一、前言
向量数据库技术正在快速发展,各服务商提供的产品在使用方式上存在显著差异。这些差异体现在数据存储结构、相似性检索方法、集合功能和条件筛选等多个方面。LangChain 对向量数据库基类进行了通用性封装,在一定程度上降低了迁移成本,但在选择向量数据库时仍需全面评估各产品间的差异。
二、向量数据库的分类
按部署方式和服务类型,向量数据库可分为以下几类:
- 本地文件向量数据库:将向量数据存储在本地文件系统中,通过数据库查询接口检索数据,如 Faiss。
- 本地部署 API 向量数据库:不仅支持本地部署,还提供便捷的 API 接口,允许通过网络请求访问和查询向量数据,通常具备更复杂的功能和管理选项,如 Milvus、Annoy、Weaviate 等。
- 云端 API 向量数据库:在云端存储向量数据,通过 API 提供数据访问和管理功能,如 TCVectorDB、Pinecone 等。
资料推荐
- 💡大模型中转API推荐
- ✨中转使用教程
三、快速上手指南
要快速掌握向量数据库的使用,可以将其类比为 Excel 电子表格,按照以下常见办公软件操作流程进行学习:
- 安装
- 写入数据
- 查找数据
- 删除数据
- 更新数据
- 保存数据
值得注意的是,向量数据库相比传统 SQL 数据库,查询功能更为简单,不支持复杂的事务处理,因此学习难度较低,上手更为容易。
四、Faiss 向量数据库简介
Faiss 是由 Facebook 团队开源的向量检索工具,专为高维空间的海量数据提供高效、可靠的相似性检索方案。它广泛应用于推荐系统、图片和视频搜索等领域。Faiss 支持 Linux、macOS 和 Windows 操作系统,在处理百万级向量的相似性检索时,Faiss 可以在牺牲一定搜索准确度的情况下,实现小于 10ms 的响应时间。
- 💡大模型中转API推荐
- ✨中转使用教程
- Faiss 官网:https://faiss.ai/
- Faiss 仓库:https://github.com/facebookresearch/faiss
Faiss 使用 C++ 开发,并提供了 Python 接口,可以通过 pip 安装 Faiss 库。
# CPU环境下使用
pip install faiss-cpu# GPU环境下使用并且已经安装了CUDA,则可以使用GPU版本
pip install faiss-gpu
目前,大多数向量数据库支持多种数据操作方法,如新增数据、检索数据、带得分的数据检索、带筛选条件的数据检索和删除数据等。然而,几乎都不支持修改数据。这是因为向量数据库通常使用特定的索引结构(如向量索引树或近似最近邻搜索算法),这些结构需要在数据插入后进行构建和优化。如果允许修改数据,索引结构可能会需要频繁更新,这将显著增加系统的复杂性和开销。因此,通常采取先删除后新增的方式。
Faiss 也具有类似的特性。不过,由于 Faiss 是本地文件向量数据库,它还支持将向量数据持久化到本地以及从本地文件夹加载向量数据库等操作。
五、Faiss 向量数据库使用技巧
1. 数据的导入与相似性搜索
在LangChain 中,提供了 from_texts 和 from_documents 两个通用方法,这两个方法可以快捷地将数据从文本和文档中导入到向量数据库中。由于向量数据库存储的是向量,因此需要传入一个文本嵌入模型,以便向量数据库自动将传入的文本转换为向量。
这些方法的使用使得将数据导入向量数据库变得简单高效,尤其是在需要快速进行相似性搜索时。通过这种方式,可以有效地管理和检索大规模的文本数据,从而满足各种应用场景的需求。
2. 代码示例:
import dotenv
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddingsdotenv.load_dotenv()embedding = OpenAIEmbeddings(model="text-embedding-3-small")db = FAISS.from_texts(["笨笨是一只很喜欢睡觉的猫咪","我喜欢在夜晚听音乐,这让我感到放松。","猫咪在窗台上打盹,看起来非常可爱。","学习新技能是每个人都应该追求的目标。","我最喜欢的食物是意大利面,尤其是番茄酱的那种。","昨晚我做了一个奇怪的梦,梦见自己在太空飞行。","我的手机突然关机了,让我有些焦虑。","阅读是我每天都会做的事情,我觉得很充实。","他们一起计划了一次周末的野餐,希望天气能好。","我的狗喜欢追逐球,看起来非常开心。",
], embedding)print(db.index.ntotal)
完成数据的填充后,即可在向量数据库中进行对应的检索,LangChain 为所有的向量数据库都设计封装了一致的搜索接口,最常用的有以下 4 种:
similarity_search():基础相似度搜索,传递 query(搜索语句)、k(返回条数)、filter(过滤器)、fetch_k(富余条数) 等。
similarity_search_with_score():携带得分的相似性搜索,参数和 similarity_search() 函数保持一致,只是会返回得分,这里的得分并不是相似性得分,而是欧几里得距离。
similarity_search_with_relevance_scores():携带相关性得分的相似性搜索,得分范围是 0-1
as_retriever():将向量数据库转换成检索器,检索器是 Runnable 可运行组件。
在向量数据库中进行检索并携带得分(这里的得分并不是相似性得分,默认是欧几里得距离),效果如下:
print(db.similarity_search_with_score("我养了一只猫,叫笨笨"))
输出内容:
10
[(Document(page_content='我养了一只猫,叫大笨'), 0.11375141), (Document(page_content='猫咪在窗台上打盹,看起来非常可爱。'), 1.0895041), (Document(page_content='我的狗喜欢追逐球,看起来非常开心。'), 1.3836973), (Document(page_content='我的手机突然关机了,让我有些焦虑。'), 1.5533546)]
由于不同文本嵌入模型生成向量的范围不一致,LangChain 封装的 Faiss 计算相关性得分的时候,可能会出现 bug(比如出现负数)。
print(db.similarity_search_with_relevance_scores("我养了一只猫,叫笨笨"))# 输出
[(Document(page_content='笨笨是一只很喜欢睡觉的猫咪', metadata={'page': 1}), 0.4592331743070337), (Document(page_content='猫咪在窗台上打盹,看起来非常可爱。', metadata={'page': 3}), 0.22960424668403867), (Document(page_content='我的狗喜欢追逐球,看起来非常开心。', metadata={'page': 10}), 0.02157827632118159), (Document(page_content='我的手机突然关机了,让我有些焦虑。', metadata={'page': 7}), -0.09838758604956)]
Faiss 计算相关性得分的核心代码如下(默认使用欧几里得距离计算相关性):
# langchain_community/vectorstores/faiss.py -> FAISS
def _euclidean_relevance_score_fn(distance: float) -> float:return 1.0 - distance / math.sqrt(2)
这个公式计算正确的前提是向量只有 2 维,并且向量的每个值范围是 [0, 1],这个公式的几何意义如下: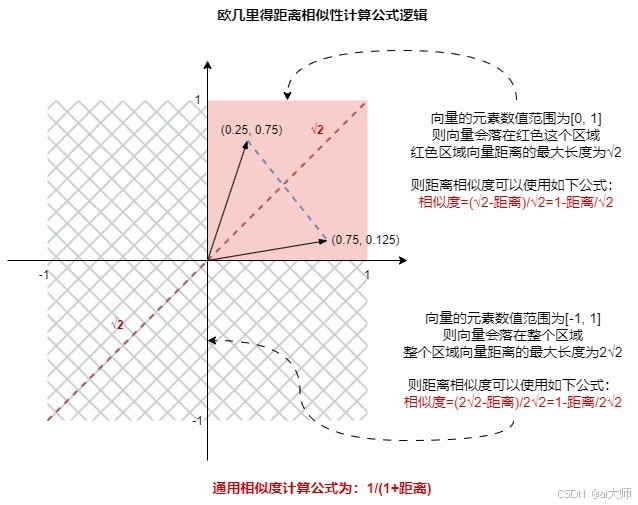
扩展到三维向量空间中(向量的范围是 [0, 1]),两个向量/点之间最大距离为 √3,并不是 √2,所以直接套用公式,可能会出现负数得分,在 N 维向量空间下,两点的最大距离是 √N,所以出现负数的概率大大增加。
可以修改成以下方式进行修正:
def _euclidean_relevance_score_fn(distance: float) -> float:return 1.0 / (1.0 + distance)
资料推荐
- 💡大模型中转API推荐
- ✨中转使用教程
在使用 LangChain 封装的向量数据库时,一定要注意测试和校验下文本嵌入模型生成向量的数值范围,避免出现明显的错误。由于向量数据库目前更新太快,而且 LangChain 封装了太多的第三方组件(数百个),在很多场合下,LangChain 可能没有对每一种情况进行测试,有可能会出现一些莫名其妙的计算结果。






