import numpy as np
import pandas as pd
import sklearn.datasets as sd# 鸢尾花数据集load_iris
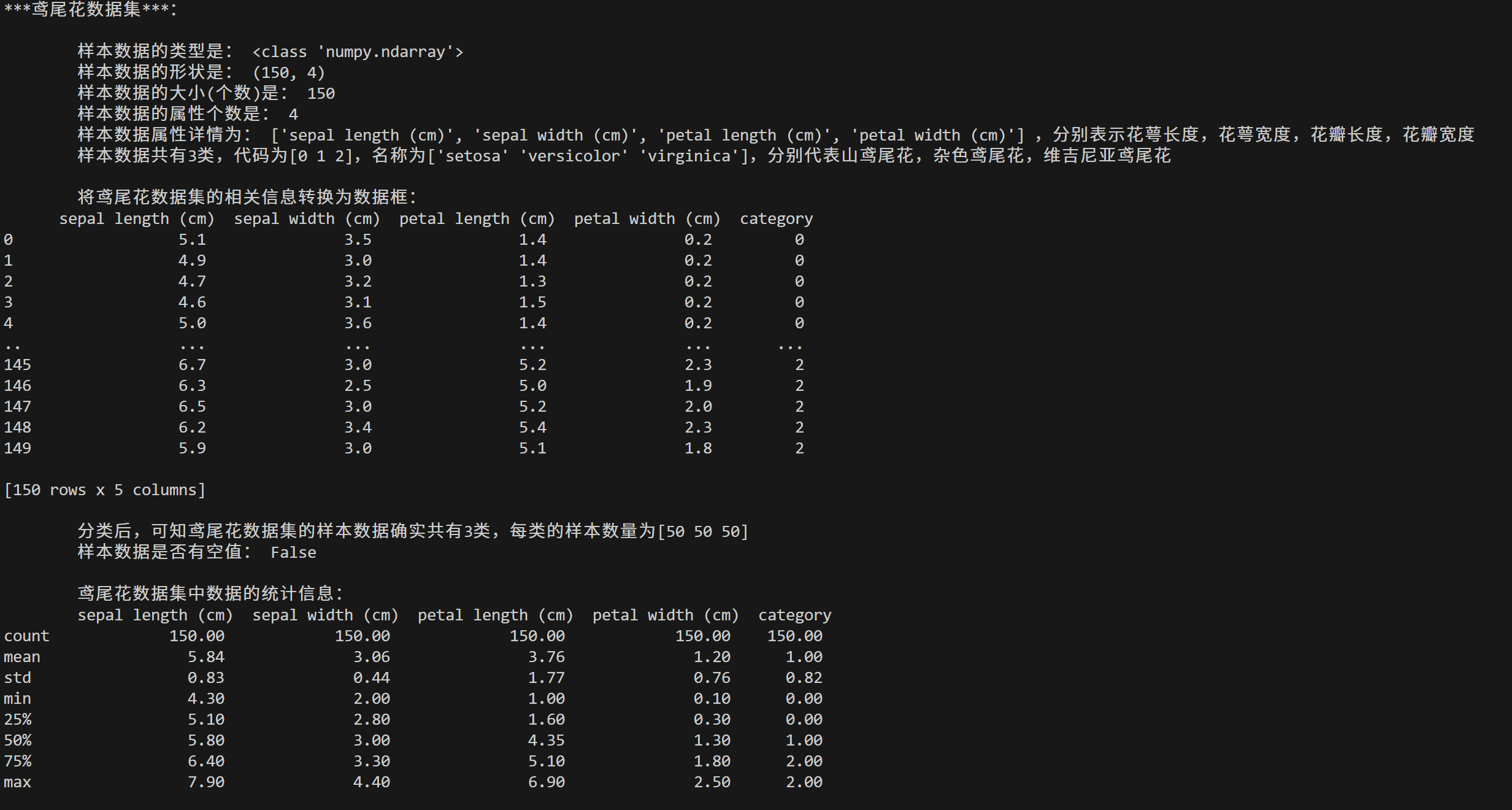
iris = sd.load_iris()print("***鸢尾花数据集***:\n")
print("\t样本数据的类型是:",type(iris.data))
print("\t样本数据的形状是:",iris.data.shape)
print("\t样本数据的大小(个数)是:",iris.data.shape[0])
print("\t样本数据的属性个数是:",iris.data.shape[1])
print("\t样本数据属性详情为:",iris.feature_names,",分别表示花萼长度,花萼宽度,花瓣长度,花瓣宽度")
print(f"\t样本数据共有{len(np.unique(iris.target))}类,代码为{np.unique(iris.target)},名称为{iris.target_names}",end=',')
print("分别代表山鸢尾花,杂色鸢尾花,维吉尼亚鸢尾花")df_iris = pd.DataFrame(data=iris.data,columns=iris.feature_names)
df_iris['category'] = iris.target
df_iris_grouped = df_iris.groupby(by='category').size()
print("\n\t将鸢尾花数据集的相关信息转换为数据框:\n",df_iris)
print(f"\n\t分类后,可知鸢尾花数据集的样本数据确实共有{len(df_iris_grouped)}类,每类的样本数量为{df_iris_grouped.values}")
print("\t样本数据是否有空值:",df_iris.isna().any().any()) # df.isna()等同于df.isnull(),是后期的pandas版本引入的,目的是为了和numpy中的isna保持一致
print("\n\t鸢尾花数据集中数据的统计信息:\n",df_iris.describe().map(lambda x:float(f'{x:.2f}')))# 葡萄酒数据集load_wine
wine = sd.load_wine()
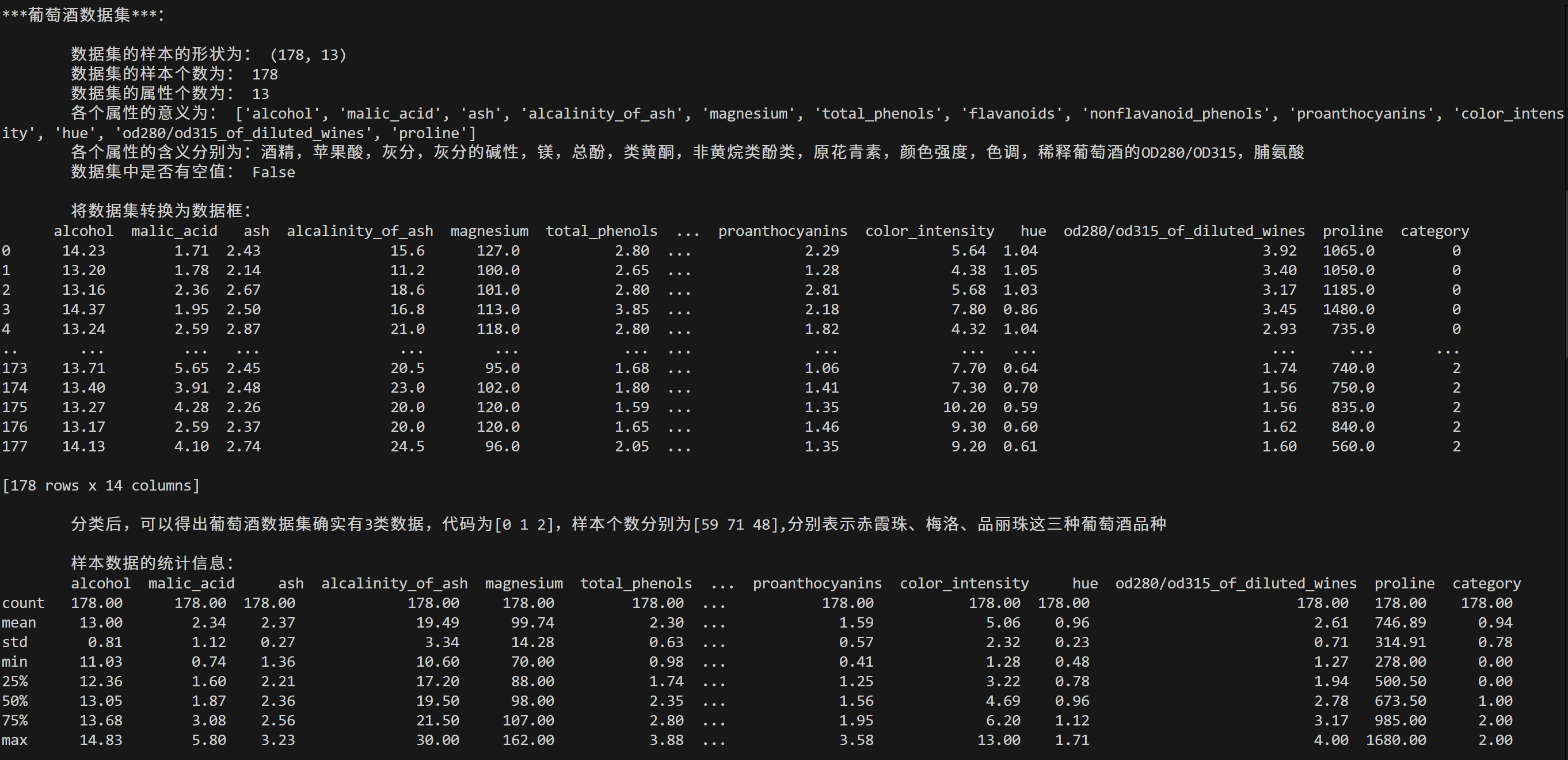
print('\n'*5 + '***葡萄酒数据集***:\n')
print("\t数据集的样本的形状为:",wine.data.shape)
print("\t数据集的样本个数为:",len(wine.data))
print("\t数据集的属性个数为:",wine.data.shape[1])
print("\t各个属性的意义为:",wine.feature_names)
print("\t各个属性的含义分别为:酒精,苹果酸,灰分,灰分的碱性,镁,总酚,类黄酮,非黄烷类酚类,原花青素,颜色强度,色调,稀释葡萄酒的OD280/OD315,脯氨酸")
print("\t数据集中是否有空值:",np.isnan(wine.data).any())df_wine = pd.DataFrame(data=wine.data,columns=wine.feature_names)
df_wine['category'] = wine.target
df_wine_grouped = df_wine.groupby(by='category').size()
print("\n\t将数据集转换为数据框:\n",df_wine)
print(f"\n\t分类后,可以得出葡萄酒数据集确实有{len(df_wine_grouped)}类数据,代码为{np.unique(wine.target)},样本个数分别为{df_wine_grouped.values},分别表示赤霞珠、梅洛、品丽珠这三种葡萄酒品种")
print("\n\t样本数据的统计信息:\n",df_wine.describe().map(lambda x:float(f'{x:.2f}')))# 糖尿病数据集load_diabetes
diabetes = sd.load_diabetes()
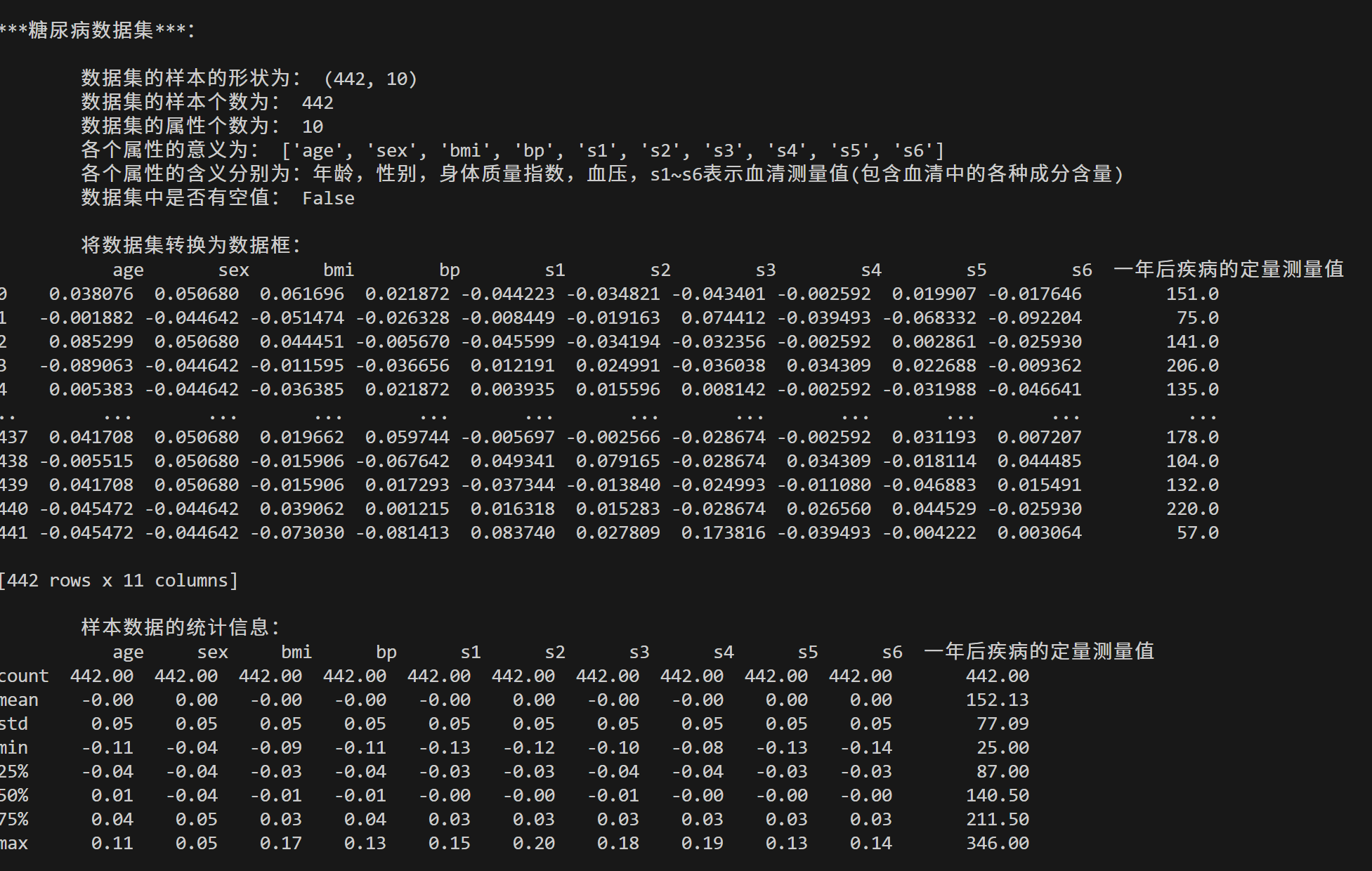
print('\n'*5 + '***糖尿病数据集***:\n')
print("\t数据集的样本的形状为:",diabetes.data.shape)
print("\t数据集的样本个数为:",len(diabetes.data))
print("\t数据集的属性个数为:",diabetes.data.shape[1])
print("\t各个属性的意义为:",diabetes.feature_names)
print("\t各个属性的含义分别为:年龄,性别,身体质量指数,血压,s1~s6表示血清测量值(包含血清中的各种成分含量)")
print("\t数据集中是否有空值:",np.isnan(diabetes.data).any())df_diabetes = pd.DataFrame(data=diabetes.data,columns=diabetes.feature_names) # 注:每个特征变量都经过均值中心化等一些处理,使得每列平方和为1
df_diabetes['一年后疾病的定量测量值'] = diabetes.target
print("\n\t将数据集转换为数据框:\n",df_diabetes)
print("\n\t样本数据的统计信息:\n",df_diabetes.describe().map(lambda x:float(f'{x:.2f}')))# 乳腺癌数据集load_breast_cancer
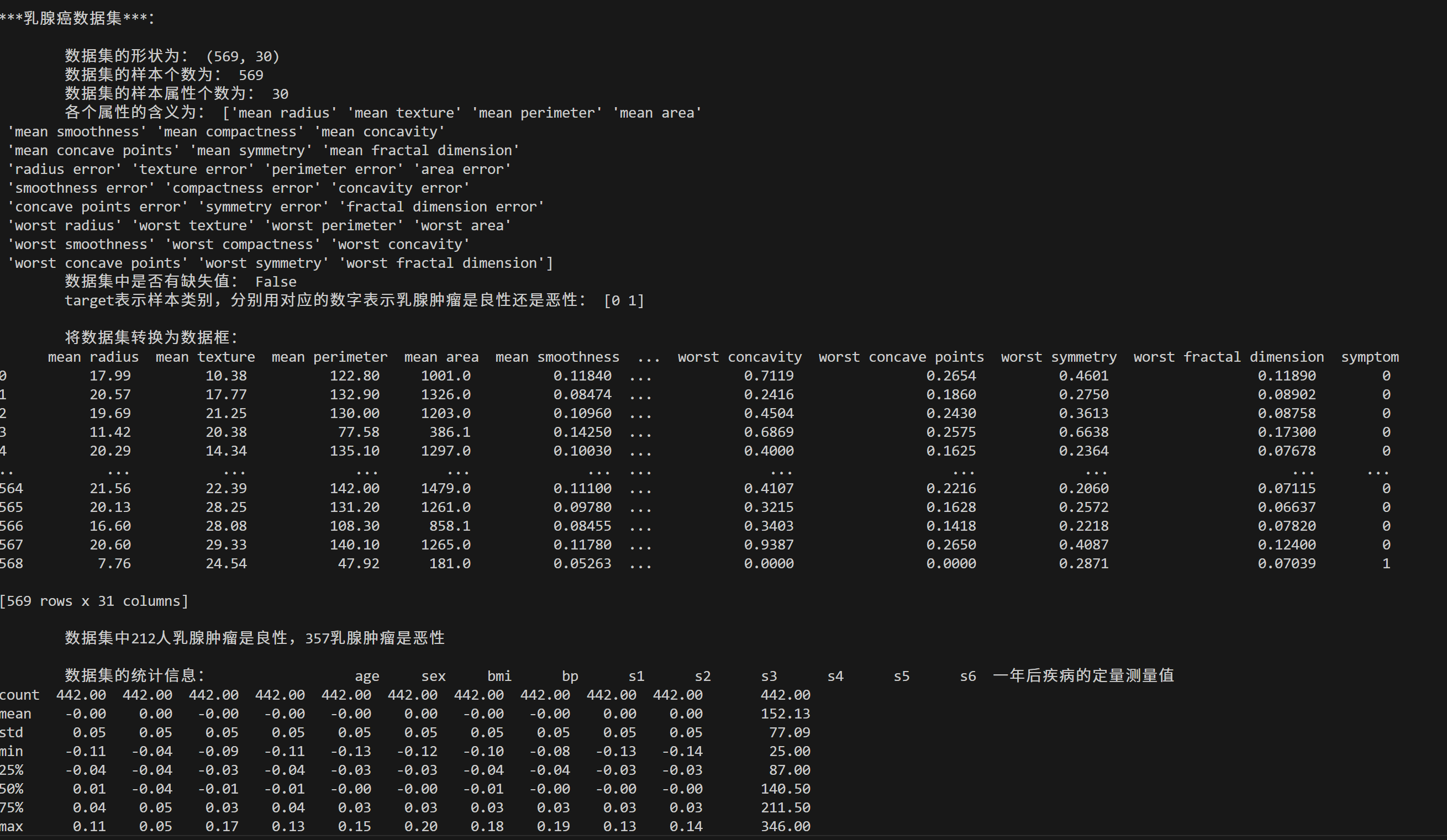
breast_cancer = sd.load_breast_cancer()print('\n'*5 + '***乳腺癌数据集***:\n')
print("\t数据集的形状为:",breast_cancer.data.shape)
print("\t数据集的样本个数为:",breast_cancer.data.shape[0])
print("\t数据集的样本属性个数为:",breast_cancer.data.shape[1])
print("\t各个属性的含义为:",breast_cancer.feature_names)
print("\t数据集中是否有缺失值:",np.isnan(breast_cancer.data).any())
print("\ttarget表示样本类别,分别用对应的数字表示乳腺肿瘤是良性还是恶性:",np.unique(breast_cancer.target))df_breast_cancer = pd.DataFrame(data=breast_cancer.data,columns=breast_cancer.feature_names)
df_breast_cancer['symptom'] = breast_cancer.target
df_breast_cancer_grouped = df_breast_cancer.groupby(by='symptom').size()
print("\n\t将数据集转换为数据框:\n",df_breast_cancer)
print(f"\n\t数据集中{df_breast_cancer_grouped[0]}人乳腺肿瘤是良性,{df_breast_cancer_grouped[1]}乳腺肿瘤是恶性")
print("\n\t数据集的统计信息:\t",df_diabetes.describe().map(lambda x:float(f'{x:.2f}')))
输出(从后往前):
)





