一.Math模块
- 常量
- 常用方法
二.collections模块
- 类比字典:counter,defaultdict,orderdict
- 类比列表:deque
三.heapq模块
四.functools模块
五.itertools模块
- 无限迭代器:count,cycle,repeat
- 有限迭代器
- 排列组合迭代器
一.Math模块

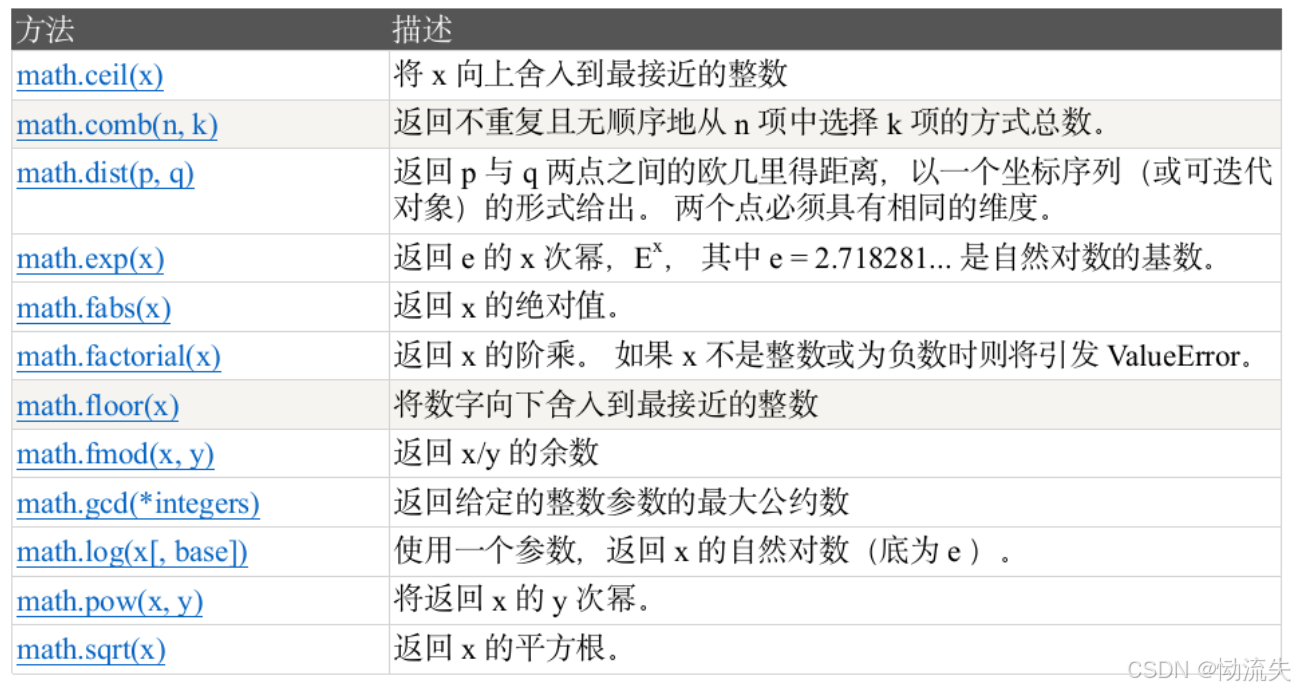
1.常量
通过常量的输出获取各个值
print(math.e) #输出欧拉数2.71828
print(math.pi) #输出圆周率π
print(math.inf) #输出正无穷大数
print(-math.inf) #输出负无穷大数
print(math.nan) #输出浮点值nan
print(math.tau) #输出数学常数2π2.718281828459045
3.141592653589793
inf
-inf
nan
6.2831853071795862.常用方法
print(math.ceil(math.tau))#向上取整
print(math.floor(math.tau))#向下取整
print(math.comb(6,2))#从6个中随机抽2个的排列总数
print(math.exp(3)) #e的3次方
print(math.sqrt(3)) #输出3的平方根
print(math.pow(2,3))#输出2的3次幂
print(math.factorial(5)) #阶乘
print(math.gcd(13,5))#输出13和5的最大公约数
7
6
15
20.085536923187668
1.7320508075688772
8.0
2.0
120
1
二.collections模块
1.类比字典
1.counter
它接受一个可迭代对象作为输入,并返回一个字典,其中键是输入对象的元素,值是该元素在输入对象中出现的次数。
定义1:counter(可迭代对象)
from collections import Counter
print(Counter()) #空counter
print(Counter("hello word")) #统计字符出现的次数
print(Counter([1, 2, 3, 4, 5])) #统计该列表元素出现的次数
a=["apple","banana","cherry","apple","apple","banana"]
b=Counter(a)
print(b)
for k,v in b.items():print(k,v)Counter()
Counter({'l': 2, 'o': 2, 'h': 1, 'e': 1, ' ': 1, 'w': 1, 'r': 1, 'd': 1})
Counter({1: 1, 2: 1, 3: 1, 4: 1, 5: 1})
Counter({'apple': 3, 'banana': 2, 'cherry': 1})
apple 3
banana 2
cherry 1定义2:使用字典来定义
1.使用字典的方法创建一个计数器
from collections import Counter
b=Counter({'a':2,'b':3,'c':4,'d':5})
c=Counter(a=1,b=2,c=3,d=5)
print(b)
print(c)Counter({'d': 5, 'c': 4, 'b': 3, 'a': 2})
Counter({'d': 5, 'c': 3, 'b': 2, 'a': 1})用法1:常用的方法
计数器.most_common(n):输出频率最高的前n项
from collections import Counter
a=Counter("hello world")
print("频率最高的两个:",a.most_common(2))
print("将计数器还原成一个列表:",list(a.elements()))频率最高的两个: [('l', 3), ('o', 2)]
将计数器还原成一个列表: ['h', 'e', 'l', 'l', 'l', 'o', 'o', ' ', 'w', 'r', 'd']用法2:属性
同时计数器还具备字典的属性,如:输出键名,输出值
print(a.keys())
print(a.values())dict_keys(['h', 'e', 'l', 'o', ' ', 'w', 'r', 'd'])
dict_values([1, 1, 3, 2, 1, 1, 1, 1])用法3:数学运算
- a+b:计数器a与计数器b各元素数量的和
- a-b:计数器a与计数器b各元素数量的差,当a中元素数小于b时,既会返回该元素为0
- a&b:计数器a与计数器b各元素数量取交集.
- a|b:计数器a与计数器b各元素数量的并集.
a=Counter(a=2,b=1)
b=Counter(a=3,b=2,c=1)
print(a+b)
print(a-b)
print(a&b)
print(a|b)
Counter({'a': 5, 'b': 3, 'c': 1})
Counter()
Counter({'a': 2, 'b': 1})
Counter({'a': 3, 'b': 2, 'c': 1})
2.defaultdict
当访问不存在键的情况下,会调用该函数以产生一个默认值,从而避免了在查询字典时检查键是否存在的需要。
defaultdict:有默认值的字典,因为正常的字典使用.get()函数获取值才不会出现报错,但是这样太麻烦
正常情况:使用.det()方法才不会报错
dict1={}
print(dict1.get("x"))None1.设置默认值类型
from collections import defaultdict
d=defaultdict(list) #默认值类型为空列表
print(d["x"])
d=defaultdict(int) #默认值类型为数值
print(d["x"])
d=defaultdict(set) #默认值类型为空集合
print(d["x"])
d=defaultdict(dict) #默认值类型为空字典
print(d["x"])[]
0
set()
{}2.用法
题目:有一个列表"s=[("yellow",1),("yellow",3),("blue",2),("red",1)]",将相同颜色后的数字加起来
一般方法:
s=[("yellow",1),("yellow",3),("blue",2),("red",1)]
d={}
for k,v in s:if k not in d: #这一步会省略d[k]=[]d[k].append(v)
print(d){'yellow': [1, 3], 'blue': [2], 'red': [1]}使用defaultdict,有默认值的字典
s=[("yellow",1),("yellow",3),("blue",2),("red",1)]
d=defaultdict(list)
for k,v in s:d[k].append(v)
print(d)
print(d["yellow"])defaultdict(<class 'list'>, {'yellow': [1, 3], 'blue': [2], 'red': [1]})
[1, 3]3.orderdict
有序字典orderdict,由于版本更替,3.7以后的版本,字典的键值对第一个插入就在第一个位置
最后一个插入就在最后一个,popitem()3.7以前是随便删,以后是删除最后一个
move_to_end("c",last=False):表示将键名为c的移动到首位,默认值为True表示移动到最后
from collections import OrderedDict
a=[("a",1),("b",2),("c",3)]
b=OrderedDict(a)
print(b)
b.popitem(last=False)#True默认删除最后一个,False删除第一个
print(b)
b.move_to_end("c",last=False) #True默认是尾部,False是首位
print(b)OrderedDict([('a', 1), ('b', 2), ('c', 3)])
OrderedDict([('b', 2), ('c', 3)])
OrderedDict([('c', 3), ('b', 2)])2.类比列表
1.deque

与列表相比,deque在首尾两端插入和删除元素的时间复杂度为O(1),因此在需要频繁从两端操作的情况下更为高效。
#双端队列deque,类比列表
from collections import deque
a=deque([1,2,3,4])
print(a) #输出双端队列
#添加
a.append(5)
a.appendleft(0)
print(a)
a.extend([1,2])
a.extendleft([1,2])
print(a)
#删除
a.pop()
a.popleft()
print(a)
#特有的:2:向右移动2步骤,-2:向左移动两步
a.rotate(1)
print(a)
a.rotate(-1)
print(a)
deque([1, 2, 3, 4])
deque([0, 1, 2, 3, 4, 5])
deque([2, 1, 0, 1, 2, 3, 4, 5, 1, 2])
deque([1, 0, 1, 2, 3, 4, 5, 1])
deque([1, 1, 0, 1, 2, 3, 4, 5])
deque([1, 0, 1, 2, 3, 4, 5, 1])
三.heapq模块
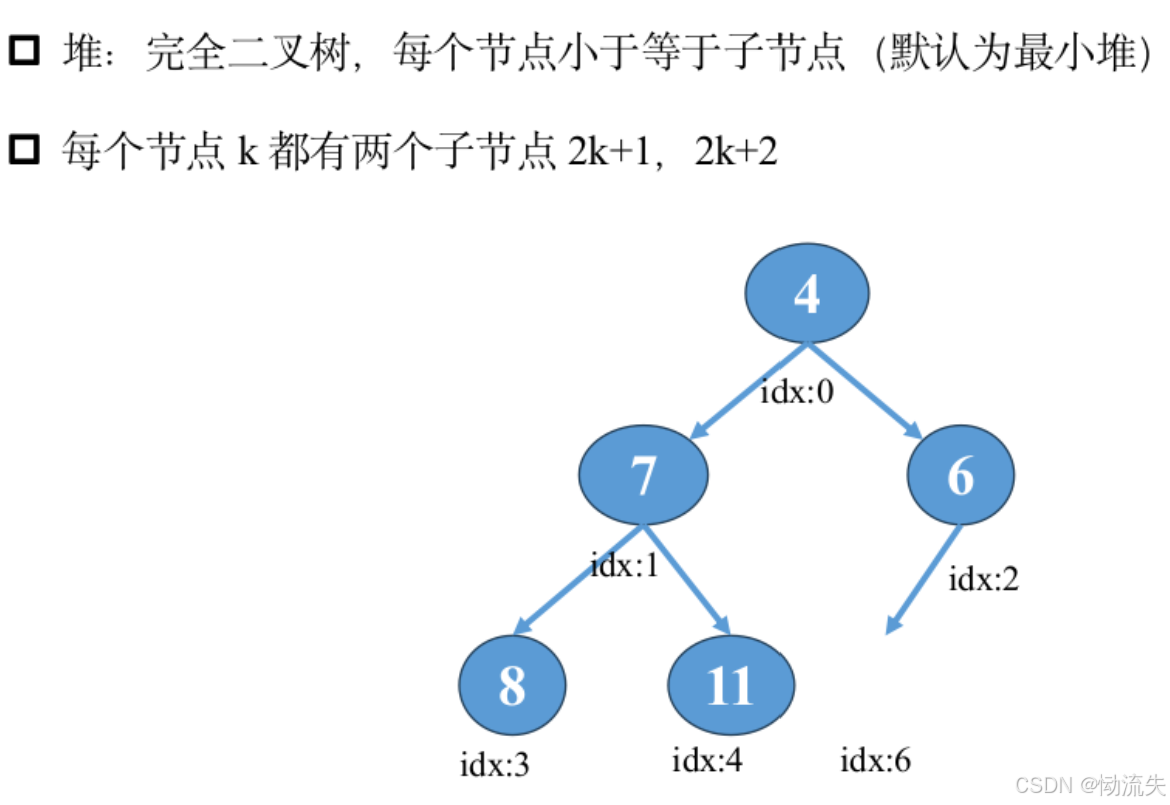
- heappush(heap, item):将值item推入堆heap中。每次加入新元素后,heapq库会自动调整堆使之重新有序,时间复杂度为O(logn)。
- heappop(heap):弹出并返回堆中的最小项。要访问堆中的最小项而不弹出,可以直接使用heap[0]。
- heapify(x):将列表x在线性时间内转换为最小堆。这个方法不会返回任何值,但会修改传入的列表x,使其满足最小堆的性质。
- heapreplace(heap, item):弹出并返回heap中最小的一项,同时推入新的item。这个方法相当于先执行heappop()再执行heappush(),但同样地,heapreplace()通常比这两个操作组合更高效。
#左节点2k+1,右节点2k+2
import heapq #导入堆:完全二叉树
a=[11,6,9,8,7,3]
heapq.heapify(a) #最小二叉树,将列表化为最小堆
print(a)
del_item=heapq.heappop(a)#谈出并返回最小元素
print("弹出的元素:",del_item)
print(a)
heapq.heappush(a,2) #将2添加进入,形成最小堆
print(a)
heapq.heapreplace(a,19)#弹出最小值,并添加19,形成最小堆
print(a)[3, 6, 9, 8, 7, 11]
弹出的元素: 3
[6, 7, 9, 8, 11]
[2, 7, 6, 8, 11, 9]
[6, 7, 9, 8, 11, 19]四.functools模块
functool函数用于高阶函数,既参数或返回值为其他函数
functool.partial:冻结某些函数的参数或关键字参数,然后返回一个函数
语法格式:functools.partial(func,*args,**kwargs) #这个不会进行调用函数
func.() #调用函数
- func:需要被扩展的函数
- *args:需要固定位置的参数
- **kwargs:需要固定的关键字参数
用法1:
from functools import partial
def add(a,b,c):print("a=",a)print("b=",b)print("c=",c)print("a+b+c=",a+b+c)
add(1,2,3)
f_add=partial(add,3,4) #按照固定位置,且必备参数与默认参数的顺序与函数参数形式一样
f_add(1)f_add=partial(add,3,4):表示扩展add()函数,且a=3,b=4
f_add(1):表示将1传给形参c
a= 1
b= 2
c= 3
a+b+c= 6
a= 3
b= 4
c= 1
a+b+c= 8用法2:
f_Add=partial(Add,10,20,K1=1,K2=2):表示,扩展Add()函数,并将10,20作为参数传给*args,K1=1,K2=2传给**kwargs
f_Add(1,2,3):表示将1,2,3传给不定长参数1*args
def Add(*args,**kwargs):for i in args:print(i)for k,v in kwargs:print(k,v)
f_Add=partial(Add,10,20,K1=1,K2=2)
f_Add(1,2,3)10
20
1
2
3
K 1
K 2五.itertools模块
一.无限迭代器
1.count
语法格式:itertools.count(start,step)
生成一个从start开始,每次增加step的无限递增整数序列。
from itertools import *
a=[]
for i in count(start=0, step=1): #起始值为0,步长为1a.append(i)print(i)if i==10: #如果不设置这个,迭代器会一直运行下去break0
1
2
3
4
5
6
7
8
9
102.cycle
语法格式:itertools.cycle(可迭代对象)
无限循环地遍历可迭代对象中的元素。
a=[1,2,3]
n=0
for i in cycle(a):print(i)n+=1if n==6:break1
2
3
1
2
33.repeat
语法格式:itertools.repeat(object,times=None)
重复生成某个元素,最多重复times次;如果times为None,则无限重复
for i in repeat("5",3):print(i)5
5
5二.有限迭代器
accumulate(iterable, func=operator.add):对迭代器中的元素进行累积运算。
chain(a,b):将a,b两个可迭代对象拼接起来
from itertools import *
import operator
a=[]
for i in count(1,1):a.append(i)if i==10:break
print(a)
print("输出每一个前n项和:",list(accumulate(a)))
print("取两个元素中的最大值:",list(accumulate(a,max)))
print("取两个元素中的最小值:",list(accumulate(a,min)))
print("使用乘法,前n项乘积:",list(accumulate(a,operator.mul)))for x in chain("abc","def"):print(x)
a=chain("abc","def")
print(list(a))
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
输出每一个前n项和: [1, 3, 6, 10, 15, 21, 28, 36, 45, 55]
取两个元素中的最大值: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
取两个元素中的最小值: [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
使用乘法,前n项乘积: [1, 2, 6, 24, 120, 720, 5040, 40320, 362880, 3628800]
a
b
c
d
e
f
['a', 'b', 'c', 'd', 'e', 'f']进程已结束,退出代码为 0
三.排列组合迭代器
permutations(iterable, r=None):生成可迭代对象中所有长度为r的排列。如果r为None,则生成所有可能的排列。combinations(iterable, r):生成可迭代对象中所有长度为r的组合,不考虑元素顺序。combinations_with_replacement(iterable, r):生成可迭代对象中所有长度为r的组合,允许元素重复。product(*iterables, repeat=1):计算多个可迭代对象的笛卡尔积,即所有输入可迭代对象中元素的排列组合。
from itertools import *#使用product进行笛卡尔积
ans=product([1,2,3],[4,5,6])
print(list(ans))
ans2=product([1,2,3],repeat=2)
print(list(ans2))
#输出排列
a=list(permutations([1,2,3,4]))
for i in a:print(i)
b=list(permutations([1,2,3,4],r=2)) #选出两个进行排列
for i in b:print(i)
#输出组合
a=list(combinations([1,2,3,4],r=2)) #选出两个组合
print(list(a))
E:\Python\Python3.10.10\python.exe E:\1各科文件\python.资料\网课笔记\第二阶段网课\第二周婷婷基础\16.6排列组合迭代器.py
[(1, 4), (1, 5), (1, 6), (2, 4), (2, 5), (2, 6), (3, 4), (3, 5), (3, 6)]
[(1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (2, 3), (3, 1), (3, 2), (3, 3)]
(1, 2, 3, 4)
(1, 2, 4, 3)
(1, 3, 2, 4)
(1, 3, 4, 2)
(1, 4, 2, 3)
(1, 4, 3, 2)
(2, 1, 3, 4)
(2, 1, 4, 3)
(2, 3, 1, 4)
(2, 3, 4, 1)
(2, 4, 1, 3)
(2, 4, 3, 1)
(3, 1, 2, 4)
(3, 1, 4, 2)
(3, 2, 1, 4)
(3, 2, 4, 1)
(3, 4, 1, 2)
(3, 4, 2, 1)
(4, 1, 2, 3)
(4, 1, 3, 2)
(4, 2, 1, 3)
(4, 2, 3, 1)
(4, 3, 1, 2)
(4, 3, 2, 1)
(1, 2)
(1, 3)
(1, 4)
(2, 1)
(2, 3)
(2, 4)
(3, 1)
(3, 2)
(3, 4)
(4, 1)
(4, 2)
(4, 3)
[(1, 2), (1, 3), (1, 4), (2, 3), (2, 4), (3, 4)]进程已结束,退出代码为 0
)

)



