目录
1、kafka消息发送的流程?
2、Kafka 的设计架构你知道吗?
3、Kafka 分区的目的?
4、Kafka 是如何做到消息的有序性?
5、ISR、OSR、AR 是什么?
6、Kafka 在什么情况下会出现消息丢失
7、怎么尽可能保证 Kafka 的可靠性
8、Kafka中如何做到数据唯一,即数据去重?
1.数据传递语义
2.幂等性
3.生产者事务
9、生产者如何提高吞吐量?
10、zk在kafka集群中有何作用
11、简述kafka集群中的Leader选举机制
12、kafka是如何处理数据乱序问题的。
13、kafka中节点如何服役和退役
1.服役
2.退役
14、Kafka中Leader挂了,Follower挂了,然后再启动,数据如何同步?
1.Leader挂了
2.Follower挂了
15、kafka中初始化的时候Leader选举有一定的规律,如何打破这个规律呢?
幂等性: 任何数字的0次方是 1
对一个结果修改N次,那么效果跟修改一次的效果是一样的。
- Kafka服务:
- Topic:主题,Kafka处理的消息的不同分类。
- Broker:消息服务器代理,Kafka集群中的一个kafka服务节点称为一个broker,主要存储消息数据。存在硬盘中。每个topic都是有分区的。
- Partition:Topic物理上的分组,一个topic在broker中被分为1个或者多个partition,分区在创建topic的时候指定。
- Message:消息,是通信的基本单位,每个消息都属于一个partition
- Kafka服务相关
- Producer:消息和数据的生产者,向Kafka的一个topic发布消息。
- Consumer:消息和数据的消费者,定于topic并处理其发布的消息。
- Zookeeper:协调kafka的正常运行。
1、kafka消息发送的流程?
消息发送会涉及到两个线程,main线程和Sender线程,在main线程里创建了一个双端队列RecordAccumulator。main线程将消息发送给RecordAccumulator,Sender线程不断从RecordAccumulator中拉取消息发送到Kafka Broker。
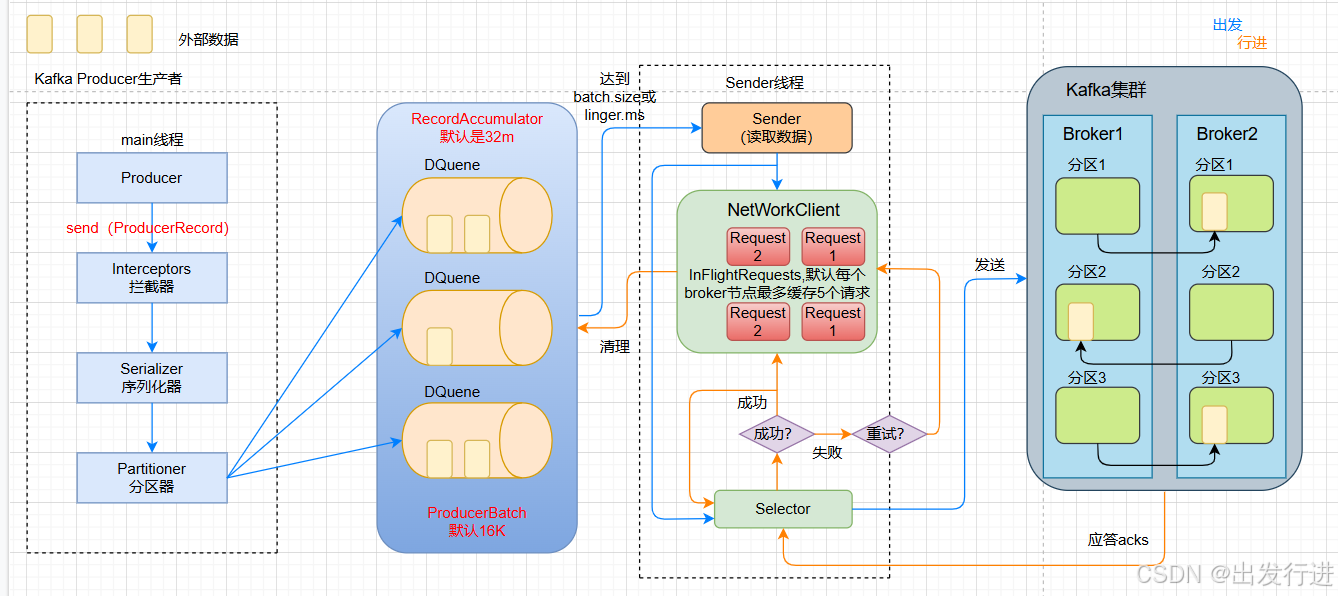
batch.size:只有数据积累到batch.size之后,sender才会发送数据。默认16K
缓冲区一批数据最大值,默认 16k。适当增加该值,可以提高吞吐量,但是如果
该值设置太大,会导致数据 传输延迟增加。
Linger.ms:如果数据迟迟未达到batch.size,sender等待Linger.ms设置的时间到了之后就发
送数据,单位ms,默认值0ms,表示没有延迟。acks:0:生产者发送过来的数据,不需要等数据落盘应答。
1:生产者发送过来的数据,Leader 收到数据后应答。
-1(all):生产者发送过来的数据,Leader+和 isr 队列 里面的所有节点收齐数据后应
答。默认值是-1,-1 和 all 是等价的。
2、Kafka 的设计架构你知道吗?
1.为了方便扩展,并提高吞吐量,一个topic分为多个partition
2.配合分区的设计,提出消费者组的概念,组内每个消费者并行消费
3.为提高可用性,为每个partition增加若干副本,类似NameNode HA
4.ZK中记录谁是leader,Kafka2.8.0以后也可以配置不采用ZK
ISR:In-Sync Replicas isr 是一个副本的列表,里面存储的都是能跟leader 数据一致的副本
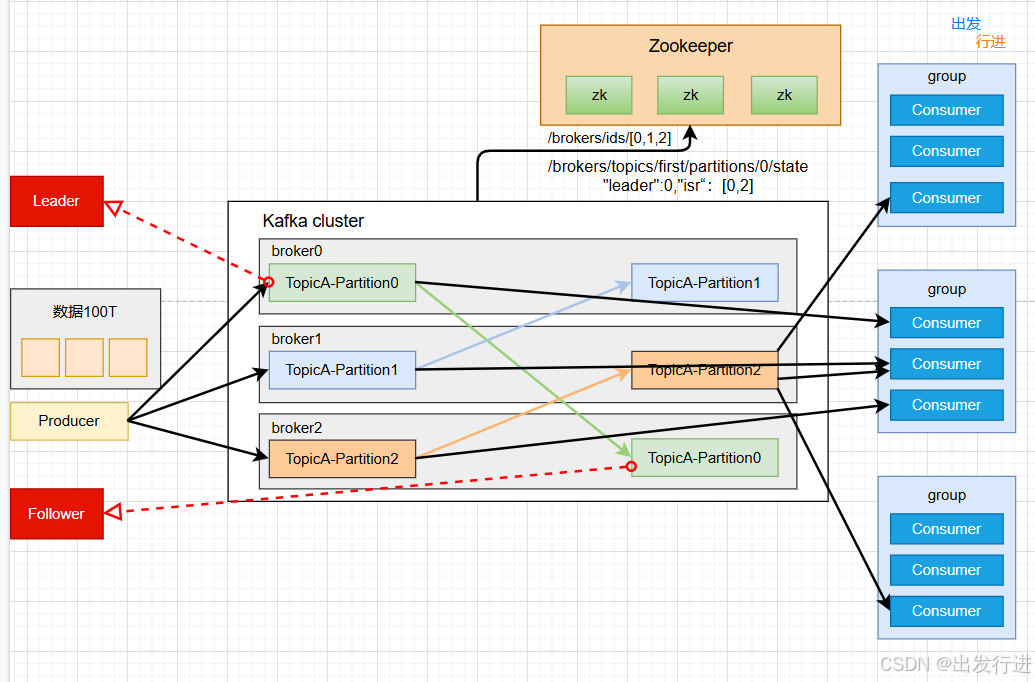
1.Producer:消息生产者,向Kafka broker发消息的客户端。
2.Consumer:消息消费者,向Kafka broker取消息的客户端。
3.Consumer Group(CG):消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费,消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。4.Broker:一台Kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
5.Topic:可以理解为一个队列,生产者和消费者面向的都是一个topic。
6.Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分成多个partition,每个partition是一个有序的队列。
7.Replica:副本,一个topic的每个分区都有若干个副本,一个Leader和若干个Follower。
8.Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是Leader。
9.Follower:每个分区多个副本中的“从”,实时从Leader中同步数据,保持和Leader数据的同步。Leader发生故障时,某个Follower会成为新的Leader。
3、Kafka 分区的目的?
分区好处:
(1)便于合理使用存储资源,每个Partition在一个Broker上存储,可以把海量的数据按照分区切割成一块一块数据存储在多台Broker上。合理控制分区的任务,可以实现负载均衡的效果。
(2)提高并行度,生产者可以以分区为单位发送数据;消费者可以以分区为单位进行消费数据。
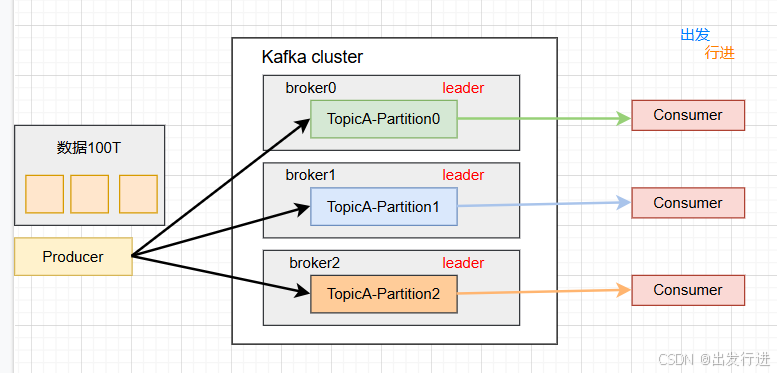
4、Kafka 是如何做到消息的有序性?
生产者发送的数据,单分区内可以做到有序。多分区,无法保证,除非把多个分区的数据拉到消费者端,进行排序,但这样的话需要等待,效率很低,还不如直接设置一个分区。

5、ISR、OSR、AR 是什么?
AR = ISR + OSR
Kafka 分区中的所有副本(包含Leader)统




)