一、 编辑文本的命令
正则表达式匹配的是文本内容,Linux的文本三剑客,都是针对文本内容。
文本三剑客
grep:过滤文本内容
sed:针对文本内容进行增删改查 (本文不相关)
awk:按行取列 (本文不相关)
文本三剑客都是按行进行匹配。
1.1 grep命令
grep的作用就是使用正则表达式来匹配文本内容。
选项:
-m:匹配几次之后停止,一行有多个匹配的内容也仅视为一次匹配-v:取反,所有不包含匹配内容的行-n:显示匹配内容所在的行号-c:仅统计匹配的行数-o:仅显示匹配的内容-q:静默模式,不输出结果到终端。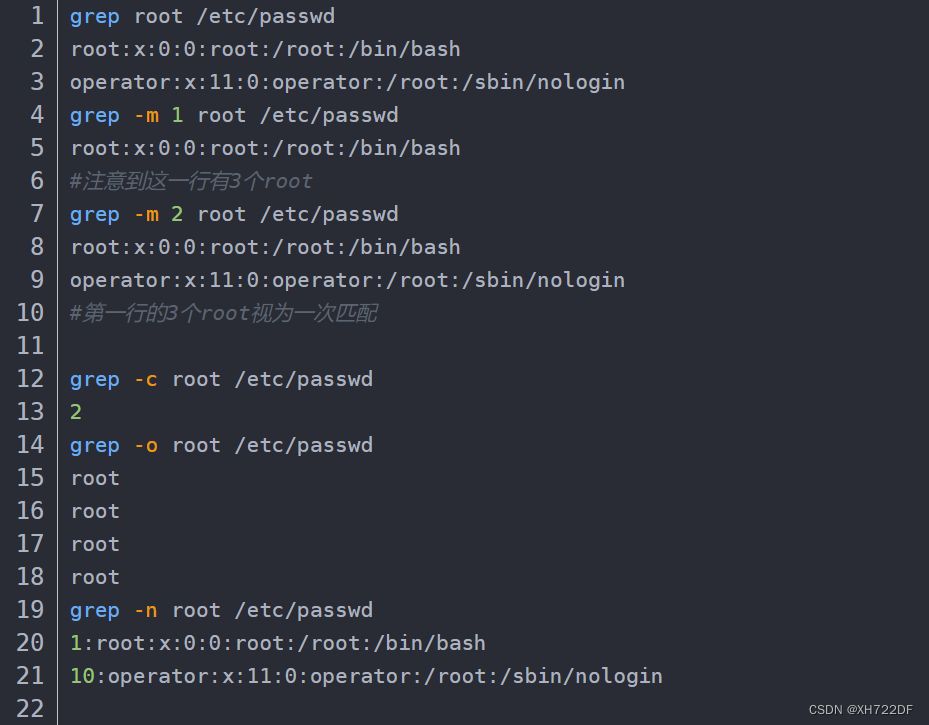
-A:after,跟数字,显示匹配到的内容所在行以及之后的几行-B:before,跟数字,显示匹配到的内容所在行以及之前的几行-C:跟数字,显示匹配到的内容所在行之前以及之后的几行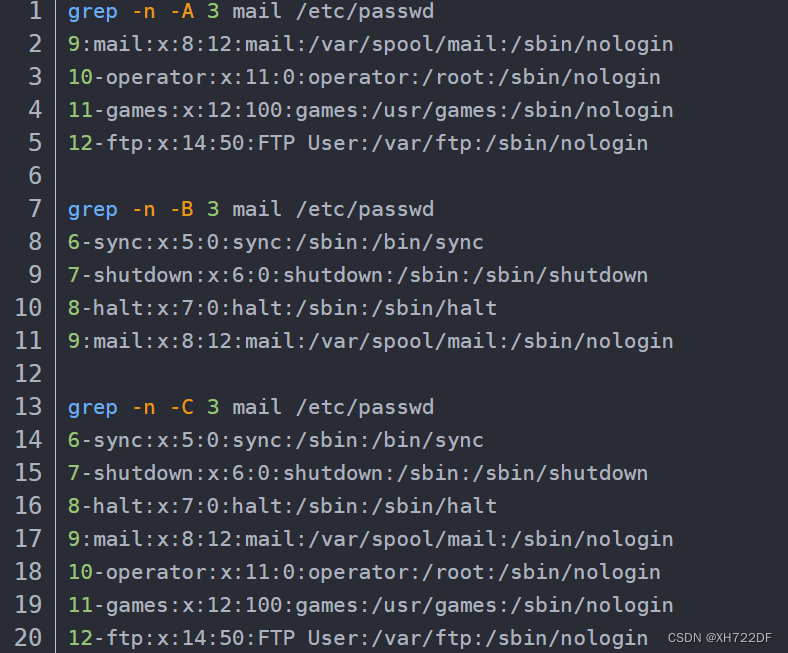
-
-e:相当于逻辑或 -
-E:匹配扩展正则表达式 -
-f:匹配两个文件,过滤出相同的内容,以第一个文件为准 -
-r:递归目录,目录下的文件内容,不处理软连接 -
-R:递归目录,目录下的文件内容,包括软连接 -
1.2 sort命令:排序
sort:以行为单位,对文件内容进行排序,默认按照数字从小到大,再字母从a到z的顺序排列,数字在前,字母在后。排序时对每行的内容从第一个字符开始依次排序。格式:常用2种方式
-
-f:忽略大小写,相同字母默认大写排在前面
-b:忽略每行之前的空格
-n:按照数字大小进行排序,此时不是按照单个字符进行比较,而是行首所有连续的数字都能被识别,按照识别到的数字的大小进行排序。且此时字母排序优先级高于数字
-r:反向排序
-u:去重,相同内容仅显示一次
-o:把排序后的结果转存到指定文件
-k:指定字段(字符)进行排序
-t:指定字段的分隔符
-
1.3 uniq命令:去重
-
uniq:去除连续重复的行,只显示一行选项:
-
-c:统计连续重复的行的次数,且合并连续重复的行 -
-u:显示仅出现一次的行,包括不是连续出现的重复行 -
-d:仅显示连续重复的行,不包括非连续出现的的重复行
1.4 tr命令:替换和删除
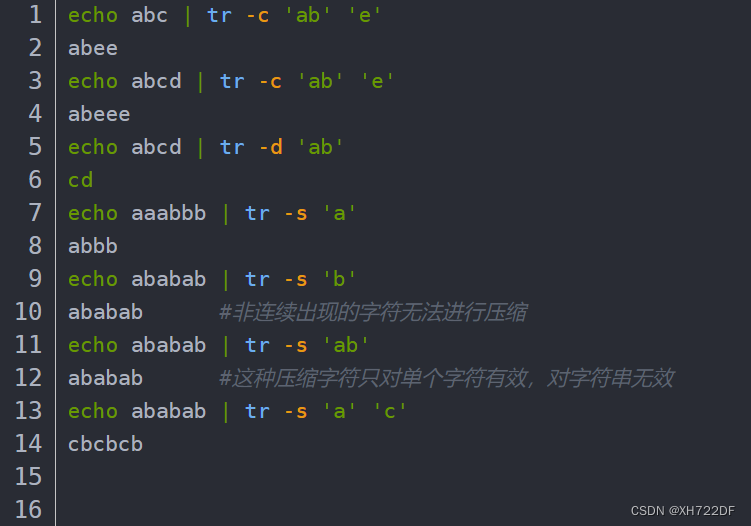
tr :用来对标准输出的字符进行替换,压缩和删除。
格式:
![]()
选项
-c:tr -c 字符集1 字符集2 ,保留字符集1的字符,其他的字符用字符集2来进行替换,字符集要用单引号''括起来-d:tr -d 字符集 ,删除字符集的字符-s:把字符集1的部分替换成字符集2的部分,也可以把连续重复出现的字符压缩成一个字符
sed比tr功能更强,常用于正则表达式。
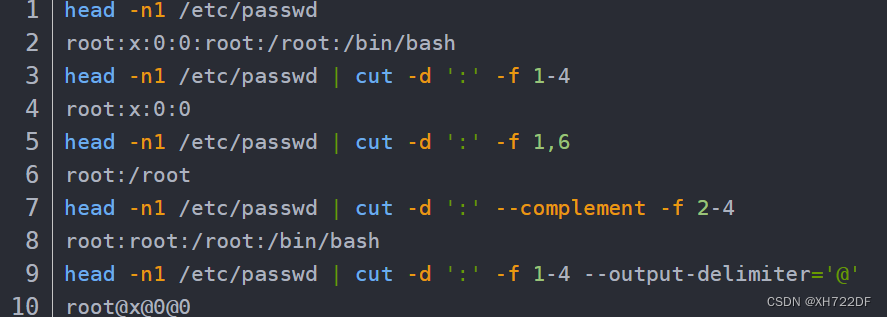
1.5 cut命令:快速裁剪
cut可以对字段进行截取和裁剪
选项:
-d :指定字段的分隔符,指定的分隔符用' '包裹,不指定-d默认分隔符为横向制表符(tab键)
-f:对字段进行截取,指定输出的字段,和-d连用,如1-3,输出1到3字段,2,4,输出2和4字段
-c :以字符为单位进行截取,不常用
-b :以字节为单位进行截取,不常用
--complement:排除指定的字段后再输出
--output-delimiter:更改输出内容的分隔符,指定改变的分隔符用=连接
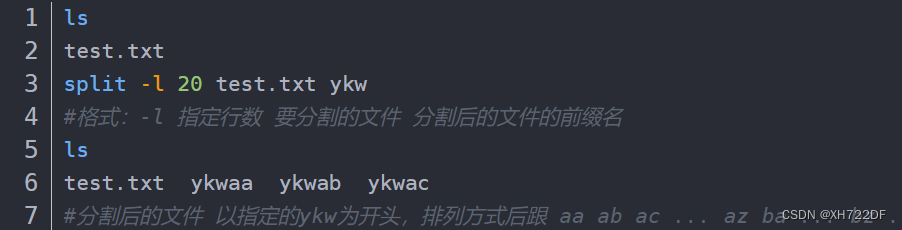
1.6 split命令:文件拆分
split :大文件拆分成若干小文件
选项:
-l :按行来进行分割
-b :按照大小来进行分割(单位K M G …)
1.7 文件合并
cat命令paste命令
cat合并和paste合并的区别?
cat是上下合并;paste是左右合并
1.8 练习
问:查看当前网络状态中有多少个ESTABLISHED和LISTEN。
![]()
其中 ^State 表示以State开头,-v是取反
二、正则表达式
正则表达式是由一类特殊字符以及文本字符所编写的一个模式,模式又来匹配文件当中的内容(字符)。校验我们输入的内容是否满足规定、格式、长度等等要求。
主要用来匹配文本的内容、命令的结果。
区别于通配符:通配符只能用于匹配文件名和目录名,不能匹配文件的内容和命令结果。
2.1 基本正则表达式
2.1.1 元字符(字符匹配)
. :匹配任意单个字符
\ :转义符:恢复字符的本意
[] :匹配指定的范围内的任意单个字符或者数字,区分大小写,也可以用1-5,a-t这样的方式范围匹配
^ :匹配以^之后内容开头的字符
^# :匹配以#开头的行
^$ :匹配空行
[ ] :中括号里输入空格,就可以匹配空格
注:匹配内容两边需要加引号,单引号双引号都可以
\w :匹配单词或汉字
\s :匹配任意的空白符
\d :匹配数字
\b :匹配单词的开始或结束
注:连续的数字、字母、下划线都算作单词的内部,如abc_123算作一个单词
反义字符:
\W :匹配任意不是字母,数字,下划线,汉字的字符,如+ - =
\S :匹配任意不是空白符的字符
\D :匹配任意非数字的字符
\B :匹配不是单词开头或结束的位置
[^] :取反,表示匹配除了^之后的内容
2.1.2 次数匹配
表示次数,匹配字符出现的次数:
* :匹配*前面的字符0次或者多次
匹配前一个元素零次或多次:
a*: 匹配零个或多个连续的字符 ‘a’。
123*: 匹配 ‘12’ 后面跟零个或多个 ‘3’ 的连续序列,如 ‘12’, ‘123’, ‘1233’, ‘12333’ 等。
贪婪匹配:
.*: 匹配任意字符(除换行符外)零次或多次。这通常用于匹配任意长度的文本。
a.*b: 匹配以 ‘a’ 开头,以 ‘b’ 结尾的字符串,中间可以是任意字符。
注意事项:
* 是贪婪的,它会尽可能多地匹配字符。如果需要非贪婪匹配(尽可能少地匹配),可以使用 *?。
与其他元字符结合使用:
.*: 匹配任意长度的字符序列。
[a-z]*: 匹配任意小写字母序列,长度可以为零。
\d*: 匹配任意数字序列。
\? :匹配前面的字符0次或者1次。如'ab\?c'可以匹配到abc和ac
\+ :匹配前面的字符至少出现一次
\{n\} :匹配前面的字符n次,且前面的字符必须是连续出现n次才能匹配
\{m,n\} :匹配前面的字符至少m次,至多n次,超出的不显示
\{,n\} :匹配前面的字符至多n次
\{m,\}:匹配前面的字符至少m次
2.1.3 位置锚定
对行匹配:
^ :行首锚定,以什么为开头,如^3 ^[a-z]
$ :行尾锚定,以什么为结尾,如t$ [3-9]$
特别的:对于^text&形式,是整行匹配,即匹配到的行的内容只能是text,字符和字符数量完全匹配。
^$:匹配空行,可以理解为行首和行尾之间为空,即空行
对词匹配:
\<或者\b :词首锚定,匹配单词的左侧,连续的数字、字母、下划线都算作单词的内部,写在匹配内容的左边
\>或者\b :词尾锚定,匹配单词的右侧,写在匹配内容的右边
\btext\b或者\<text\>表示整词匹配,只能匹配到内容为text的文本,字符和字符数量完全匹配。
2.1.4 分组和逻辑关系
\(\) :表示分组,把括号内的内容视为一个整体
\| :表示逻辑或
2.2 扩展正则表达式
扩展正则表达式和基本正则表达式的规则完全一致,唯一的区别就是扩展正则表达式大部分时候不需要转义符\。除了\b \< \>锚定词首词尾的时候不能去掉转义符\,表示()而不是分组时也要加\。
grep -E支持扩展正则表达式。
egrep和grep -E一个效果。
2.3 练习
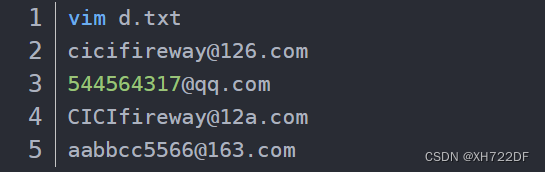
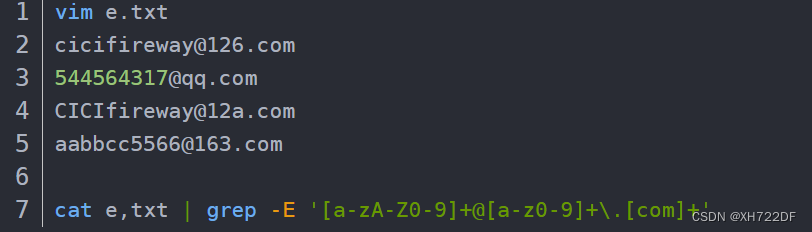
- 使用正则表达式把下列邮箱全部匹配出来

- 匹配下列电话
显示/etc/passwd中以sh结尾的行;
![]()
查找/etc/inittab中含有“以s开头,并以d结尾的单词”模式的行

查找ifconfig命令结果中的1-255之间的整数;
![]()
在/etc/passwd中取出默认shell为bash的行;
![]()
高亮显示passwd文件中冒号,及其两侧的字符
![]()

)



