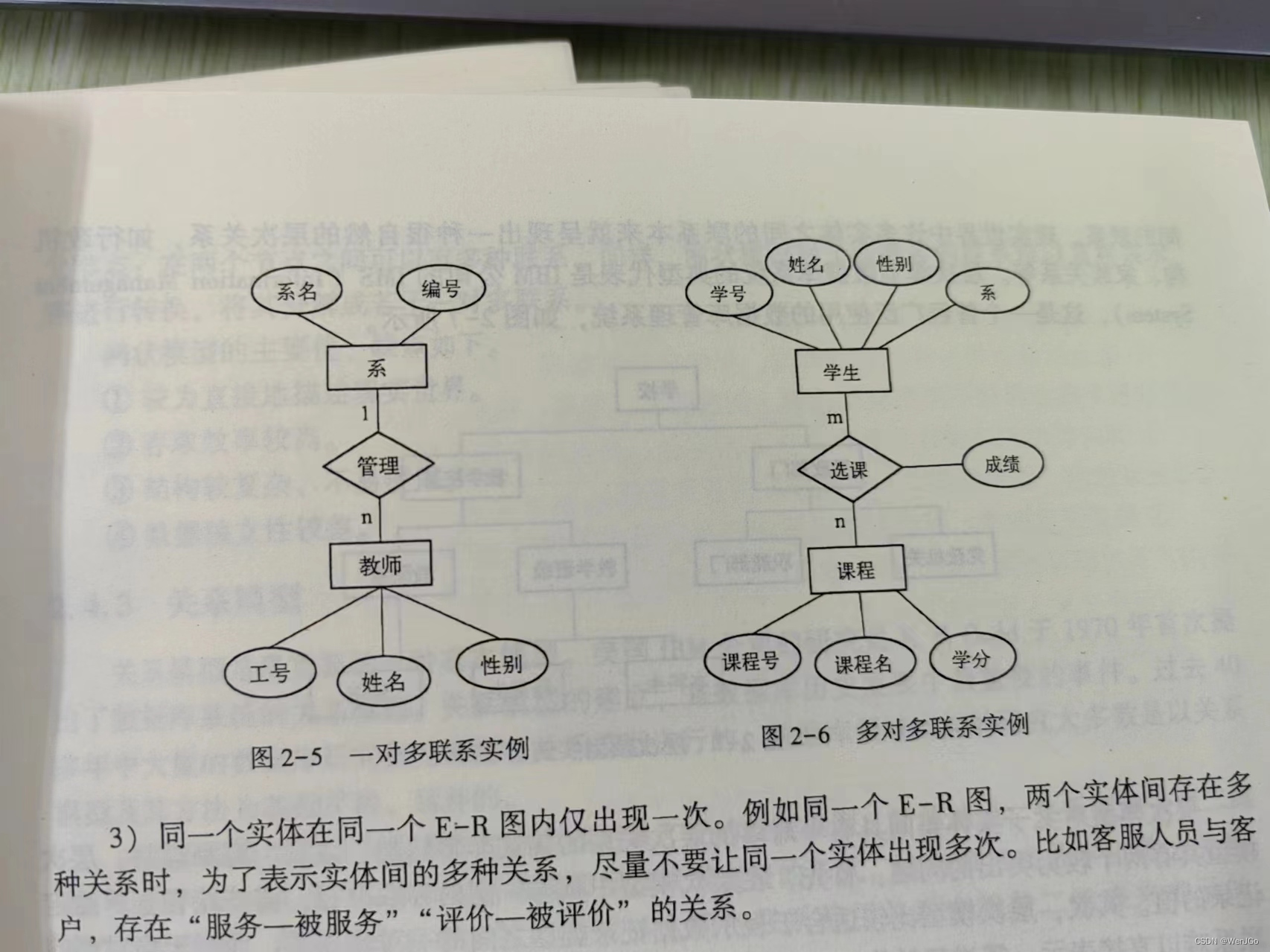
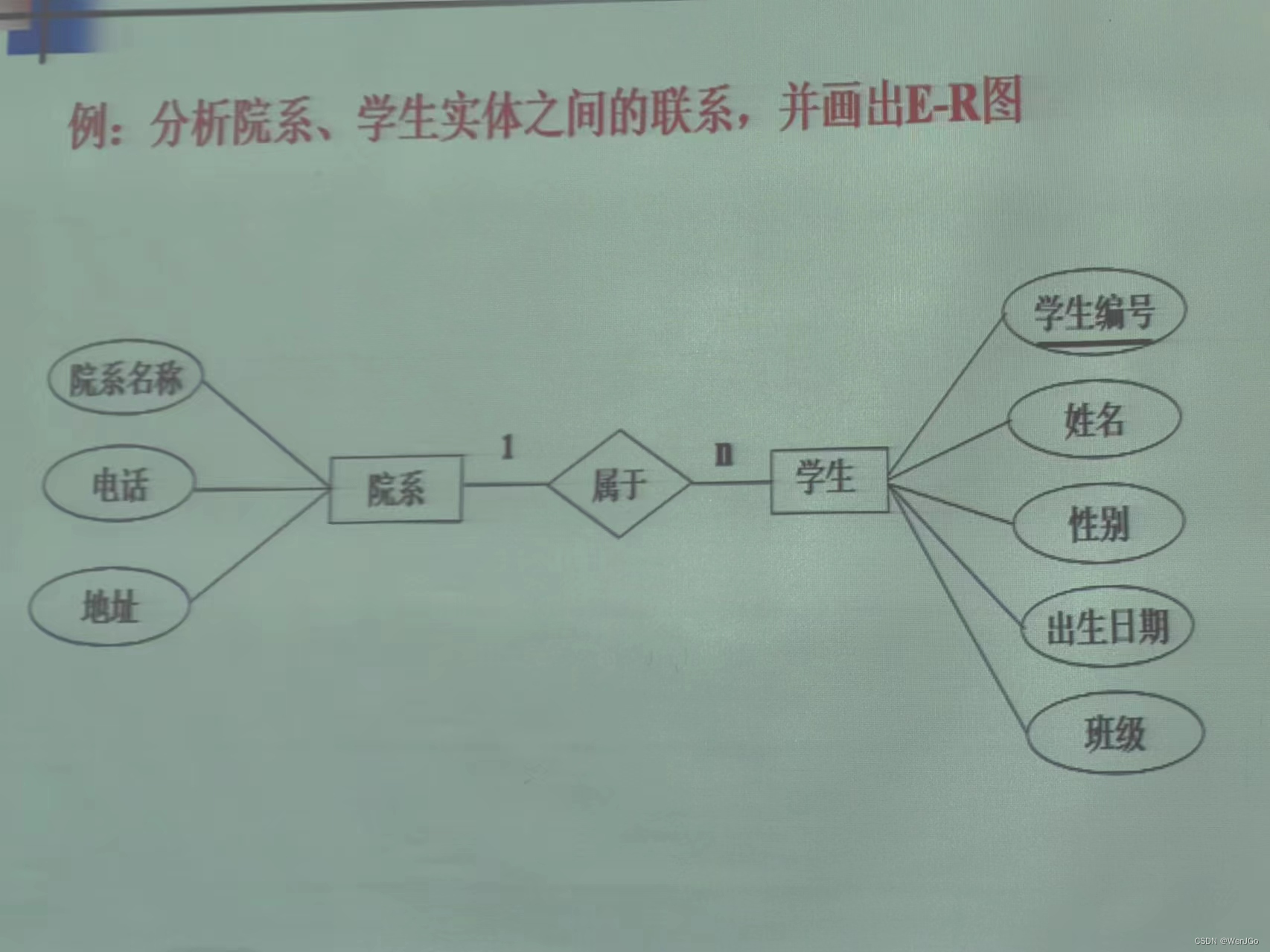
E-R模型设计原则
(1)属性应该存在于且只存在于一个地方
(2)实体是一个单独的个体,不能存在于另一个实体中成为其属性
(3)同一个实体在同一个E-R图内仅能出现一次
E-R模型设计步骤
(1)划分和确定实体
(2)划分和确定关系
(3)确定属性
(4)画出E-R模型
(5)优化E-R模型
优化E-R模型时,注意三个冲突
(1)命名冲突
(2)结构冲突
(3)属性冲突
2.4逻辑模型
存在于计算机世界。指数据库的逻辑结构,是对现实世界的第二层抽象,即概念模型针对某一个具体类型的数据库所转化的模型。
分类
(1)层次模型
(2)网状模型
(3)关系模型 (目前为主)
(4)面向对象模型
概念模型与逻辑模型的转换
实体转换的原则
(1)一个实体转换为一个关系模式
(2)实体的名称即是关系模型的名称
(3)实体的属性就是关系的属性
(4)实体的码就是关系模型的码
具有联系的实体转换原则
1:1的联系
方法一:将两个实体类型转换成两个独立的关系模式;
在任意一端的关系模式中加入另一个关系模式的码和联系类型的属性。
方法二:将两个实体类型转换成两个独立的关系模式;
将两个实体的码以及联系本身的属性均转换为一个新的关系模式的属性,关系名称可以是联系的名称,每个实体的码均是该关系模式的码。
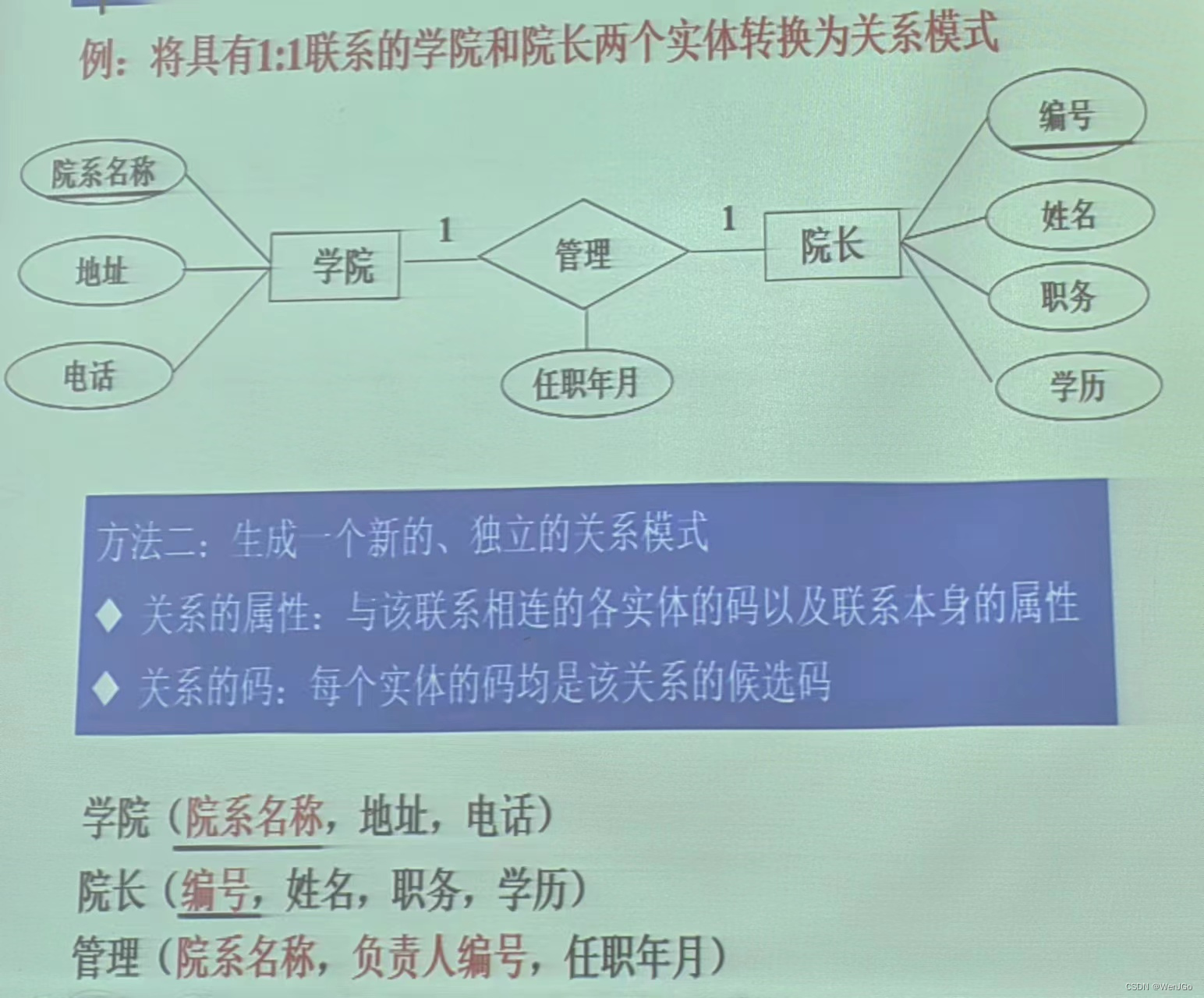
1:n和n:m

关系模型
关系数据结构
-
元组:在关系数据库中,元组(或行)是数据表中的一行。每一行代表数据表中的一个实体(如一个人、一个产品)。组成元组的元素叫做分量,N目关系必有n个属性。
-
属性:属性(或列)代表数据表中的一列,它描述了数据表中实体的某一个特征(如姓名、价格)。
-
候选码:候选码是一个最小字段集合,它在一张表内可以唯一确定一行记录。在一个表中可以有一个或多个候选码。
-
主码:在每张表的多个候选码中,用户选定一个作为主要使用的候选码,这个被选定的候选码就叫做这张表的主码。主码具有唯一性和最小性,能唯一标志一条记录,且不能再减少字段。唯一且不可为空。
-
全码:全码就是表中所有的属性组合,一定能够唯一确定一条记录,因此全码也可以看作是候选键。
-
主属性和非主属性:主属性是指候选码中的所有属性,非主属性是指除主属性之外的所有属性。简单地说,大多数表中的属性分别属于主属性和非主属性两类。
-
代理键:代理键是数据库自动生成的一个唯一键,而不是从现实世界的数据模型中得到的。例如,主键字段通常就是一个代理键。使用代理键的主要理由是,现实世界的候选键可能会变化,使用代理键可以避免这种问题。
数据库中的关系的类型
数据库中的关系类型包括基本关系、查询表和视图表。
-
基本关系:基本关系是指数据库中的实际表格,也称为物理表。它由行和列组成,每一行代表一个记录,每一列代表一个属性。基本关系是存储和操作实际数据的主要对象。基本关系的结构由关系模式决定,通过关系模式定义了表的列名、数据类型、主键和约束等信息。
-
查询表:查询表是在数据库查询操作中生成的虚拟表格。它不在数据库中存储实际数据,而是通过查询语句从基本关系中计算和生成的结果。查询表可以根据需要选择和过滤基本关系中的数据,并根据特定的条件进行计算和组合。查询表可以用于实现数据的汇总、统计、筛选、排序和连接等操作。
-
视图表:视图表是基于一个或多个基本关系或查询表的定义而创建的虚拟表。它是数据库中的逻辑表格,不存储实际数据,而是根据需要从基本关系中获取数据并按照特定的条件和规则进行处理和展示。视图表可以用于简化复杂的查询操作、提供数据安全性、隐藏实际数据结构等。视图表可以被认为是对基本关系或查询表的一种抽象和逻辑上的表现形式。
关系的性质
(1)元组存储了某个实体或实体某个部分的数据
(2)元组的位置具有顺序无关性,即元组的顺序可以任意交换。
(3)同一属性的数据具有同质性,即每一列的分量是同一类型的数据。
(4)同一关系的字段名具有不可重复性。
(5)元组无冗余性,即两个元组不能完全相同。
(6)列的位置具有顺序无关性。
(7)每一个分量必须去原子值,即每个分量都是不可分的数据项。
关系模式
可以表示为:R(U, D, Dom, F)
R:关系名
U:组成该关系的属性的集合
D:属性组U中的属性所来自的域
Dom:属性向域的映像集合
F:为属性间数据依赖关系的集合
关系操作
基本内容
(1)数据查询
指数据检索。统计、排序、分组以及用户对信息的需求等功能
(2)数据维护
指数据添加、删除、修改等数据自身更新的功能
(3)数据控制
是为了保证数据的安全性和完整性而采用的数据存取控制及并发控制等功能
关系的完整性
关系的完整性是关系型数据库中非常重要的一个概念,它确保了数据的准确性和一致性。这主要由以下三个方面的完整性规则来保证:
-
实体完整性:这个规则确保表中的每一行都有一个唯一标识,通常是通过主键来实现的。在实体完整性规则下,主键不能为NULL,也不能重复。这是确保每一条数据都能被唯一找到的基础。(主码)
-
参照完整性:这个规则确保了两个表间相关列上的数据保持一致性。如果一张表的某列是另一张表主键的外键,那么这列的数据应该是另一张表主键列中已经存在的值,或者为NULL。这个规则主要通过设立外键约束来实现,它可以避免在相关表间出现无效数据。(外键)
-
用户定义完整性:这是对某些特定应用的特殊要求,用户有可能需要定义自己的一些特定的完整性规则。这类规则是根据具体的业务需求来的,比如一个年龄字段的数据必须是1到100之间的整数等。(用户需求)
这三类完整性是维护数据准确性和一致性的主要方式,它们可以让我们在插入、修改和删除操作中避免出现数据不准确或不一致的问题,从而保证了数据的可靠性。
关系代数与关系数据库理论
关系代数及其运算
(1)域:一组具有相同数据类型值的集合
(2)笛卡尔积:给定一组域D1,D2...Dn,则笛卡尔积为
D1×D2×...×Dn = {(d1,d2,..,dn)d∈Dj,j = 1,2,...,n}
(3)关系: D1×D2×...×Dn的子集叫作在域D1,D2...Dn上的关系,表示为R(D1,D2...Dn)
关系运算三大要素
(1)运算对象
(2)运算符
(3)运算结果
基本运算符
(1)比较运算符
(2)逻辑运算符
(3)集合运算符
(4)专门关系运算符
传统的集合运算
(1)并(Union)
(2)差(Difference)
(3)交(Intersection)
(4)广义笛卡尔积(Extended Cartesian Product)
***特殊的关系运算***
选择、投影、连接和除运算。
-
选择(Selection):选择运算是从关系中选择满足指定条件的元组的运算。可以使用各种比较运算符(如等于、不等于、大于、小于等)以及逻辑运算符(如AND、OR、NOT)来定义选择条件。
-
投影(Projection):投影运算是从关系中选择指定属性的运算。它可以用于获取关系中的特定列,即选取关系中的某些属性,而不需要选择关系中的所有属性。
-
连接(Join):连接运算是将两个关系中的元组进行合并的一种运算。连接运算基于两个关系之间的公共属性,将具有相同属性值的元组进行合并。常见的连接运算包括自然连接(Natural Join)、内连接(Inner Join)以及外连接(Outer Join)。

-
除(Division):除运算是一种特殊的关系运算,用于检查一个关系中的元组是否包含在另一个关系中。除运算通常用于判定关系之间的包含关系。该运算可以确定某个关系中的元组是否能够找到与之匹配的元组在另一个关系中。


这些关系运算是关系型数据库中常用的操作,用于进行数据查询和处理。它们能够通过组合和使用各种条件来提取和处理关系数据,从而满足不同的查询需求。
关系规范化理论
解决的问题
关系规范化理论是数据库设计中的重要原则,主要目的是将数据库中的数据进行组织和管理,以减少数据冗余、避免数据插入、更新和删除的异常。
-
数据冗余:
数据冗余指的是在数据库中出现重复的数据。数据冗余会占用额外的存储空间,并增加数据更新的复杂性。通过关系规范化理论可以将冗余数据分解为多个关系,从而减少冗余,提高数据存储的效率和一致性。 -
插入异常:
插入异常指的是当试图插入一条记录时,由于关系中的其他属性没有值,导致插入操作无法完成。这通常是由于关系设计不合理,造成关系属性之间的依赖关系缺失。通过关系规范化可以将关系拆分为更小的关系,避免插入异常的发生。 -
更新异常:
更新异常是指由于关系设计不合理,导致更新操作时出现数据不一致的情况。例如,当更新一条记录时,如果该记录在多个地方都有引用,需要同时更新多个位置的数据,否则数据就会不一致。通过关系规范化可以将关系拆分为多个关系,使得更新操作更加简单和可靠。 -
删除异常:
删除异常是指由于关系设计不合理,导致删除操作时出现数据丢失的情况。例如,当删除一个关系中的一条记录时,由于该记录被其他关系引用,如果不同时删除所有引用该记录的关系,就会导致数据丢失。通过关系规范化可以避免删除异常的发生,保证数据的完整性和一致性
函数依赖
(1)关系模式
描述为:R(U,D,DOM,F)
- R 是关系的名称。
- U 是关系模式中的属性集合,即关系模式的所有属性。U={A1, A2, ..., An}。
- D 是关系模式中的域集合,即关系模式中所有属性的取值范围。D={D1, D2, ..., Dn}。
- DOM 是一个域函数,用来表示关系模式中每个属性的数据类型。DOM(Ai) 表示属性 Ai 的数据类型,可以是整数、字符串等。
- F 是关系模式中的函数依赖集合,用来表示属性之间的依赖关系。F={F1, F2, ..., Fm}。
(2)函数依赖的定义
函数依赖(Functional Dependency)是关系模型中属性之间的一种关系,它描述了一个属性集合对另一个属性集合的决定关系。在描述函数依赖时,使用箭头 "->" 表示依赖关系。
给定一个关系模式 R(U),其中 U={A1, A2, ..., An} 表示关系模式的属性集合。函数依赖 F 表示一个或多个属性集合之间的依赖关系。每个函数依赖 F 都包含两个属性集合,用大括号表示。
例如,一个函数依赖 F={A1, A2, ..., An} -> {B1, B2, ..., Bm} 表示在关系模式 R 中,属性集合 {A1, A2, ..., An} 的值决定了属性集合 {B1, B2, ..., Bm} 的值。
函数依赖的定义有两种形式:
-
简单函数依赖(Simple Functional Dependency):当一个属性集合的任何两个元组的属性值相同时,它们的依赖属性也必须相同。 例如,对于函数依赖 F={A1, A2, ..., An} -> {B},如果在关系模式 R 中,存在两个元组 t1 和 t2,它们的属性值 A1, A2, ..., An 都相等,那么它们的属性值 B 也必须相等。
-
复合函数依赖(Composite Functional Dependency):当一个属性集合的任何两个元组的属性组合值相同时,它们的依赖属性组合也必须相同。 例如,对于函数依赖 F={A1, A2, ..., An} -> {B1, B2, ..., Bm},如果在关系模式 R 中,存在两个元组 t1 和 t2,它们的属性组合值 A1, A2, ..., An 都相等,那么它们的属性组合值 B1, B2, ..., Bm 也必须相等。
函数依赖在数据库设计中起着重要的作用,它可以帮助我们确定主键、外键和关系模式的范式,从而提高数据库的数据一致性和查询效率。
(3)关系模式的基本性质
叠加性(Additivity):对于关系模式R的属性集合U和V,如果U -> V,则U ∪ V -> V。这表示如果一个属性集合的值决定了另一个属性集合的值,则两个属性集合的并集也决定了后者。
分配性(Distribution):对于关系模式R的属性集合U、V和W,如果U -> V,则 U -> V ∩ W。这表示如果一个属性集合的值决定了另一个属性集合的值,那么它也决定了与第三个属性集合的交集的值。
扩张性(Extension):对于关系模式R的属性集合U和V,如果U -> V,则 U ∪ W -> V。这表示如果一个属性集合的值决定了另一个属性集合的值,那么它也决定了与第三个属性集合的并集的值。
投影性(Projection):对于关系模式R的属性集合U,如果U -> V,则 U -> W,其中W是V的一个子集。这表示如果一个属性集合的值决定了另一个属性集合的值,那么它也决定了这个属性集合的一个子集的值。
这些关系模式的基本性质有助于我们理解和处理关系模式的属性集合之间的依赖关系,帮助优化数据库设计和查询性能。
(4)平凡函数依赖和非平凡函数依赖
在关系模型中,函数依赖描述了一个属性集对另一个属性集的决定关系。根据决定关系的强度,函数依赖可以分为平凡函数依赖和非平凡函数依赖。
-
平凡函数依赖(Trivial Functional Dependency):当一个属性集对另一个属性集的决定是显而易见的,没有实际的信息提供时,称为平凡函数依赖。一个函数依赖 F 是平凡的,如果 F 的右侧属性集是 F 的左侧属性集的真子集。例如,如果关系模式R有属性集 A 和 B,且函数依赖定义为 A -> B,则称该函数依赖是平凡的,因为B的值可以直接从A的值推导出来,没有提供额外的信息。
-
非平凡函数依赖(Non-Trivial Functional Dependency):当一个属性集对另一个属性集的决定提供了有用的信息时,称为非平凡函数依赖。一个函数依赖 F 是非平凡的,如果 F 的右侧属性集不是 F 的左侧属性集的真子集。例如,如果关系模式R有属性集 A、B 和 C,且函数依赖定义为 A -> B,则称该函数依赖是非平凡的,因为B的值不能直接从A的值推导出来,需要额外的信息来确定。
非平凡函数依赖通常提供了更丰富的信息,有助于优化数据库设计和查询性能。在关系模式的分析和规范化过程中,我们通常希望尽可能地消除平凡函数依赖,以保留和利用非平凡函数依赖的信息。
(5)完全函数依赖和部分函数依赖
在关系模型中,函数依赖描述了一个属性集对另一个属性集的决定关系。根据决定关系的程度,函数依赖可以分为完全函数依赖和部分函数依赖。
-
完全函数依赖(Fully Functional Dependency):当一个属性集中的任何一个属性都决定着另一个属性集中所有属性的取值时,称为完全函数依赖。换句话说,如果对于关系模式R的属性集X和Y,如果Y的所有属性都依赖于X的所有属性,而且去掉X中任何一个属性都会导致Y的决定关系失效,那么称Y完全函数依赖于X。
-
部分函数依赖(Partial Functional Dependency):当一个属性集中的某些属性决定着另一个属性集中的一部分属性的取值,但不决定另一部分属性的取值时,称为部分函数依赖。换句话说,如果对于关系模式R的属性集X和Y,如果Y的某些属性依赖于X的所有属性,而另一部分属性只依赖于X的某些属性,那么称Y部分函数依赖于X。
完全函数依赖通常在数据库设计中被认为是理想的状态,因为它保证了关系模式中的属性之间的最小冗余和最大信息提供。部分函数依赖则表示了一定的冗余和重复,可能会导致数据不一致和更新异常。在关系模式的分析和规范化过程中,我们通常希望尽可能地消除部分函数依赖,以优化数据库设计和减少数据冗余。
(6)范式
在关系型数据库设计中,范式是一组用于评估和调整数据库设计的规则或准则。最初由埃德加·科德在1970年定义,目的是减少数据冗余,增强数据完整性。
目前在业界常用的有1NF, 2NF, 3NF这三种范式,它们的定义如下:
-
第一范式(1NF):在任何一个关系数据库中,只要每个属性列都是不可分解的数据项,就满足了第一范式。简单来说,1NF要求数据表中的每一列数据都是原子性的,数据表中不可以再嵌套其他表格。
-
第二范式(2NF):首先,它必须满足第一范式。其次,需要保证数据库表中的每一列都与主键相关,也就是说,数据表中不能存在与主键无关的列。注意,这个主键可以是联合主键,是多个列一起组成的。
-
第三范式(3NF):首先,它必须满足第二范式。其次,它要求数据表中的每一列数据都与主键直接相关,而不能间接相关。这就意味着,一个表中不可以存在传递依赖,如果存在,则应分解为多个表。
这三种范式是数据库设计最基础的三种范式,将数据库设计满足这三种范式,可以有效地减少数据冗余,提高数据完整性,但是,有时候为了优化读写性能,我们也会有意识打破范式去设计数据库。
第三规范形式(3NF)是数据库规范化中的一个重要概念,它建立在第一规范形式(1NF)和第二规范形式(2NF)的基础上。达到3NF的数据库设计可以解决以下主要问题:
-
消除重复数据(减少数据冗余):通过将数据分解到不同的表中,并通过外键关联,可以有效避免同一数据的多次存储。这样做不仅减少了数据存储空间的浪费,也使得数据更新更加高效和一致。
-
消除插入异常(Insertion Anomalies):在不满足3NF的数据库设计中,可能无法独立添加某些信息,因为它依赖于其他非主属性的存在。例如,在一个包含员工和部门信息的表中,如果某个部门还没有员工,就可能无法添加该部门的记录。通过达到3NF,可以通过分表和恰当的设计减轻这类问题。
-
消除更新异常(Update Anomalies):在未充分规范化的数据库中,同一信息的多处存储可能导致数据不一致,即某些信息被更新而其他部分却遗漏。3NF通过确保数据只存储一次来解决这个问题,从而保证数据的一致性和正确性。
-
消除删除异常(Deletion Anomalies):当想要删除某些数据时,可能会意外地丢失其他有用的信息。例如,如果某个记录含有多个属性且这些属性某些仅因为其他属性而存在,则删除包含这一关键属性的任何记录可能导致其他属性的信息也被不希望地删除。通过实现3NF,并将这些信息分解到多个表中,这种信息丢失的风险可以被极大减小。
数据库应用系统的设计
必考
需求分析阶段、概念结构设计、逻辑结构设计、物理结构设计、数据库实施、运行维护阶段
在数据库设计中,整个过程通常分为几个阶段,每个阶段之间相互联系、相互支持。我们来依次介绍这些阶段:
-
需求分析阶段
这是数据库设计的第一步,目的是清晰地了解和定义系统应该满足的业务需求。在这个阶段,数据库设计师会同业务分析师、项目管理者、未来的用户等沟通讨论,收集信息,弄清楚数据应该如何被组织、访问和维护。需求分析结果应该以文档形式明确记录下来,它会成为之后设计工作的基础。 -
概念结构设计
在需求分析确定后,概念结构设计阶段就是要基于需求来创建一个高层次的数据库模型,这通常会使用实体-关系模型(E-R模型)来完成。概念结构设计的目标是确定数据间的逻辑结构,无需涉及具体的数据库管理系统(DBMS)。这个模型定义了实体的类型、属性、关系以及约束和规则。 -
逻辑结构设计
在概念结构设计之后,下一步是将概念模型转换成逻辑模型。这个阶段不再考虑高层次的概念,而是更关注具体的逻辑结构,例如表的设计、字段的类型与长度、主外键的定义等。逻辑设计会根据概念模型创建标准化的关系模式,以避免数据冗余和依赖。 -
物理结构设计
逻辑设计完成之后,物理设计阶段开始关注数据模型在特定数据库管理系统中的实现。这意味着必须考虑如何在硬件上存储数据以及这些数据如何被访问和操作,以优化性能和存储。这一阶段要考虑文件的存储位置、索引的创建、存储过程和视图、安全性等。 -
数据库实施
助理确定了物理模型之后,下一步是在选定的数据库管理系统中实际创建数据库。这包括创建表格、定义字段、设定约束、编写触发器和存储过程、建立索引等。数据定义语言(DDL)通常用来执行这些任务。这一阶段还包括数据的迁移和加载。 -
运行维护阶段
当数据库处于运行阶段后,数据库管理员(DBA)负责日常运维工作,包括监控系统性能、优化查询、备份和恢复、处理安全性问题等。实际使用过程中可能还会根据新的需求对数据库进行调整和扩展,比如添加新的功能、调整数据库结构或优化索引等,以确保数据库系统能有效支持业务运作。
需求分析
数据流图
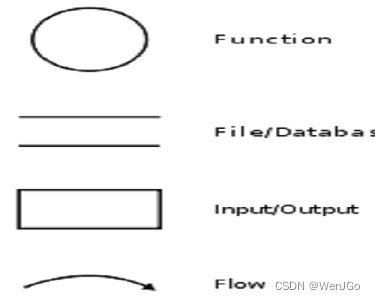
数据流图(Data Flow Diagram, DFD)是一种图形化工具,用于表示信息流和数据从输入到系统之后的变换过程。它是系统分析和设计过程中常用的工具,帮助分析人员理解系统如何运作,数据是如何被处理以及数据流向何方。数据流图展示的是系统的功能视图,而非实施视图,因此它不关心系统内部的复杂实现细节,而是着重于数据的流动和变化。
数据流图主要包含以下组成部分:
- 过程(Process):通常用圆形或圆角矩形表示,过程显示系统内部如何输入、处理数据。
- 数据流(Data Flow):通常用带箭头的线表示,数据流显示数据如何在系统中移动。
- 数据存储(Data Store):通常用开口的直线或矩形表示,数据存储表示系统中数据的保存地点。
- 外部实体(External Entity):通常用矩形表示,外部实体表示与系统交互的外部源或目的地,比如用户或其他系统。
数据流图可以分为不同的层次,从总览(顶层DFD,也称作Context Diagram)开始,逐步分解到详细的层面。顶层DFD显示了系统整体与外部实体的交互,而更低层次的DFD则展示了系统内部过程的具体操作。
下图来自百度百科

概念结构设计
****重点****
数据抽象的分类:
(1)分类
(2)概括
(3)聚集
合并E-R图需要解决的冲突:
(1)属性冲突
(2)命名冲突
(3)结构冲突
数据库备份和恢复概述
数据库备份类型
1.根据是否离线备份进行划分
(1)热备份:备份的同时,备份的同时不能对数据库进行读写操作
(2)冷备份:关闭MySQL服务,备份的同时不能对数据库进行读写操作
(3)温备份:MySQL服务在线,备份的同时支持读操作、不允许写操作
2.根据备份的数据集合进行划分***
(1)完全备份:备份全部数据
(2)增量备份:对上次完全备份或增量备份后发生改变的数据进行备份
(3)差异备份:对上次完全备份
3.根据备份的数据或文件进行划分
(1)物理备份:备份全部数据文件
(2)逻辑备份:备份表中的数据和代码
数据库备份命令mysqldump
mysqldump是一个用于备份MySQL数据库的命令行工具。它允许你将数据库的结构和数据导出到一个SQL文件中,以便后续可以使用该文件来还原数据库或将数据导入到其他环境中。
以下是一个使用mysqldump备份数据库的示例命令:
// 拷贝表
mysqldump -h主机名 -u用户名 -p密码 数据库名 表名 > d:backup.sql// 拷贝数据库
mysqldump -h主机名 -u用户名 -p密码 数据库名> d:backup.sql// 将所有数据库拷贝指指定目录下
mysqldump -h主机名 -u用户名 -p密码 --all--数据库名> d:backup.sql其中:
username是连接数据库的用户名password是该用户名对应的密码database_name是要备份的数据库的名称backup.sql是导出的SQL文件的目标文件名
执行上述命令后,mysqldump将会将指定的数据库的结构和数据导出到backup.sql文件中。可以使用备份文件进行还原或在其他环境中导入数据。
mysqld
mysqld是MySQL数据库服务器的守护进程或服务。mysqld负责启动和管理MySQL数据库系统,处理客户端的数据库请求,并处理数据的存储和检索。
视图
****视图的优势****
(1)增强数据的安全性。
(2)提高灵活性,操作变得简单
(3)提高数据的逻辑独立性。
特点
(1)是一个虚拟的关系二维表。
(2)数据库中只存放视图的定义,其内容由查询语句定义,不会出现数据冗余。
(3)在数据库中,视图具有和表一样的使用方法,可被检索或删除,但更新操作有一定的限制,也可以定义其它视图。
(4)基表中数据发生变化,视图中查询的数据也随之改变、
创建视图
MySQL创建视图的命令语法如下:
CREATE VIEW view_name AS SELECT column1, column2, ... FROM table_name WHERE condition with check option;其中,view_name 是视图的名称,column1, column2, ... 是需要选择的列,table_name 是视图所基于的表,condition 是筛选记录的条件。
索引
索引的优点
(1)通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
(2)可以大大加快数据的检索速度。
(3)可以加速表和表之间的连接,特别是在实现数据的参考完整性方面有特别的意思。
(4)在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
(5)通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
MySQL索引的类型
(1) 普通索引:普通索引是最基本的索引类型,可以加快数据的检索速度,但不会限制列中的值的唯一性。可以在创建表时或者已存在的表中使用 ALTER TABLE 语句来创建普通索引。
(2) 唯一性索引:唯一性索引是用来保证某列的值的唯一性,即列中的值不能重复。可以在创建表时或者已存在的表中使用 ALTER TABLE 语句来创建唯一性索引。
(3) 全文索引:全文索引用于在文本数据中进行全文搜索,比如搜索引擎中的关键字搜索。全文索引可以在 MyISAM 存储引擎的表上创建,但是在 InnoDB 存储引擎的表上需要使用全文搜索插件来创建。
(4) 单列索引:单列索引是只包含单个列的索引。单列索引可以提高单个列上的查询性能。
(5) 多列索引:多列索引是包含多个列的索引,也叫联合索引。多列索引可以提高多个列的联合查询性能。
(6) 空间索引:空间索引用于优化空间数据类型的查询,如几何类型或地理类型的查询。可以在创建表时或已存在的表中使用 ALTER TABLE 语句来创建空间索引。
创建索引
在MySQL中,可以直接创建索引和间接创建索引。
直接创建索引:
-
在创建表时,可以在 CREATE TABLE 语句中使用 INDEX 或 KEY 关键字来创建索引。 例如:
CREATE TABLE mytable (id INT,name VARCHAR(100),INDEX idx_id (id),KEY idx_name (name) ); -
在已存在的表中,可以使用 ALTER TABLE 语句来创建索引。 例如:
ALTER TABLE mytable ADD INDEX idx_id (id);
间接创建索引:
-
使用 CREATE INDEX 语句来创建索引。 例如:
CREATE INDEX idx_id ON mytable (id); -
使用 ALTER TABLE 语句来创建索引。 例如:
ALTER TABLE mytable ADD INDEX idx_id (id);
无论是直接创建索引还是间接创建索引,创建索引都可以提高数据的检索速度,提高查询性能。但需要注意的是,过多的索引也会增加更新操作的开销,并且占用更多的存储空间。所以在创建索引时需要权衡索引的数量和列的选择。
MySQL程序设计
基本语法
声明变量
(1)用户变量:@x
(2)全局变量: @@x 或 global x
(3)局部变量: declare x
查询全局变量:show global variables;
show global variables like '%autocommit%';
set gloabl autocommit='off';
delete from tacher where tno='2001102';
select * from teacher;
rollback;
变量赋值
(1)set x
(2)select ... into x from
流控制语句
选择
IF 1 THEN
...1
ELSE
...2
END IF;
多条件选择
IF 1 THEN
...1
[ELSEIF 2 THEN
...2]
[ELSEIF 3 THEN
...3]
循环结构
WHILE 条件表达式 DO
循环体
END WHILE;
(1)LEAVE: 跳出循环,跳出循环结构
(2)ITEBATE: 跳出本次循环,进入下一轮循环
[循环标签]LOOP
<循环体>
IF 条件表达式 THEN
LEAVE 循环标签;
END IF;
END LOOP[循环标签]
函数
substr
substr是一种字符串函数,用于从给定的字符串中提取子字符串。它的语法通常是 substr(string, start, length),其中:
string是要提取子字符串的原始字符串。start是起始位置,表示要提取的子字符串的起始索引。索引从 0 开始,即第一个字符的索引为 0。length是可选参数,表示要提取的子字符串的长度。如果未指定length,则会提取从start位置到原始字符串的末尾的所有字符。
例如,如果有一个字符串 str = "Hello, World!",使用 substr(str, 7, 5) 将返回子字符串 "World",因为它从索引位置 7(包括)开始提取 5 个字符。
replace
replace 是一种字符串函数,用于替换字符串中的指定子字符串为新的字符串。它的语法通常是 replace(string, from_string, to_string),其中:
string是原始字符串,需要进行替换的字符串。from_string是要被替换的子字符串。to_string是替换后的新字符串。
replace 函数会在原始字符串中查找所有与 from_string 匹配的子字符串,并将其替换为 to_string。替换后的字符串将作为结果返回。
例如,如果有一个字符串 str = "Hello, World!",使用 replace(str, "Hello", "Hi") 将返回字符串 "Hi, World!",因为它将原始字符串中的 "Hello" 替换为 "Hi"。
-- 创建函数f_tname,能够根据教师名字获得所属院系的负责人名字,
-- 若教师名字不存在,给出‘没有此人’提示-- 删除已存在的 f_tname 函数
DROP FUNCTION IF EXISTS f_tname;-- 创建函数 f_tname,声明为 DETERMINISTIC
DELIMITER $$CREATE FUNCTION f_tname(teacher_name CHAR(8))
RETURNS VARCHAR(50)
DETERMINISTIC
BEGINDECLARE teacher_deptno CHAR(2);DECLARE dept_head VARCHAR(50);-- 查找教师的院系编号SELECT deptno INTO teacher_deptnoFROM teacherWHERE tname = teacher_nameLIMIT 1;-- 如果教师不存在,返回提示信息IF teacher_deptno IS NULL THENRETURN '没有此人';END IF;-- 查找该院系的负责人SELECT tname INTO dept_headFROM teacherWHERE deptno = teacher_deptno AND title = '院长'LIMIT 1;-- 如果没有找到负责人,返回提示信息IF dept_head IS NULL THENRETURN '没有找到负责人';END IF;-- 返回负责人的名字RETURN dept_head;
END $$DELIMITER ;-- 调用函数
SELECT f_tname('王翠茂'); SELECT f_tname('李俊');存储过程
****存储过程的优点****
1. 存储过程增强了SQL语言的功能和灵活性
2. 存储过程允许标准组件是编程
3. 存储过程能实现较快的执行速度
4. 存储过程能过减少网络流量
5. 存储过程可被作为一种安全机制来充分利用
创建存储过程
创建函数是:function
创建存储过程是:procedure
CREATE PROCEDURE 存储过程名([参数列表]) [特性列表] BEGIN -- 过程体 END;在这个模板中:
存储过程名是想要创建的存储过程的名称。[参数列表]包含存储过程的输入和/或输出参数。它是可选的。[特性列表]包含存储过程的特性,比如语言设置、安全权限等。也是可选的。BEGIN和END之间是存储过程的主体,其中包含实际的 SQL 代码。
例子
这是一个通过学号获取学生姓名的存储过程示例,包括创建存储过程和执行存储过程的过程。
创建存储过程:
CREATE PROCEDURE p_stu (IN xh CHAR(15), OUT xm CHAR(10))
BEGIN SELECT sname INTO xm FROM student WHERE sno = xh; END;执行存储过程并设置输出变量:
SET @name = NULL;
CALL p_stu('0601020212', @name);查询变量以获取存储过程的值:
SELECT @name; 这段代码创建了一个名为 p_stu 的存储过程,接受一个输入参数 xh(学号),并返回一个输出参数 xm(姓名)。然后在执行存储过程时,将学号传递给存储过程,并通过输出参数获取学生的姓名。
异常处理
1.异常处理语法
DECLARE handler_type HANDLER FOR condition_value [..] sp_statement;2. 参考说明
(1) handler_type:
CONTINUE:遇到错误不处理,继续执行。EXIT:遇到错误时马上退出。UNDO:遇到错误后撤回之前的操作(MySQL暂不支持回滚操作)。
(2) condition_value:
SQLSTATE [VALUE] sqlstate_value:为包含5个字符的字符串错误值。condition_name:表示通过DECLARE CONDITION定义的错误条件名称。SQLWARNING:匹配所有以01开头的SQLSTATE错误代码。NOT FOUND:匹配所有以02开头的SQLSTATE错误代码。SQLEXCEPTION:匹配所有没有被SQLWARNING或NOT FOUND捕获的SQLSTATE错误代码。mysql_error_code:匹配数值类型错误代码。
3.异常捕获方法
方法一: 捕获 SQLSTATE 异常
这种方法是捕获 SQLSTATE 值。如果遇到 SQLSTATE 值为 "42S02",执行 CONTINUE 操作,并输出 "NO_SUCH_TABLE" 信息。
DECLARE CONTINUE HANDLER FOR SQLSTATE '42S02' SET @info = 'NO_SUCH_TABLE';方法二: 捕获 MySQL 错误代码异常
这种方法是捕获 MySQL 错误代码值。如果遇到 MySQL 错误代码值为 1146,执行 CONTINUE 操作,并输出 "NO_SUCH_TABLE" 信息。
DECLARE CONTINUE HANDLER FOR 1146 SET @info = 'NO_SUCH_TABLE';方法三: 先定义条件,然后捕获异常
DECLARE no_such_table CONDITION FOR 1146; DECLARE CONTINUE HANDLER FOR no_such_table SET @info = 'NO_SUCH_TABLE';方法四: 使用 SQLWARNING 捕获异常
DECLARE EXIT HANDLER FOR SQLWARNING SET @info = 'ERROR';方法五: 使用 NOT FOUND 捕获异常
DECLARE EXIT HANDLER FOR NOT FOUND SET @info = 'NO_SUCH_TABLE';方法六: 使用 SQLEXCEPTION 捕获异常
DECLARE EXIT HANDLER FOR SQLEXCEPTION SET @info = 'ERROR';例子创建函数 f_tname
这个函数能够根据教师名字获得所属院系的负责人名字。考虑到可能的错误情况,例如当教师名字出现重复时会返回多个院系编号,这里增加了错误处理语句。
delimiter //
drop function if exists f_tname;
create function f_tname(x char(10))returns char(6)
DETERMINISTIC
begindeclare n varchar(10);-- declare exit handler for 1242 return '返回多个值'; -- declare exit handler for sqlstate'21000' return '返回多个值';declare exit handler for sqlexception return '返回多个值';select tname into n from teacher where deptno=(select deptno from teacher where tname=x) and title='院长';if n is null then return '查无此人';elsereturn n;end if;
end;
-- 执行:
select f_tname('王翠茂');说明
- 定义错误处理:
manyrow条件捕获子查询返回多行的情况(SQLSTATE '21000')。SQLEXCEPTION捕获其他所有SQL异常。
- 错误处理句柄:
- 当捕获到
manyrow或其他SQL异常时,返回'返回多个值'。
- 当捕获到
- 主要查询逻辑:
- 使用子查询找到对应院系的负责人名字,并根据院系编号和职称为“院长”进行匹配。
- 结果返回:
- 如果查询结果为空,返回
'查无此人';否则返回找到的负责人名字。
- 如果查询结果为空,返回
游标
1. 定义游标
DECLARE 游标名 CURSOR FOR SELECT 语句;2. 打开游标
OPEN 游标名;3. 提取数据
FETCH 游标名 INTO 变量1, 变量2, ...;4. 关闭游标
CLOSE 游标名;示例条件语句
IF n = 0 THEN RETURN '没有学生选修'; ELSE RETURN 'nihao'; END IF;例子: 创建函数 `f_tname`
这个函数能够根据教师名字获得所属院系的负责人名字和所属院系编号。当教师的名字出现重复时,使用游标来解决并显示所有数据。
DELIMITER //
DROP FUNCTION IF EXISTS f_tname;
CREATE FUNCTION f_tname(x CHAR(10))
RETURNS VARCHAR(255)DETERMINISTIC
BEGINDECLARE done INT DEFAULT FALSE;DECLARE v_tname VARCHAR(10);DECLARE v_deptno VARCHAR(2);DECLARE result VARCHAR(255) DEFAULT '';DECLARE cur_tea CURSOR FORSELECT tname, deptnoFROM teacherWHERE tname = x AND title = '院长'; -- 假设tle是职位列,并且值为'院长'DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;OPEN cur_tea;read_loop: LOOPFETCH cur_tea INTO v_tname, v_deptno;IF done THENLEAVE read_loop;END IF;IF LENGTH(result) = 0 THENSET result = CONCAT(v_tname, ' (', v_deptno, ')');ELSESET result = CONCAT(result, ', ', v_tname, ' (', v_deptno, ')');END IF;END LOOP read_loop;CLOSE cur_tea;IF LENGTH(result) = 0 THENSET result = '未找到信息';END IF;RETURN result;
END //
DELIMITER ;
说明
-
声明变量:
v_tname和v_deptno用于存储游标提取的数据。str用于存储最终的结果字符串。done用于标识游标读取结束。
-
定义游标:
cur_tea游标用于查询匹配的教师和院系编号。
-
异常处理:
- 使用
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;来处理游标读取完毕的情况。
- 使用
-
打开游标:
- 使用
OPEN cur_tea;打开游标。
- 使用
-
读取数据:
- 在循环中使用
FETCH cur_tea INTO v_tname, v_deptno;提取数据,并将结果拼接到str中。 - 如果
done标志为TRUE,则退出循环。
- 在循环中使用
-
关闭游标:
- 使用
CLOSE cur_tea;关闭游标。
- 使用
-
返回结果:
- 如果
str为空,设置为'未找到信息 '。 - 返回拼接后的字符串。
- 如果
触发器
什么是触发器?
触发器是一种特殊的存储过程,它在插入,删除或修改特定表中的数据时触发执行,它比数据库本身标准的功能有更精细和更复杂的数据控制能力
****触发器作用****
◆安全性
◆审计
◆实现复杂的数据完整性规则
◆实现复杂的非标准的数据库相关完整性规则
创建触发器
create trigger 触发器名称触发时间触发事件
on 数据表 for each row
触发器执行体;
三要素:
(1)触发时间: before 或 after
(2)触发事件: insert 、 update 、 delete
(3)触发器功能:触发器执行体
代码举例
一、触发器
要求:创建实现级联删除触发器:删除course表中数据时,若数据被score表引用,需要先删除score表中数据,再删除course表中数据。
(1)删除course表中数据,查看情况
delete from course where cno=upper('a005');
drop trigger tr_delcou;
(2)创建触发器,实现级联删除
DELIMITER//
drop trigger if exists tr_delcou//
create trigger tr_delcou before delete
on course for each row
begindelete from score where cno=old.cno;
end;
(3)测试:
delete from course where cno=upper('a005');
select * from score;用户和授权
****MySQL 安全检查****
■****登陆验证****
用户名、密码
■****授权****
授予创建、修改、删除等权限
■****访问控制****
操作哪些对象、做何种操作
代码举例
二、用户与权限
1.用户权限表
(1)查询user表的相关用户字段。
select host,user,authentication_string from mysql.user;
select * from mysql.user;
(2)查看tables_priv表结构
desc tables_priv;
select * from mysql.tables_priv;
2.创建用户
(1)创建新的用户
create user sysman identified by '123';
create user 'system'@'localhost' identified by '123';
(2)使用insert命令添加用户
insert into mysql.user(host,user,authentication_string,ssl_cipher,x509_issuer,x509_subject) values('localhost','sysuser','123','','','');
刷新权限:flush privileges;
(3)修改用户名
rename user sysman to sam@localhost;
(4)删除用户
drop user 'system'@'localhost';
drop user 'sysuser'@'localhost';
delete from mysql.user where user='sam';
flush privileges;3.授权
(1)查看所有权限
show grants;(2)查看用户所有权限
select * from information_schema.user_privileges;
select * from mysql.user;(3)给用户system增加对数据库student的查询权限
grant select on student.* to 'system'@'localhost';(4)测试:(登陆system连接界面,执行下面操作)
select * from teacher; //可以看到结果
update teacher set deptno='01' where tname='赵文艳'; //无法更新(5)给用户system增加对数据库student学生表student的中的sno,sname,sage这三个字段的查询和更新权限
grant select(sno,sname,sage),update(sage) on student.student to
'system'@'localhost';
grant all privileges on student.* to 'system'@'localhost';(6)权限的转移和限制
create user 'my'@'localhost' identified by '123';
grant all privileges on student.* to 'system'@'localhost' with grant option;
flush privileges;4.回收权限
revoke select on student.* from 'system'@'localhost';
flush privileges;****grant:给与权限
****revoke :回收权限
事物
****特点(ACID)****
(1)原子性
(2)一致性
(3)隔离性
(4)持久性
****隔离性级别****
(1)未提交读(read uncommitted)
(2)提交读(read committed)
(3)可重复度(repeatable read)
(4)序列化(serializable)
***锁***
(1)表级锁
(2)页面锁
(3)行级锁
***并发操作带来的问题***
(1)丢失更新
(2)脏读
(3)不可重复读
(4)幻读
日志
****日志的类型****:
(1)错误日志:
主要用来记录 MySQL 服务的开启、关闭和错误信息。
(2)通用查询日志:
记录用户登录和记录查询的信息
(3)慢查询日志:
记录执行时间超过指定时间的操作。保存为 文本文件
(4)二进制日志文件:
主要用于记录数据库的变化情况。通过二进制日志可以查询MySQL数据库中进行了哪些改变。
重要杂项****
@@:全局变量
重点
1.数据库特点
2.日志文件的作用
3.事物特点、隔离性级别、并发操作带来的问题
4.MySQL安全检查(登录验证、授权、访问控制)
第一章
1.数据库特点
(1)数据结构化
(2)数据共享性高,冗余度第,易扩充
(3)数据独立性高
(4)数据由DBMS统一管理和控制
2.三级模式两级映像
外模式、概念模式(全部数据的逻辑结构和特征)、内模式
外模式/概念模式映射:实现逻辑独立性、概念模式/内模式映射:实现物理独立性



![[操作系统] 进程间通信:system V共享内存](http://pic.xiahunao.cn/nshx/[操作系统] 进程间通信:system V共享内存)

