前言
出于想对接口文档直接生成测试用例或者自动化的需求,且方便检索对接,对本地知识库进行的研究,搭建了一天才搞出来,踩了许多坑,于是分享下过程。当然用docker搭应该挺方便(也许?)
本人电脑配置,AMD u,仅核显,32GB内存,运行该项目时也没什么波动,占用不高,感觉16GB也能跑。

以下搭建过程都不需要梯子,这就是为什么选择deepseek的原因,而且deepseek还送免费额度。
一、搭建conda虚拟环境
1.1 说明
Anaconda可以方便隔离各种python项目之间的环境,指定各项目的python版本和包依赖,因为各种ai项目基本都是用python搭建,所以用Anaconda不用经历本地python版本不一致,依赖乱了又要重装一遍的烦恼。
Anaconda 包及其依赖项和环境的管理工具为 conda 命令
1.2 安装
下载 Anaconda:Download Anaconda Distribution | Anaconda
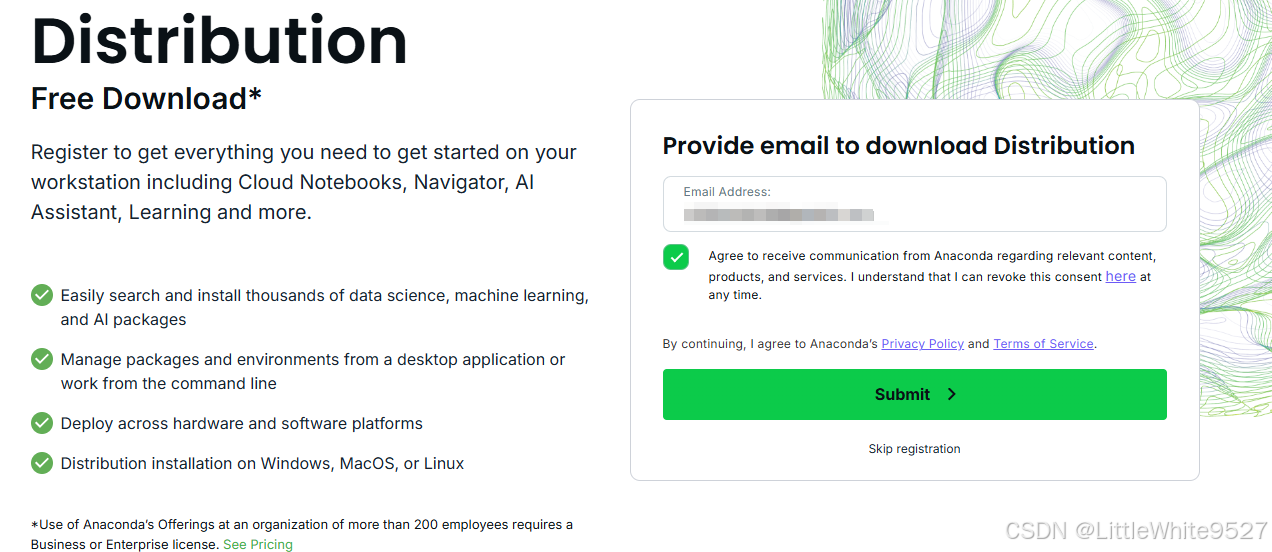
填入邮箱地址,点击Submit即可进入下载页
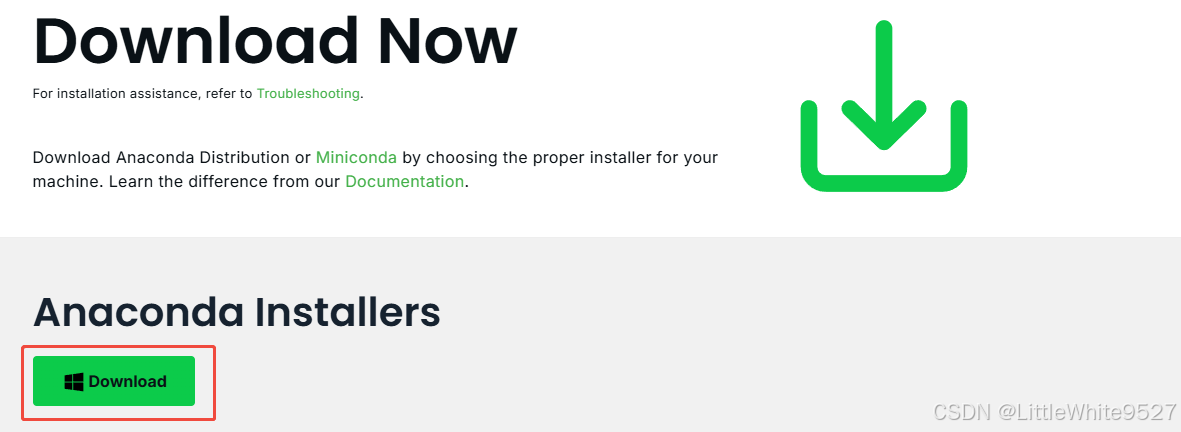
下载完成后执行安装(建议以管理员身份运行),然后一路next,安装目录选个大点的盘就行。
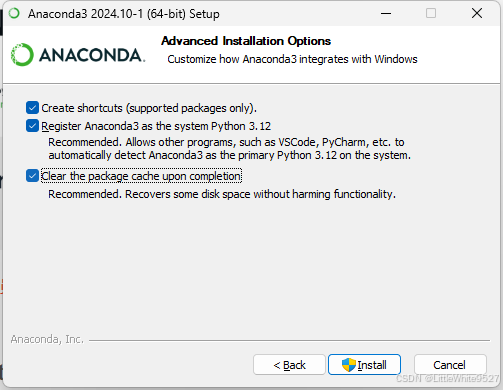
这里可以全勾选,第二个选项是支持将anaconda当python环境使用,第三个选项是安装完成后清理包缓存,可以释放一些磁盘空间,对后续使用没有影响。
1.3 配置本地环境变量PATH
右键我的电脑 -> 属性 -> 高级系统设置 -> 环境变量 -> Path -> 新建
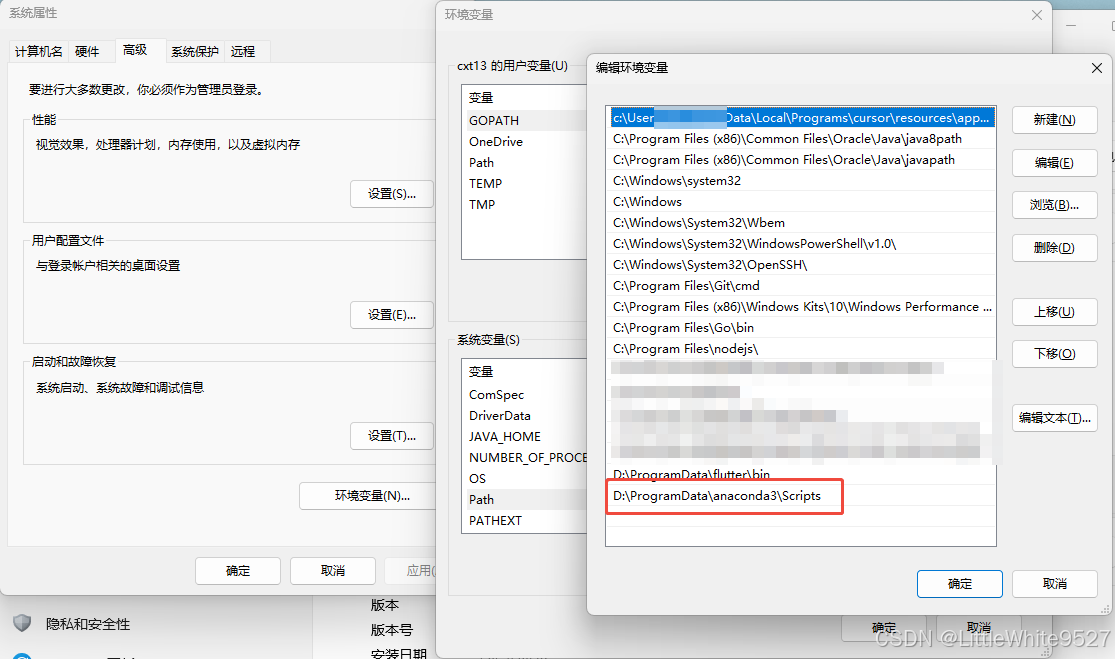
我这里安装D盘目录下,所以配置 D:\ProgramData\anaconda3\Scripts ,你可以根据你安装的目录配置
1.4 测试Conda
按win键打开开始菜单,搜索命令提示符,以 管理员身份 运行,输入
conda --help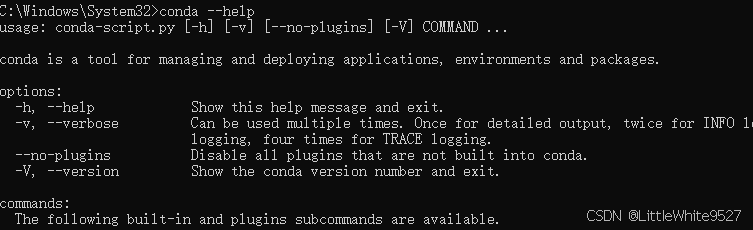
看到这个输出,说明路径配置正常
1.5 创建虚拟环境
接下来创建 langchain-chatchat 需要用到的虚拟环境,chatchat支持python版本3.8->3.11,我们这里使用3.10,用3.11运行也正常。
conda create -n chatchat python=3.10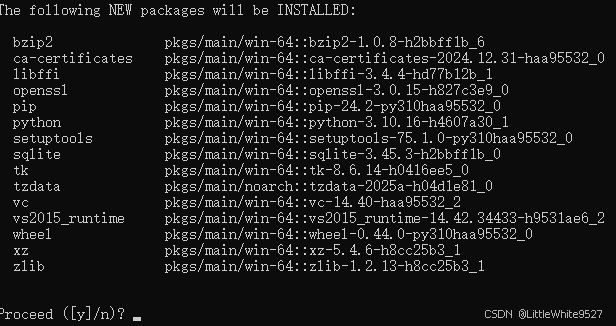
输入y回车,继续执行,我们看到以下输出就可以执行 conda activate chatchat,来激活这个环境了
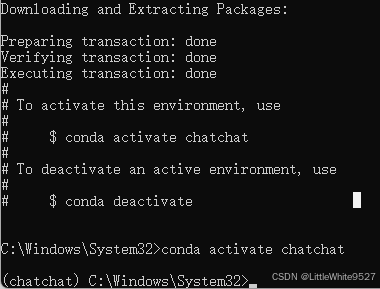
如果遇到,提示 conda init before conda activate,可以尝试执行下 conda init,执行完如果还提示这个,那就尝试直接执行 activate chatchat,如果还不行,就看下是不是以管理员身份运行的命令提示符(或者powershell)
还有其它问题本人就没遇到过了,可以自行搜索解决,conda其它命令也可以自行搜索。
二、搭建Ollama及下载相关Embedding模型
2.1 说明
Ollama可以理解为一个llm框架,负责加载各类llm模型,使用起来十分方便。
Embedding主要是用来做文本的向量化,后可存储到向量数据库,方便RAG检索。
2.2 安装
下载Ollama:Ollama
进页面就是一个大大的download,直接下载安装即可。
安装完成后,你右下角就会有只羊驼图标,同时ollama会占用你本地11434端口(确保端口可用),进行开放服务。
同样以 管理员身份 运行命令提示符。在Ollma页面有个大大的搜索框可以直接搜索你需要的模型。
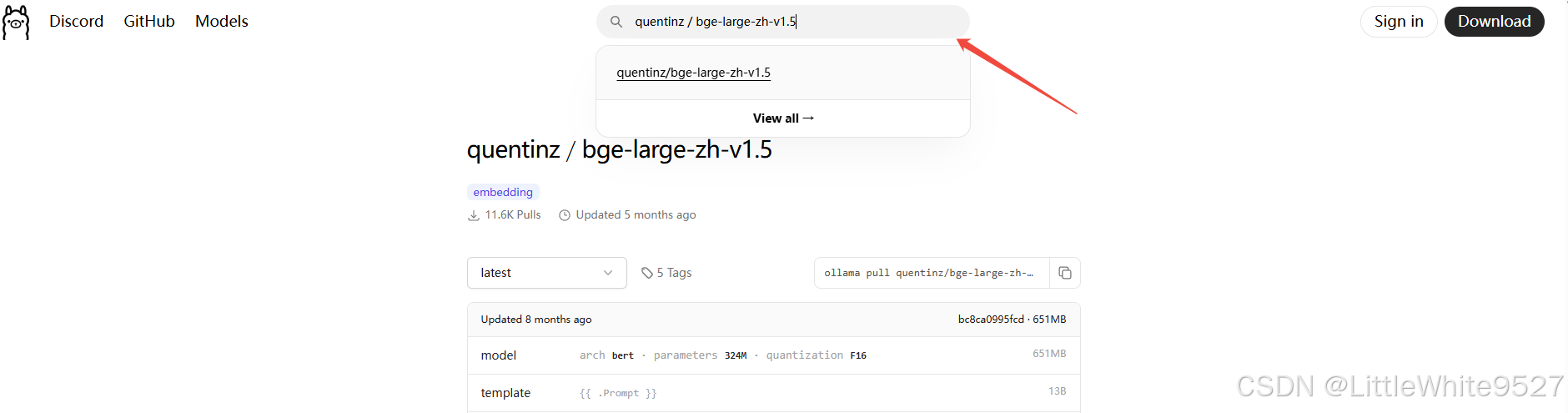
这里我们下载 quentinz/bge-large-zh-v1.5 和 bge-m3
简单说明:
bge-large-zh-v1.5 主支持中文
bge-m3 支持百来种语言
关于这两个模型详细信息可以自行搜索,也可以使用其它embedding模型,主要这个两个是在langchain-chatchat的配置文件里就有。
直接在命令提示符,运行
ollama pull quentinz/bge-large-zh-v1.5ollama pull bge-m3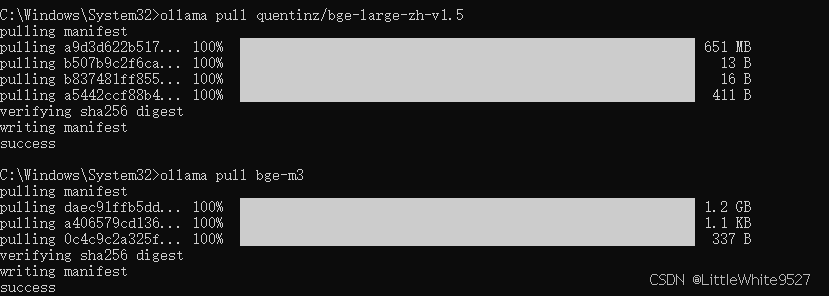
2.3 测试
不像llm模型需要run,到这里embedding模型已经可以使用了,你可以本地postman测试一下。
curl --request POST \--url http://127.0.0.1:11434/v1/embeddings \--header 'Accept: application/json' \--header 'Accept-Encoding: gzip, deflate, br' \--header 'Connection: keep-alive' \--header 'Content-Type: application/json' \--header 'User-Agent: PostmanRuntime-ApipostRuntime/1.1.0' \--data '{"model": "quentinz/bge-large-zh-v1.5","input": ["天很蓝", "海很深"]
}'关于ollama相关配置项(鉴权、模型存储路径、端口等)可以自行搜索。
继续下一步
三、申请DeepSeek API Key
如果你有了或知道怎么申请,可以直接跳过到下一章。
3.1 申请api key
进入DeepSeek官网:DeepSeek
右上角进入API开放平台

登录后,默认送10块钱额度,进入API Keys
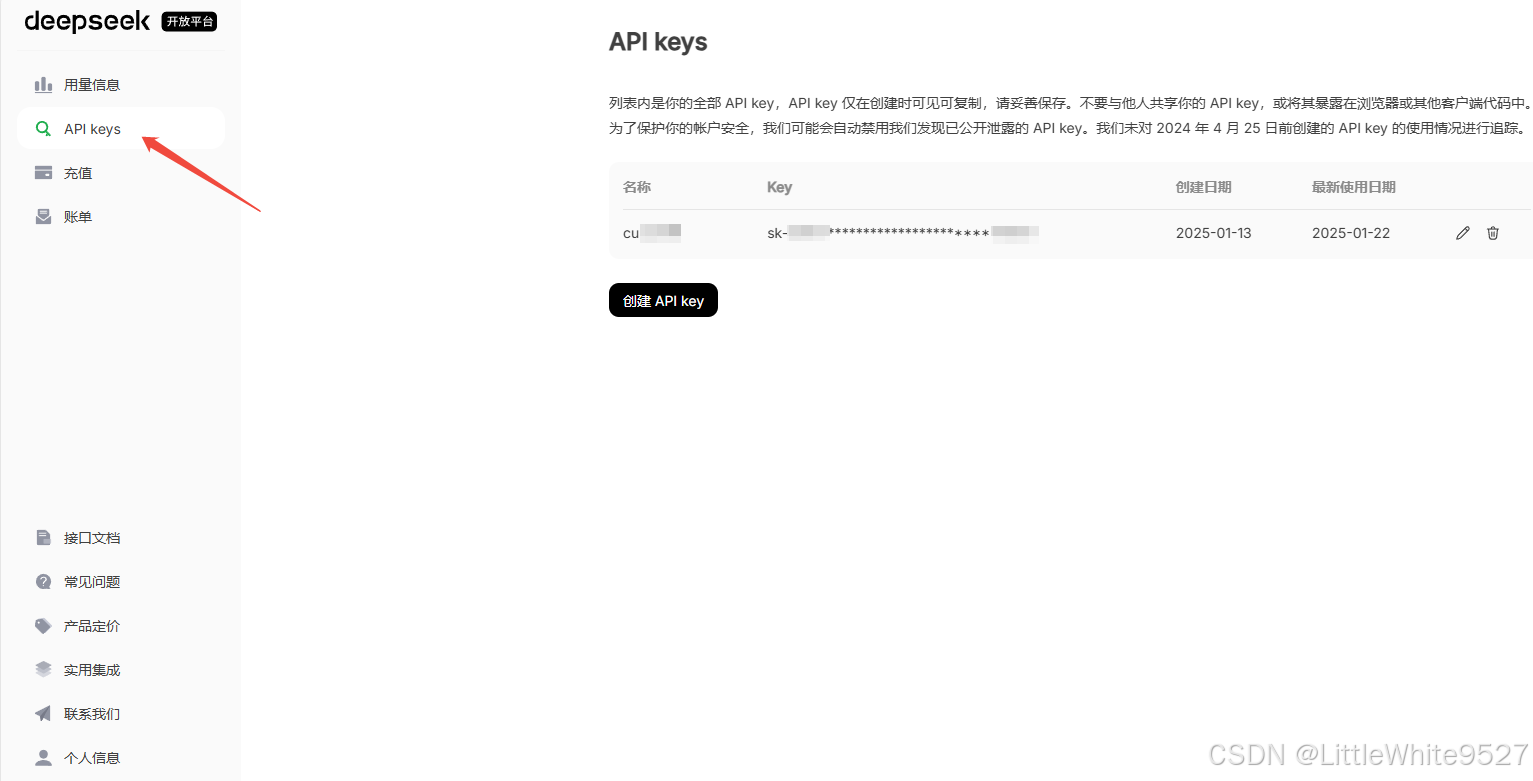
申请到Key后,我们找个地方保存下来。
3.2 测试
curl --request POST \--url https://api.deepseek.com/chat/completions \--header 'Accept: application/json' \--header 'Accept-Encoding: gzip, deflate, br' \--header 'Authorization: Bearer sk-你自己的apikey' \--header 'Connection: keep-alive' \--header 'Content-Type: application/json' \--header 'User-Agent: PostmanRuntime-ApipostRuntime/1.1.0' \--data '{"model": "deepseek-chat","messages": [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Hello!"}]
}'DeepSeek支持opanai的API调用格式,接口文档里也有,可以自行测试
四、搭建Langchain-ChatChat
至此,前期准备工作都已经做完O(∩_∩)O,接下来,正式开始搭建chatchat
github地址:GitHub - chatchat-space/Langchain-Chatchat: Langchain-Chatchat(原Langchain-ChatGLM)基于 Langchain 与 ChatGLM, Qwen 与 Llama 等语言模型的 RAG 与 Agent 应用 | Langchain-Chatchat (formerly langchain-ChatGLM), local knowledge based LLM (like ChatGLM, Qwen and Llama) RAG and Agent app with langchain
gitcode镜像站地址:GitCode - 全球开发者的开源社区,开源代码托管平台
本文使用 pip 安装部署 有源码部署需求可根据项目中readme自行部署,关键是配置,其它大差不差。
4.1 pip安装部署
首先,以管理员身份运行命令提示符,执行 conda activate chatchat,激活chatchat的python环境,如果在conda搭建那一步已激活,则忽略。
conda activate chatchat设置清华源
这个地址建议收藏,经常要用,后续搭建其它python项目也可以用到。
pip config set global.index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple安装 Langchain-Chatchat
选一个目录,执行
pip install langchain-chatchat -U安装完成后,执行
chatchat init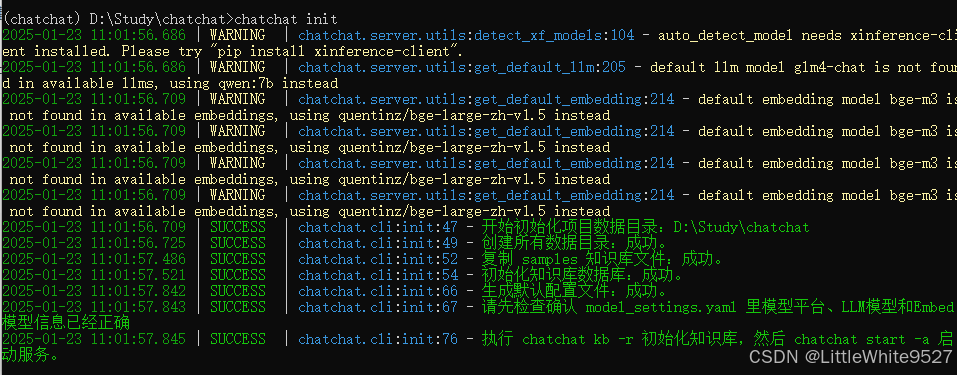
到这里,上面WARNING我们都忽略,接下来打开chatchat的目录,我们开始配置 model_setting.yaml,确保Ollama及embedding已安装,DeepSeek已申请
4.2 配置 model_setting.yaml
修改 DEFAULT_LLM_MODEL,DEFAULT_EMBEDDING_MODEL
# 默认选用的 LLM 名称
DEFAULT_LLM_MODEL: deepseek-chat# 默认选用的 Embedding 名称
DEFAULT_EMBEDDING_MODEL: quentinz/bge-large-zh-v1.5这里 DEFAULT_EMBEDDING_MODEL 你也可以使用 bge-m3,看个人需求,关于两者的区别我已在上文有说明。
修改 platform_type
记得把前面 # 号去掉(有点啰嗦哈哈)
platform_type: ['ollama', 'openai']这样就可以做到 embedding 使用本地的模型,而 llm 使用deepseek的
修改 MODEL_PLATFORMS
把xinference的auto_detect_model改为false,不然后续一直会告警,并且卡住chatchat的执行
- platform_name: xinferenceplatform_type: xinferenceapi_base_url: http://127.0.0.1:9997/v1api_key: EMPTYapi_proxy: ''api_concurrencies: 5auto_detect_model: falseollama加上bge-m3,如果你的DEFAULT_EMBEDDING_MODEL用的bge-m3的话,llm_models不用管,这里配置只是说明可用的模型,你上面没用到就没影响了
- platform_name: ollamaplatform_type: ollamaapi_base_url: http://127.0.0.1:11434/v1api_key: EMPTYapi_proxy: ''api_concurrencies: 5auto_detect_model: falsellm_models: []embed_models:- quentinz/bge-large-zh-v1.5- bge-m3openapi地址改为deepseek的api地址,并修改llm_models
- platform_name: openaiplatform_type: openaiapi_base_url: https://api.deepseek.comapi_key: sk-你自己的apikeyapi_proxy: ''api_concurrencies: 5auto_detect_model: falsellm_models:- deepseek-chatembed_models: []text2image_models: []image2text_models: []rerank_models: []speech2text_models: []text2speech_models: []到这里配置完成,修改完记得保存,以确保生效,接下来我们初始化知识库,
4.3 初始化测试知识库
执行
chatchat kb -r需要等待一段时间
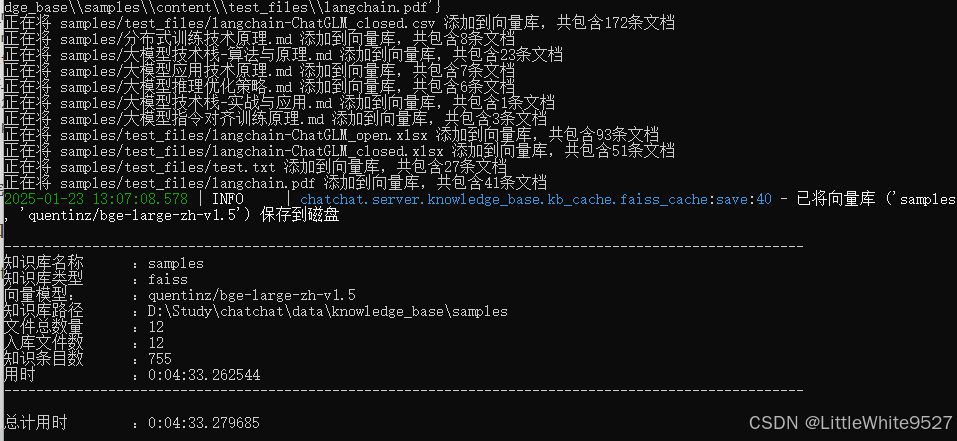
看到这里说明,测试知识库初始化完成
4.4 启动chatchat
执行
chatchat start -a如果出现

这个报错,则说明httpx版本过高,不支持proxies,需要降低下httpx版本([BUG] httpx包版本错误 · Issue #5115 · chatchat-space/Langchain-Chatchat)
Ctrl + C 终止当前chatchat进程(一次不行就按多几次),然后执行
pip install httpx==0.27.2 -U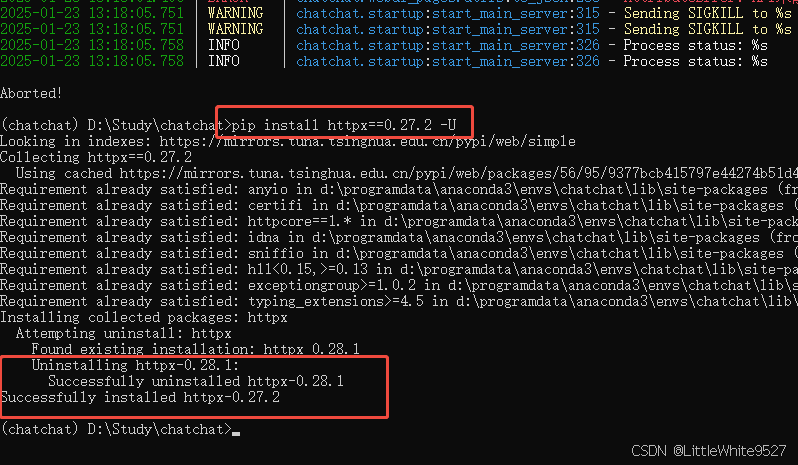
再次运行chatchat
chatchat start -a 
测试一下chat功能和Rag对话功能,默认rag的知识库是取自github仓库的issue中。
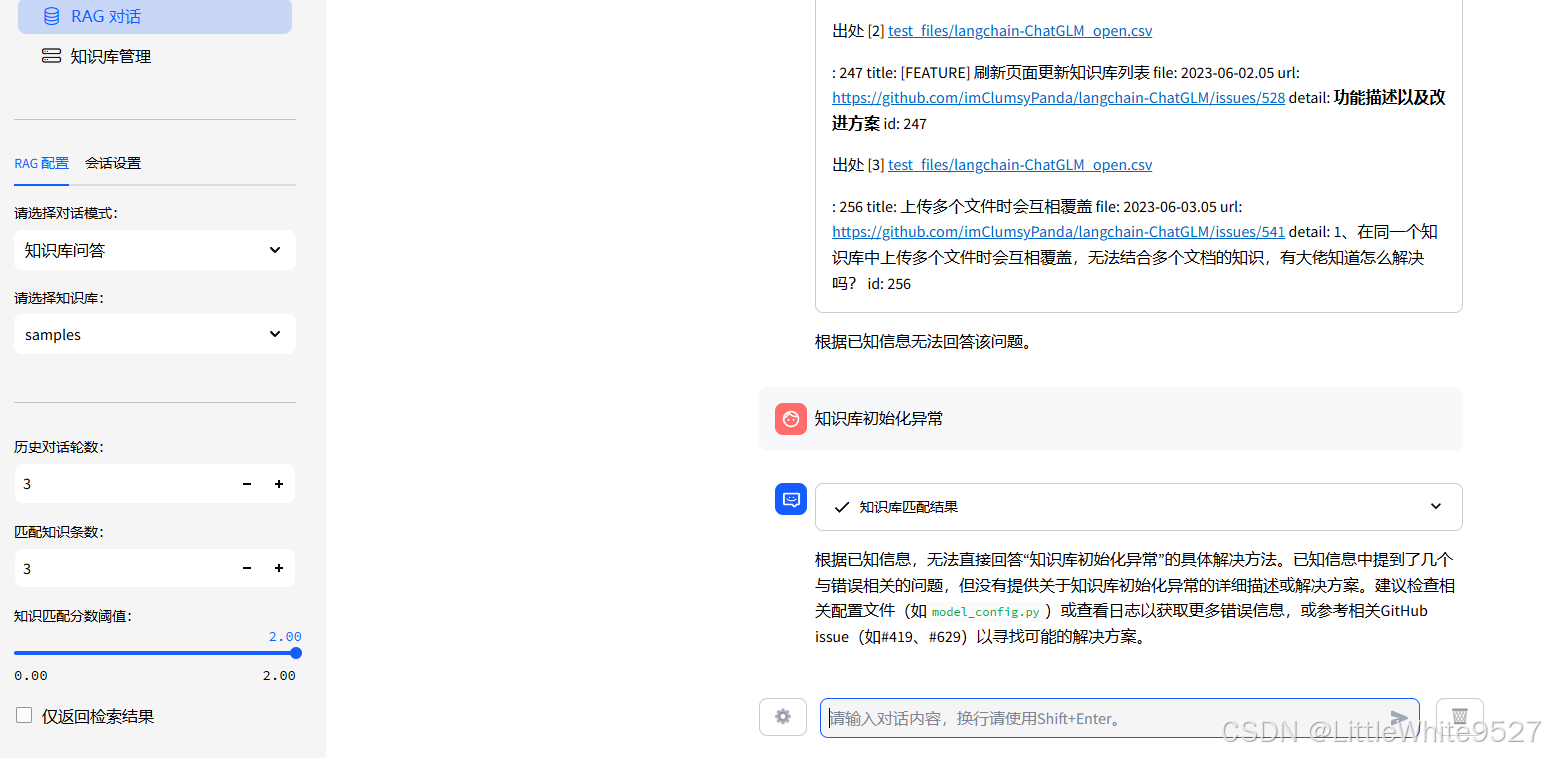
在知识库管理中可以新建你自己的知识库,然后上传文件,就可以生成你自己的知识库问答系统了,比如上传swagger生成的json接口文档,或者各种专业领域的pdf、图片、ppt等。
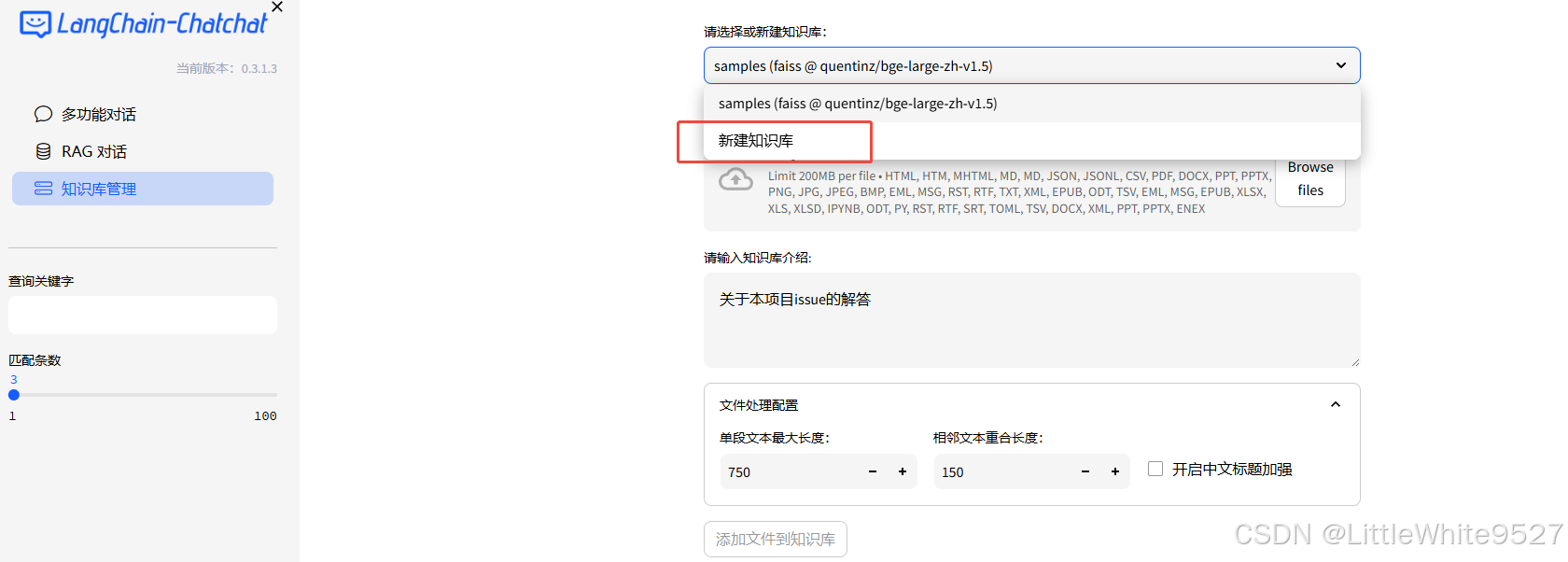
至此整体部署完成。
结语
本文主要是面向如何部署,避开了个人在部署过程中踩的各种坑,像我一开始embedding模型用的豆包,百度一直报错,后续是用oneapi去解决的,这些都卡了我半天,所以写这篇文章做个笔记,选择Langchain-chatchat是因为它star数高而且中文友好,prompt原生就是中文配置,还有个项目叫 kotaemon,结合了GraphRAG能生成知识图谱。
大家如果隐私要求比较高也可以使用自己的llm模型,这里是为了方便,而且普通办公笔记本就能部署运行所以llm模型用的deepseek。
chatchat中还有许多配置项,可以调整prompt,也可以更换向量数据库,也可以使用agent,还有很多其它配置可以实现一些,像是获取数据库链接并将你说的话转换为sql语句执行(理论上有风险,可以测试环境试着玩),这些在开源项目的文档中都有,大家可以自行探索。
同时chatchat也暴露了http接口,start -a 本身是启动了api + web端,如果你有自己的web端,或者想通过接口来访问,然后开发自己的功能,也可以只启动api,api文档在开源文档也有。





的创建与自定义)
