LLVD:LSTM在Blind video denoising中的应用
- 导言
- Main Contribution
- 建模过程
- 目标
- 具体架构介绍
- 整体架构
- 框架数据流向
- 网络结构
- loss design
- 降噪效果
导言
尽管相机传感器技术已经取得了很大的进步,但是由于噪声的出现,拍摄的图像和视频依然会有画质下降问题。因为光子统计过程中的随机性和硬件电路的不准确性,导致拍摄过程中的噪声具有复杂且随机的本质特点。特别是在低光照环境和低端相机传感器的条件下,噪声会让画质出现严重的下降。因此,在计算机视觉领域,降噪(去除噪声artifacts、恢复画面细节)依然是很重要的问题。
图像降噪的发展历史相对长一些,但视频降噪目前在科研界的热度更高。相比图像降噪,视频降噪主要有两点不同:
- 相邻帧之间的时间相关性有助于显著提升降噪效果;
- 增加的时序维度导致算力暴涨。
因此,视频降噪需要对时序信息进行高效建模,以降低算力需求,达到实时性要求(4M@30fps等),才更有可能在端侧设备上落地应用。
近几年,在视频降噪领域出现了很多优秀的工作。例如DVDNet(运动估计),FastDVDNet(learning-based),EMVD(多帧平均&时空降噪)等,但这些方法都需要较大的算力,难以达到实时的性能。
显式的运动建模通常基于光流、运动估计或者运动补偿的方法,尽管显式的估计运动很有效,但受限于算力无法在实际中应用。虽然有方法可以通过多阶段级联的架构挖掘相邻帧间的运动信息,但降噪性能还是会稍差一些,并且算力需求还不够小。
隐式运动建模方法的性能较差可能是由于它们在利用帧之间的时间相关性方面的能力有限。这一挑战可以通过采用长短期记忆(LSTM)网络来解决。LSTM网络以其在处理序列数据方面的卓越表现而闻名,非常适合对视频帧中的时空关系进行建模,为提高视频去噪性能提供了一种有前景的解决方案。
所以,本篇文章作者提出了一种基于LSTM的方法用于blind video denoising,Latent space LSTM Video Denoising,named LLVD。
Main Contribution
- 提出一种新架构,将LSTM层无缝集成到视频帧的编码潜空间中。这种方法有助于获取连续帧之间的时间关系,同时捕捉难以捉摸的长期依赖关系,这些依赖关系在恢复过程中起着至关重要的作用;
- 提出一种轻量级的盲去噪方法,使消费者智能手机(和其他嵌入式设备)上的视频去噪成为可能。与SOTA方法相比,使用特征潜空间的LSTM可以显著减少对单帧进行去噪所需的计算量。
- 进行了详细的消融实验,证明潜空间的LSTM的作用,以及相比单纯的ConvLSTM或空间编码器,潜空间的LSTM可以作为一种更好的选择;
- 在合成高斯噪声和真实噪声的benchmark上证明了LLVD出色的降噪性能,并且LLVD不需要额外的噪声特性先验信息,这可以显著降低计算量。
建模过程
干净的视频序列: X T = [ x 1 , x 2 , . . . , x T ] X_T=[x_1, x_2,...,x_T] XT=[x1,x2,...,xT] , T表示帧数, x t x_t xt ∈ \in ∈ R H ∗ W ∗ C R^{H*W*C} RH∗W∗C
退化的视频序列: Y T = [ y 1 , y 2 , . . . , y T ] Y_T=[y_1, y_2,...,y_T] YT=[y1,y2,...,yT] , T表示帧数, y t y_t yt ∈ \in ∈ R H ∗ W ∗ C R^{H*W*C} RH∗W∗C
退化公式:
y t = f ( d ( x t ) + n t ) {y_t} = f(d({x_t})+{n_t}) yt=f(d(xt)+nt) ,d(.)表示拍摄过程引起的退化(过曝、运动blur等), n t n_t nt 表示噪声, f ( . ) f(.) f(.) 表示后处理引起的退化(ISP或视频编码压缩)。
在这篇文章中, d ( . ) d(.) d(.) 表示恒等映射,即不做任何操作, f ( . ) f(.) f(.)分两种情况:
- raw域: f ( . ) f(.) f(.)表示恒等映射,即不做任何操作
y t = x t + n t {y_t} = {x_t}+{n_t} yt=xt+nt - rgb域: f ( . ) f(.) f(.) 表示isp pipeline
y t = f ( x t + n t ) {y_t} = f({x_t}+{n_t}) yt=f(xt+nt)
目标
建模降噪函数 F F F
- RGB域:
F ( Y T ) F({Y_T}) F(YT) ≈ \approx ≈ f ( X T ) f(X_T) f(XT) - RAW域:
F ( Y T ) F({Y_T}) F(YT) ≈ \approx ≈ X T X_T XT
具体架构介绍
整体架构
包含三个模块:
F E F_E FE:空间编码器
F L F_L FL:Recurrent Block
F D F_D FD:空间解码器
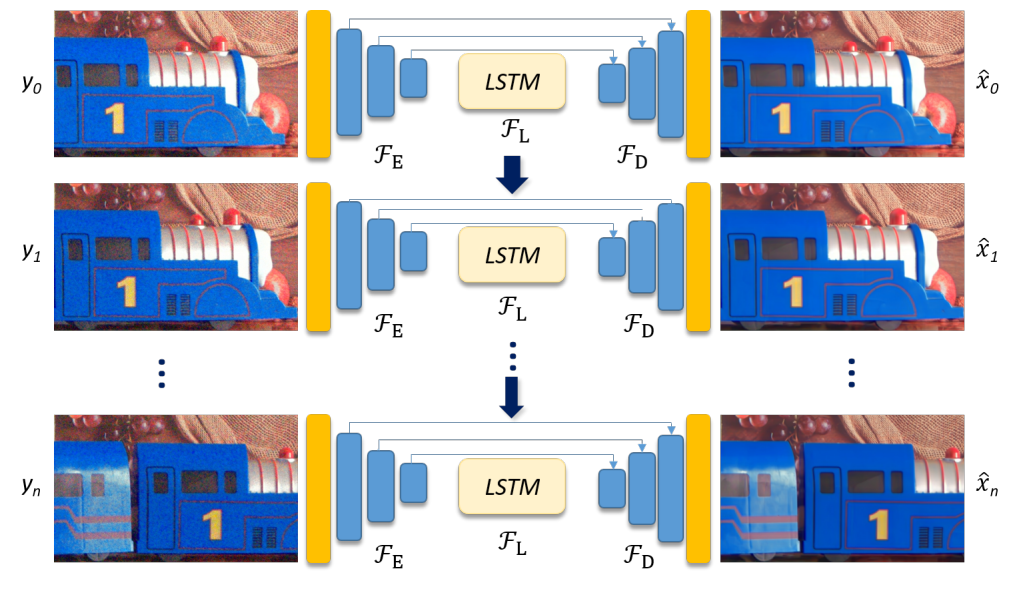
框架数据流向
框架数据流向分为3个阶段:
step 1. 视频的所有帧经过 F E F_E FE得到latent space的空间特征 e t e_t et;
e t e_t et = F E ( y t ) F_E(y_t) FE(yt) ∀ t ∈ \forall t\in ∀t∈ [ 1 , . . . , T ] [1,...,T] [1,...,T]
step 2. 空间特征 e t e_t et经过 F L F_L FL整合时序信息,得到时空特征 l t l_t lt;
l t l_t lt = F L ( e t ) F_L(e_t) FL(et) ∀ t ∈ \forall t\in ∀t∈ [ 1 , . . . , T ] [1,...,T] [1,...,T]
step 3. 时空特征 l t l_t lt经过空间解码器 F D F_D FD得到降噪结果;
x t ^ \hat{x_t} xt^ = σ ( F D ( l t ) ) \sigma(F_D(l_t)) σ(FD(lt)) ∀ t ∈ \forall t\in ∀t∈ [ 1 , . . . , T ] [1,...,T] [1,...,T]
σ ( . ) \sigma(.) σ(.)是sigmoid激活函数
网络结构

loss design
L 2 L2 L2 + λ 1 L 1 + λ 2 [ 1 − S S I M ] \lambda_1 L1 + \lambda_2[1 - SSIM] λ1L1+λ2[1−SSIM]
L2 loss 会惩罚网络输出和GT之间较大的误差,导致降噪强度过大,画面会比较模糊;L1 loss会生成相对稀疏的结果,增加主观上的清晰度;SSIM loss会增强图像中的细节感,但系数不宜过大,否则容易出现artifacts。
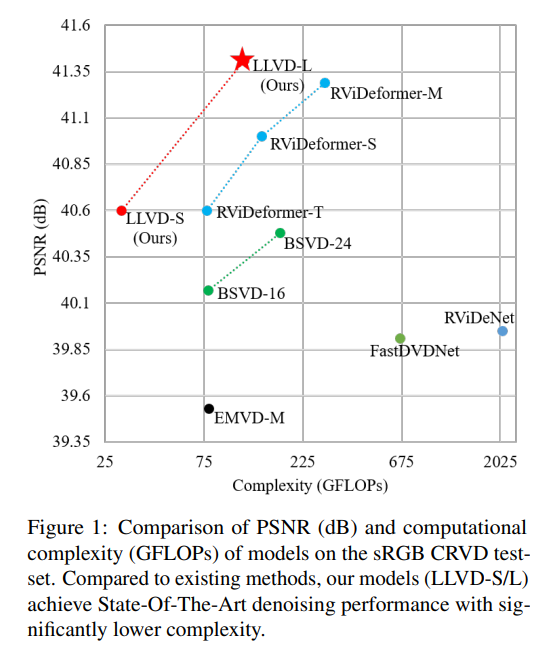
降噪效果