Redis的主从复制
- 一.主从复制的简介
- 1.主从介绍
- 2.主从解决的问题
- 性能/支持的开发量是有限的
- 可用性问题
- 二.配置redis的主从结构
- 1.一个云服务器上开启多个redis服务器
- 2.绑定主从结构
- (1)通过配置文件来绑定主从结构
- (2)查看主从结构信息
- 3.断开主从连接
- 4.投靠其他节点
- 5.安全性和只读
- 6.传输延迟
- 三.拓扑结构
- 1.一主一从结构
- 2.一主多从结构
- 3.树形主从结构
- 4.原理
- (1)数据同步 psync
- (2)psync运行流程
- 四.全量复制和部分复制
- 1.全量复制流程
- runid和replid
- 2.部分复制主要流程
- 五.实时复制
- 六.主节点断开后无法连接
一.主从复制的简介
1.主从介绍
在若干个redis节点中,有主和从节点,假设有三个物理服务器(称为三个节点),此时就可以把其中一个节点作为主节点,另外两个为从节点。
从节点必须听从主节点的,从节点上的数据要跟随主节点的数据变化,从节点的数据也必须和主节点的数据保持一致。从节点就是主节点的副本,主节点上保存的数据,引入了从节点后,从节点会把主节点上的数据复制到从节点自身当中。
用户没办法在从节点上修改数据,只能读取数据,因为redis对此进行了强制要求。
2.主从解决的问题
准确的说,主从模式主要是针对读操作进行并发量和可用性的提高,而写操作的话,无论是可用性还是并发都是非常依赖主节点的,主节点也无法搞多个,所以主次结构没办法解决写问题。
性能/支持的开发量是有限的
由于从节点的数据都是时刻和主节点的数据保持一致的,因此其他的客户端从节点这里读取数据和从主节点这里读取数据是没有区别的。
后续如果有客户端来读取数据了,就可以从上述节点中随机挑一个节点给这个客户端提供读取数据的服务。引入了更多的计算资源,自然能够支撑的并发量也就大幅提高了。
可用性问题
在没用主从结构时,redis服务器是单个节点,此时这个机器挂了,整个redis就挂了。但是使用了主从结构后,即使有机器挂了,还有其他机器的redis机器进行支撑。
如果挂掉的机器是某个从节点,是没有什么影响的,此时主节点或者其他从节点读取数据得到的效果也是完全一样的。但是如果挂掉的是主节点的机器,此时就会有一定的影响,因为此时只有从节点,而从节点是能读数据,而不是能写数据(虽然使用了主从结构使得可用性提高了,但是也没有达到非常理想的效果)
二.配置redis的主从结构
使用一个云服务器的方式来运行多个redis-server进程,就能够实现主从结构的模式,此处运行多个redis-server需要保证每个redis-server的端口号要是不相同的,可以通过配置文件中来设定端口号,也可以通过命令来指定端口号。
1.一个云服务器上开启多个redis服务器
-
创建一个redis-conf文件:

-
再将redis的配置文件拷贝到这里来,拷贝两份,作为两个从节点:


-
修改从节点的配置文件(端口号改成其他的和daemonize改成yes),而不需要修改主节点的配置文件:



-
启动服务器:

2.绑定主从结构
绑定主从结构有三种方式:
(1)通过配置文件来绑定主从结构
-
打开从节点的配置文件,进行配置文件的修改:

-
修改完毕配置文件,重新启动从节点服务器:


-
设置成功:

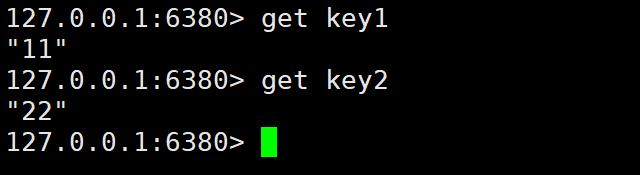

(2)查看主从结构信息
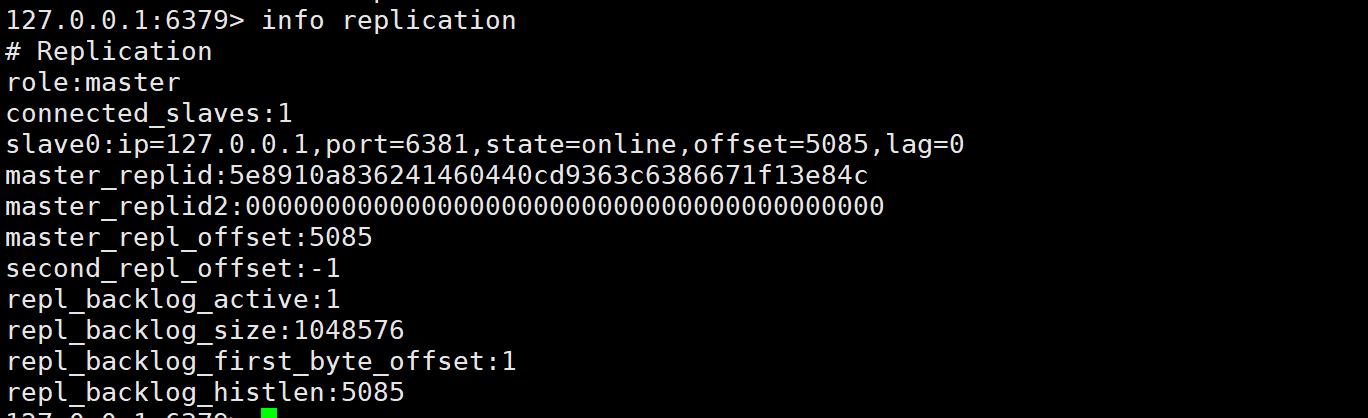
通过命令info replication来查看主从结构的信息: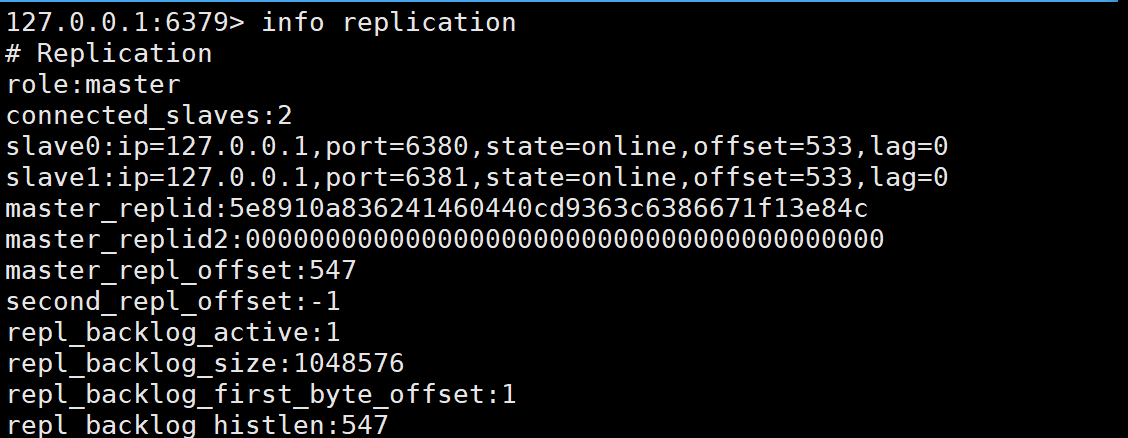
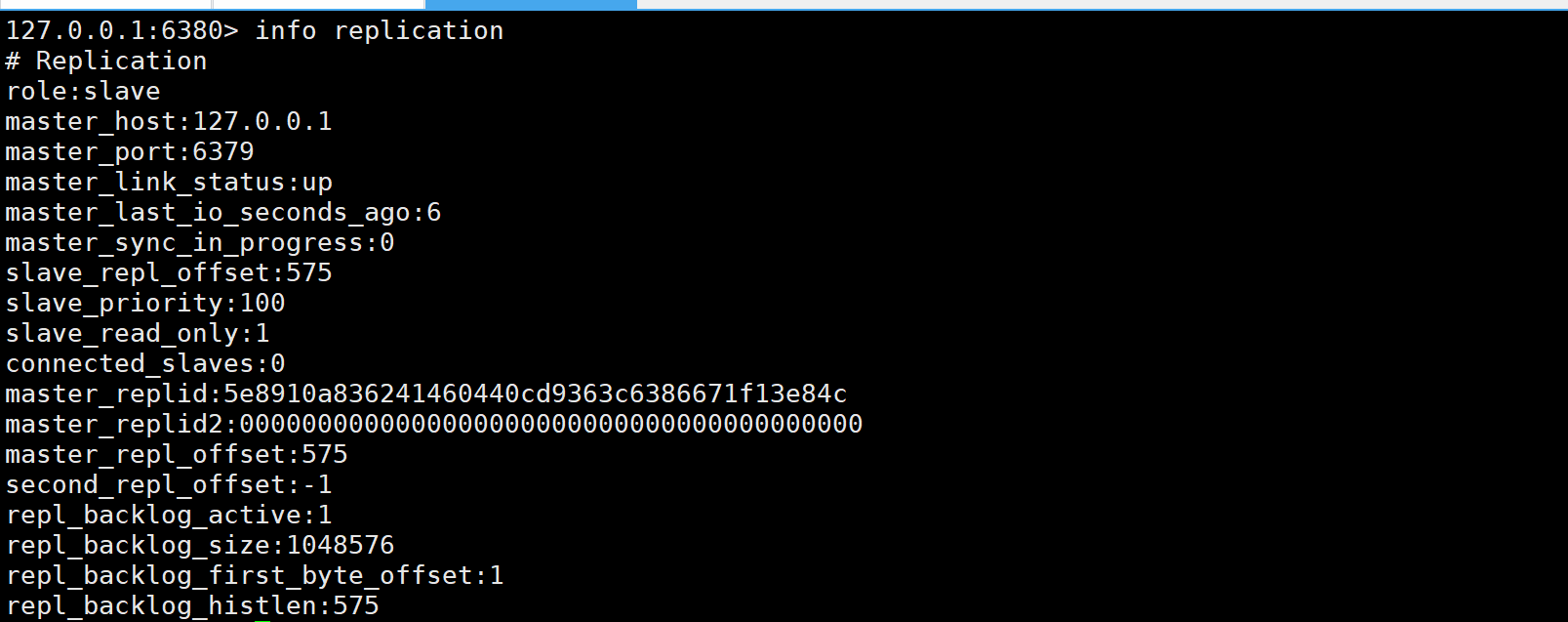
上述的信息可以通过redis官网中查询:

3.断开主从连接
从节点和主节点断开连接的两种情况
- 从节点和主节点主动断开连接slaveof no noe(此时从节点就晋升为主节点)
- 主节点挂了(这个时候从节点不会成为主节点,需要人工干预来恢复主节点)
通过slaveof no one命令直接断开现有的主从关系。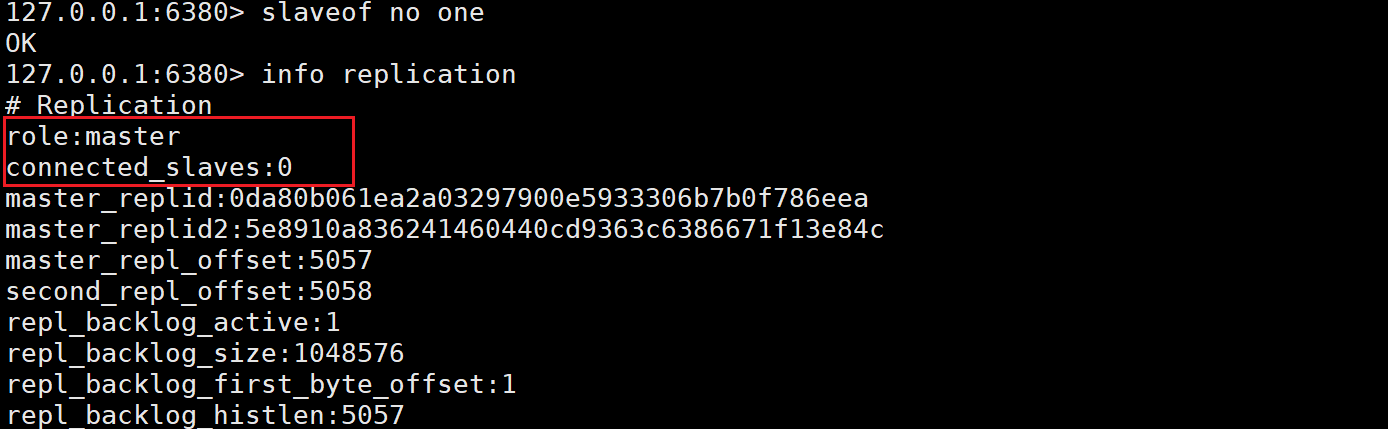
但是此时即使断开主从关系,原来从节点中的数据也是不会删除的:

4.投靠其他节点
使用命令slaveof 127.0.0.1 端口号来进行指定该客户端的主节点,但是此时通过命令修改是临时的,重启服务器就会改回去: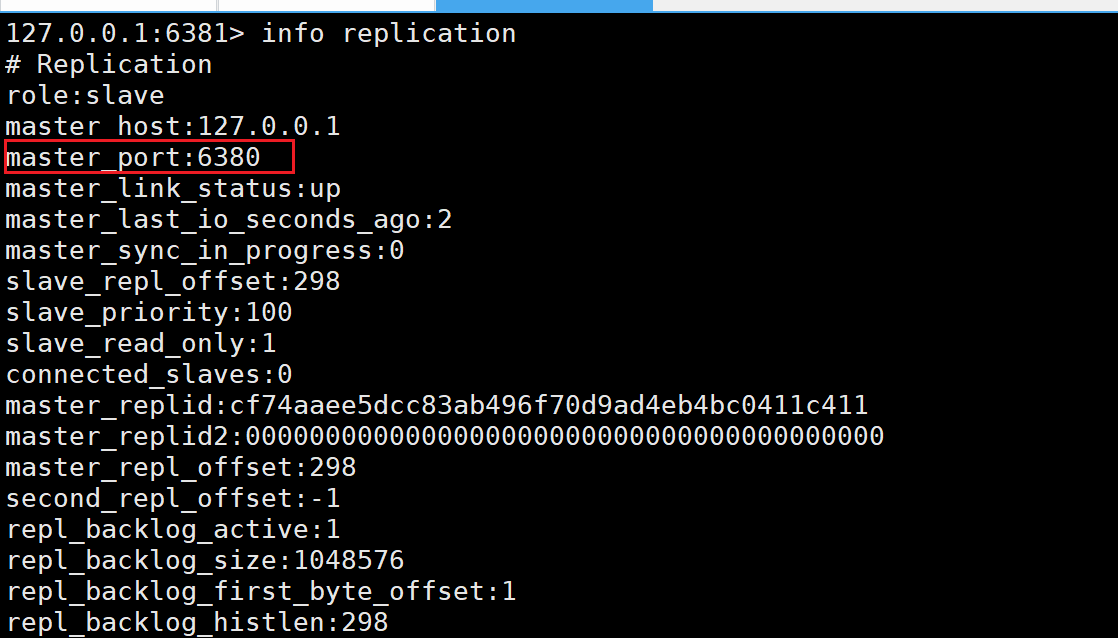
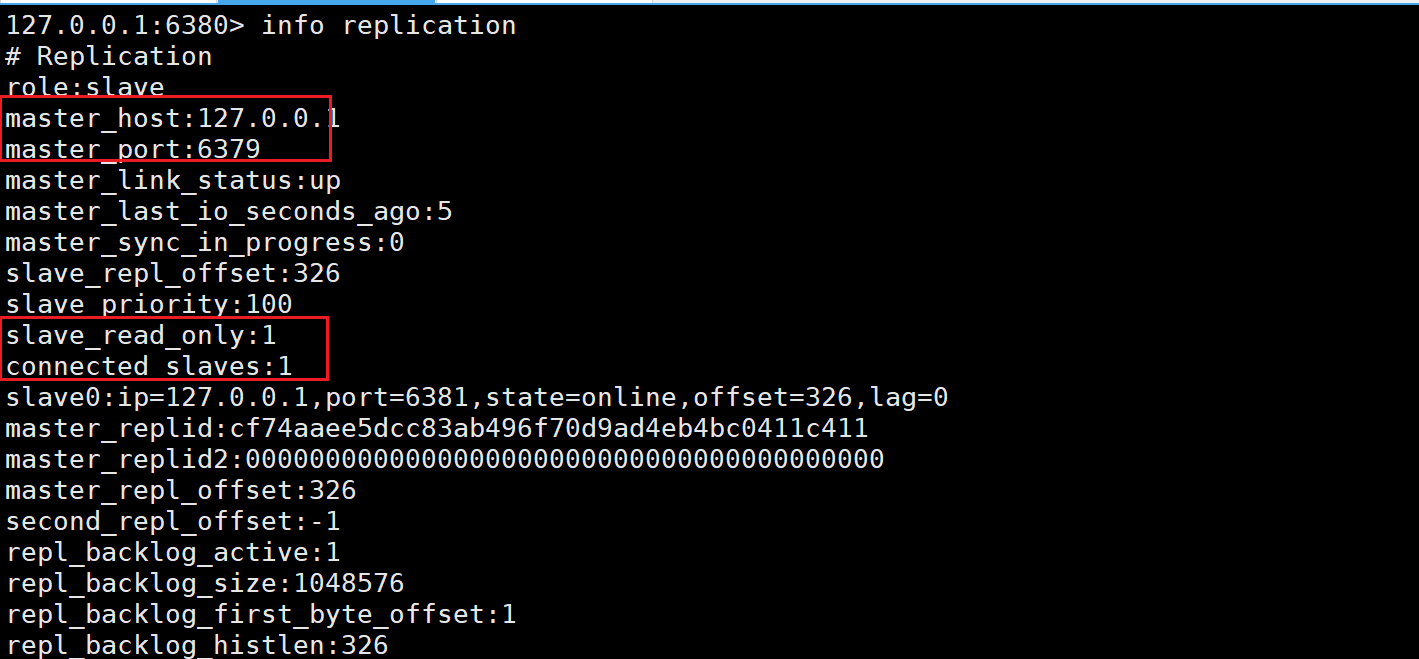
此时三个节点的关系是,379是6380的主节点,6380是6381的主节点,但是此时6380依旧没办法进行写操作:
5.安全性和只读
安全性
对于数据比较重要的节点,主节点会通过设置requirepass参数进行密码验证,这时所有的客户端访问必须使用auth命令实行校验。
从节点与主节点的复制连接是通过⼀个特殊标识的客户端来完成,因此需要配置从节点的masterauth参数与主节点密码保持⼀致,这样从节点才可以正确地连接到主节点并发起复制流程。
只读
默认情况下,从节点使用slave-read-only=yes配置为只读模式。由于复制只能从主节点到从节点,对于从节点的任何修改主节点都无法感知,修改从节点会造成主从数据不一致。所以建议线上不要修改从节点的只读模式。
6.传输延迟
主从节点⼀般部署在不同机器上,复制时的网络延迟就成为需要考虑的问题,Redis为我们提供了repl-disable-tcp-nodelay参数用于控制是否关闭TCP_NODELAY,默认为no,即开启tcpnodelay功能。
说明如下:
- 当关闭时,主节点产生的命令数据无论大小都会及时地发送给从节点,这样主从之间延迟会变小,但增加了网络带宽的消耗。适用于主从之间的网络环境良好的场景,如同机房部署。
- 当开启时,主节点会合并较小的TCP数据包从而节省带宽。默认发送时间间隔取决于Linux的内核,⼀般默认为40毫秒。这种配置节省了带宽但增大主从之间的延迟。适用于主从网络环境复杂的场景,如跨机房部署。
三.拓扑结构
1.一主一从结构
⼀主⼀从结构是最简单的复制拓扑结构,用于主节点出现宕机时从节点提供故障转移支持,如图所示。当应用写命令并发量较高且需要持久化时,可以只在从节点上开启AOF,这样既可以保证数据安全性同时也避免了持久化对主节点的性能干扰。但需要注意的是,当主节点关闭持久化功能时,如果主节点宕机要避免自动重启操作。
如果进行主节点的自动重启操作会导致主节点的数据丢失,一进步主从同步后,从节点的数据也丢失了,此时应该让主节点先获取从节点的AOF文件后,再进行重新启动。

2.一主多从结构
一主多从结构(星形结构)使得应用端可以利用多个从节点实现读写分离,如图所示。对于读比重较大的场景,可以把读命令负载均衡到不同的从节点上来分担压力。
同时一些耗时的读命令可以指定⼀台专门的从节点执行,避免破坏整体的稳定性。对于写并发量较高的场景,多个从节点会导致主节点写命令的多次发送从⽽加重主节点的负载。
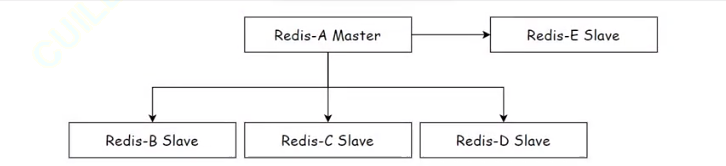
3.树形主从结构
树形主从结构(分层结构)使得从节点不但可以复制主节点数据,同时可以作为其他从节点的主
节点继续向下层复制。
通过引入复制中间层,可以有效降低主节点负载和需要传送给从节点的数据量,如图所示。数据写⼊节点A之后会同步给B和C节点,B节点进一步把数据同步给D和E节点。当主节点需要挂载等多个从节点时为了避免对主节点的性能⼲扰,可以采用这种拓扑结构。

4.原理
- 保存主节点的信息有IP和端口信息
- 主从建立连接是通过TCP连接
- 发送ping命令,是为了验证节点是否能够正常工作
- 权限验证只有redis主节点开启了密码才能进行验证
- 复制数据最关键的操作
- 复制数据最关键的操作

(1)数据同步 psync
redis提供了psync命令,完成数据同步的过程,但是psync的命令不需要手动执行,redis服务器会在建立好主从同步关系之后自动执行psync。从节点负责执行psync,从主节点中拉取数据。
- replicationid/replid(复制id)
主节点的复制id。主节点重新启动,或者从节点晋级成主节点,都会生成⼀个replicationid。(同一个节点,每次重启,生成的replicationid也会变化).从节点在和主节点建立连接之后,就会获取到主节点的replicationid。
一般情况下使用不到replid2,有一种情况会使用到replid2,假设此时有主节点A和一个从节点B,如果A和B通信过程中出现了一些网络抖动,B可能认为A挂了,此时B就会自己成为主节点(给自己生成一个replid)
但是,B此时依旧会记得之前旧的replid,也就是通过replid2获取的,后续网络稳定后,B还可以根据replid2重新回到A的从结构中(需要手动干预,如果哨兵机制,可以自动完成这个过程)
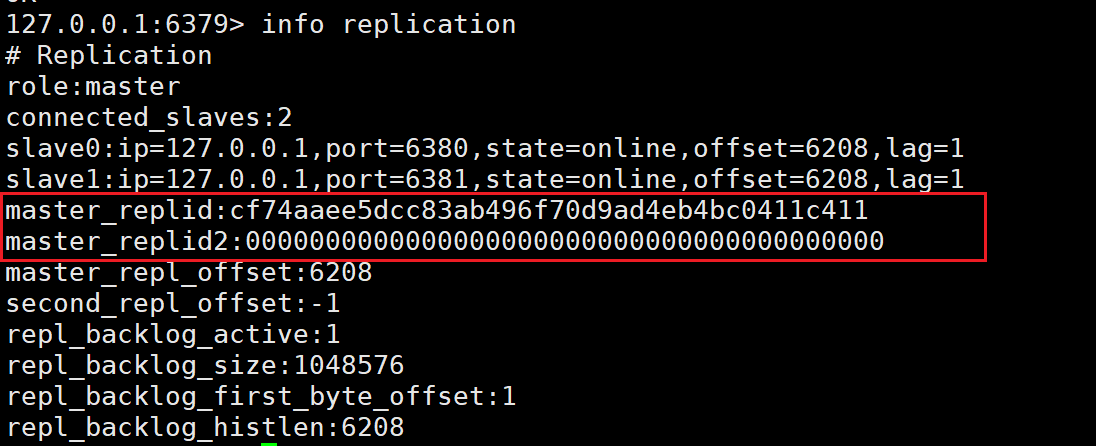
- offset偏移量
主节点和从节点都会维护偏移量,主节点的偏移量是通过主节点处理完写入命令后,把命令的字节长度做累加进行记录。从节点的偏移量描述的是现在从节点根据主节点的数据同步到了什么地方。
replication id 和 offset共同描述了一个数据集合,如果发现两台机器replication id和offset都是相同的,那么就可以认为这两个redis机器上存储的数据就是完全一样的。
(2)psync运行流程
psync可以从主节点获取全量数据,也可以获取一部分数据,主要是看offset此时的进度,如果offset写作-1,此时就是获取全量数据,如果offset写的是具体的整数,则是从当前偏移量位置来进行获取的。
获取所有数据是最稳妥的,但是会比较低效,如果从节点之前已经从主节点这里复制过一部分数据了,就只需要把新的之前没复制过的数据进行复制即可。
首次和主节点进行数据同步,或者是主节点不方便进行部分复制的时候,进行全量复制;从节点之前已经从主节点上复制过数据了,因为网络抖动或者从节点重启了,从节点需要重新从主节点上同步数据,此时看看能不能只同步一小部分(大部分数据是一致的)就使用部分复制。

四.全量复制和部分复制
1.全量复制流程
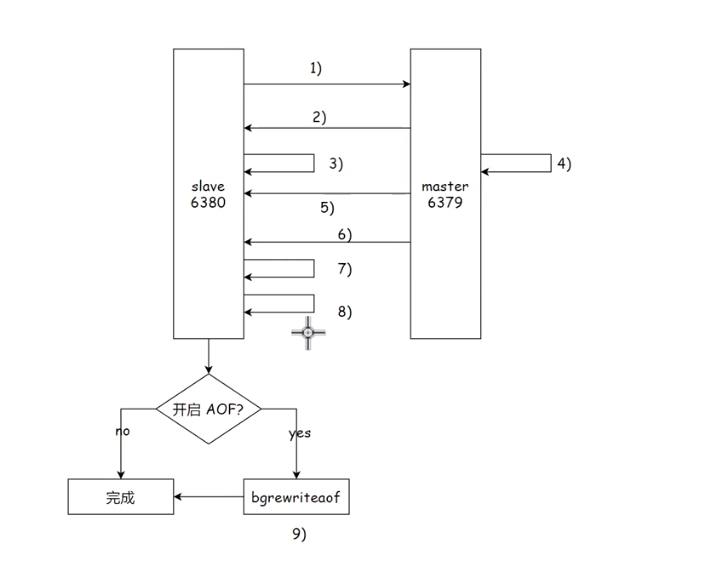
1)从节点发送psync命令给主节点进行数据同步,由于是第⼀次进行复制,从节点没有主节点的运行ID和复制偏移量,所以发送psync ?-1。
2)主节点根据命令,解析出要进行全量复制,回复+FULLRESYNC响应。
3)从节点接收主节点的运行信息进行保存。
4)主节点执行bgsave进行RDB文件的持久化。
5)主节点发送RDB文件给从节点,从节点保存RDB数据到本地硬盘。
6)主节点将从生成RDB到接收完成期间执行的写命令,写入缓冲区中,等从节点保存完RDB文件后,主节点再将缓冲区内的数据补发给从节点,补发的数据仍然按照rdb的二进制格式追加写入到收到的rdb文件中。保持主从⼀致性。
7)从节点清空自身原有旧数据。
8)从节点加载RDB⽂件得到与主节点⼀致的数据。
9)如果从节点加载RDB完成之后,并且开启了AOF持久化功能,它会进行bgrewrite操作,得到最近的AOF文件。
虽然主节点进行全量复制的时候,也支持无硬盘模式,也就是主节点生成的rdb二进制数据,不是直接保存到文件中了,而是直接进行了网络传输(省下了一系列读硬盘和写硬盘的操作)
从节点现在也可以省略把收到的rdb数据写入硬盘中再进行加载的过程,此时直接把收到的数据进行加载即可。
但是,在这个无硬盘模式下,整个操作仍然是比较重量的,也比较耗时,其中会有更多的网络数据传输,这是没办法省的,而且网络传输可是大头。
runid和replid
主节点

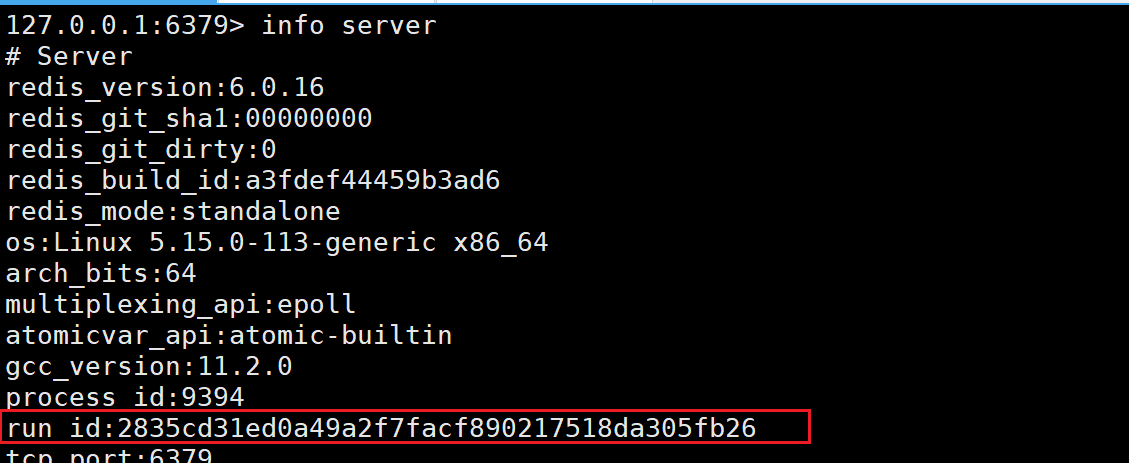
从节点


runid主要是用在支撑实现redis哨兵的功能,和主从复制并没有什么关系,而replid主要就是在主从复制中起到作用的。
2.部分复制主要流程
1)当主从节点之间出现⽹络中断时,如果超过repl-timeout时间,主节点会认为从节点故障并终端复制连接。
2)主从连接中断期间主节点依然响应命令,但这些复制命令都因网络中断无法及时发送给从节点,所以暂时将这些命令滞留在复制积压缓冲区(repl-backlog-buffer)中。
3)当主从节点网络恢复后,从节点再次连上主节点。
4)从节点将之前保存的replicationId和复制偏移量作为psync的参数发送给主节点,请求进行部分复制。
5)主节点接到psync请求后,进行必要的验证。随后根据offset去复制积压缓冲区查找合适的数据,并响应+CONTINUE给从节点。
6)主节点将需要从节点同步的数据发送给从节点,最终完成⼀致性。
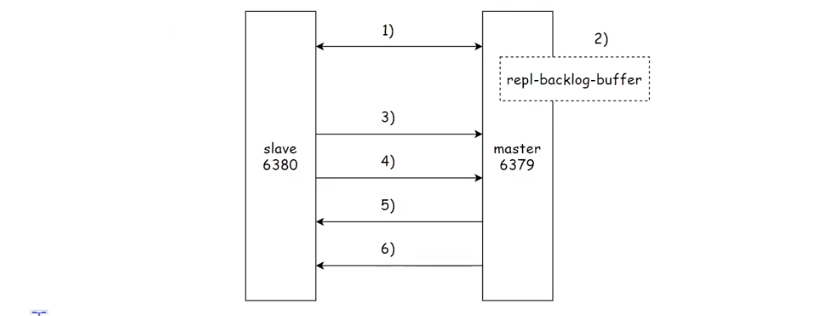
上述的积压缓冲区是一个内存中简单的队列,会记录最近一段时间修改的数据,总量是有限的,随着时间的推移,会把之前的旧数据逐渐删除。
上述replicationId不一样的话,就无法进行部分复制,只能进行全量复制,即使replicationId一致,还要看offset的偏移量是什么情况。
offset的值表示了此时从节点同步数据的进度是多少,主节点就看这个进度是否在当前积压缓冲区之内,如果在积压缓冲区之内,则可以直接进行部分复制,如果超出了积压缓冲区的范围,就是能进行全量复制。
五.实时复制
从节点已经和主节点同步好了数据,但是之后主节点这边会源源不断的收到新的修改数据请求,此时主节点上的数据就会随之改变,也需要同步给从节点。
从节点和主节点之间就会建立TCP长连接,然后主节点把自己收到的修改数据的请求通过上述连接,发给从节点,从节点再根据这些修改请求,修改内存中的数据。
在进行实时复制的时候,需要保证链接处于可用状态,此时就会用到心跳包机制。假设现在主节点默认每隔10s,给从节点发送一个ping命令,从节点返回一个pong;从节点默认每隔1s就给主节点发送一个特定的请求,就会上报当前从节点复制数据的进度(offset);其他详细的就不再赘述了。
六.主节点断开后无法连接
问题描述
如果将主节点的服务器进行关闭,此时就无法启动主节点的服务器了,因为此时三个redis server共用一个AOF文件,此时是不科学的,而且在最开始创建从节点的配置文件时,就没有修改生成AOF文件路径,所以就会导致这个问题出现。
从节点是通过手动启动的方式运行的。此时在root用户下启动redis服务器的话,生成的AOF文件也是root用户的文件。通过service redis-server start启动的redis服务器是通过一个redis这样的用户来启动的。

redis server 需要按照可读可写的方式打开这个AOF文件,而这个文件对于root以外的用户只有读权限,因此service redis-server start启动的redis服务器无法打开这个文件,就启动失败了。

解决方案
把三个rdis服务器生成的文件区分开,这个办法是可行的,但是更靠谱的方法是通过直接将三个redis服务器的工作目录分开,也就是修改配置文件中的dir选项。
-
停止全部redis服务器:

-
使用rm删除之前工作目录下已经生成的AOF文件 或者通过chown命令修改AOF文件所属的用户:
-
给从节点创建出新的目录,用来作为从节点的工作目录:

-
修改从节点的配置文件,搞一个新的目录作为工作目录:

之前的工作目录:
修改后的工作目录:

-
启动redis服务器:





)

介绍,附pdf)