随着Deepseek API+Python 测试用例一键生成与导出 V1.0.5的试用不断深入,在处理需求文档内容时,会出现由于文档内容过长导致大模型返回的用例远达不到我们的期望数量;另一方面,是接口文档的读取,如果接口数量过多,也会出现这种清空,所以,我们引入了分块策略,将内容分块后多次请求大模型,并将大模型返回的结果进行整合。主要优化点是支持从 docx、yml、json 和 excel 文档中提取内容,采用合理的分块策略,确保大模型返回结果更完整可靠,同时支持导出为 json 或 excel 文件。这款工具将赋能测试工程师,让测试用例生成更智能、更高效!
V1.0.6在群友的试用反馈中,也一并修复了两个缺陷。
- 文本标题为空时,未对预览内容进行分块
- 当json格式的接口数据尺寸大于分块尺寸时,第一段数据将会是空值
感谢群友的反馈~~
支持的python环境是python 3.12
具体可参考Deepseek API+Python测试用例一键生成与导出 V1.05(支持读取json及yml,环境及库安装保姆级指南)
工具使用阿里云百炼api-key,具体可参考结合pageassist与阿里百炼api实现deepseek-r1联网搜索功能
整体布局如下图所示:

一、工具核心功能概览
1.1 支持多种文档类型
工具支持以下文档类型,满足不同场景下的测试需求:
- docx 文档:从需求文档中提取指定标题内容,进行分块处理后生成功能测试用例。
- excel 文档:从接口文档中提取接口定义,基于内容进行分块生成接口测试用例。
- json 文档:从接口文档中提取内容,合理分块后生成接口测试用例。
- yml 文档:针对接口文档,按接口定义分块生成测试用例。
1.2 分块策略
分块策略是本工具的核心亮点,针对不同文档类型采用不同的分块方式:
- 固定长度分块:将文本按固定长度切割,同时添加滑动窗口重叠,避免上下文丢失。
- 内容分块:按接口定义或段落内容分块,确保数据完整性。
1.3 测试用例导出
生成的测试用例不仅支持在工具内预览,还可导出为 json 或 excel 格式,便于后续管理和使用。
二、分块策略详解与代码实现
2.1 docx 文档分块策略
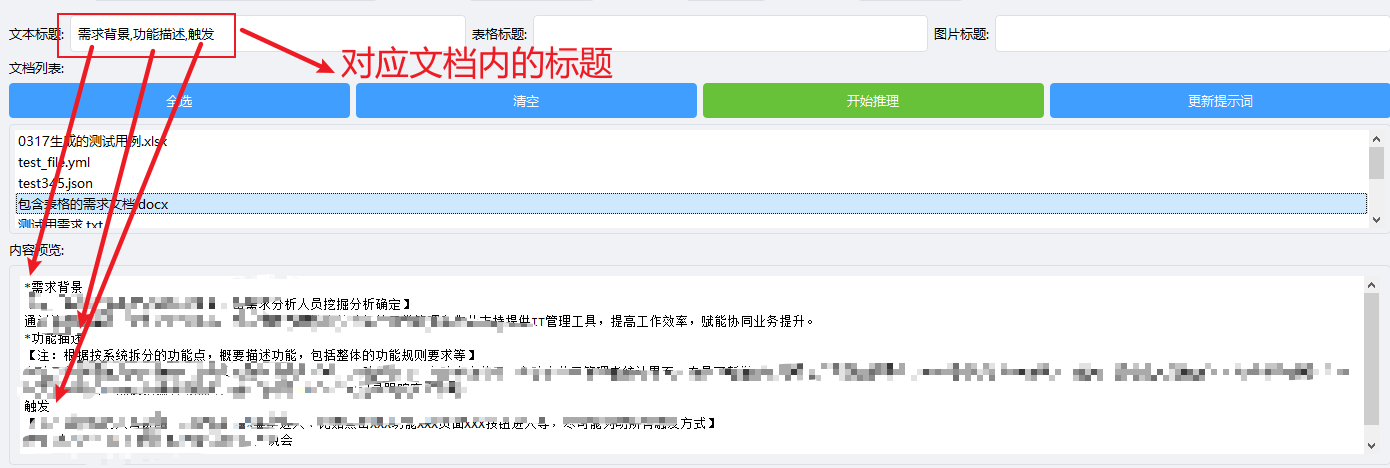
针对 docx 文档,采用 固定长度+滑块重叠 的分块策略,确保大模型生成的功能测试用例上下文完整。 支持输入文档的文本标题提取有效内容。如下图所示。
代码实现
def chunk_text(self, text, chunk_size=1000, overlap=200):"""将文本按固定长度分块,同时添加滑动窗口重叠。适用于功能测试用例生成。参数:- text (str): 输入的长文本内容- chunk_size (int): 每块的最大字符数- overlap (int): 相邻块的重叠字符数返回:- list: 分块后的文本列表"""print("开始对docx文档进行分块")chunks = []start = 0text_length = len(text)while start < text_length:end = min(start + chunk_size, text_length)chunk = text[start:end]chunks.append(chunk)# 滑动窗口:下一块的起始位置向后移动 chunk_size - overlapstart += chunk_size - overlapprint(f"分块完成,共生成 {len(chunks)} 个块。")return chunks
代码注释
chunk_size:每块的最大字符数(默认 1000)。overlap:相邻块的重叠字符数(默认 200),避免上下文丢失。- 滑动窗口:通过滑块策略,生成内容连续且无缝对接的分块。
2.2 excel 文档分块策略
针对 excel 接口文档,按接口定义逐行分块,确保每个接口的数据完整,避免分割到不完整的定义。
代码实现
def chunk_xlsx(self, df, max_chunk_size=1000):"""将 .xlsx 接口文档按接口定义分块,确保接口数据完整。参数:- df (DataFrame): pandas 读取的 excel 数据。- max_chunk_size (int): 每个分块的最大字符数。返回:- list: 分块后的接口定义列表。"""print('开始对xlsx文档内容进行分块!')chunks = []current_chunk = ""current_size = 0for _, row in df.iterrows():row_content = row.to_json(force_ascii=False) # 将行内容转换为 JSON 字符串row_size = len(row_content)if current_size + row_size > max_chunk_size:chunks.append(current_chunk)current_chunk = row_contentcurrent_size = row_sizeelse:current_chunk += "\n" + row_contentcurrent_size += row_sizeif current_chunk:chunks.append(current_chunk)return chunks
代码注释
- 逐行处理:遍历 excel 数据行内容,按行生成 JSON 字符串。
- 分块规则:若当前块大小超过最大字符数,则开始新块。
分块后的请求效果如图所示。
第一段:

第二段:

第三段:

将结果整合汇总并重新对用例ID进行排序:
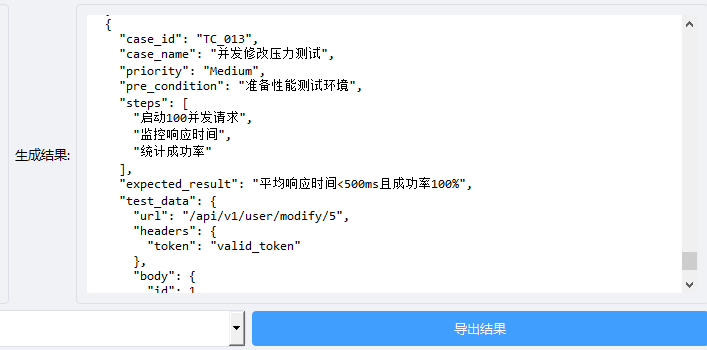
可将结果导出为excel或json文档。
2.3 yml 文档分块策略
针对 yml 文件,按接口定义分块,确保每个接口的数据完整性,同时支持字典和列表两种结构。
代码实现
def chunk_yaml(self, data, max_chunk_size=1000):"""将 .yml 接口文档按接口定义分块,确保接口数据完整。参数:- data (dict or list): 已解析的 YAML 数据。- max_chunk_size (int): 每个分块的最大字符数。返回:- list: 分块后的接口定义列表。"""print("开始对yml文件进行分块~~")chunks = []current_chunk = ""current_size = 0if isinstance(data, dict):for key, value in data.items():interface_content = yaml.dump({key: value}, allow_unicode=True)interface_size = len(interface_content)if current_size + interface_size > max_chunk_size:chunks.append(current_chunk)current_chunk = interface_contentcurrent_size = interface_sizeelse:current_chunk += "\n" + interface_contentcurrent_size += interface_sizeelif isinstance(data, list):for item in data:interface_content = yaml.dump(item, allow_unicode=True)interface_size = len(interface_content)if current_size + interface_size > max_chunk_size:chunks.append(current_chunk)current_chunk = interface_contentcurrent_size = interface_sizeelse:current_chunk += "\n" + interface_contentcurrent_size += interface_sizeif current_chunk:chunks.append(current_chunk)return chunks
代码注释
- 支持 字典和列表 两种 YAML 数据结构。
- 使用
yaml.dump将接口定义转为字符串,确保接口完整分块。
2.4 json 文档分块策略
针对 json 文件,按接口定义逐个分块,确保每个接口数据完整,避免分割到不完整的定义。
代码实现
def chunk_json(self, content, max_chunk_size=1000):"""将 .json 接口文档按接口定义分块,确保接口数据完整。参数:- content (list): 已解析的 JSON 数据列表。- max_chunk_size (int): 每个分块的最大字符数。返回:- list: 分块后的接口定义列表。"""print("开始对json文件进行分块~~")chunks = []current_chunk = ""current_size = 0for n, interface in enumerate(content):interface_content = json.dumps(interface, indent=2, ensure_ascii=False)interface_size = len(interface_content)if current_size + interface_size > max_chunk_size:if n == 0: # 修复首个元素过大的 bugchunks.append(interface_content)else:chunks.append(current_chunk)current_chunk = interface_contentcurrent_size = interface_sizeelse:current_chunk += "\n" + interface_contentcurrent_size += interface_sizeif current_chunk:chunks.append(current_chunk)return chunks
代码注释
- 针对 JSON 列表内容逐个分块。
- 修复首个元素尺寸过大导致的分块错误。
三、工具优势
- 智能分块策略:针对不同文档类型采用最优分块方案,确保大模型生成结果完整可靠。
- 多文档支持:支持 docx、yml、json 和 excel 等多种文档类型,满足多场景需求。
- 高效导出:生成的测试用例支持一键导出为 json 或 excel 格式,便于后续管理。
- 贴心细节优化:如滑动窗口处理、首块 bug 修复等,确保工具稳定性和精准性。
四、总结
通过对文档进行智能分块处理,结合大模型生成测试用例的能力,大幅提升测试效率和用例质量。无论是功能测试还是接口测试,这款工具都能为测试工程师提供强大支持,助力实现测试工作的智能化升级!
快来试试这款工具,让测试用例生成变得轻松高效吧!源码已上传~
往期迭代文章:
Deepseek API+Python测试用例一键生成与导出 V1.05(支持读取json及yml,环境及库安装保姆级指南)
Deepseek API+Python 测试用例一键生成与导出 V1.0.4 (接口文档生成接口测试用例保姆级教程)
Deepseek API+Python 测试用例一键生成与导出 V1.0.3
Deepseek API+Python测试用例一键生成与导出-V1.0.2
Deepseek API+Python测试用例一键生成与导出-V1.0.1
Deepseek API+Python测试用例一键生成与导出-V1
Deepseek API+Python测试用例一键生成与导出






